Scrapy入门到放弃04:下载器中间件,让爬虫更完美
前言
MiddleWare,顾名思义,中间件。主要处理请求(例如添加代理IP、添加请求头等)和处理响应
本篇文章主要讲述下载器中间件的概念,以及如何使用中间件和自定义中间件。
MiddleWare分类
依旧是那张熟悉的架构图。
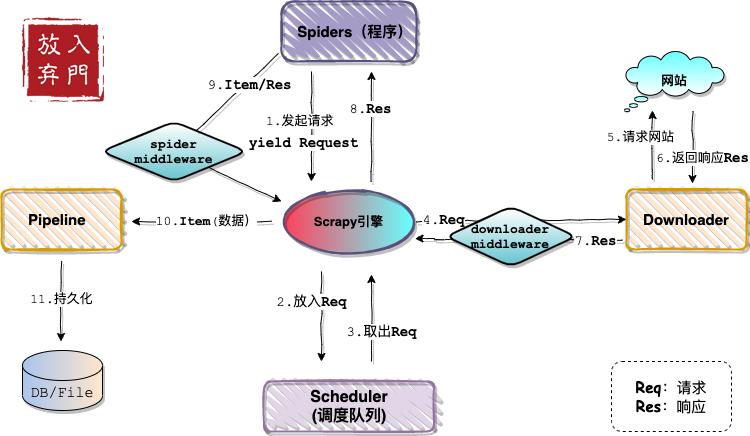
从图中看,中间件主要分为两类:
- Downloader MiddleWare:下载器中间件
- Spider MiddleWare:Spider中间件
本篇文主要介绍下载器中间件,先看官方的定义:
下载器中间件是介于Scrapy的request/response处理的钩子框架。 是用于全局修改Scrapy request和response的一个轻量、底层的系统。
作用
如架构图中所描述的一样,下载器中间件位于engine和下载器之间。engine将未处理的请求发送给下载器的时候,会经过下载器中间件,这时候在中间件里可以包装请求,例如修改请求头信息(设置UA、cookie等)和添加代理IP。
当下载器将网站的响应发送给engine的时候,也会经过下载器中间件,这里我们就可以对响应内容进行处理。
内置下载器中间件
Scrapy内置了很多下载器中间件供开发者使用。当我们启动一个Scrapy爬虫时,Scrapy会自动帮助我们启用这些中间件。如图:
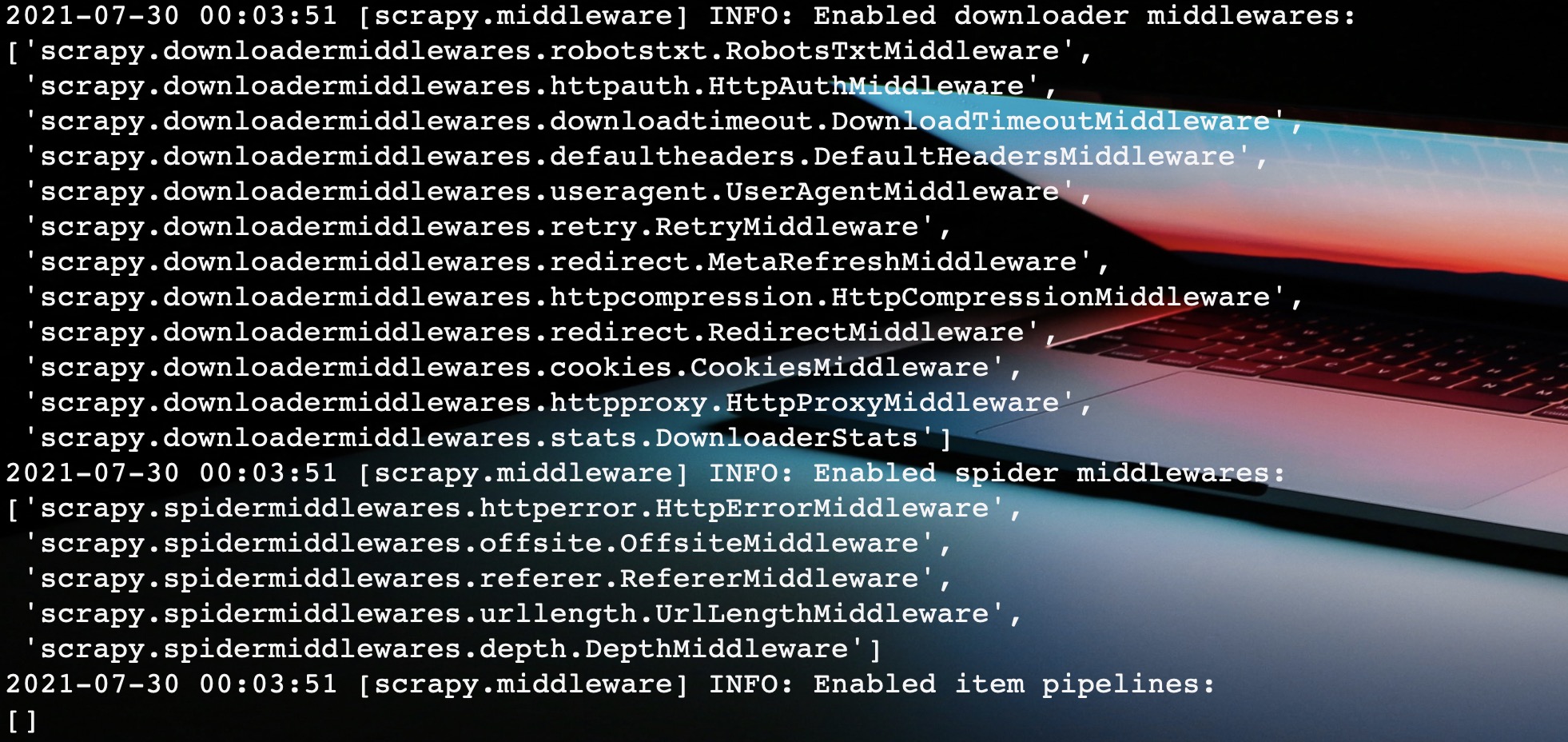
图中就是在启动Scrapy程序时控制台打印的日志信息,我们发现Scrapy帮我们启用了很多下载器中间件和Spider中间件。
这里,先看看这些内置的中间件是如何发挥作用的?
