GPT-3被超越?解读低能耗、高性能的GlaM模型
原创作者 | LJ
GLaM: Efficient Scaling of Language Models with Mixture-of-Experts
https://arxiv.org/pdf/2112.06905.pdf
01 摘要
这是上个月谷歌刚刚在arxiv发布的论文,证明了一种能scale GPT-3但又比较节省耗能的架构。
GPT-3自问世以来在多项自然语言处理的任务上都有超强的表现。但是训练GPT-3这样庞大的模型非常耗费能源。
在这篇论文中,作者开发了以Mixture of Experts为基础的GlaM (Generalist Language Model)。它虽然参数量有GPT-3的7倍之多,但训练起来只需GPT-3三分之一的能耗,而且在NLP任务的表现上相比GPT-3持平甚至更优。
02 什么是Mixture of Experts Model (MoE)
MoE这个概念其实已经提出很久了。这个概念本身非常容易理解,有点类似ensemble:与其训练一个模型,我们训练数十个独立的“专家模型”(expert model)。
与简单的ensemble不同的是,在做训练或推断(inference)的时候,我们用一个gating network来“挑选专家” — 在几十个专家模型中挑选出几个适合的专家模型用来计算。通俗的讲,这些专家“术业有专攻”,根据所长而分工。
那么,为什么MoE可以省能耗呢?因为无论是训练或者推算的时候,每次真正的计算只有几个专家被激活。所以,虽然参数量很大,但每次用到的参数只是很小的一部分。
这个团队在2017年在一篇ICLR的论文[1]里已经把MoE的概念应用在了当时NLP state-of-the-art的RNN model上,并且超越了当时的state of the art。
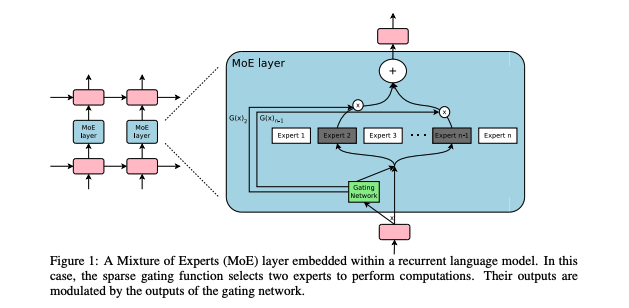
这次,因为GPT-3的发布,作者又将MoE的概念应用在GPT-3这样以transformer为基础的模型上。
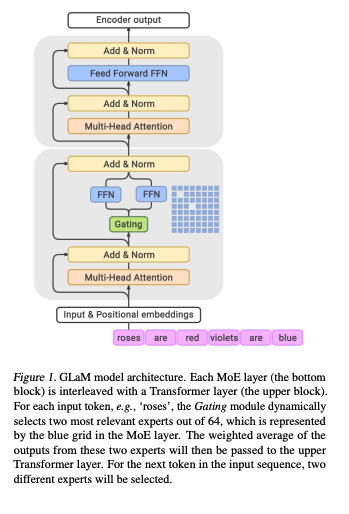
这次也同样得到了很好的结果。这篇论文其实是2017年那篇论文的自然延伸,方法上大同小异,所以很多的精华在2017年的那篇论文里。我们今天一并总结。
03 实验细节
3.1 困难和挑战
MoE这个概念既然由来已久,为什么从前没有得到很好的实验结果呢?这是因为在实际应用中MoE有几个难点之前一直没被解决,而Google团队逐一找到了解决方案。
难点一:batch size太小
MoE训练的时候会把一个batch的训练数据分布到几十个expert model上。一分下来,分到每个model头上的数据量就很少了。一般GPU和CPU需要很大的batch size保证运算的高效,不然固定成本(overhead cost)太大了。但如果一开始的batch太大的话,memory又不够。作者巧妙的把模型的某些部分做分布式计算,通过data parallelism和model parallelism来弥补这个问题。
难点二:专家模型分工不均匀
Gating network挑选专家的结果经常会是同样的几个专家。这样就会引起恶性循环:好的专家模型能分到的训练数据越来越多,模型也变得越来越好;不好的专家一直不被调用,就一直不好。为此,作者在loss function里加了一项权重用来load balance,鼓励gating network分配平衡。
难点三:需要在大数据集上才能体现优势
已有的专家模型的论文所采用的的数据集只有60万个数据点。专家模型的参数量庞大。所以需要更大的数据集才能真正体现他的优势。作者采用和GPT-3类似的训练集,很自然地解决了这个问题。
3.2 实际训练的注意事项
