深入MySQL(四):MySQL的SQL查询语句性能优化概述
关于SQL查询语句的优化,有一些一般的优化步骤,本节就介绍一下通用的优化步骤。
一条查询语句是如何执行的
首先,我们如果要明白一条查询语句所运行的过程,这样我们才能针对过程去进行优化。
参考我之前画的一张MySQL基础架构图:
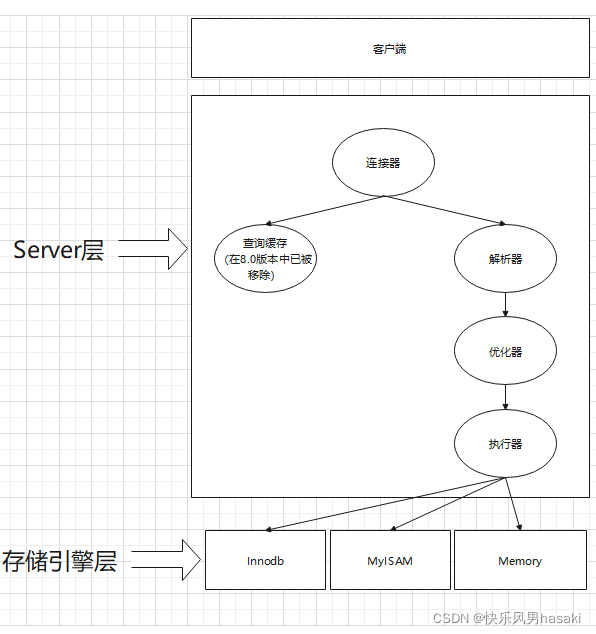
MySQL中一条查询语句的生命周期大概可以分为
- 客户端通过连接器连接服务器
- 在解析器中解析SQL语句
- 优化器进行优化
- 执行器执行生成的执行计划
- 返回结果给客户端
一般而言,执行器执行阶段是最为重要的阶段,也就是说,最耗费性能的阶段。所以我们的优化,其实就是在优化执行器的执行计划。
如何发现与解决慢查询
查询性能低下的原因是因为访问的数据量太大,使得一个查询很慢,那么我们如何发现并且解决慢查询呢。
慢查询日志
MySQL中有一个日志叫做慢查询日志SLOW_QUERY_LOG,它会记录该MySQL中响应时间超过阈值(long_query_time)的语句,慢查询日志默认不开启,并且默认阈值为10,如果是在线上环境的话不建议开启慢查询日志,有调优需要的时候在开启比较合适。
mysql> show variables like '%slow_query_log%';
+---------------------+-------------------------------------------------+
| Variable_name | Value |
+---------------------+-------------------------------------------------+
| slow_query_log | OFF |
| slow_query_log_file | /var/lib/mysql/iZwz9iiwojnmkotgajxjlqZ-slow.log |
+---------------------+-------------------------------------------------+
2 rows in set (0.01 sec)
mysql> set global slow_query_log=1;
Query OK, 0 rows affected (0.00 sec)
使用set global slow_query_log=1开启慢查询在重启MySQL之后会失效,如果要一直生效的话,那么就需要修改配置文件my.cnf。
slow_query_log_file就可以看到你所存储的慢查询日志的位置,我们首先执行语句:
mysql> select sleep(12);
+-----------+
| sleep(12) |
+-----------+
| 0 |
+-----------+
1 row in set (12.00 sec)
然后进入/var/lib/mysql/iZwz9iiwojnmkotgajxjlqZ-slow.log
/usr/sbin/mysqld, Version: 8.0.27-0ubuntu0.20.04.1 ((Ubuntu)). started with:
Tcp port: 3306 Unix socket: /var/run/mysqld/mysqld.sock
Time Id Command Argument
# Time: 2022-02-04T08:27:51.234016Z
# User@Host: root[root] @ localhost [] Id: 1653
# Query_time: 12.001395 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 1
SET timestamp=1643963259;
select sleep(12);
我们就可以看到,一条慢查询已经记录到慢查询日志中,然后我们可以根据后面会提到的正常的优化步骤进行逐步优化。
注:因为我本身专注后端,MySQL的慢查询日志这里只是简单使用,其实慢查询日志还有很多其他的参数,同时还有多种MySQL日志分析工具可以协助,等到以后如果有需要的时候,我会专门出一章来讲述MySQL日志分析工具的使用。
通用的优化思路
SQL语句的优化有一些通用的思路,这里一一介绍一下。
尽量不获取不需要的数据
有些时候,查询会请求超过实际需要的数据,然后在应用程序中丢弃多余数据,这样会给MySQL服务器带来额外的负担,并且增加网络开销,损耗应用服务器的CPU和内存资源。
典型的场景:
- 查询不需要的数据
- 多表关联时返回全部列
- 总是取出全部列
- 重复查询相同的数据
总结而言,我认为其实就是分为两点:
- 慎用SELECT * FROM
- 只取出需要的字段
减少MySQL扫描的额外记录行数
对于MySQL的查询语句而言,其返回的数据行和扫描的数据行是不同的,我们可以用一个很简单的例子来说明:
这是一张利用存储过程生成了100w条数据的数据表
其中索引有这些:

我们执行一条查询SQL语句:
mysql> EXPLAIN SELECT * from user where account = 12345;
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
