(论文笔记Arxiv2021)Walk in the Cloud: Learning Curves for Point Clouds Shape Analysis
Walk in the Cloud: Learning Curves for Point Clouds Shape Analysis
漫步在云中:学习点云形状分析的曲线
论文地址:https://arxiv.org/abs/2105.01288
代码:https://curvenet.github.io/
摘要
离散点云对象缺乏足够的三维几何图形的形状描述符。在本文中,我们提出了一种新的方法来聚合点云中的假设曲线。连接点(曲线)的序列最初通过在点云中进行引导行走进行分组,然后聚合回来以增强其逐点特征。我们提供了所提出的聚合策略的有效实现,包括一个新的曲线分组运算符,然后是一个曲线聚合运算符。我们的方法在几个点云分析任务上进行了基准测试,在ModelNet40分类任务上达到了94.2%的最新分类精度,在ShapeNetPart分割任务上达到了86.8%的实例IoU,在ModelNet40法线估计任务上达到了0.11的余弦误差。我们的项目页面位于:https://curvenet.github.io/ 。
1、引言
点云是一系列室内/室外计算机视觉应用中的主要数据结构。现在,各种各样的三维传感器(如激光雷达传感器)能够捕捉现实世界中的物体,通过对表面上的离散点进行采样,可以将它们投影到数字形式。为了更好地理解三维目标,需要有效的点云分析技术和方法。随着深度学习的蓬勃发展,先锋著作[26,28]及其追随者[20,6,43,1,42,7,17,47]通过精心设计的神经网络处理点云,学习输入点坐标与地面真值标签之间的潜在映射。与传统的二维视觉任务不同,点云通常是不规则和无序的,因此,有效地设计点云之间的特征聚集和信息传递方案仍然是一个挑战。
局部特征聚合是近年来被广泛研究的一种基本操作。对于每个关键点,其邻域点特征首先按预定义规则(例如KNN)进行分组。随后计算查询点与相邻点之间的相对位置编码,并将其传递到各种基于点的变换和聚合模块中进行局部特征提取。 尽管上述操作在一定程度上有助于描述局部模式,但忽略了长程点关系。 虽然非局部模块[34]提供了一种聚合全局特征的解决方案,但我们认为全局点到点映射可能仍然不足以提取点云形状隐含的底层模式。
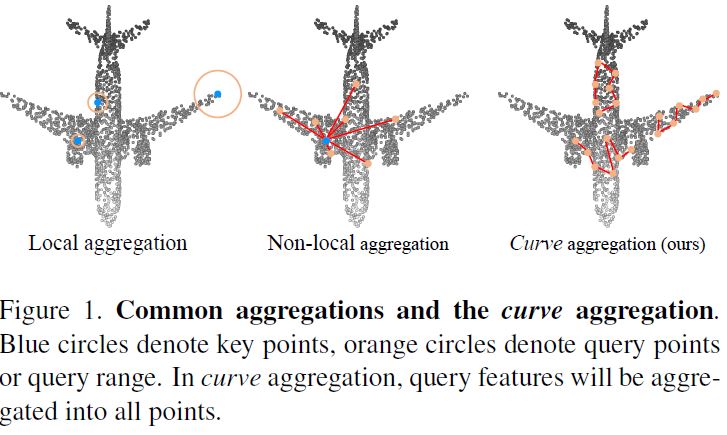