RetryMiddleware
其实,这些内置中间件是和settings中的配置配套使用的。这里就拿RetryMiddleware为例。它的作用主要是:当请求失败时,可以根据RETRY_ENABLED和RETRY_TIMES配置来启用重试策略以及决定重试次数。就酱!!
那么问题又来了,这么多中间件,我去哪里找这个settings配置和中间件的对应关系啊??
这里我的方法有两种:
- 去官方文档,上篇文章有链接
- 看源码注释,在scrapy包下的都有中间件对应的py文件
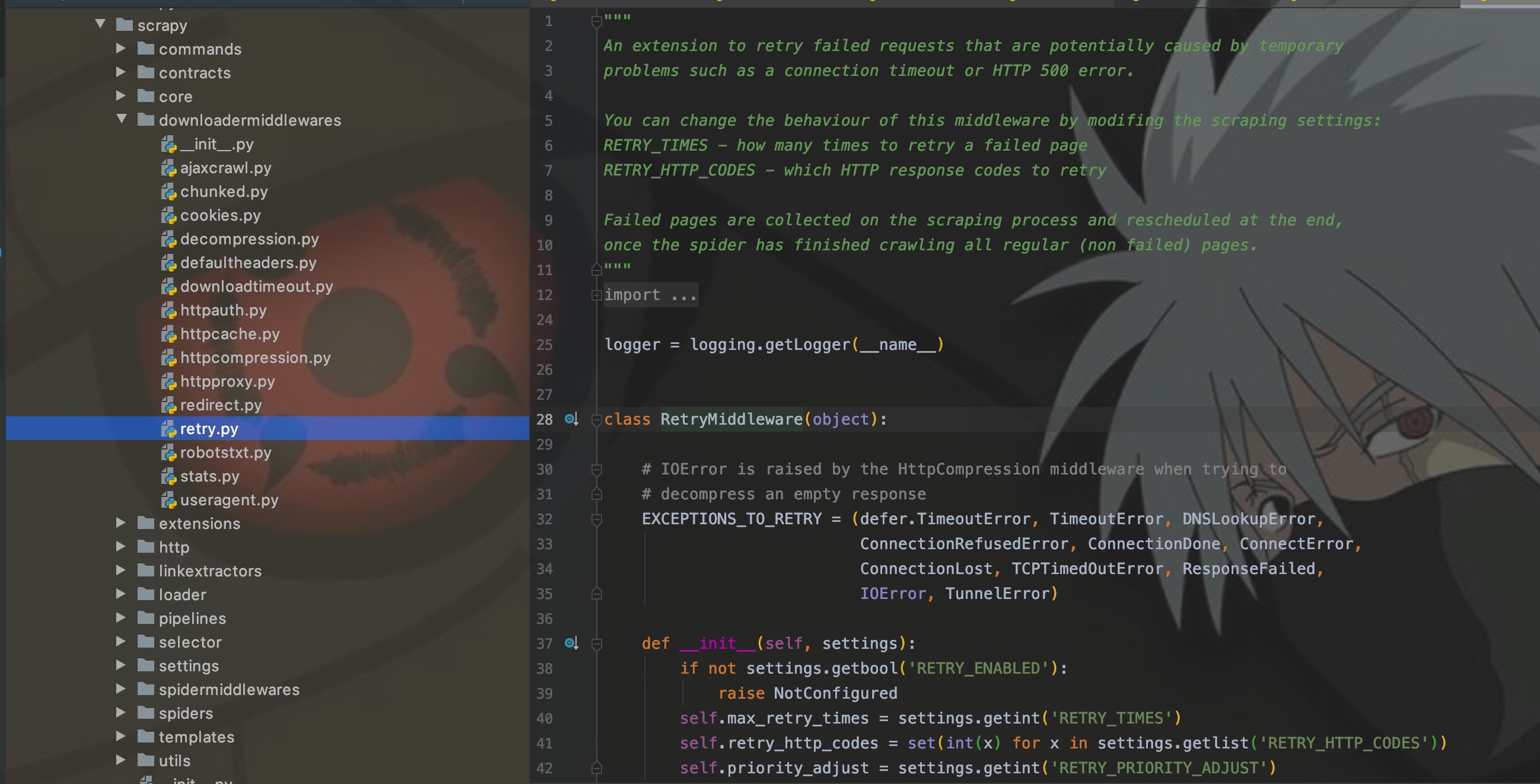
注释里面写的明明白白,代码中获取的参数也一览无余。
自定义中间件
有时候,内置的中间件满足不了自己的需求,所以我们就要自力更生,自定义中间件。所有的中间件都在middlewares.py中进行定义。
我们打开middlewares.py,发现里面已经自动生成了一个下载器中间件和Spider中间件。
先看自生成的下载器中间件模板:
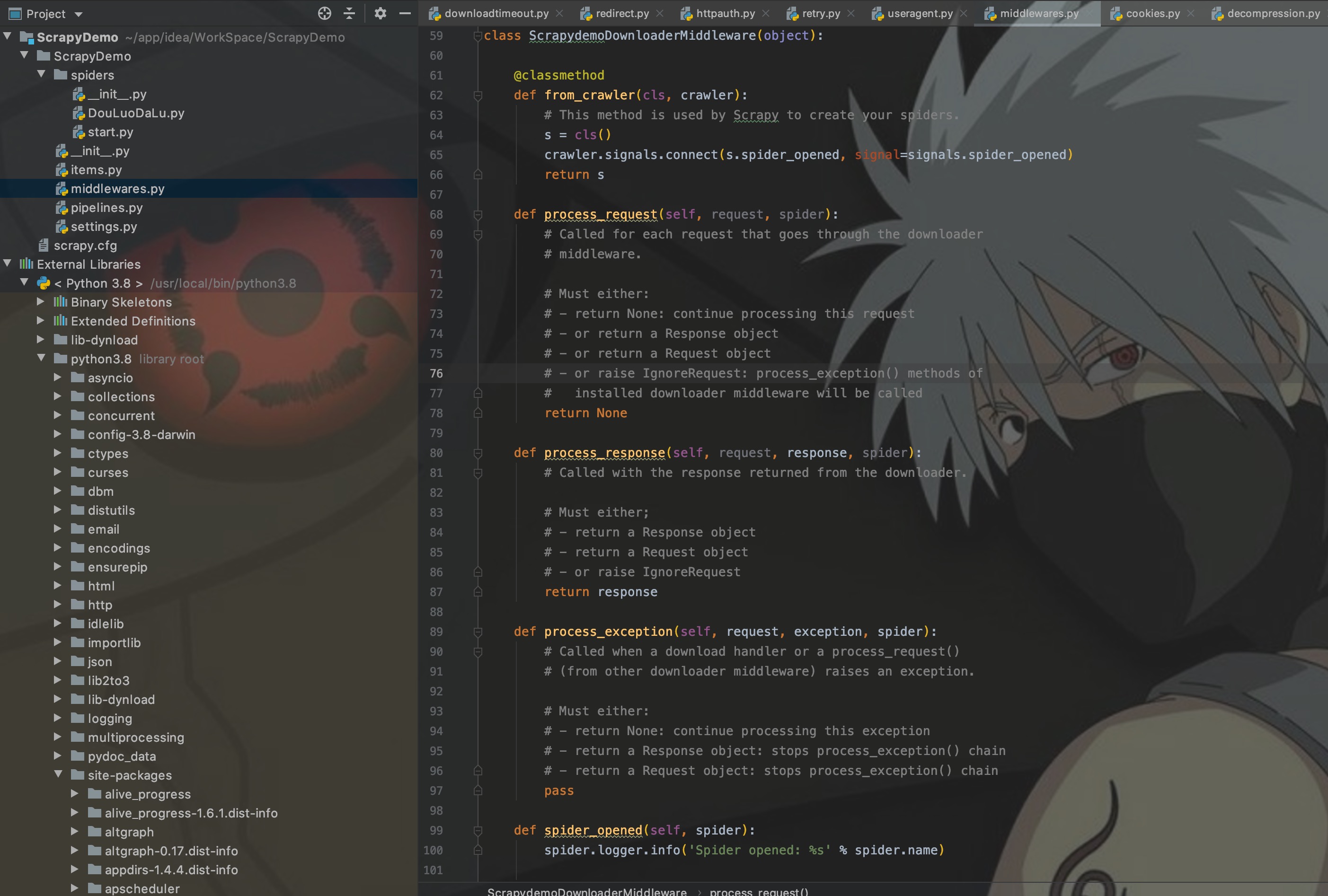
可以看到里面主要有五个方法:
- from_crawler:类方法,用于初始化中间件
- process_request:每个request通过下载中间件时,都会调用该方法,对应架构图步骤4
- process_response:处理下载器返回的响应内容,对应架构图步骤7
- process_exception:当下载器或者处理请求异常时,调用此方法
- spider_opened:内置的信号量回调方法,这里先不关注,先不关注!
这里主要关注3,顺带了解一下4、5。
