Map 实现类之一:HashMap
Map 实现类之一:HashMap
HashMap是 Map 接口 使用频率最高的实现类。
允许使用null键和null值,与HashSet一样,不保证映射的顺序。
所有的key构成的集合是Set:无序的、不可重复的。所以,key所在的类要重写:
equals()和hashCode()
所有的value构成的集合是Collection:无序的、可以重复的。所以,value所在的类
要重写:equals()
一个key-value构成一个entry
所有的entry构成的集合是Set:无序的、不可重复的
HashMap 判断两个 key 相等的标准是:两个 key 通过 equals() 方法返回 true,
hashCode 值也相等。
HashMap 判断两个 value 相等的标准是:两个 value 通过 equals() 方法返回 true。

HashMap 源码中的重要常量
DEFAULT_INITIAL_CAPACITY : HashMap的默认容量,16
MAXIMUM_CAPACITY : : HashMap的最大支持容量,2^30
DEFAULT_LOAD_FACTOR :HashMap的默认加载因子
TREEIFY_THRESHOLD :Bucket中链表长度大于该默认值,转化为红黑树
UNTREEIFY_THRESHOLD :Bucket中红黑树存储的Node小于该默认值,转化为链表
MIN_TREEIFY_CAPACITY :桶中的Node被树化时最小的hash表容量。(当桶中Node的
数量大到需要变红黑树时,若hash表容量小于MIN_TREEIFY_CAPACITY时,此时应执行
resize扩容操作这个MIN_TREEIFY_CAPACITY的值至少是TREEIFY_THRESHOLD的4
倍。)
table :存储元素的数组,总是2的n次幂
entrySet: :存储具体元素的集
size :HashMap中存储的键值对的数量
modCount :HashMap扩容和结构改变的次数。
threshold :扩容的临界值,=容量*填充因子
loadFactor: :填充因子

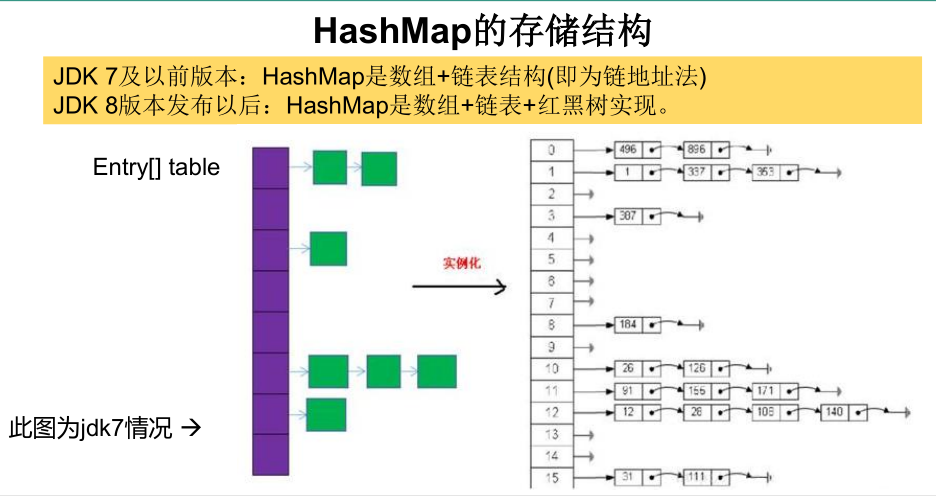
HashMap 的存储: 结构:JDK 1.8 之前
HashMap的内部存储结构其实是 数组和链表的结合。当实例化一个HashMap时,
系统会创建一个长度为Capacity的Entry数组,这个长度在哈希表中被称为容量
(Capacity),在这个数组中可以存放元素的位置我们称之为“桶”(bucket),每个
bucket都有自己的索引,系统可以根据索引快速的查找bucket中的元素。
每个bucket中存储一个元素,即一个Entry对象,但每一个Entry对象可以带一个引
用变量,用于指向下一个元素,因此,在一个桶中,就有可能生成一个Entry链。
而且新添加的元素作为链表的head。
添加元素的过程:
向HashMap中添加entry1(key,value),需要首先计算entry1中key的哈希值(根据
key所在类的hashCode()计算得到),此哈希值经过处理以后,得到在底层Entry[]数
组中要存储的位置i。如果位置i上没有元素,则entry1直接添加成功。如果位置i上
已经存在entry2(或还有链表存在的entry3,entry4),则需要通过循环的方法,依次
比较entry1中key和其他的entry。如果彼此hash值不同,则直接添加成功。如果
hash值不同,继续比较二者是否equals。如果返回值为true,则使用entry1的value
去替换equals为true的entry的value。如果遍历一遍以后,发现所有的equals返回都
为false,则entry1仍可添加成功。entry1指向原有的entry元素。
HashMap 的扩容
当HashMap中的元素越来越多的时候,hash冲突的几率也就越来越高,因为数组的
长度是固定的。所以为了提高查询的效率,就要对HashMap的数组进行扩容,而在
HashMap数组扩容之后,最消耗性能的点就出现了:原数组中的数据必须重新计算
其在新数组中的位置,并放进去,这就是resize。
那么HashMap 什么时候进行扩容呢 ?