为此,我们提出通过在点云曲面上生成连续的点线段序列来改进点云几何学习。我们认为,与目前流行的局部和非局部算子相比,这种连续描述子更适合描述点云对象的几何结构。我们把这样的连续描述符表示为曲线。通过将点云视为一个无向图,其中离散点作为图节点,相邻点连接作为图边,因此曲线可以描述为图中的行走。图1直观地比较了局部聚合、非局部聚合和曲线聚合操作符。在本文中,我们首先回顾了局部特征聚合的一般形式,并深入讨论了为什么需要长距离特征聚合策略(第3.1节)。然后,我们通过定义曲线分组策略(第3.2节)以及曲线特征和点特征之间的聚合(第3.3)。 一个新的点云处理网络CurveNet是通过将所提出的模块和几个基本的构建块集成到ResNet[4]风格的网络中来构建的。
本文的主要贡献有三个方面:
(1)提出了一种新的点云形状分析的特征聚合方法。对点(曲线)序列进行分组和聚合,以便更好地描述点云对象的几何图形。提出了一种新的曲线分组算子和曲线聚集算子来实现曲线特征的传播
(2)我们研究了分组循环的潜在缺点,并提供了相应的解决方案。此外,还提出了一种动态编码策略,使得曲线在抑制潜在交叉的同时能够包含更丰富的信息
(3)我们将曲线模块嵌入到一个名为CurveNet的网络中,该网络在目标分类、法向量估计和目标部件分割任务上取得了最新的结果。
2、相关工作
3D点云处理
点云分析的最大挑战之一是处理非结构化表示。从间接表示变换方法[16,11,29,13]到直接特征传播方法[26,46,6],许多工作已经朝着有效的点云分析方向发展。
作为最早的直接方法之一,PointNet/PointNet++[26,28]利用共享mlp来学习逐点特性。随后,最近的工作将逐点方法扩展到各个方向,包括设计高级卷积运算[12、42、37、19],考虑更宽的邻域[14、49、35、21],以及它的自适应聚合[6、43、48、44]。上述方法的成功离不开特征聚合算子的帮助,它实现了深层网络中离散点的直接信息传递。
现有的特征聚合算子一般可分为两类:局部特征聚合和非局部特征聚合。作为局部聚集算子的代表,EdgeConv[35]学习关键点与其特征空间邻域之间的语义位移。非局部聚集算子的兴起始于非局部网络[34],通过非局部网络将全局特征转换并聚集在一起,学习多对一特征映射。随着Transformer[33]最近在视觉任务中的成功应用,Guo等人[3]设计了一个由简单Transformer组成的点云处理架构。
除了局部和非局部的特征聚集算子外,我们还提出了一种新的点云分析方法,即对形状分段、边缘和曲线进行特殊处理。通过聚集额外的曲线特征,可以丰富潜在的信息,从而得到更好的特征描述。
3D点云中的采样技术
采样技术聚集了指示点模式,因此对所有点云处理方法都是必不可少的。基于体素化的方法[27、36、38、23]将离散点空间转换为三维网格(体素),其中输入点云表现为连续三维空间上的离散采样。然而,这种采样的质量对细分频率非常敏感。与基于体素化的采样方法类似,基于视图的方法[32、10、39]通过从不同角度捕捉点云的2D快照来采样3D信息,并基于2D图像的集合进行预测。在这样的图像采样过程中,空间信息的丢失是不可避免的。