process_request()
此方法有两个参数:
- request:spider发起的需要处理的request
- spider:该request对应的spider,暂定信号量细讲这个对象
def process_request(self, request, spider):
# Called for each request that goes through the downloader middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None
这里主要是为了让大家看注释,看注释的目的是为了告诉大家:此方法必须返回值。
- None:基本上用的都是这个返回值。表示这个请求可以进去下一个中间件进行处理了。
- request:停止调用process_request方法,并重新将request放回队列重新调度
- response:不会调用其他的 process_request,直接返回response,执行process_response。
还有一个是raise抛出异常,其实基本上返回值都用None,其他的目前可以仅做了解,有兴趣的可以自己探索一下。
process_response()
此方法有三个参数:
- request:response所对应的request
- response:被处理的response
- spider:response所对应的spider
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
一样是看注释,返回值有两个:
- response:下载器返回的响应内容,在各个中间件的process_response处理
- request:停止调用process_response方法,响应不会到达spider,并重新将request放回队列重新调度
这里记住,只要return response就行。
process_exception()
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
此方法就是当上面两个方法抛出异常的时候就会进入此方法,返回值有三个,意思和上面的差不多,用None就行。
启用和禁用中间件
自定义的中间件,有时候会和内置中间件功能重复,也担心功能上互相覆盖。所以这里我们可以选择,在配置中关掉内置中间件。
我个人比较喜欢自定义User-Agent中间件,但是Scrapy内置UserAgentMiddleware中间件,这就冲突了。如果内置中间件执行优先级低,后执行的话,则内置的UA就会覆盖自定义的UA。所以,我们需要关掉这个内置中UA中间件。
DOWNLOADER_MIDDLEWARES参数用来设置下载器中间件。其中,Key为中间件路径,Value为中间件执行优先级,数字越小,越先执行,当Value为None时,表示禁用。
# settings.py
DOWNLOADER_MIDDLEWARES = {
# 禁用默认的useragent插件
'scrapy.downloadermiddleware.useragent.UserAgentMiddleware': None,
# 启用自定义的中间件
'ScrapyDemo.middlewares.VideospiderDownloaderMiddleware': 543,
}
这样,内置的UA中间件则被禁用。
调用优先级