当HashMap中的元素个数超过数组大小(数组总大小length,不是数组中个数
size)*loadFactor 时 , 就 会 进 行 数 组 扩 容 , loadFactor 的 默 认 值
(DEFAULT_LOAD_FACTOR)为0.75,这是一个折中的取值。也就是说,默认情况
下,数组大小(DEFAULT_INITIAL_CAPACITY)为16,那么当HashMap中元素个数
超过16*0.75=12(这个值就是代码中的threshold值,也叫做临界值)的时候,就把
数组的大小扩展为 2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,
而这是一个非常消耗性能的操作,所以如果我们已经预知HashMap中元素的个数,
那么预设元素的个数能够有效的提高HashMap的性能。
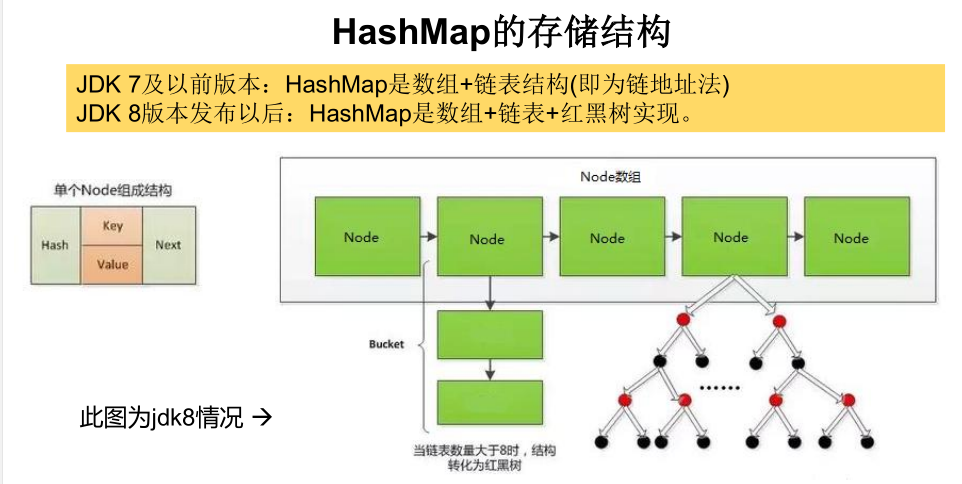
HashMap 的存储: 结构:JDK 1.8
HashMap的内部存储结构其实是 数组+ 链表+ 树 的结合。当实例化一个
HashMap时,会初始化initialCapacity和loadFactor,在put第一对映射关系
时,系统会创建一个长度为initialCapacity的Node数组,这个长度在哈希表
中被称为容量(Capacity),在这个数组中可以存放元素的位置我们称之为
“桶”(bucket),每个bucket都有自己的索引,系统可以根据索引快速的查
找bucket中的元素。
每个bucket中存储一个元素,即一个Node对象,但每一个Node对象可以带
一个引用变量next,用于指向下一个元素,因此,在一个桶中,就有可能
生成一个Node链。也可能是一个一个TreeNode对象,每一个TreeNode对象
可以有两个叶子结点left和right,因此,在一个桶中,就有可能生成一个
TreeNode树。而新添加的元素作为链表的last,或树的叶子结点。
那么HashMap 什么时候进行扩容和树形化呢 ?