最近文献中的先进采样方法克服了上述缺点,在基本点云分析任务中取得了很好的结果。GS-Net[41]利用特征图对具有相似欧氏距离和几何信息的点进行分组。PointASNL[43]和SOCNN[46]对相邻点和全局点进行采样,以获得点云对象的完整描述。与上述方法不同的是,PAT[44]借助变压器[33]对点云建模,并通过Gumbel Softmax门学习点采样。在最近的一项工作中,RandLA Net[6]回顾了多种不同的采样技术,并采用了随机采样来实现非常高效的点云处理。与现有的采样方法不同的是,我们将相邻的点段作为曲线进行采样和分组,这些曲线包含了描述物体形状和几何结构的丰富信息。
3、方法
在这一节中,我们描述提出的对任意点云P={p}及其逐点特征F={f}的曲线进行分组和聚合的运算符。如上所述,曲线表示点云中点的连接序列,可以正式定义为:
定义1(点云中的曲线) 给定P,F和同构图G=(F,E) 用KNN算法计算P上的连通度E。将特征空间中长度为l的曲线c生成为F中的点特征序列,使得C = {s1,··· ,sl|s∈F} 。为了对曲线进行分组,我们考虑一个定义在同构图G上的行走策略π,它从起点s1开始一条行走(曲线)并过渡到l步。
3.1局部特征聚合的再思考
局部特征聚合的一般目的是在k个元素的局部空间中学习底层模式。对于每个点p,邻域N = {p1,··· ,pk}首先采用确定性规则进行分组,KNN算法由于其计算效率高,是最常用的分组算法[6,43,20,46]。然后,计算N中每两个元素之间的成对差值,并将其叠加在一起。最后,使用共享mlp进一步聚合计算出的编码,得到局部聚合的特征g。形式上,上述局部特征聚合过程可以表述为:
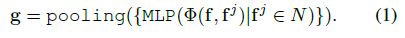
使用曼哈顿距离Φ(f,fj) = f − fj 作为相对编码是最自然的做法,已被广泛采用。然而,我们认为这种编码方法并不能提供丰富的相对信号,因为点云中的大多数g在相同的特征通道中包含几乎相同的信息(不管池策略如何),特别是在浅层中,如图2所示。由于从三维物体的显式表示R中采样的原始点云是无序的,点云P可视为在R上建模的特定概率密度函数U中采样的一组随机变量,使得P ~U(R)。通过一定数量的网络层传播后,F成为随机变量集P上的变换。
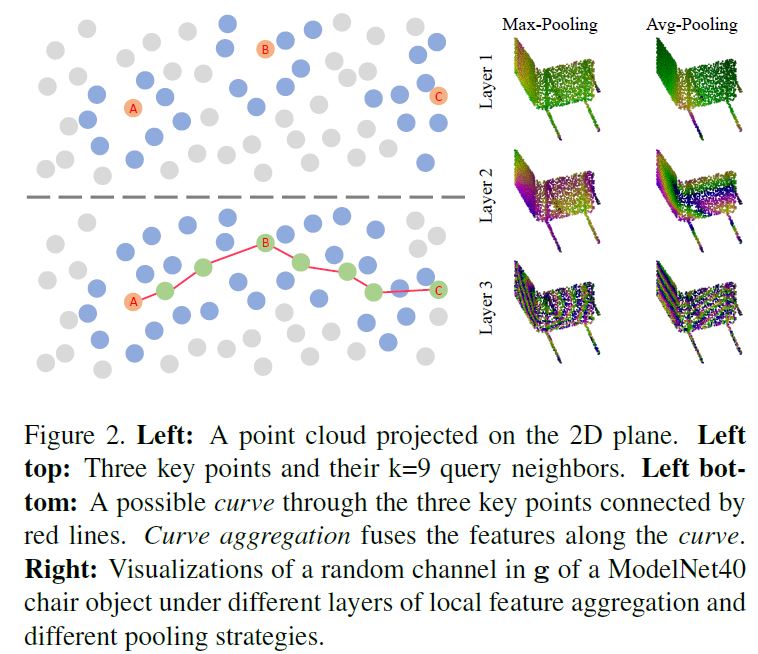
图2。左:投影在二维平面上的点云。左上角:三个关键点及其k=9查询邻居。左下:通过红线连接的三个关键点的可能曲线。曲线聚合沿曲线融合特征。右:在不同的局部特征聚合层和不同的池策略下,ModelNet40椅子对象的随机通道的可视化。