其次我们要明确的是:中间件是链式调用,一个请求会根据中间件的优先级,先后经过每个中间件,响应也是。
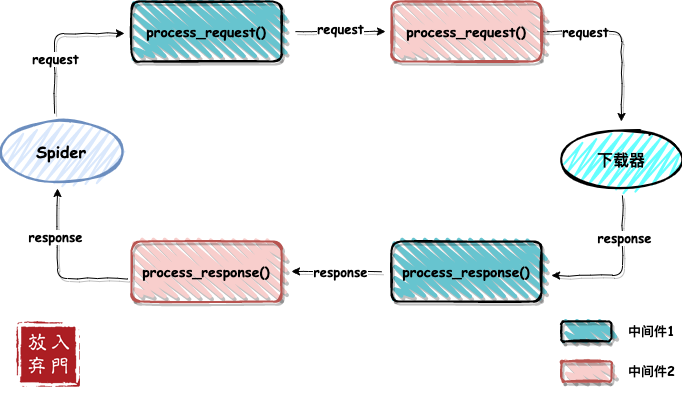
上面也说了,每个中间件都会设置一个执行优先级,数字越小越先执行。例如中间件1的优先级设置为200,中间件2的优先级设置为300。
当spider发起一个请求时,request会先经过中间件1的process_request进行处理,然后到达中间件2的此方法进行处理,当经过所有的中间件的此方法处理之后,最后到达下载器进行网站请求,然后返回响应内容。
process_response就是逆序处理,先到达中间件2的此方法,再到达中间件1,最后响应返回spider中,由开发者处理。
实践
这里我们自定义一个下载器中间件,来添加User-Agent。
自定义中间件
在middlewares.py中定义一个中间件:
class CustomUserAgentMiddleWare(object):
def process_request(self, request, spider):
request.headers['User-Agent'] = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36'
return None
def process_response(self, request, response, spider):
print(request.headers['User-Agent'])
return response
启用中间件
为了直观,我们不修改settings.py全局配置,依旧使用代码内局部配置。
