详解Apache Dubbo的SPI实现机制
一、SPI
SPI全称为Service Provider Interface,对应中文为服务发现机制。SPI类似一种可插拔机制,首先需要定义一个接口或一个约定,然后不同的场景可以对其进行实现,调用方在使用的时候无需过多关注具体的实现细节。在Java中,SPI体现了面向接口编程的思想,满足开闭设计原则。
1.1 JDK自带SPI实现
从JDK1.6开始引入SPI机制后,可以看到很多使用SPI的案例,比如最常见的数据库驱动实现,在JDK中只定义了java.sql.Driver的接口,具体实现由各数据库厂商来提供。下面一个简单的例子来快速了解下Java SPI的使用方式:
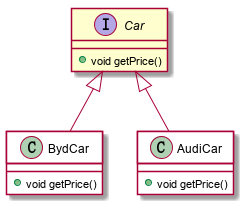
1)定义一个接口
package com.vivo.study
public interface Car {
void getPrice();
}
2)接口实现
package com.vivo.study.impl
/**
* 实现一
*
*/
public class AudiCar implements Car {
@Override
public void getPrice() {
System.out.println("Audi A6L's price is 500000 RMB.");
}
}
package com.vivo.study.impl
/**
* 实现二
*
*/
public class BydCar implements Car {
@Override
public void getPrice() {
System.out.println("BYD han's price is 220000 RMB.");
}
}
3)挂载扩展类信息
在META-INF/services目录下以接口全名为文件名的文本文件,对应此处即在META-INF/services目录下创建一个文件名为com.vivo.study.Car的文件,文件内容如下:
com.vivo.study.impl.AudiCar
com.vivo.study.impl.BydCar
4)使用
public class SpiDemo {
public static void main(String[] args) {
ServiceLoader<Car> load = ServiceLoader.load(Car.class);
Iterator<Car> iterator = load.iterator();
while (iterator.hasNext()) {
Car car = iterator.next();
car.getPrice();
}
}
}
上面的例子简单的介绍了JDK SPI机制的使用方式,其中最关键的类为ServiceLoader,通过ServiceLoader类来加载接口的实现类,ServiceLoader是Iterable接口的实现类,对于ServiceLoader加载的详细过程此处不展开。
JDK对SPI的加载实现存在一个较为突出的小缺点,无法按需加载实现类,通过ServiceLoader.load加载时会将文件中的所有实现都进行实例化,如果想要获取具体某个具体的实现类需要进行遍历判断。
1.2 Dubbo SPI
SPI扩展是Dubbo的最大的优点之一,支持协议扩展、调用拦截扩展、引用监听扩展等等。在Dubbo中,根据不同的扩展定位,扩展文件分别被放置在META-INF/dubbo/internal/,META-INF/dubbo/,META-INF/services/这三个路径下。