我们首先考虑一个极端情况,其中F表示初始点特征,例如F=P。使用简单的2D平面(图2左)作为示例R,稀疏点分散在R2的紧致子空间上。在图2左上角,三个关键点用它们的KNN计算邻域突出显示。从实践中可以观察到,在采样点之后,{PA-PAj}和{PB-PBj}最有可能具有相似的值,因为关键点被它们的查询邻居以相似的模式包围。但是,边界上的点C(三维空间中的一条边或一段不规则的曲面)是一个例外。受R的几何结构限制,C点查询邻域的分布与A、B点查询邻域的分布有很大的不同,导致{PC-PCj}的变化。
基于上述观察,我们声称,在任何结构化PDF中,确保在相似几何体上具有相同的采样行为,等式1中的g依赖于F和P的分布。点云对象具有相似的几何信息,在g中编码相似和不可分辨的信息。如右图2所示,椅子的靠背和座椅在同一通道中具有紧密的特征,尤其是在浅层中。丰富g的一个可能策略是使用更多的相对编码规则,而不是仅仅使用元素差异[6,1]。在本文中,我们通过组合从曲线聚集的特征来丰富局部特征g,如图2左下角所示。每一条曲线在点云中覆盖一条长路径,编码独特的几何信息,可以用来进一步增加点特征的多样性
3.2 曲线分组
在本小节中,我们将详细介绍如何在点云的特征空间中对曲线进行分组。曲线的起点对整体分组质量至关重要。要同时将n条曲线分组,需要预先确定在Rn×||f||中设置的起点。借用文献[2]中的top-k选择方法,我们使用一个sigmoid门控MLP来学习F中每个点特征的选择分数。起始点是得分最高的n分。为了实现梯度流,我们通过自注意力机制的方式将分数乘以F。
在构建起始点集之后,然后步行W从起点s1中的一个开始并且以正好l步的方式过渡。通过W移动的点被分组形成曲线c。给定走i步后到达的曲线si的中间状态(在特征空间中对曲线分组时si在数值上等于fi),我们感兴趣的是找到一个走i+1步时确定曲线下一个状态的行走策略π(si)。对于预定义的π(·),可能最终通过反复执行以下等式l次,可以对曲线c = {s1,··· ,sl}进行分组:
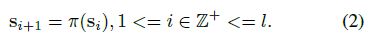
良好的π(·)对于保证有效的曲线分组至关重要。我们提出了一种可学习的π(·)策略来代替确定性策略,该策略可以与骨干网络一起进行优化。更详细地说,对于状态s,我们在状态描述符hs ∈ R2||s||上应用mlp来决定下一步。状态描述符被构造为点特征si和曲线描述符ri的拼接,这将在本小节后面介绍。因此,可以通过MLP学习Ns中所有相邻点上的选择logits α。然后,我们将α输入到评分函数(例如softmax),以便在[0;1]中为每个邻居分配一个基于分数的乘数。得分最高的点就是π(·)的输出。形式上,我们将π(s)表示为:
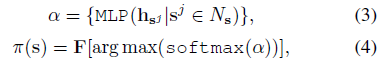