import scrapy
class DouLuoDaLuSpider(scrapy.Spider):
name = 'DouLuoDaLu'
allowed_domains = ['v.qq.com']
start_urls = ['https://v.qq.com/detail/m/m441e3rjq9kwpsc.html']
custom_settings = {
'DOWNLOADER_MIDDLEWARES': {
# 禁用默认的useragent插件
'scrapy.downloadermiddleware.useragent.UserAgentMiddleware': None,
# 启用自定义的中间件
'ScrapyDemo.middlewares.CustomUserAgentMiddleWare': 400
}
}
def parse(self, response):
pass
这里首先禁用了默认的UA中间件,然后启用了自定义的UA中间件。并且我在最后一行打上断点,Debug看UA是否设置成功。
测试结果
Debug模式启动程序,这里先把自定义的UA中间件禁用。
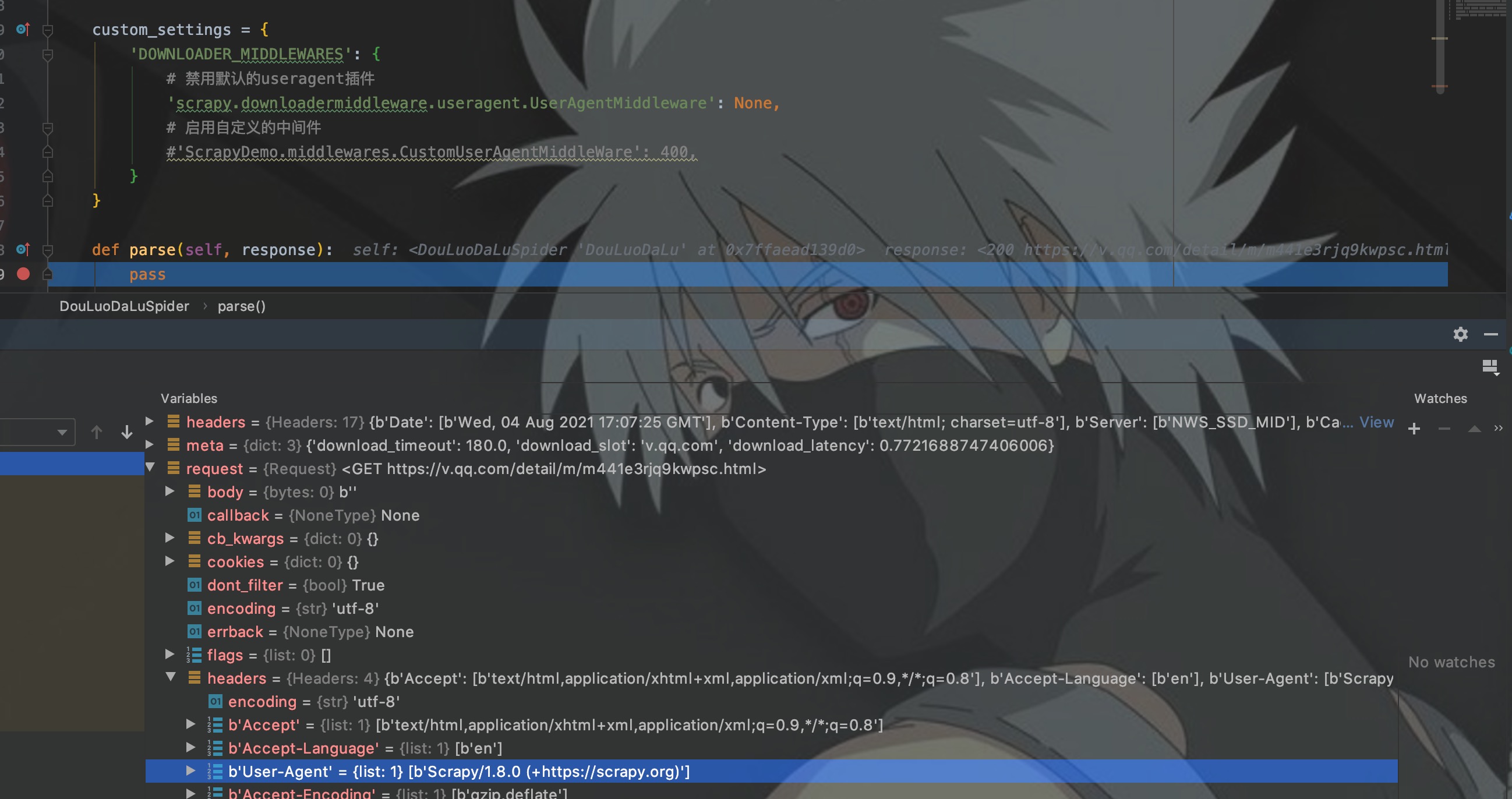
如图,request的UA是Scrapy。我们将注释去掉,启动UA中间件,再次启动程序测试。
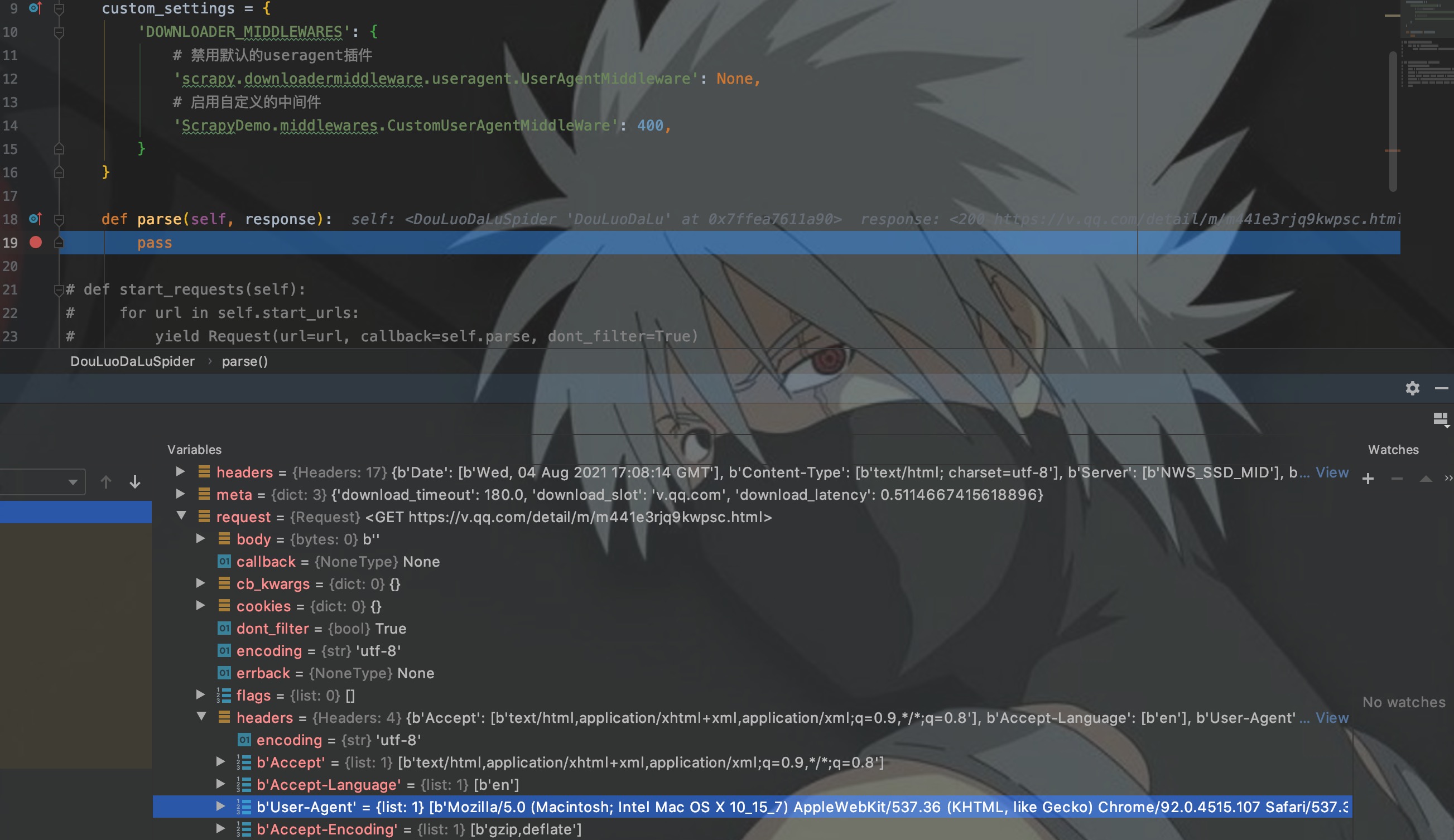
如图,request的UA已经变成我在中间件中设置的UA了。
设置代理IP
依旧是在process_request方法中设置代理IP。
代码如下:
request.meta["proxy"] = 'http://ip:port'