Dubbo中有直接使用JDK SPI实现的方式,比如org.apache.dubbo.common.extension.LoadingStrategy放在META-INF/services/路径下,但大多情况下都是使用其自身对JDK SPI的实现的一种优化方式,可称为Dubbo SPI,也就是本文要讲解的点。
相比于JDK的SPI的实现,Dubbo SPI具有以下特点:
配置形式更灵活:支持以key:value的形式在文件里配置类似name:xxx.xxx.xxx.xx,后续可以通过name来进行扩展类按需精准获取。
缓存的使用:使用缓存提升性能,保证一个扩展实现类至多会加载一次。
对扩展类细分扩展:支持扩展点自动包装(Wrapper)、扩展点自动装配、扩展点自适应(@Adaptive)、扩展点自动激活(@Activate)。
Dubbo对扩展点的加载主要由ExtensionLoader这个类展开。
二、加载-ExtensionLoader
ExtensionLoader在Dubbo里的角色类似ServiceLoader在JDK中的存在,用于加载扩展类。在Dubbo源码里,随处都可以见到ExtensionLoader的身影,比如在服务暴露里的关键类ServiceConfig中等,弄清楚ExtensionLoader的实现细节对阅读Dubbo源码有很大的帮助。
2.1 获取ExtensionLoader的实例
ExtensionLoader没有提供共有的构造函数,
只能通过ExtensionLoader.getExtensionLoader(Class type)来获取ExtensionLoader实例。
public
// ConcurrentHashMap缓存,key -> Class value -> ExtensionLoader实例
private static final ConcurrentMap<Class<?>, ExtensionLoader<?>> EXTENSION_LOADERS = new ConcurrentHashMap<>(64);
private ExtensionLoader(Class<?> type) {
this.type = type;
objectFactory = (type == ExtensionFactory.class ? null : ExtensionLoader.getExtensionLoader(ExtensionFactory.class).getAdaptiveExtension());
}
public static <T> ExtensionLoader<T> getExtensionLoader(Class<T> type) {
if (type == null) {
throw new IllegalArgumentException("Extension type == null");
}
// 检查是否是接口,如果不是则抛出异常
if (!type.isInterface()) {
throw new IllegalArgumentException("Extension type (" + type + ") is not an interface!");
}
// 检查接口是否是被@SPI注解修饰,如果没有则抛出异常
if (!withExtensionAnnotation(type)) {
throw new IllegalArgumentException("Extension type (" + type +
") is not an extension, because it is NOT annotated with @" + SPI.class.getSimpleName() + "!");
}
// 从缓存里取,没有则初始化一个并放入缓存EXTENSION_LOADERS中
ExtensionLoader<T> loader = (ExtensionLoader<T>) EXTENSION_LOADERS.get(type);