当HashMap中的元素个数超过数组大小(数组总大小length,不是数组中个数
size)*loadFactor 时 , 就 会 进 行 数 组 扩 容 , loadFactor 的 默 认 值
(DEFAULT_LOAD_FACTOR)为0.75,这是一个折中的取值。也就是说,默认
情况下,数组大小(DEFAULT_INITIAL_CAPACITY)为16,那么当HashMap中
元素个数超过16*0.75=12(这个值就是代码中的threshold值,也叫做临界值)
的时候,就把数组的大小扩展为 2*16=32,即扩大一倍,然后重新计算每个元
素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知
HashMap中元素的个数,那么预设元素的个数能够有效的提高HashMap的性能。
当HashMap中的其中一个链的对象个数如果达到了8个,此时如果capacity没有
达到64,那么HashMap会先扩容解决,如果已经达到了64,那么这个链会变成
树,结点类型由Node变成TreeNode类型。当然,如果当映射关系被移除后,
下次resize方法时判断树的结点个数低于6个,也会把树再转为链表。

代码测试学习:
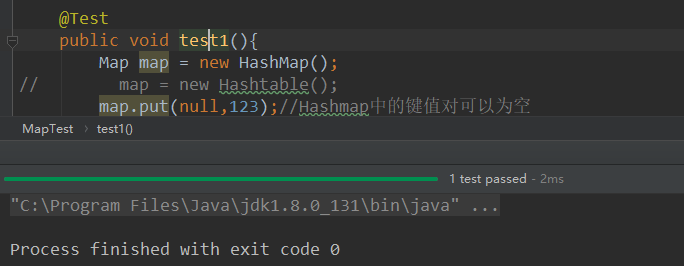
@Test
public void test1(){
Map map = new HashMap();
// map = new Hashtable();
map.put(null,123);//Hashmap中的键值对可以为空 }
无报错:
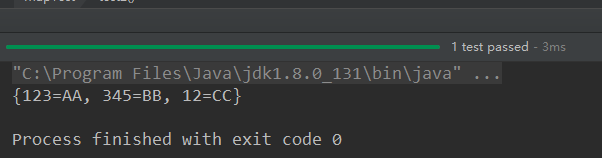
@Test
public void test2(){
Map map = new HashMap();
map = new LinkedHashMap();
map.put(123,"AA");
map.put(345,"BB");
map.put(12,"CC"); System.out.println(map);
}
/*
添加、删除、修改操作:
Object put(Object key,Object value):将指定key-value添加到(或修改)当前map对象中
void putAll(Map m):将m中的所有key-value对存放到当前map中
Object remove(Object key):移除指定key的key-value对,并返回value
void clear():清空当前map中的所有数据
*/
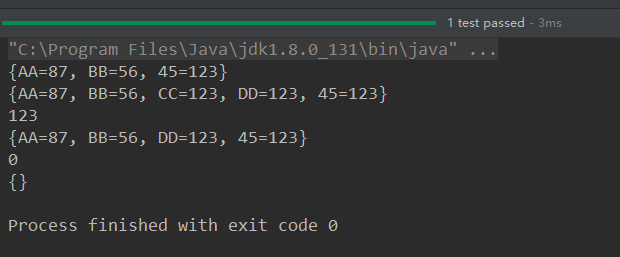
@Test
public void test3(){
Map map = new HashMap();
//添加
map.put("AA",123);
map.put(45,123);
map.put("BB",56);
//修改
map.put("AA",87); System.out.println(map); Map map1 = new HashMap();
map1.put("CC",123);
map1.put("DD",123); map.putAll(map1); System.out.println(map); //remove(Object key)
Object value = map.remove("CC");
System.out.println(value);
System.out.println(map); //clear()
map.clear();//与map = null操作不同
System.out.println(map.size());
System.out.println(map);
}
/*
元素查询的操作:
Object get(Object key):获取指定key对应的value
boolean containsKey(Object key):是否包含指定的key
boolean containsValue(Object value):是否包含指定的value
int size():返回map中key-value对的个数
boolean isEmpty():判断当前map是否为空
boolean equals(Object obj):判断当前map和参数对象obj是否相等
*/
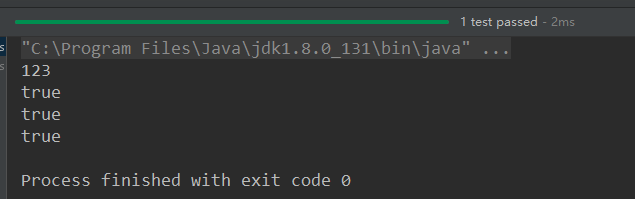
@Test
public void test4(){
Map map = new HashMap();
map.put("AA",123);
map.put(45,123);