其中hsj是KNN邻居sj的状态描述符。在前向传播中,等式4用计算出的α确定下一个状态。然而,在反向传播过程中,arg max掩盖了梯度,因此等式3中的MLP不能按预期更新。
给定计算的α,我们提出了一个替代方程,方程4丢弃arg max门并启用梯度流。首先,我们为生成一个硬一位热编码的得分向量,而不是从softmax函数获得的软得分。通过使用gumbel softmax[9,22,44]作为评分函数,logits可以根据arg max索引转换为一个热向量。通过gumbelsoftmax计算的梯度与通过softmax计算的梯度相同。然后,我们将查询邻居与一位热编码得分向量相乘,并将乘法相加。上述运算的最终结果在数值上与式4计算的结果相同。因此,我们可学习的策略定义如下:

其中, .表示沿特征维度的广播乘法。上述流程的概述如下图3所示。
通过用最高分点扩展曲线,π(·)基于邻域中的状态描述符来确定曲线的行进方向。我们首先采用一种简单的方法,将状态描述符hsj构造为s和邻居sj的直接拼接。然而,这种幼稚的方法很容易导致圆圈,因为等式3在每个点的相同输入总是有相同的输出。循环是具有重复s的c = {s1,··· ,sl},它携带冗余和有限的信息,因此应该避免。图4显示了四种可能的圆圈,在KNN计算过程中,通过排除关键点本身,可以很容易地避免自身构成的圆圈。为了避免其他圆圈,简单的状态描述符形式是不够的。
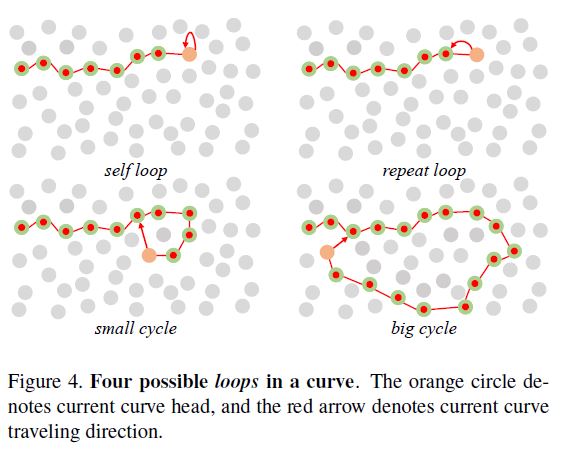
图4:曲线中四个可能的圆圈。橙色圆圈表示当前曲线头,红色箭头表示当前曲线行进方向。
动态动量
避免圆圈的关键在于考虑当前曲线进度对状态描述符进行动态编码。我们在步骤i中维护曲线描述符ri ∈ R||s||,该描述符对曲线的前缀进行编码。现在,关键点si的每个邻居的状态描述符hsj变为sj i和ri的串联。
受[8]的启发,我们按照动量范式更新ri。 但是,我们发现在最终结果方面设置固定的动量系数是有限的。我们提出曲线的前缀r可以通过动态动量变体更好地编码,例如:
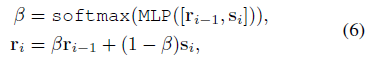
其中[]表示拼接。图3底部说明了动态动量范例。
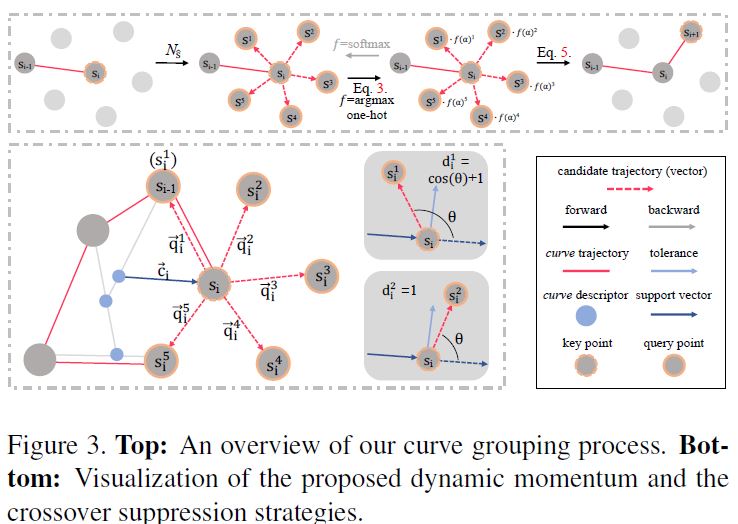
图3.上图:曲线分组过程概述。底部:提出的动态动量和交叉抑制策略的可视化。
交叉抑制
尽管动态动量策略避免了圆圈,但是曲线可能仍会遇到交叉现象。与圆圈不同,少量的交叉可能暗示有用的模式,因此不应完全避免。 但是,当发生大量交叉时,将重复包含同一节点,这会损害曲线表示。因此,我们建议通过研究曲线的行进方向来抑制交叉。