if (loader == null) {
EXTENSION_LOADERS.putIfAbsent(type, new ExtensionLoader<T>(type));
loader = (ExtensionLoader<T>) EXTENSION_LOADERS.get(type);
}
return loader;
}
}
上面的代码展示了获取ExtensionLoader实例的过程,可以看出,每一个被@SPI修饰的接口都会对应同一个ExtensionLoader实例,且对应ExtensionLoader只会被初始化一次,并缓存在ConcurresntHashMap中。
2.2 加载扩展类
加载扩展类入口,当使用ExtensionLoader时,getExtensionName、getActivateExtension或是getDefaultExtension都要经过getExtensionClasses方法来加载扩展类,如下图;
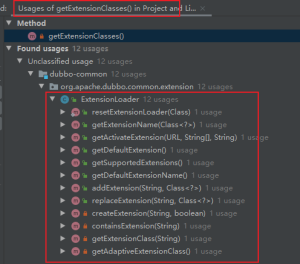
getExtensionClasses方法调用的路径如下图,getExtensionClasses是加载扩展类的一个起点,会首先从缓存中获取,如果缓存中没有则通过loadExtensionClasses方法来加载扩展类,所以说实际上的加载逻辑入口在loadExtensionClasses。
getExtensionClasses
|->loadExtensionClasses
|->cacheDefaultExtensionName
|->loadDirectory
|->loadResource
|->loadClass
2.2.1 loadExtensionClasses加载扩展类
由于整个加载过程设计的源码较多,因此用一个流程图来进行描述,具体细节可以结合源码进行查看。
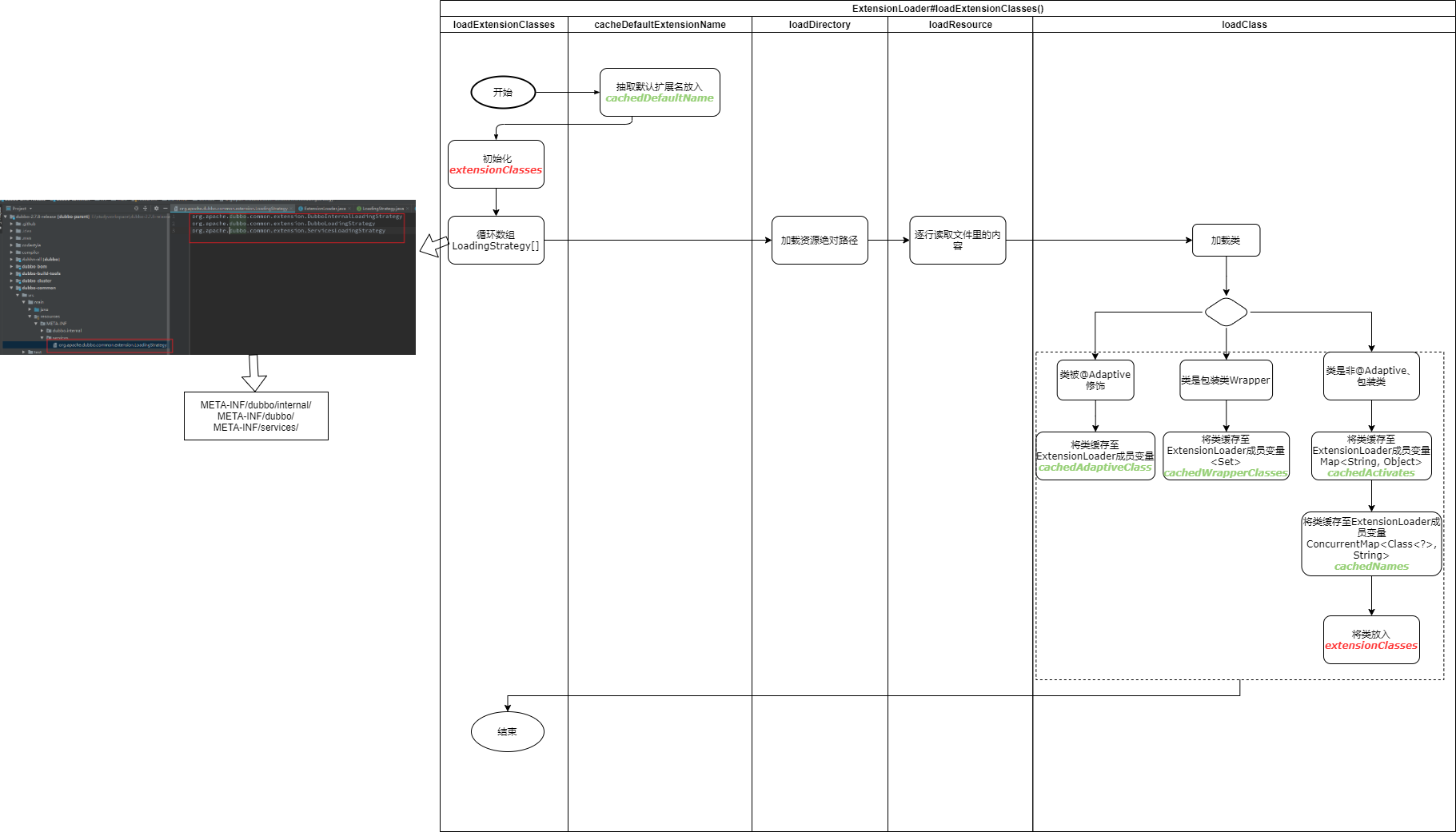
loadExtensionClasses主要做了以下这几件事:
默认扩展名:
抽取默认扩展实现名并缓存在ExtensionLoader里的cachedDefaultName,默认扩展名配置通过@SPI注解在接口上配置,如配置@SPI("defaultName")则默认扩展名为defaultName。
加载扩展类信息:
从META-INF/dubbo/internal/,META-INF/dubbo/,META-INF/services/这三个路径下寻找以类的全路径名命名的文件,并逐行读取文件里的内容。
加载class并缓存:
对扩展类分为自适应扩展实现类(被@Adaptive修饰的实现类)、包装类(拥有一个只有一个为这个接口类型的参数的构造方法)、普通扩展类,其中普通扩展类中又包含自动激活扩展类(被@Activate修饰的类)和真普通的类,对自适应扩展实现类、包装类、自动激活扩展类这三种类型的类分别加载并分别缓存到cachedAdaptiveClass、cachedActivates、cachedWrapperClasses。
返回结果Map<String, Class<?>>:
结果返回Map,其中key对应扩展文件里配置的name,value对应扩展的类class,最后在getExtensionClasses方法里会将此结果放入缓存cachedClasses中。此结果Map中包含除了自适应扩展实现类和包装实现类的其他所用的扩展类名与对应类的映射关系。
通过loadExtensionClasses方法把扩展类(Class对象)都加载到相应的缓存中,是为了方便后面实例化扩展类对象,通过newInstance()等方法来实例化。
2.2.2扩展包装类
什么是扩展包装类?是不是类名结尾包含了Wrapper的类就是扩展包装类?
