联邦学习:按Dirichlet分布划分Non-IID样本
我们在《Python中的随机采样和概率分布(二)》介绍了如何用Python现有的库对一个概率分布进行采样,其中的dirichlet分布大家一定不会感到陌生。该分布的概率密度函数为
\bm{x}=(x_1,x_2,...,x_k),\quad x_i > 0 , \quad \sum_{i=1}^k x_i = 1\\
\bm{\alpha} = (\alpha_1,\alpha_2,..., \alpha_k). \quad \alpha_i > 0
\]
其中\(\bm{\alpha}\)为参数。
我们在联邦学习中,经常会假设不同client间的数据集不满足独立同分布(non-iid)。那么我们如何将一个现有的数据集按照non-iid划分呢?我们知道带标签样本的生成分布看可以表示为\(p(\bm{x}, y)\),我们进一步将其写作\(p(\bm{x}, y)=p(\bm{x}|y)p(y)\)。其中如果要估计\(p(\bm{x}|y)\)的计算开销非常大,但估计\(p(y)\)的计算开销就很小。所有我们按照样本的标签分布来对样本进行non-iid划分是一个非常高效、简便的做法。
总而言之,我们采取的算法思路是尽量让每个client上的样本标签分布不同。我们设有\(K\)个类别标签,\(N\)个client,每个类别标签的样本需要按照不同的比例划分在不同的client上。我们设矩阵\(\bm{X}\in \mathbb{R}^{K*N}\)为类别标签分布矩阵,其行向量\(\bm{x}_k\in \mathbb{R}^N\)表示类别\(k\)在不同client上的概率分布向量(每一维表示\(k\)类别的样本划分到不同client上的比例),该随机向量就采样自dirichlet分布。
据此,我们可以写出以下的划分算法:
import numpy as np
np.random.seed(42)
def split_noniid(train_labels, alpha, n_clients):
'''
参数为alpha的dirichlet分布将数据索引划分为n_clients个子集
'''
n_classes = train_labels.max()+1
label_distribution = np.random.dirichlet([alpha]*n_clients, n_classes)
# (K, N)的类别标签分布矩阵X,记录每个client占有每个类别的多少
class_idcs = [np.argwhere(train_labels==y).flatten()
for y in range(n_classes)]
# 记录每个K个类别对应的样本下标
client_idcs = [[] for _ in range(n_clients)]
# 记录N个client分别对应样本集合的索引
for c, fracs in zip(class_idcs, label_distribution):
# np.split按照比例将类别为k的样本划分为了N个子集
# for i, idcs 为遍历第i个client对应样本集合的索引
for i, idcs in enumerate(np.split(c, (np.cumsum(fracs)[:-1]*len(c)).astype(int))):
client_idcs[i] += [idcs]
client_idcs = [np.concatenate(idcs) for idcs in client_idcs]
return client_idcs
加下来我们在EMNIST数据集上调用该函数进行测试,并进行可视化呈现。我们设client数量\(N=10\),dirichlet概率分布的参数向量\(\bm{\alpha}\)满足\(\alpha_i=1.0,\space i=1,2,...N\):
import torch
from torchvision import datasets
import numpy as np
import matplotlib.pyplot as plt
torch.manual_seed(42)
if __name__ == "__main__":
N_CLIENTS = 10
DIRICHLET_ALPHA = 1.0
train_data = datasets.EMNIST(root=".", split="byclass", download=True, train=True)
test_data = datasets.EMNIST(root=".", split="byclass", download=True, train=False)
n_channels = 1
input_sz, num_cls = train_data.data[0].shape[0], len(train_data.classes)
train_labels = np.array(train_data.targets)
# 我们让每个client不同label的样本数量不同,以此做到non-iid划分
client_idcs = split_noniid(train_labels, alpha=DIRICHLET_ALPHA, n_clients=N_CLIENTS)
# 展示不同client的不同label的数据分布
plt.figure(figsize=(20,3))
plt.hist([train_labels[idc]for idc in client_idcs], stacked=True,
bins=np.arange(min(train_labels)-0.5, max(train_labels) + 1.5, 1),
label=["Client {}".format(i) for i in range(N_CLIENTS)], rwidth=0.5)
plt.xticks(np.arange(num_cls), train_data.classes)
plt.legend()
plt.show()
最终的可视化结果如下:
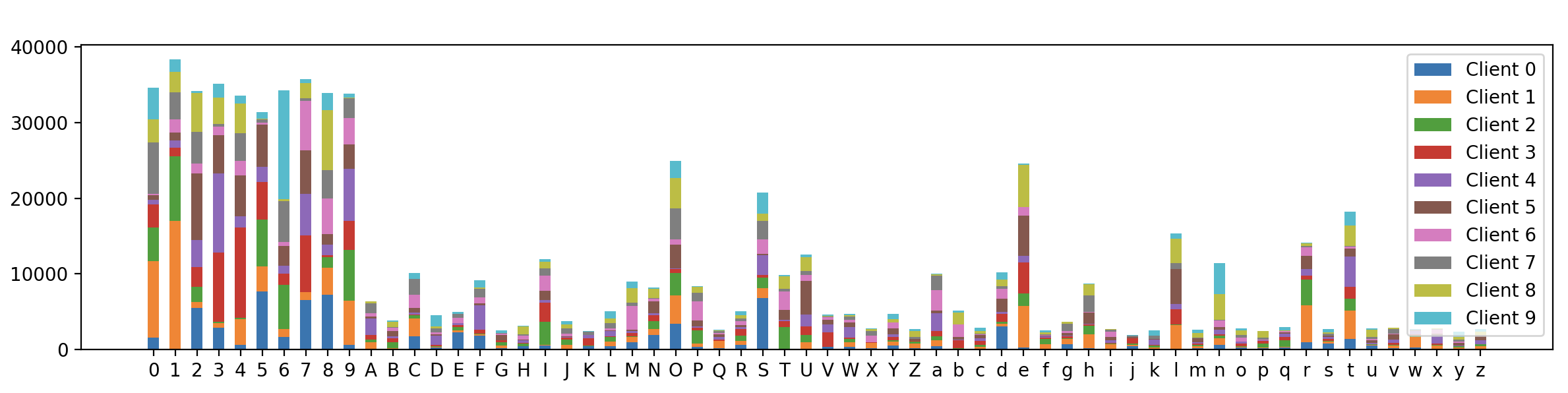
可以看到,62个类别标签在不同client上的分布确实不同,证明我们的样本划分算法是有效的。
联邦学习:按Dirichlet分布划分Non-IID样本的更多相关文章
- 联邦学习:按混合分布划分Non-IID样本
我们在博文<联邦学习:按病态独立同分布划分Non-IID样本>中学习了联邦学习开山论文[1]中按照病态独立同分布(Pathological Non-IID)划分样本. 在上一篇博文< ...
