Python爬虫之lxml-etree和xpath的结合使用
本篇文章给大家介绍的是Python爬虫之lxml-etree和xpath的结合使用(附案例),内容很详细,希望可以帮助到大家。
lxml:python的HTML / XML的解析器
官网文档:https://lxml.de/
使用前需要安装lxml包
终端输入(win7.8,10在cmd输入)pip install -i https://pypi.tuna.tsinghua.edu.cn/simple lxml
功能:
1 解析html:使用etree.html(text)将字符串格式的 html片段解析成 html 文档
2 读取xml文件
3 etree和xpath配合使用(本文主要介绍)
示例:etree和xpath配合使用
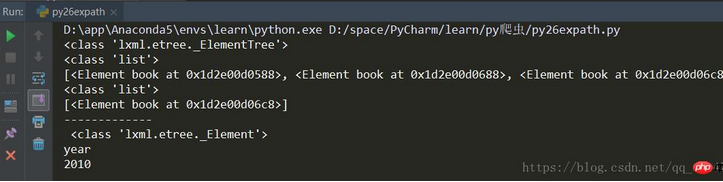
# lxml-etree读取文件from lxml import etree
xml = etree.parse("./py24.xml")
print(type(xml))# 查找所有 book 节点rst = xml.xpath('//book')
print(type(rst))
print(rst)# 查找带有 category 属性值为 sport 的元素rst2 = xml.xpath('//book[@category="sport"]')
print(type(rst2))
print(rst2)# 查找带有category属性值为sport的元素的book元素下到的year元素rst3 = xml.xpath('//book[@category="sport"]/year')
rst3 = rst3[0]
print('-------------\n',type(rst3))
print(rst3.tag)
print(rst3.text)结果:
示例:使用lxml解析html代码
# 先安装lxml
# 用 lxml 来解析HTML代码
from lxml import etree
text = '''<p>
<ul>
<li class="item-0"><a href="0.html">item 0 </a></li>
<li class="item-1"><a href="1.html">item 1 </a></li>
<li class="item-2"><a href="2.html">item 2 </a></li>
<li class="item-3"><a href="3.html">item 3 </a></li>
<li class="item-4"><a href="4.html">item 4 </a></li>
<li class="item-5"><a href="5.html">item 5 </a></li>
</ul> </p>'''
# 利用 etree.HTML 把字符串解析成 HTML 文件
html = etree.HTML(text)
s = etree.tostring(html).decode()
print(s)结果:

示例:读取xml文件
# lxml-etree读取文件from lxml import etree
xml = etree.parse("./py24.xml")
sxml = etree.tostring(xml, pretty_print=True)
print(sxml)结果:

Python爬虫之lxml-etree和xpath的结合使用的更多相关文章
- 小白学 Python 爬虫(20):Xpath 进阶
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(19):Xpath 基操
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 爬虫之lxml - etree - xpath的使用
# 解析原理: # - 获取页面源码数据 # - 实例化一个etree对象,并且将页面源码数据加载到该对象中 # - 调用该对象的xpath方法进行指定标签定位 # - xpath函数必须结合着xpa ...
- python爬虫入门(三)XPATH和BeautifulSoup4
XML和XPATH 用正则处理HTML文档很麻烦,我们可以先将 HTML文件 转换成 XML文档,然后用 XPath 查找 HTML 节点或元素. XML 指可扩展标记语言(EXtensible Ma ...
- Python 爬虫 解析库的使用 --- XPath
一.使用XPath XPath ,全称XML Path Language,即XML路径语言,它是一门在XML文档中查找信息的语言.它最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索. 所 ...
- Python爬虫——使用 lxml 解析器爬取汽车之家二手车信息
本次爬虫的目标是汽车之家的二手车销售信息,范围是全国,不过很可惜,汽车之家只显示100页信息,每页48条,也就是说最多只能够爬取4800条信息. 由于这次爬虫的主要目的是使用lxml解析器,所以在信息 ...