在Dubbo SPI接口的实现扩展类中,如果此类包含一个此接口作为参数的构造方法,则为扩展包装类。扩展包装类的作用是持有具体的扩展实现类,可以一层一层的被包装,作用类似AOP。
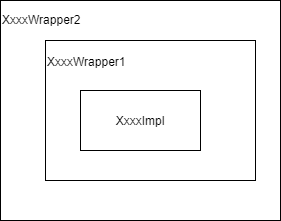
包装扩展类的作用是类似AOP,方便扩展增强。具体实现代码如下:
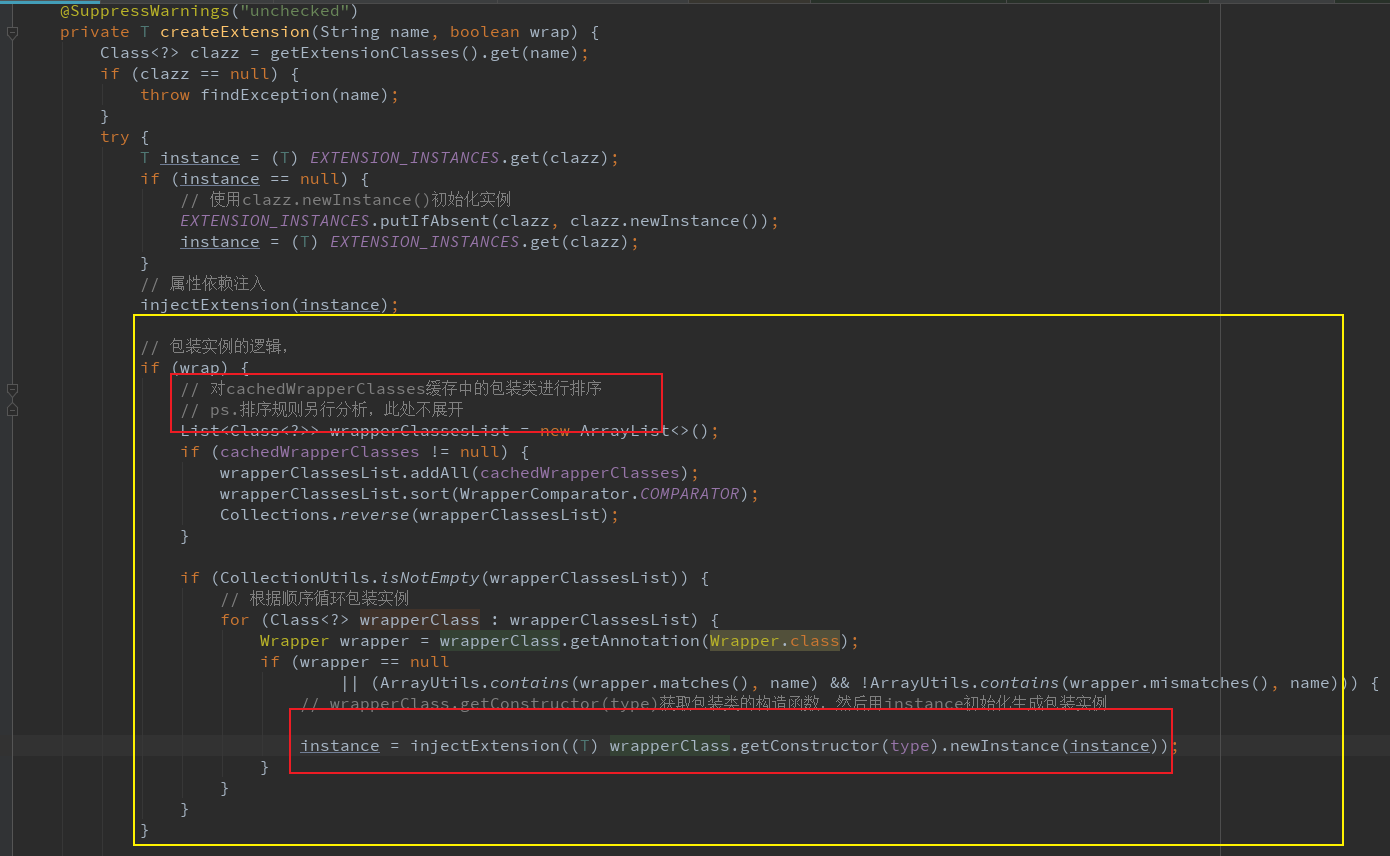
从代码中可以得出,可以通过boolean wrap选择是否使用包装类,默认情况下为true;如果有扩展包装类,实际的实现类会被包装类按一定的顺序一层一层包起来。
如Protocol的实现类ProtocolFilterWrapper、ProtocolListenerWrapper都是扩展包装类。
2.2.3自适应扩展实现类
2.2.3.1 @Adaptive
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE, ElementType.METHOD})
public @interface Adaptive {
String[] value() default {};
}
从源码以及源码注释中可以得出以下几点:
Adaptive是一个注解,可以修饰类(接口,枚举)和方法。
此注解的作用是为ExtensionLoader注入扩展实例提供有用的信息。
从注释中理解value的作用:
value可以决定选择使用具体的扩展类。
通过value配置的值key,在修饰的方法的入参org.apache.dubbo.common.URL中通过key获取到对应的值value,根据value作为extensionName去决定使用对应的扩展类。
如果通过2没有找到对应的扩展,会选择默认的扩展类,通过@SPI配置默认扩展类。
2.2.3.2 @Adaptive简单例子
由于@Adaptive修饰类时比较好理解,这里举一个@Adaptive修饰方法的例子,使用@Adaptive修饰方法的这种情况在Dubbo也是随处可见。
/**
* Dubbo SPI 接口
*/
@SPI("impl1")
public interface SimpleExt {
@Adaptive({"key1", "key2"})
String yell(URL url, String s);
}
如果调用
ExtensionLoader.getExtensionLoader(SimpleExt.class).getAdaptiveExtension().yell(url, s)方法,最终调用哪一个扩展类的实例去执行yell方法的流程大致为:先获取扩展类的名称extName(对应上面说的name:class中的name),然后通过extName来获取对应的类Class,再实例化进行调用。所以关键的步骤在怎么得到extName,上面的这个例子得到extName的流程为:
通过url.getParameters.get("key1")获取,
没有获取到则用url.getParameters.get("key2"),如果还是没有获取到则使用impl1对应的实现类,最后还是没有获取到则抛异常IllegalStateException。
可以看出,@Adaptive的好处就是可以通过方法入参决定具体调用哪一个实现类。下面会对@Adaptive的具体实现进行详细分析。
