scrapy爬取youtube游戏模块
本次使用mac进行爬虫 mac爬虫安装过程中出现诸多问题
避免日后踩坑这里先进行记录
首先要下载xcode ,所以要更新macOS到10.14.xx版本
更新完之后因为等下要进行环境路径配置 但是macOS升级到高级版本之后自带了一个自我保护的功能
因此需要重启电脑然后按cmd+r 进入编辑模式 然后选择语言 粘贴下面的命令后,按回车,输入你的系统密码;
sudo spctl --master-disable
然后取消后重启就可以了 然后下载xcode 下载完重启
接下来下载下载神器 https://brew.sh/index_zh-cn.html
下载安装后提示
Warning: Homebrew's sbin was not found in your PATH but you have installed formulae that put executables in /usr/local/sbin.Consider setting the PATH for example like so
就是说这个homebrew虽然安装了 但是不在路径中 因此需要配置路径 刚刚已经把安全模式取消 现在要去更改下路径环境
Mac配置环境变量的地方
1./etc/profile (建议不修改这个文件 )
全局(公有)配置,不管是哪个用户,登录时都会读取该文件。
2./etc/bashrc (一般在这个文件中添加系统级环境变量)
全局(公有)配置,bash shell执行时,不管是何种方式,都会读取此文件。
3.~/.bash_profile (一般在这个文件中添加用户级环境变量)
每个用户都可使用该文件输入专用于自己使用的shell信息,当用户登录时,该文件仅仅执行一次!
这里选择~/.bash_profile
sudo vim ~/.bash_profile
然后输入电脑密码进入
export PATH="/usr/local/bin:$PATH"
修改完后按esc 然后输入wq:! 回车 (:wq! 强制保存文件,并退出vi)
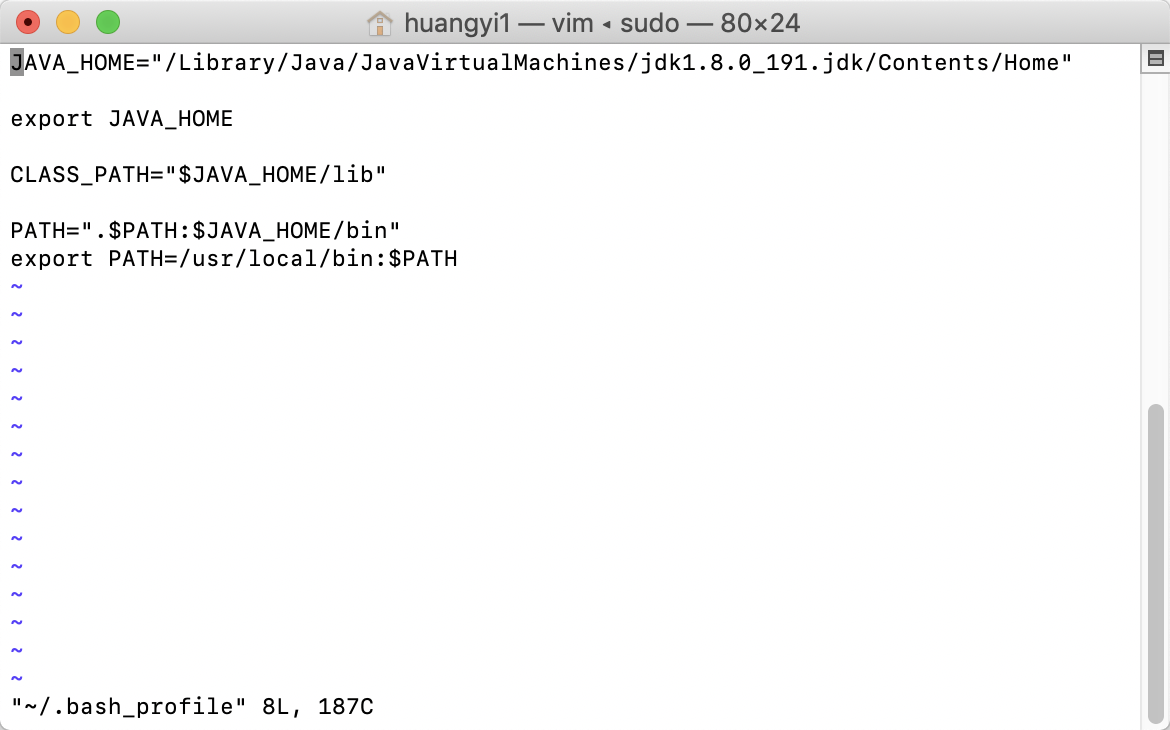
然后终端输入 $source ~/.bash_profile 进行刷新
sudo python get-pip.py
sudo pip install Scrapy
如果安装成功则输入 scrapy --verison 查看版本
本次内容是热门直播游戏、推荐、热门直播、work to game、时下流行视频。
热门直播游戏
Live-broadcast-id = 游戏直播名称
live-viewers-count = 游戏观看人数
推荐
video-title = 推荐视频名称
byline = 推荐游戏类别
热门直播
hot-img = 热门直播图片
hot-video-title = 热门视频名称
hot-byline = 热门游戏类别
hot-metadata = 观看人数
hot-button = 热门下一页
work to game
work-thumbnail = work展示图片
work-video-title = work视频名称
work-metadata-line = work观看人数
work-ytd-grid-video-renderer = work视频日期
p.p1 { margin: 0; font: 11px Menlo; color: rgba(0, 0, 0, 1) }
span.s1 { font-variant-ligatures: no-common-ligatures }
scrapy爬取youtube游戏模块的更多相关文章
- nodejs爬虫笔记(三)---爬取YouTube网站上的视频信息
思路:通过笔记(二)中代理的设置,已经可以对YouTube的信息进行爬取了,这几天想着爬取网站下的视频信息.通过分析YouTube,发现可以从订阅号入手,先选择几个订阅号,然后爬取订阅号里面的视频分类 ...