由于这个模型有几个兆的参数量,训练一次就是一个庞大的工程,所以容错率非常低:如果模型训练时出现bug了,重头再训练非常昂贵,也基本没什么空间来优化超参数。
另外,像这一类极稀疏参数被激活的模型很容易碰到分母为零之类的计算不稳定性。基于此,在理论的基础上,作者也分享了实际训练也有一些注意事项。
注意事项一: 先训练一个小模型。在这个过程中,能够暴露很多潜在的bug。在保证这个迷你模型能够收敛之后,再真正训练大的模型。
注意事项二:如果一个batch中出现导数为零或者无限大的情况时,直接跳过这个batch的训练数据。
注意事项三:及时保存checkpoint。一旦出错,自动把之前的checkpoint调出来,从那里开始继续训练,这样就不用从头开始。由于每个batch是随机抽取的,即使上一次随机的数据导致了分母为零等不稳定性,新一批数据是重新随机选择的,有可能能顺利通过之前报错的地方。
注意事项四:虽然是老生常谈,但训练数据的质量真的很重要。作者花了很多心思来提高数据的质量,并印证这样做的重要性。
原始的数据集包含了1.6 x 10^12的单词,包括了书籍和互联网上各种各样的网页。有的网页是专业人员写的,文本质量高;有的网页是各种论坛上零零总总的用户评论,文本质量低。
和GPT-3团队的思路一样,作者也自己训练了一个线性模型,用以判断文本质量。
他们将维基百科、出版的书籍和一些其他信得过的网站作为正面样本,把其他的网站作为负面样本,让模型去鉴别。通过这个过程,他们过滤掉了很多低质量网页,把他们从训练集中删除。
这样做的效果是非常显著的。在下图中可以看到绿色的是过滤后的训练集,灰色的虚线是过滤前的原始训练集。横轴是训练集的大小。之前很多的研究都在看训练集大小的影响。
这个结果告诉我们,训练集不能一味只追求数量,而是要追求数量。同样的原始训练集,数量扩大三倍,还远不如在同样的数量下把质量提上去。另外,相对于自然语言理解(Natural language understanding, NLU)的任务,数据质量在自然语言生产(Natural language generation, NLG)的任务上效果更为显著。
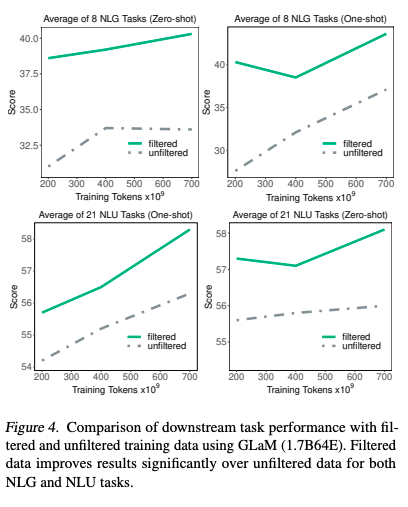
04 结果
4.1 MoE和GPT-3的比较
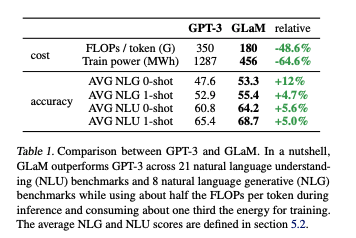
GLaM在29个自然语言的任务上总的来说相比GPT-3略胜一筹。最重要的是训练的总能耗仅仅是GPT-3的三分之一。
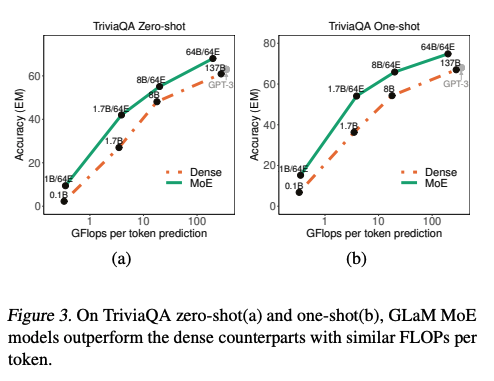
以TriviaQA任务举例,上图中Dense指的是类似GPT-3架构的单个模型。Dense和MoE model的准确率都会因为参数量增长而增长。但是在相同的运算量下(横轴),MoE总是表现得更好。
4.2. 需要多少专家模型
相比于dense model,MoE如果想scale的话不仅可以将模型变得更宽更深,还可以增加专家的数量。只要每次被激活的专家数量不变,增加专家并不增加prediction时的运算量。
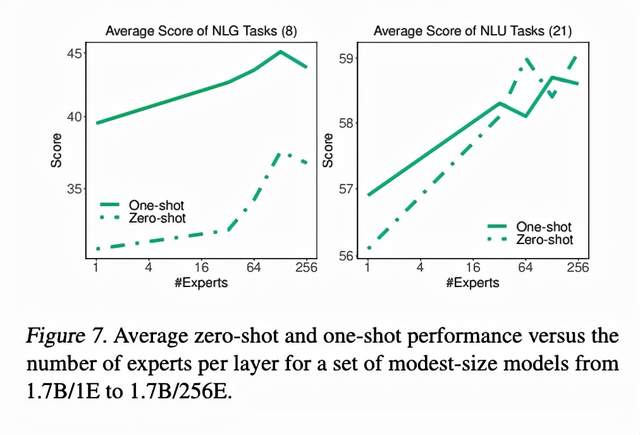
上图中,作者控制每次prediction的计算量不变,调整不同的专家数量。一般看来,专家越多,模型表现越好。
05 总结
总的来说,作者开发了以MoE为基础的GLaM模型。虽然模型参数量很多,但通过激活少量的专家,这类的模型训练和推算的能耗更低,而且结果比GPT-3更好。
GPT-3被超越?解读低能耗、高性能的GlaM模型的更多相关文章
- TI推出SimpleLink低能耗蓝牙CC2541
TI推出SimpleLink低能耗蓝牙CC2541 日前,德州仪器 (TI) 宣布推出 SimpleLink™ 低能耗蓝牙 (Bluetooth®Low Energy) CC2541-Q1, 这是一款 ...