2.2.3.3 @Adaptive加载流程

流程关键点说明:
1)黄色标记的,cachedAdaptiveClass是在ExtensionLoader#loadClass方法中加载Extension类时缓存的。
2)绿色标记的,如果Extension类中存在被@Adaptive修饰的类时会使用该类来初始化实例。
3)红色标记的,如果Extension类中不存在被@Adaptive修饰的类时,则需要动态生成代码,通过javassist(默认)来编译生成Xxxx$Adaptive类来实例化。
4)实例化后通过injectExtension来将Adaptive实例的Extension注入(属性注入)。
后续围绕上述的关键点3详细展开,关键点4此处不展开。
动态生成Xxx$Adaptive类:下面的代码为动态生成Adaptive类的相关代码,具体生成代码的细节在AdaptiveClassCodeGenerator#generate中
public class ExtensionLoader<T> {
// ...
private Class<?> getAdaptiveExtensionClass() {
// 根据对应的SPI文件加载扩展类并缓存,细节此处不展开
getExtensionClasses();
// 如果存在被@Adaptive修饰的类则直接返回此类
if (cachedAdaptiveClass != null) {
return cachedAdaptiveClass;
}
// 动态生成Xxxx$Adaptive类
return cachedAdaptiveClass = createAdaptiveExtensionClass();
}
private Class<?> createAdaptiveExtensionClass() {
// 生成Xxxx$Adaptive类代码,可自行加日志或断点查看生成的代码
String code = new AdaptiveClassCodeGenerator(type, cachedDefaultName).generate();
ClassLoader classLoader = findClassLoader();
// 获取动态编译器,默认为javassist
org.apache.dubbo.common.compiler.Compiler compiler = ExtensionLoader.getExtensionLoader(org.apache.dubbo.common.compiler.Compiler.class).getAdaptiveExtension();
return compiler.compile(code, classLoader);
}
}
AdaptiveClassCodeGenerator#generate生成code的方式是通过字符串拼接,大量使用String.format,整个代码过程比较繁琐,可通过debug去了解细节。
最关键的的部分是生成被@Adaptive修饰的方法的内容,也就是最终调用实例的@Adaptive方法时,可通过参数来动态选择具体使用哪个扩展实例。下面对此部分进行分析:
public class AdaptiveClassCodeGenerator {
// ...