| 1 | SIMPLE | user | NULL | ref | test | test | 4 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
EXPLAIN待会再解释,大家只要知道该关键字可以看到大致扫描行数即可。
可以看到扫描行数为1行,返回的行数也是一行。
我们删除掉‘test’索引,再来执行同样的语句:
mysql> EXPLAIN SELECT * from user where account = 12345;
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | user | NULL | ALL | NULL | NULL | NULL | NULL | 991536 | 10.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
可以看到,我们的扫描行数非常大,是一个全表扫描,但是我们返回的行数其实是一行,也就是说我们做了大量的无用扫描。
一般MySQL能够使用如下三种方式应用WHERE条件,从好到坏依次为:
- 在索引中使用WHERE条件过滤不匹配的记录。这是在存储引擎完成的。
- 使用覆盖索引扫描返回记录,直接从索引中过滤不需要的记录并返回命中的结果。MySQL的服务层完成的,不需要回表。
- 从数据表中返回数据,然后过滤不满足条件的记录。在MySQL服务器层完成。
重构查询的方式
常见的重构查询的方式有以下几种:
- 将一个复杂查询拆分为多个简单查询
- 切分查询,对大查询分而治之,一次查询一小部分结果
- 分解关联查询
一个复杂查询还是多个简单查询
在传统的实现中,强调在数据库层完成尽可能多的工作,在过去是认为网络通信、查询解析和优化是一件代价很高的事情。
但是MySQL的设计让连接和断开连接都十分轻量级,返回一个小的查询结果方面很高效。MySQL内部每秒能够扫描内存中上百万行数据,相较而言,MySQL响应数据给客户端速度很慢。
所以有的时候可以权衡一下是否需要将一个大查询分解为多个小查询。
切分查询
有时候对于一个大查询分而治之,将一个大查询分解为小查询。每个查询功能完全一样,每次只返回一小部分。
最典型的场景便是删除旧数据,比如要删除100w旧数据,如果一次SQL执行全部删除,那么该SQL语句会执行相当长的过程,同时可能导致锁住大量数据、占满整个事务日志、耗尽系统资源、阻塞其他查询。那么我们可以一次删除1w的旧数据,这样子就可以将删除全部旧数据的性能损耗平摊到一个很长的时间,大大降低对于服务器的影响。
分解关联查询
关于JOIN关键字,很多DBA会直接禁用JOIN语句,原因是JOIN语句可能会扫描大量的行数,在后期的博客中,我会专门总结。简单而言,如果被驱动表上面不能使用索引,那么会直接每次查询被驱动表的时候都进行全表扫描,A JOIN B的扫描行数会直接是A的行数 * B的行数。
所以我们可以将一个JOIN语句拆分成多个简单的查询,然后在应用程序中进行组装。
分解关联查询可以有以下优点:
- 执行单个查询可以减少锁的竞争
- 应用层做关联,更容易对数据库进行拆分,更容易做到高性能和可扩展
- 可以减少冗余记录的查询
- 这种形式相当于在应用层做了哈希关联,很多情况下哈希关联效率高很多
MySQL优化器
MySQL的优化器是一个基于成本的优化器,有些原因会导致MySQL优化器选择错误的执行计划:
- 统计信息不准确。
- 执行计划的成本估计并不等于实际成本。
- MySQL的最优并不只是考虑响应时间。
- MySQL不考虑并发执行的情况。
- MySQL有时候会基于一些固定规则优化。
MySQL能够处理的优化类型有以下:
- 重新定义关联表的顺序
- 将外连接转为内连接
- 使用等价变化规则:比如合并和减少一些比较、移除一些恒等或者不恒等的判断,例如(5=5 AND a>5)会被改写为a>5。
- 优化COUNT()、MIN()、MAX()
- 预估并转化为常数表达式
- 覆盖索引扫描
- 子查询优化
- 提前终止查询:LIMIT、发现一个不成立的条件。
- 等值传播:使用USING的时候,不用重复声明两个表中相同的字段。
10.列表IN()的比较:MySQL中的IN()是将列表中的数据先排序,然后二分查询。
EXPLAIN关键字的应用
EXPLAIN关键字对于经常进行SQL语句优化的同学肯定很熟悉,我在这里简单介绍一下,EXPLAIN是显示该SQL语句的预计执行计划,是否使用索引、中间表、排序等,以及预计扫描行数等数据。
尾言
以上便是MySQL的SQL查询语句性能优化的概述,后期将会针对以下问题出针对性的博客进行具体场景的优化:
- 优化COUNT()查询
- 优化LIMIT分页
- 关联语句的优化
- 排序的优化
以及EXPLAIN的详解、常见的优化失效的情况,以及如何解决。
深入MySQL(四):MySQL的SQL查询语句性能优化概述的更多相关文章
- Mysql常用30种SQL查询语句优化方法
出处:http://www.antscode.com/article/12deee70111da0c4.html 1.应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使 ...