map.put("BB",56);
// Object get(Object key)
System.out.println(map.get(45));
//containsKey(Object key)
boolean isExist = map.containsKey("BB");
System.out.println(isExist); isExist = map.containsValue(123);
System.out.println(isExist); map.clear(); System.out.println(map.isEmpty()); }
/*
元视图操作的方法:
Set keySet():返回所有key构成的Set集合
Collection values():返回所有value构成的Collection集合
Set entrySet():返回所有key-value对构成的Set集合
*/
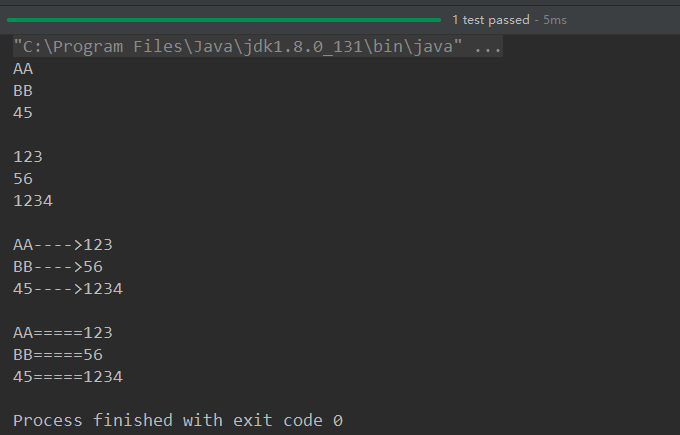
@Test
public void test5(){
Map map = new HashMap();
map.put("AA",123);
map.put(45,1234);
map.put("BB",56); //遍历所有的key集:keySet()
Set set = map.keySet();
Iterator iterator = set.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
System.out.println();
//遍历所有的value集:values()
Collection values = map.values();
for(Object obj : values){
System.out.println(obj);
}
System.out.println();
//遍历所有的key-value
//方式一:entrySet()
Set entrySet = map.entrySet();
Iterator iterator1 = entrySet.iterator();
while (iterator1.hasNext()){
Object obj = iterator1.next();
//entrySet集合中的元素都是entry
Map.Entry entry = (Map.Entry) obj;
System.out.println(entry.getKey() + "---->" + entry.getValue()); }
System.out.println();
//方式二:
Set keySet = map.keySet();
Iterator iterator2 = keySet.iterator();
while(iterator2.hasNext()){
Object key = iterator2.next();
Object value = map.get(key);
System.out.println(key + "=====" + value); } }
Map 实现类之一:HashMap的更多相关文章
- Java 数据类型:集合接口Map:HashTable;HashMap;IdentityHashMap;LinkedHashMap;Properties类读取配置文件;SortedMap接口和TreeMap实现类:【线程安全的ConcurrentHashMap】
Map集合java.util.Map Map用于保存具有映射关系的数据,因此Map集合里保存着两个值,一个是用于保存Map里的key,另外一组值用于保存Map里的value.key和value都可以是 ...
- Java中List,ArrayList、Vector,map,HashTable,HashMap区别用法
Java中List,ArrayList.Vector,map,HashTable,HashMap区别用法 标签: vectorhashmaplistjavaiteratorinteger ArrayL ...
- 常用Map实现类对比
翻译人员: 铁锚 翻译时间: 2013年12月12日 原文链接: HashMap vs. TreeMap vs. Hashtable vs. LinkedHashMap Map 是最常用的数据结构之一 ...
- 利用JSON将Map转换为类对象
Map类型做为一种常见的Java类型,经常在开发过程中使用,笔者最近遇到要将Map对象做为一种通用的参数变量,下传到多个业务类方法中,然后在各个业务类方法中将Map转换为指定类对象的情况.如何将Map ...