/**
* generate method content
*/
private String generateMethodContent(Method method) {
// 获取方法上的@Adaptive注解
Adaptive adaptiveAnnotation = method.getAnnotation(Adaptive.class);
StringBuilder code = new StringBuilder(512);
if (adaptiveAnnotation == null) {
// 方法时没有@Adaptive注解,生成不支持的代码
return generateUnsupported(method);
} else {
// 方法参数里URL是第几个参数,不存在则为-1
int urlTypeIndex = getUrlTypeIndex(method);
// found parameter in URL type
if (urlTypeIndex != -1) {
// Null Point check
code.append(generateUrlNullCheck(urlTypeIndex));
} else {
// did not find parameter in URL type
code.append(generateUrlAssignmentIndirectly(method));
}
// 获取方法上@Adaptive配置的value
// 比如 @Adaptive({"key1","key2"}),则会返回String数组{"key1","key2"}
// 如果@Adaptive没有配置value,则会根据简写接口名按驼峰用.分割,比如SimpleExt对应simple.ext
String[] value = getMethodAdaptiveValue(adaptiveAnnotation);
// 参数里是否存在org.apache.dubbo.rpc.Invocation
boolean hasInvocation = hasInvocationArgument(method);
code.append(generateInvocationArgumentNullCheck(method));
// 生成String extName = xxx;的代码 ,extName用于获取具体的Extension实例
code.append(generateExtNameAssignment(value, hasInvocation));
// check extName == null?
code.append(generateExtNameNullCheck(value));
code.append(generateExtensionAssignment());
// return statement
code.append(generateReturnAndInvocation(method));
}
return code.toString();
}
}
上述生成Adaptive类的方法内容中最关键的步骤在生成extName的部分,也就是generateExtNameAssignment(value,hasInvocation),此方法if太多了(有点眼花缭乱)。
以下列举几个例子对此方法的实现流程进行简单展示:假设方法中的参数不包含org.apache.dubbo.rpc.Invocation,包含org.apache.dubbo.rpc.Invocation的情况会更加复杂。
1)方法被@Adaptive修饰,没有配置value,且在接口@SPI上配置了默认的实现
@SPI("impl1")
public interface SimpleExt {
@Adaptive
String echo(URL url, String s);
}
对应生成extName的代码为:
String extName = url.getParameter("simple.ext", "impl1")
2)方法被@Adaptive修饰,没有配置value,且在接口@SPI上没有配置默认的实现
@SPI("impl1")
public interface SimpleExt {
@Adaptive({"key1", "key2"})
String yell(URL url, String s);
}
对应生成extName的代码为:
String extName = url.getParameter( "simple.ext")
3)方法被@Adaptive修饰,配置了value(假设两个,依次类推),且在接口@SPI上配置了默认的实现
@SPI
public interface SimpleExt {
@Adaptive({"key1", "key2"})
String yell(URL url, String s);
}
对应生成extName的代码为:
String extName = url.getParameter("key1", url.getParameter("key2", "impl1"));
4)方法被@Adaptive修饰,配置了value(假设两个,依次类推),且在接口@SPI没有配置默认的实现
@SPI
public interface SimpleExt {
@Adaptive({"key1", "key2"})
String yell(URL url, String s);
}
对应生成extName的代码为:
String extName = url.getParameter("key1", url.getParameter("key2"));
完整的生成类可参见附录。
2.2.4自动激活扩展类
如果你有扩展实现过Dubbo的Filter,那么一定会对@Activate很熟悉。@Activate注解的作用是可以通过给定的条件来自动激活扩展实现类,通过ExtensionLoader#getActivateExtension(URL,String, String)方法可以找到指定条件下需要激活的扩展类列表。
下面以一个例子来对@Activate的作用进行说明,在Consumer调用Dubbo接口时,会经过消费方的过滤器链以及提供方的过滤器链,在Provider暴露服务的过程中会拼接需要使用哪些Filter。
对应源码中的位置在ProtocolFilterWrapper#buildInvokerChain(invoker, key, group)方法中。
// export:key-> service.filter ; group-> provider
private static <T> Invoker<T> buildInvokerChain(final Invoker<T> invoker, String key, String group) {
// 在Provider暴露服务服务export时,会根据获取Url中的service.filter对应的值和group=provider来获取激活对应的Filter
List<Filter> filters = ExtensionLoader.getExtensionLoader(Filter.class).getActivateExtension(invoker.getUrl(), key, group);
}
ExtensionLoader#getActivateExtension(URL, String, String)是怎么根据条件来自动激活对应的扩展类列表的可以自行查看该方法的代码,此处不展开。
三、总结
本文主要对Dubbo SPI机制的扩展类加载过程通过ExtensionLoader类源码来进行总结,可以概况为以下几点:
1.Dubbo SPI结合了JDK SPI的实现,并在此基础上进行优化,如精准按需加载扩展类、缓存提升性能。
2.分析ExtensionLoader加载扩展类的过程,加载META-INF/dubbo/internal/,META-INF/dubbo/,META-INF/services/这三个路径下的文件,并分类缓存在ExtensionLoader实例。
3.介绍扩展包装类及其实现过程,扩展包装类实现了类似AOP的功能。
4.自适应扩展类,分析@Adptive修饰方法时动态生成Xxx$Adaptive类的过程,以及通过参数自适应选择扩展实现类完成方法调用的案例介绍。
简单介绍自动激活扩展类及@Activate的作用。
四、附录
4.1 Xxx$Adaptive完整案例
@SPI接口定义
@SPI("impl1")
public interface SimpleExt {
// @Adaptive example, do not specify a explicit key.