- MySQL 常用30种SQL查询语句优化方法
1.应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描. 2.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉 ...
- 一次SQL查询语句的优化
1.项目中之前的"我关注的拍品列表"需要添加筛选功能,因为目前显示的关注的拍品太多没有进行分类,用户体验差. 2.添加筛选条件之后,可以筛选出“未开始”“进行中”“已结束”三种情况 ...
- 转: 从Mysql某一表中随机读取n条数据的SQL查询语句
若要在i ≤ R ≤ j 这个范围得到一个随机整数R ,需要用到表达式 FLOOR(i + RAND() * (j – i + 1)).例如, 若要在7 到 12 的范围(包括7和12)内得到一个随机 ...
- MySQL 笔记整理(2) --日志系统,一条SQL查询语句如何执行
笔记记录自林晓斌(丁奇)老师的<MySQL实战45讲> 2) --日志系统,一条SQL查询语句如何执行 MySQL可以恢复到半个月内任意一秒的状态,它的实现和日志系统有关.上一篇中记录了一 ...
- MySQL 笔记整理(1) --基础架构,一条SQL查询语句如何执行
最近在学习林晓斌(丁奇)老师的<MySQL实战45讲>,受益匪浅,做一些笔记整理一下,帮助学习.如果有小伙伴感兴趣的话推荐原版课程,很不错. 1) --基础架构,一条SQL查询语句如何执行 ...
- 从Mysql某一表中随机读取n条数据的SQL查询语句
若要在i ≤ R ≤ j 这个范围得到一个随机整数R ,需要用到表达式 FLOOR(i + RAND() * (j – i + 1)).例如, 若要在7 到 12 的范围(包括7和12)内得到一个随机 ...
- MySQL数据库详解(一)执行SQL查询语句时,其底层到底经历了什么?
一条SQL查询语句是如何执行的? 前言 大家好,我是WZY,今天我们学习下MySQL的基础框架,看一件事千万不要直接陷入细节里,你应该先鸟瞰其全貌,这样能够帮助你从高维度理解问题.同样,对于MyS ...
- mysql数据库系统学习(一)---一条SQL查询语句是如何执行的?
本文基于----MySQL实战45讲(极客时间----林晓斌 )整理----->https://time.geekbang.org/column/article/68319 一.第一节:一条sq ...
随机推荐
- SpringMVC拦截器的应用
一.作用 好文章参考:https://www.cnblogs.com/panxuejun/p/7715917.html 对请求进行预处理和后处理: 使用场景: 登录验证,判断用户是否登录 权限验证,判 ...
- Nginx虚拟主机、日志排错、模块配置
目录 Nginx虚拟主机 1. 基于多IP的方式 2. 基于多端口的方式 3. 基于多域名的方式 Nginx日志 Nginx配置文件配置项 Nginx模块 Nginx访问控制模块 Nginx状态监控模 ...
- session反序列化
先来了解一下关于session的一些基础知识 什么是session?在计算机中,尤其是在网络应用中,称为"会话控制".Session 对象存储特定用户会话所需的属性及配置信息.这样 ...
- Selenium2+python自动化65-js定位几种方法总结
Selenium2+python自动化65-js定位几种方法总结 前言 本篇总结了几种js常用的定位元素方法,并用js点击按钮,对input输入框输入文本 一.以下总结了5种js定位的方法 除了i ...
- 微信小程序云开发框架
概述 一直做后端服务器开发,最近看了一篇文章介绍小程序的云开发模式,觉得挺有意思,就尝试了一下,由本文做个记录. 因为不是专业的小程序开发人员,也没有做过网页开发,所以论述中出现错误难以避免,请多谅解 ...
- 定位new
常规的new是分配内存,然后调用相应的构造函数,而定位new是在已经分配内存的上面调用构造函数: // ConsoleApplication7.cpp : 定义控制台应用程序的入口点. #includ ...
- Python如何把八进制转换成ASCII码
做题途中拿到一串八进制字符串 0126 062 0126 0163 0142 0103 0102 0153 0142 062 065 0154 0111 0121 0157 0113 0111 010 ...
- java多线程中同步的问题?
一.通过模拟网络延迟,解决同步的问题. package com.zxf.demo; public class G01 implements Runnable{ private int num=10; ...
- 如何使用自对弈强化学习训练一个五子棋机器人Alpha Gobang Zero
前言 2016年3月,Alpha Go 与围棋世界冠军.职业九段棋手李世石进行围棋人机大战,以4比1的总比分获胜,在当时引起了轩然大波.2017年10月,谷歌公布了新版五子棋程序 AlphaGo Ze ...
- LeetCode673
LeetCode每日一题2021.9.20 LeetCode673. 最长递增子序列的个数 思路 在最长上升子序列的转移时,维护一个 cnt 数组,表示 以 i 结尾的最长上升子序列个数 f[i] 表 ...