结语
下载器中间件主要的功能还是包装请求,我个人自定义下载器中间件都是用来动态设置UA和实时检测更换代理IP。至于其他的场景需求,内置的下载器中间件基本上够用。
当然,不去学习下载器中间件这一块的知识同样可以开发Scrapy爬虫,但是下载器中间件会让你的爬虫更加完美。
本来想把下载器中间件和Spider中间件写在一篇中,但是知识点太碎,不好排版,而且还容易混淆,所以Spider中间件就留在下一篇写,期待下一次相遇。
95后小程序员,写的都是日常工作中的亲身实践,置身于初学者的角度从0写到1,详细且认真。文章会在公众号 [入门到放弃之路] 首发,期待你的关注。

Scrapy入门到放弃04:下载器中间件,让爬虫更完美的更多相关文章
- Scrapy入门到放弃06:Spider中间件
前言 写一写Spider中间件吧,都凌晨了,一点都不想写,主要是也没啥用...哦不,是平时用得少.因为工作上的事情,已经拖更好久了,这次就趁着半夜写一篇. Scrapy-deltafetch插件是在S ...
- scrapy中的下载器中间件
scrapy中的下载器中间件 下载中间件 下载器中间件是介于Scrapy的request/response处理的钩子框架. 是用于全局修改Scrapy request和response的一个轻量.底层 ...
- Scrapy学习篇(十)之下载器中间件(Downloader Middleware)
下载器中间件是介于Scrapy的request/response处理的钩子框架,是用于全局修改Scrapy request和response的一个轻量.底层的系统. 激活Downloader Midd ...