@Adaptive
String echo(URL url, String s);
@Adaptive({"key1", "key2"})
String yell(URL url, String s);
// no @Adaptive
String bang(URL url, int i);
}
生成的Adaptive类代码
package org.apache.dubbo.common.extension.ext1;
import org.apache.dubbo.common.extension.ExtensionLoader;
public class SimpleExt$Adaptive implements org.apache.dubbo.common.extension.ext1.SimpleExt {
public java.lang.String yell(org.apache.dubbo.common.URL arg0, java.lang.String arg1) {
if (arg0 == null) throw new IllegalArgumentException("url == null");
org.apache.dubbo.common.URL url = arg0;
String extName = url.getParameter("key1", url.getParameter("key2", "impl1"));
if (extName == null)
throw new IllegalStateException("Failed to get extension (org.apache.dubbo.common.extension.ext1.SimpleExt) name from url (" + url.toString() + ") use keys([key1, key2])");
org.apache.dubbo.common.extension.ext1.SimpleExt extension = (org.apache.dubbo.common.extension.ext1.SimpleExt)ExtensionLoader.getExtensionLoader(org.apache.dubbo.common.extension.ext1.SimpleExt.class).getExtension(extName);
return extension.yell(arg0, arg1);
}
public java.lang.String echo(org.apache.dubbo.common.URL arg0, java.lang.String arg1) {
if (arg0 == null) throw new IllegalArgumentException("url == null");
org.apache.dubbo.common.URL url = arg0;
String extName = url.getParameter("simple.ext", "impl1");
if (extName == null)
throw new IllegalStateException("Failed to get extension (org.apache.dubbo.common.extension.ext1.SimpleExt) name from url (" + url.toString() + ") use keys([simple.ext])");
org.apache.dubbo.common.extension.ext1.SimpleExt extension = (org.apache.dubbo.common.extension.ext1.SimpleExt) ExtensionLoader.getExtensionLoader(org.apache.dubbo.common.extension.ext1.SimpleExt.class).getExtension(extName);
return extension.echo(arg0, arg1);
}
public java.lang.String bang(org.apache.dubbo.common.URL arg0, int arg1) {
throw new UnsupportedOperationException("The method public abstract java.lang.String org.apache.dubbo.common.extension.ext1.SimpleExt.bang(org.apache.dubbo.common.URL,int) of interface org.apache.dubbo.common.extension.ext1.SimpleExt is not adaptive method!");
}
}
作者:vivo互联网服务器团队-Ning Peng
详解Apache Dubbo的SPI实现机制的更多相关文章
- Dubbo中SPI扩展机制解析
dubbo的SPI机制类似与Java的SPI,Java的SPI会一次性的实例化所有扩展点的实现,有点显得浪费资源. dubbo的扩展机制可以方便的获取某一个想要的扩展实现,每个实现都有自己的name, ...
- 图文详解 Android Binder跨进程通信机制 原理
图文详解 Android Binder跨进程通信机制 原理 目录 目录 1. Binder到底是什么? 中文即 粘合剂,意思为粘合了两个不同的进程 网上有很多对Binder的定义,但都说不清楚:Bin ...
- Java集合详解3:Iterator,fail-fast机制与比较器
Java集合详解3:Iterator,fail-fast机制与比较器 今天我们来探索一下LIterator,fail-fast机制与比较器的源码. 具体代码在我的GitHub中可以找到 https:/ ...