我们首先在步骤i处构造一个支持向量ci=si-ri-1表示电流曲线的大致方向。随后,对于曲线头si的每个查询邻居,我们将候选向量计算为qi=sij-si, c与q之间的角度Θ表示曲线是直线还是转弯。我们通过缩小具有较大值(即可能会掉头并引起潜在交叉)的αj来抑制交叉。
具体来说,我们通过余弦相似度确定c与q之间的角度Θ,并且每个向量对的测量值严格落在[-1,1]。接近-1的值表示两个向量在相反的方向(应被抑制),而1表示它们在相同的方向(不应被抑制)。 考虑到潜在空间中存在边界,如果不转弯就无法永远直线弯曲。 因此,我们将公差阈值角度设置为θ¯,只有夹角大于θ¯ 需要抑制。根据上述直觉,然后通过将余弦相似度得分移动并裁剪为[0,1]来构造交叉抑制乘法器dj。 通过用dj缩放候选的logit αj可以抑制潜在的交叉。图3底部概述了交叉抑制策略。
3.3 曲线聚合和CurveNet
如第3.1节所述,曲线聚合的目的是丰富相关编码的信道内特征变化φ,最终为g提供了更好的描述。为了简单起见,我们将特征通道的数量定义为C,点的数量定义为P,并将一个基本的注意力池化操作符[6]定义为AP。在AP中,input features ∈ RC×∗以自注意力机制的方式进行衡量,并沿着∗ 维度求和,导致RC×1。
给定分组曲线C ={c1,··· ,cn} ∈RC×n×l,为了聚集曲线中的特征,我们考虑了曲线之间的相互关系和每条曲线内部的关系。我们首先学习曲线间特征向量finter ∈ RC×l和曲线内特征向量fintra ∈ RC×n,通过沿不同轴在C上应用AP。点特征F与finter和fintra一起被馈送到三个单独的瓶颈mlp以减少特征维数。我们分别用降维的finter和fintra在降维的F上应用矩阵乘法来学习相应的曲线点映射。使用Softmax函数将映射转换为分数。在另一个分支中,用两个额外的mlp进一步变换降维后的fintra和finter,然后通过矩阵乘法分别与计算出的映射分数融合。上述过程最终得到两个细粒度特征向量fintra0 和 finter0,其形状为RC×P。我们沿着特征轴将fintra0 和 finter0连接起来,并馈入最终MLP。曲线聚合的输出是原始输入的残差加法。
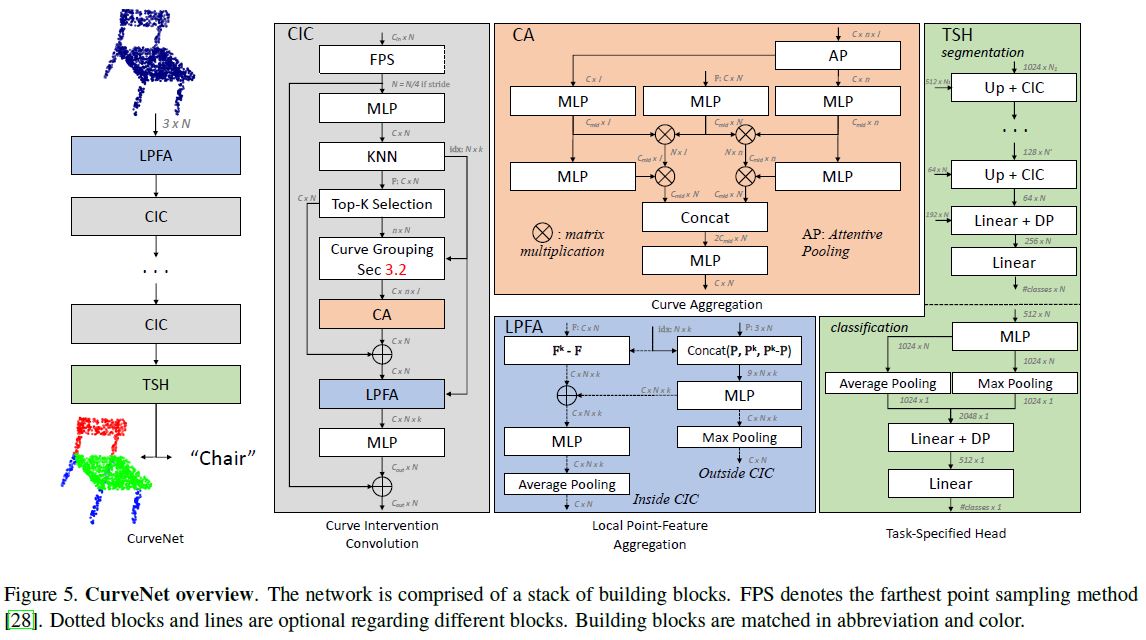
图5。CurveNet概述。网络由一堆构建块组成。FPS表示最远点采样方法[28]。对于不同的块,虚线块和虚线是可选的。构建块在缩写和颜色上是匹配的。