- Scrapy爬取美女图片第三集 代理ip(上) (原创)
首先说一声,让大家久等了.本来打算那天进行更新的,可是一细想,也只有我这样的单身狗还在做科研,大家可能没心思看更新的文章,所以就拖到了今天.不过忙了521,522这一天半,我把数据库也添加进来了,修复 ...
- Scrapy爬取美女图片续集 (原创)
上一篇咱们讲解了Scrapy的工作机制和如何使用Scrapy爬取美女图片,而今天接着讲解Scrapy爬取美女图片,不过采取了不同的方式和代码实现,对Scrapy的功能进行更深入的运用.(我的新书< ...
- scrapy爬取海量数据并保存在MongoDB和MySQL数据库中
前言 一般我们都会将数据爬取下来保存在临时文件或者控制台直接输出,但对于超大规模数据的快速读写,高并发场景的访问,用数据库管理无疑是不二之选.首先简单描述一下MySQL和MongoDB的区别:MySQ ...
- Scrapy爬取美女图片 (原创)
有半个月没有更新了,最近确实有点忙.先是华为的比赛,接着实验室又有项目,然后又学习了一些新的知识,所以没有更新文章.为了表达我的歉意,我给大家来一波福利... 今天咱们说的是爬虫框架.之前我使用pyt ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- scrapy爬取西刺网站ip
# scrapy爬取西刺网站ip # -*- coding: utf-8 -*- import scrapy from xici.items import XiciItem class Xicispi ...
- scrapy爬取豆瓣电影top250
# -*- coding: utf-8 -*- # scrapy爬取豆瓣电影top250 import scrapy from douban.items import DoubanItem class ...
- scrapy爬取极客学院全部课程
# -*- coding: utf-8 -*- # scrapy爬取极客学院全部课程 import scrapy from pyquery import PyQuery as pq from jike ...
随机推荐
- JavaScript输出的两种方式
var a="Hello World" document.write(a) //在网页上输出:Hello World var a="Hello World" c ...
- golang中接口对象的转型
接口对象的转型有两种方式: 1. 方式一:instance,ok:=接口对象.(实际类型) 如果该接口对象是对应的实际类型,那么instance就是转型之后对象,ok的值为true 配合if...el ...
- 查看Linux系统信息
1.查看内核 [root@localhost etc]# uname -aLinux localhost.localdomain 3.10.0-514.el7.x86_64 #1 SMP Tue No ...
- Power Apps 创建响应式布局
前言 我们都知道Power Apps作为低代码平台,最大的优势就是各个设备之间的兼容性,尤其是自带的响应式布局,非常好用. 这不,我们就为大家分享一下,如何使用Power Apps画布应用,创建响应式 ...
- 实际工程中加快 Java 代码编写的小提示
这里我简单谈谈 Java 语法在编程效率方面的弱势,以及如何补救. 一.集合的快速创建 C# 是少数拥有集合字面值(又叫初始化表达式)的静态语言之一. var list = new List<i ...
- halcon视觉入门钢珠识别
halcon视觉入门钢珠识别 经过入门篇,我们有了基础的视觉识别知识.现在加以应用. 有如下图片: 我们需要识别图片中比较明亮的中间区域,有黑色的钢珠,我们需要知道他的位置和面积. 分析如何识别 编写 ...
- ABC222 部分简要题解
G 这个问题不好直接做,考虑转化为一个好求的问题. 原问题等价于求最小的 \(x\) 使得(或判断无解): \[\begin{aligned} \frac{2}{9}(10 ^ x - 1) & ...
- JS Map与Set
笔记整理自:廖雪峰老师的JS教程 Map JavaScript的对象有个小问题,就是键必须是字符串.但实际上Number或者其他数据类型作为键也是非常合理的. 为了解决这个问题,最新的ES6规范引入了 ...
- Nodejs中调用系统命令、Shell脚本的方法和实例
每种语言都有自己的优势,互相结合起来各取所长程序执行起来效率更高或者说哪种实现方式较简单就用哪个,nodejs是利用子进程来调用系统命令或者文件,文档见http://nodejs.org/api/ch ...
- node.js中的fs.appendFile方法使用说明
方法说明: 该方法以异步的方式将 data 插入到文件里,如果文件不存在会自动创建.data可以是任意字符串或者缓存. 语法: 代码如下: fs.appendFile(filename, data, ...