- react第五单元(事件系统-原生事件-react中的合成事件-详解事件的冒泡和捕获机制)
第五单元(事件系统-原生事件-react中的合成事件-详解事件的冒泡和捕获机制) 课程目标 深入理解和掌握事件的冒泡及捕获机制 理解react中的合成事件的本质 在react组件中合理的使用原生事件 ...
- 使用Dubbo的SPI扩展机制实现自定义LoadBalance——方法一 修改Dubbo源代码
一. 拉取源码 到Dubbo官网 https://github.com/apache/incubator-dubbo/tree/2.5.x 下载源码,解压. 二. 导入IDEA 选择解压后的源码目录, ...
- Springboot mini - Solon详解(五)- Solon扩展机制之Solon Plugin
Springboot min -Solon 详解系列文章: Springboot mini - Solon详解(一)- 快速入门 Springboot mini - Solon详解(二)- Solon ...
- OkHttp3源码详解(五) okhttp连接池复用机制
1.概述 提高网络性能优化,很重要的一点就是降低延迟和提升响应速度. 通常我们在浏览器中发起请求的时候header部分往往是这样的 keep-alive 就是浏览器和服务端之间保持长连接,这个连接是可 ...
- 详解 Rainbond Ingress 泛解析域名机制
Rainbond 作为一款云原生应用管理平台,天生带有引导南北向网络流量的分布式网关 rbd-gateway.区别于一般的 Ingress 配置中,用户需要自行定义域名的使用体验,Rainbond 的 ...
- 使用Dubbo的SPI扩展机制实现自定义LoadBalance——方法二 不改源码添加META-INF/dubbo元数据
一.官网提供的方法 参考官网 http://dubbo.apache.org/zh-cn/docs/dev/impls/load-balance.html 二.方法总结 在工程中创建类并实现LoadB ...
随机推荐
- Jenkins + Docker + ASP.NET Core自动化部署
本来没想着要写这篇博客,但是在实操过程中,一个是被网络问题搞炸了心态(真心感觉网络能把人搞疯,别人下个包.下个镜像几秒钟搞定,我看着我的几KB小水管真是有苦说不出),另一个就是这里面坑还是有一些的,写 ...
- PTA 第三章 栈与队列
一.判断题 1.若一个栈的输入序列为1,2,3,--,N,输出序列的第一个元素为i,则第j个输出的元素是j-i-1 (×)解析:应该是不确定的,不能保证数字出栈后不会再入栈 2.所谓" ...
- Zabbix 5.0 优化建议
Blog:博客园 个人 在使用Zabbix过程中,正确的调整Zabbix系统,使之保持高性能是非常重要的,能够充分利用硬件资源,监控更多主机和性能指标. 硬件 关于zabbix server端硬件的建 ...
- Nifi:nifi的基本使用
Nifi的安装使用 Nifi安装 首先说一下Nifi的安装,这里Nifi可以支持Windows版和Linux,只需要去官网:http://nifi.apache.org/ 根据自己需要的版本,选择下载 ...
- [前端、HTTP协议、HTML标签]
[前端.HTTP协议.HTML标签] 什么是前端 """ 任何与用户直接打交道的操作界面都可以称之为前端 比如:电脑界面 手机界面 平板界面 什么是后端 后端类似于幕后操 ...
- 关于__new__和__call__的想法
__new__和__call__很像,两个都是用来产生对象的 __new__用来产生的对象是'类',class 时触发(不是) __call__用来产生的对象是'对象',这种对象无法继续产生对象,但是 ...
- Spring与Springboot
1.Spring能做什么 1.1.Spring的能力 1.2.Spring的生态 https://spring.io/projects/spring-boot 覆盖了: web开发 数据访问 安全控制 ...
- springboot+Thymeleaf+layui 实现分页
layui分页插件 引入相关的js和css layui:css <link rel="stylesheet" th:href="@{layui/css/layui. ...
- golang:TCP总结
在TCP/IP协议中,"IP地址+TCP或UDP端口号"唯一标识网络通讯中的一个进程."IP地址+端口号"就对应一个socket.欲建立连接的两个进程各自有一个 ...
- [web] 虚拟机网络设置
三种模式 桥接(Bridged):主机网卡--虚拟网桥--虚拟机网卡,把主机虚拟为交换机,虚拟机ip需与主机设置在同一网段,网关与DNS与主机网卡一致 地址转换(NAT):主机网卡--虚拟NAT设备- ...