- Java容器类List、ArrayList、Vector及map、HashTable、HashMap的区别与用法
Java容器类List.ArrayList.Vector及map.HashTable.HashMap的区别与用法 ArrayList 和Vector是采用数组方式存储数据,此数组元素数大于实际存储的数 ...
- ava:Map借口及其子类HashMap三
ava:Map借口及其子类HashMap三 HashMap常用子类(异步非安全线程,性能高: Hashtable:同步的安全线程,性能低) map(HashMap)中的key,value可以通过 Se ...
- Java并发包——线程安全的Map相关类
Java并发包——线程安全的Map相关类 摘要:本文主要学习了Java并发包下线程安全的Map相关的类. 部分内容来自以下博客: https://blog.csdn.net/bill_xiang_/a ...
- java 实体对象转Map公共类
java 实体对象转Map公共类 package org.kxtkx.portal.utils; import java.lang.reflect.Field; import java.util.Ha ...
- java:Map借口及其子类HashMap五,identityHashMap子类
java:Map借口及其子类HashMap五,identityHashMap子类 了解:identityHashMap子类 一般情况下,标准的Map,是不会有重复的key值得value的,相同的key ...
随机推荐
- 创建ortools的Dockerfile
技术背景 基于已有的Docker容器镜像,去创建一个本地的镜像,有两种方法:一种是在之前的博客中提到过的,使用docker commit的方案,也就是先进去基础系统镜像内部完成所需的修改,然后comm ...
- MyBatis-Plus Generator自定义模板
相信大家在开发过程中,应该都用过Mybatis-Plus的Generator,但是可能没有自定义过模板并使用. 每个项目都应该有一个从Controller层到Mapper层的通用模板,来去掉哪些简单的 ...
- CI/CD版本回滚Jenkins解决方案
一.创建项目 填写项目名,关系到项目路径对应请谨慎命名 二.项目配置 1.配置字符串参数和选项参数 2.代码仓库配置 3.构建环境 4.构筑脚本配置 5.点击左下方的保存或者应用 三.使用方法 1.发 ...
- Shell中的(),{}几种语法用法-单独总结
shell中的(),{}几种语法用法 查看脚本语法是否有错误: bash -n modify_suffix.sh 跟踪执行 sh -x modify_suffix.sh aaa 1. ${var} 2 ...
- for what? while 与 until 差在哪?-- Shell十三问<第十三问>
for what? while 与 until 差在哪?-- Shell十三问<第十三问> 最后要介绍的是 shell script 设计中常见的"循环"(loop). ...
- [Fundamental of Power Electronics]-PART II-9. 控制器设计-9.2 负反馈对网络传递函数的影响
9.2 负反馈对网络传递函数的影响 我们已经知道了如何推导开关变换器的交流小信号传递函数.例如,buck变换器的等效电路模型可以表示为图9.3所示.这个等效电路包含三个独立输入:控制输入变量\(\ha ...
- 死磕Spring之AOP篇 - Spring AOP常见面试题
该系列文章是本人在学习 Spring 的过程中总结下来的,里面涉及到相关源码,可能对读者不太友好,请结合我的源码注释 Spring 源码分析 GitHub 地址 进行阅读. Spring 版本:5.1 ...
- leetcode 刷题(数组篇)11题 盛最多水的容器(双指针)
题目描述 给你 n 个非负整数 a1,a2,...,an,每个数代表坐标中的一个点 (i, ai) .在坐标内画 n 条垂直线,垂直线 i 的两个端点分别为 (i, ai) 和 (i, 0) .找出其 ...
- 迷宫问题(BFS)
给定一个n* m大小的迷宫,其中* 代表不可通过的墙壁,而"."代表平地,S表示起点,T代表终点.移动过程中,如果当前位置是(x, y)(下标从0开始),且每次只能前往上下左右.( ...
- 【CTF】Pwn入门 XCTF 部分writeup
碎碎念 咕咕咕了好久的Pwn,临时抱佛脚入门一下. 先安利之前看的一个 Reverse+Pwn 讲解视频 讲的还是很不错的,建议耐心看完 另外感觉Reverse和Pwn都好难!! 不,CTF好难!! ...