- Scrapy下载器中间件用法示例
1.爬虫文件httpbin.py # -*- coding: utf-8 -*- import scrapy class HttpbinSpider(scrapy.Spider): name = 'h ...
- scrapy 下载器中间件 随机切换user-agent
下载器中间件如下列表 ['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware', 'scrapy.downloadermiddlewa ...
- scrapy入门到放弃02:整一张架构图,开发一个程序
前言 Scrapy开门篇写了一些纯理论知识,这第二篇就要直奔主题了.先来讲讲Scrapy的架构,并从零开始开发一个Scrapy爬虫程序. 本篇文章主要阐述Scrapy架构,理清开发流程,掌握基本操作. ...
- Scrapy入门到放弃03:理解settings配置,监控Scrapy引擎
前言 代码未动,配置先行.本篇文章主要讲述一下Scrapy中的配置文件settings.py的参数含义,以及如何去获取一个爬虫程序的运行性能指标. 这篇文章无聊的一匹,没有代码,都是配置化的东西,但是 ...
- Scrapy入门到放弃05:让Item在Pipeline中飞一会儿
前言 "又回到最初的起点,呆呆地站在镜子前". 本来这篇是打算写Spider中间件的,但是因为这一块涉及到Item,所以这篇文章先将Item讲完,顺便再讲讲Pipeline,然后再 ...
- Elasticsearch从入门到放弃:分词器初印象
Elasticsearch 系列回来了,先给因为这个系列关注我的同学说声抱歉,拖了这么久才回来,这个系列虽然叫「Elasticsearch 从入门到放弃」,但只有三篇就放弃还是有点过分的,所以还是回来 ...
随机推荐
- excel函数sum、sumif和sumifs
1.sum(a1,a2,a2,...a10)或sum(a1:a10)求a1到a10的和 2.sumif(条件区域,指定的求和条件,求和的区域) =SUMIF($F$2:$F$7,J2,$H$2:$H$ ...
- 【原创】SystemVerilog中的多态和虚方法
封装可以隐藏实现细节,使代码模块化,继承可以扩展已经存在的代码模块,目的都是为了代码重用.多态是为了实现接口的重用.在SystemVerilog中,子类和父类之间多个子程序使用同一个名字的现象称为Sy ...
- Qt之先用了再说系列-串口通讯(单串口单线程)
QT 串口通讯(单串口单线程) 串口通讯在我们写程序的时候或多或少会用到,借此在这记录一下QT是如何使用串口来通讯的.本次先侃侃在单线程下使用1个串口来通讯过程.好了,废话不多说,直接看步骤,我们的宗 ...
- css input 设置只读样式
input[readonly]{ background-color: #EEEEEE !important; }
- linux设备驱动编写入门
linux设备驱动是什么,我个人的理解是liunx有用户态和内核态,用户空间中是不能直接对设备的外设进行使用而内核态中却可以,这时我们需要在内核空间中将需要的外设驱动起来供用户空间使用.linux的驱 ...
- Gym 100169E Tetrahedron Inequality
大致题意: 给出六条边,判断是否能组成四面体 分析: 四面体由四个三角形组成,所以每一条边肯定要符合三角形的任意两边大于第三边的性质.一开始以为这样判断就可以了,然而这题并没有这么简单. 如右图,有四 ...
- Linux系统下安装MongoDB
下载安装包 去MongoDB官网https://www.mongodb.com/try/download/community,下载社区版的安装包: 我的Linux系统是CentOS 7.5版本的,通常 ...
- Springboot quartz集群(3) — 多节点发送邮件
本期将提供quartz集群能力 集群案例分析: 上一期的邮件发送功能,若在服务需要部署多节点,但定时任务不支持集群,因此,多节点定时任务势必会同时运行, 若向用户发送邮件通知,这种情况下会向用户发送两 ...
- CG-CTF WxyVM2
一.原本以为要动调,因为出现了这个,函数太长,无法反编译 后面才知道这玩意可以在ida的配置文件里面去改,直接改成1024. 里面的MAXFUNSIZE改成1024,就可以反编译了,这个长度是超过这个 ...
- buu 新年快乐
一.查壳 发现是upx的壳. 二.拖入ida,发现要先脱壳. 题外话.总结一下手动脱壳,esp定律: 1.先单步到只有esp红色时,右键数据窗口跟随. 2.到数据窗口后,左键硬件访问,byte和wor ...