- Python爬虫使用lxml模块爬取豆瓣读书排行榜并分析
上次使用了BeautifulSoup库爬取电影排行榜,爬取相对来说有点麻烦,爬取的速度也较慢.本次使用的lxml库,我个人是最喜欢的,爬取的语法很简单,爬取速度也快. 本次爬取的豆瓣书籍排行榜的首页地 ...
- python爬虫三大解析库之XPath解析库通俗易懂详讲
目录 使用XPath解析库 @(这里写自定义目录标题) 使用XPath解析库 1.简介 XPath(全称XML Path Languang),即XML路径语言,是一种在XML文档中查找信息的语言. ...
- Python爬虫:数据解析 之 xpath
资料: W3C标准:https://www.w3.org/TR/xpath/all/ W3School:https://www.w3school.com.cn/xpath/index.asp 菜鸟教程 ...
- Python爬虫教程-22-lxml-etree和xpath配合使用
Python爬虫教程-22-lxml-etree和xpath配合使用 lxml:python 的HTML/XML的解析器 官网文档:https://lxml.de/ 使用前,需要安装安 lxml 包 ...
随机推荐
- 【linux】驱动-15-定时器
目录 前言 15. 定时器 15.1 内核函数汇总 15.2 内核滴答 15.3 相关结构体 15.4 setup_timer() 设置定时器 15.5 add_timer() 向内核添加定时器 15 ...
- 数据库创建好之后如何创建scott用户
SQL> conn / as sysdba Connected. SQL> @%oracle_home%\rdbms\admin\utlsampl.sql 建立完成以后会自动退出sqlpl ...
- HTTP头部POST表单详解
2 POST /hello/checkUser.html?opt=xxx HTTP/1.1 方法的声明,Get,Post,Delete等 3 Accept: */* 4 Referer: http:/ ...
- js中有对象的key怎么获取对应的值
一般人的思路是这样的 var obj = {"name1":"张三","name2":"李四"}; var key = ...
- 如何在国产龙芯架构平台上运行c/c++、java、nodejs等编程语言
高能预警:本文内容过于硬核,涉及编译器原理.cpu指令集.机器码.编程语言原理.跨平台原理等计算机专业基础知识,建议具有c.c++.java.nodejs等多种编程语言开发能力,且实战经验丰富的资深开 ...
- 乘风破浪,.Net Core遇见MAUI(.NET Multi-platform App UI),进击现代化跨设备应用框架
什么是MAUI https://github.com/dotnet/maui .NET Multi-platform App UI (MAUI) 的前身是Xamarin.Forms(适用于Androi ...
- 12、Linux磁盘设备基础知识(2)
12.4.计算磁盘容量: 磁盘的大小=盘面大小*磁头数 盘面的大小=磁道大小*磁道数 磁道大小=512字节*扇区数 磁盘的大小=512字节*扇区数*磁道数*磁头数 磁盘的大小=柱面大小*柱面数 柱面大 ...
- CRM企业管理系统一年多少钱?
CRM系统一年多少钱?这是很多企业管理者比较关心的问题.目前市面上的CRM系统分为本地部署型和云部署型.云部署型CRM费用相对较低,只需要按需购买账号,连接网络即可使用:本地部署型CRM费用较高,企业 ...
- 大话Java代理模式
一.什么是代理 首先理解一下什么是代理.简单来说,代理就你要做一件事情,我替你把事情做了.这是现实生活中我们遇到的代理的需求场景.但写代码的时候对代理场景的需求,跟现实场景有点区别,本质上还是帮你做事 ...
- svn创建新分支报错:svn: E155015: Aborting commit: XXX remains in conflict
用diea在对svn创建新分支的时候报错,错误为 svn: E155015: Aborting commit: XXX remains in conflict 百度和查阅资料后得知,此错误为分支被拉取 ...