- 2019-8-24-win10-本地适配器不支持重要的低能耗控制器状态
title author date CreateTime categories win10 本地适配器不支持重要的低能耗控制器状态 lindexi 2019-8-24 16:2:33 +0800 20 ...
- 服务器端高性能的IO模型 转自酷勤网
服务器端编程经常需要构造高性能的IO模型,常见的IO模型有四种: (1)同步阻塞IO(BlockingIO):即传统的IO模型. (2)同步非阻塞IO(Non-blockingIO):默认创建的soc ...
- (转)高性能I/O模型
本文转自:http://www.cnblogs.com/fanzhidongyzby/p/4098546.html 服务器端编程经常需要构造高性能的IO模型,常见的IO模型有四种: (1)同步阻塞IO ...
- 一种全新的MEMS开关——高性能、快速、低能耗以及双稳态
这种开关最早由申军教授和研究生阮梅春发明,研究生埃里克·朗格卢瓦在简化结构和缩小尺寸上作了探索,黄志林用相同原理做出了MEMS光学镜子开关,曹志良改变设计.材料和工艺后制作出了能同步开关的矩阵.这种M ...
- 从表单驱动到模型驱动,解读低代码开发平台的发展趋势 ZT
原文地址:https://www.grapecity.com.cn/blogs/read-the-trends-of-low-code-development-platforms 随着社会数字化进程的 ...
- 从区划边界geojson中查询经纬度坐标对应的省市区县乡镇名称,开源Java工具,内存占用低、高性能
目录 坐标边界查询工具:AreaCity-Query-Geometry 性能测试数据 测试一:Init_StoreInWkbsFile 内存占用很低(性能受IO限制) 测试二:Init_StoreIn ...
- 简述 高性能Linux服务器 模型架构 设计
主要从三个方面进行分析: 1.事件处理模式 2.并发模式 一.事件处理模式 1.Reactoor模式 定义: 主线程只负责监听文件描述符上是否有事件发生,有的话立即将该事件通知工作线程,除此之外,主线 ...
- 标准的CSS盒子模型?与低版本IE的盒子模型有什么不同的?
CSS盒子模型:由四个属性组成的外边距(margin).内边距(padding).边界(border).内容区(width和height); 标准的CSS盒子模型和低端IE CSS盒子模型不同:宽高不 ...
随机推荐
- Jvm内存回收
一.什么内存会被回收 可达性分析算法 通过一系列的GC ROOT的对象作为超始点,从这些节点开始向下搜索,搜索所走的路径称为"引用链",当一个对象到GC ROOT之间没有任何引用链 ...
- 深入Windows APC
本篇原文为 Depths of Windows APC ,如果有良好的英文基础,可以点击该链接进行阅读.本文为我个人:寂静的羽夏(wingsummer) 中文翻译,非机翻,著作权归原作者 Rbmm ...
- PyTorch 介绍 | AUTOMATIC DIFFERENTIATION WITH TORCH.AUTOGRAD
训练神经网络时,最常用的算法就是反向传播.在该算法中,参数(模型权重)会根据损失函数关于对应参数的梯度进行调整. 为了计算这些梯度,PyTorch内置了名为 torch.autograd 的微分引擎. ...
- IDE集成git
目录 简介 Git安装 IDE集成Git IDE集成Git代码的创建分享上传 代码的下载和普通上传 分子的创建以及合并 代码的回滚 查看历史版本 简介 Git 是一个开源的分布式版本控制软件,用以有效 ...
- git clone 命令
感谢原文作者:寻芝彬 原文链接:https://www.jianshu.com/p/c992c799f2dd 描述 拷贝一个 Git 仓库到本地 实例 拷贝一个 Git 仓库到本地,本地目录名称与Gi ...
- js获取 url?后面的参数取值
function GetRequest() { var url = location.search; //获取url中"?"符后的字串 var theRequest ...
- docker错误处理——docker Job for docker.service failed because the control process exited with error code.
(15条消息) docker Job for docker.service failed because the control process exited with error code._Hel ...
- Puppeteer简介
puppeteer常用API https://github.com/GoogleChrome/puppeteer/blob/master/docs/api.md Puppeteer是一个node库,他 ...
- JMeter使用流程
JMeter使用流程 首先我们要新建一个线程组,线程组的作用模拟多个访问对象,对系统可以进行压力测试 添加"HTTP Cookie管理器": 添加"Http请求默认值&q ...
- Sublime Text3安装及汉化
Sublime Text 是一款流行的代码编辑器软件,也是HTML和散文先进的文本编辑器,可运行在Linux,Windows和Mac OS X.也是许多程序员喜欢使用的一款文本编辑器软件. 下载地址: ...