- LDA学习之beta分布和Dirichlet分布
---恢复内容开始--- 今天学习LDA主题模型,看到Beta分布和Dirichlet分布一脸的茫然,这俩玩意怎么来的,再网上查阅了很多资料,当做读书笔记记下来: 先来几个名词: 共轭先验: 在贝叶斯 ...
- Apache Pulsar 在腾讯 Angel PowerFL 联邦学习平台上的实践
腾讯 Angel PowerFL 联邦学习平台 联邦学习作为新一代人工智能基础技术,通过解决数据隐私与数据孤岛问题,重塑金融.医疗.城市安防等领域. 腾讯 Angel PowerFL 联邦学习平台构建 ...
- 【一周聚焦】 联邦学习 arxiv 2.16-3.10
这是一个新开的每周六定期更新栏目,将本周arxiv上新出的联邦学习等感兴趣方向的文章进行总结.与之前精读文章不同,本栏目只会简要总结其研究内容.解决方法与效果.这篇作为栏目首发,可能不止本周内容(毕竟 ...
- 关于Beta分布、二项分布与Dirichlet分布、多项分布的关系
在机器学习领域中,概率模型是一个常用的利器.用它来对问题进行建模,有几点好处:1)当给定参数分布的假设空间后,可以通过很严格的数学推导,得到模型的似然分布,这样模型可以有很好的概率解释:2)可以利用现 ...
- 【论文考古】联邦学习开山之作 Communication-Efficient Learning of Deep Networks from Decentralized Data
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, "Communication-Efficient Learni ...
- Beta分布和Dirichlet分布
在<Gamma函数是如何被发现的?>里证明了\begin{align*} B(m, n) = \int_0^1 x^{m-1} (1-x)^{n-1} \text{d} x = \frac ...
- LDA-math-认识Beta/Dirichlet分布
http://cos.name/2013/01/lda-math-beta-dirichlet/#more-6953 2. 认识Beta/Dirichlet分布2.1 魔鬼的游戏—认识Beta 分布 ...
- 机器学习的数学基础(1)--Dirichlet分布
机器学习的数学基础(1)--Dirichlet分布 这一系列(机器学习的数学基础)主要包括目前学习过程中回过头复习的基础数学知识的总结. 基础知识:conjugate priors共轭先验 共轭先验是 ...
随机推荐
- mysql数据库存放的路径以及安装路径
mysql数据库存放的路径以及安装路径 1.查看mysql的存放路径 1.查看数据库的存放路径 进入mysql终端 mysql>show variables like '%datadir%'; ...
- 解决maven每次更新都编程java1.5
Maven: 每次更新Maven Project ,JAVA 版本都变为1.5 本文转载自:http://www.cnblogs.com/Hxinguan/p/6132446.html 问题: 1.创 ...
- IE播放音频踩坑之路---待修改
在其他浏览器都是兼容的!在IE9就是显示一个黑色的框上面有个X 音乐无法播放 要显示播放界面的话,要添加 controls 属性(控件属性)例子:<audio src="xxx.m ...
- php伪协议总结
本篇总结下一些封装协议,涉及的相关协议:file://.php://filter.php://input.zip://.compress.bzip2://.compress.zlib://.data: ...
- IntelliJ IDEA最新破解方法
IntelliJ IDEA最新破解方法 首先说下,本人使用idea版本是2021.2.3. 一.下载IDEA(推荐从官网下载) 官网地址:https://www.jetbrains.com/idea/ ...
- IDEA超级好用的插件推荐
IDEA超级好用的插件推荐 以下都是本人使用idea开发以来,所使用过的插件,强烈推荐,提升代码质量,事半功倍之首选!!! 先介绍下如何安装这些插件:(本人使用idea的版本是2020.2.3) 1. ...
- c++中构造函数与析构函数
构造函数与析构函数 构造函数与析构函数1. 构造函数2. 析构函数3. 拷贝函数4. 总结 在c++中有2个特殊的函数:构造函数和析构函数,它们分别对类对象进行初始化和清理工作. 1. 构造函数 构造 ...
- openssl基本原理 + 生成证书(转)
https://blog.csdn.net/cpcpcp123/article/details/108885922 https://liruzhen.blog.csdn.net/article/det ...
- JDBC固定步骤-java连接MySQL
static final String JDBC_DRIVER = "com.mysql.cj.jdbc.Driver"; static final String DB_URL = ...
- 字节Android Native Crash治理之Memory Corruption工具原理与实践
作者:字节跳动终端技术--庞翔宇 内容摘要 MemCorruption工具是字节跳动AppHealth (Client Infrastructure - AppHealth) 团队开发的一款用于定 ...