我们将曲线分组(CG)块和曲线聚集(CA)块嵌入到曲线干预卷积(CIC)块中。在每个CIC块中,曲线首先分组(第3.2节),然后聚合到所有点特征(第3.3节)。我们将8个CIC块堆叠在一起,构建一个ResNet[4]风格的网络,称为CurveNet。我们的CurveNet最初通过局部点特征聚合(LPFA)块学习输入点坐标的相对局部编码,将相对点之差投影到更高的维度。CurveNet最终通过任务指定头(TSH)对不同的点云处理任务进行预测。对于分类任务,首先将提取的点特征集合起来,然后传递到两个全连接层中。对于分割任务,我们使用了一个注意力U-Net[24]风格的解码器,它连接了来自编码器的注意力跳跃连接。图5给出了CurveNet的概述。网络结构和构建块细节见补充材料。
4、实验
我们目前的实验结果为我们的点云对象分析方法的目标分类,形状部件分割和法向量估计任务。
4.1 应用细节
在所有实验中,在最后的线性层中采用了dropout[31],概率为0.5[35]。我们在主干子网中使用LeakyReLU作为激活函数,在任务特定的头中使用ReLU。 θ¯设置为90度。为了消除随机性的影响,在所有实验中都固定了随机种子,这些实验是在PyTorch框架中实现的[25]。
对于分类任务,我们使用动量为0.9的SGD作为优化器,并将KNN中的邻居数设置为20。对于分割任务,根据不同的半径动态设置KNN邻域数,不超过32个。在上采样期间,点特征的插值类似于[26]。通过交叉熵损失使预测值与地面真值之间的距离最小化。
4.2 基准
物体分类 ModelNet 10/40数据集[38]是对象形状分类基准中最常用的数据集,用于收集各种对象的网格CAD模型。ModelNet10数据集由分布在10个不同类别中的4899个单独模型组成。我们按照[18]中相同的模式分割训练和测试样本。在一个更大的同构数据集中,ModelNet40由12311个模型组成,这些模型分为40个类别。在这两个数据集中,我们只使用1024个均匀采样点的坐标作为网络输入。在输入网络之前,这些点被标准化为单位球体。首先在采样点上乘以[0.66,1.5]范围内的随机缩放倍数。然后,通过[-0.2,0.2]内的随机位移沿三个方向平移每个点。缩放和转换设置与[11,19]中使用的设置一致。我们训练了200个时期的模型,从学习率为0.1开始,在200个epochs内cosineannealling scheduled为0.001。批大小设置为32用于训练,16用于验证。
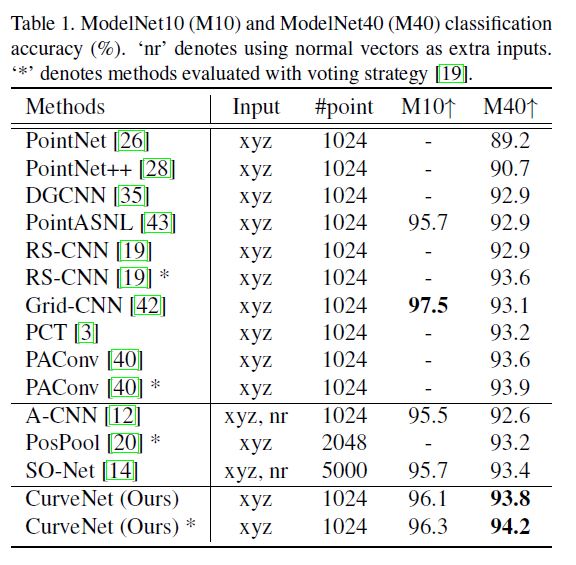
表1报告了我们的CurveNet和最新方法之间的比较结果。在大规模ModelNet40数据集上,我们的方法仅使用1024个均匀采样点,在没有投票的情况下达到了93.8%的最新结果[19],在平均10个预测投票的情况下达到了94.2%。在ModelNet10子集上,我们也获得了96.3%的结果,这是所有具有相同训练数据的方法中第二好的结果。在图6中,我们可视化了局部聚集的特征、聚集的长距离特征和一些随机选择的曲线。曲线能够覆盖长距离语义,从而在很大程度上带来了通道的多样性。
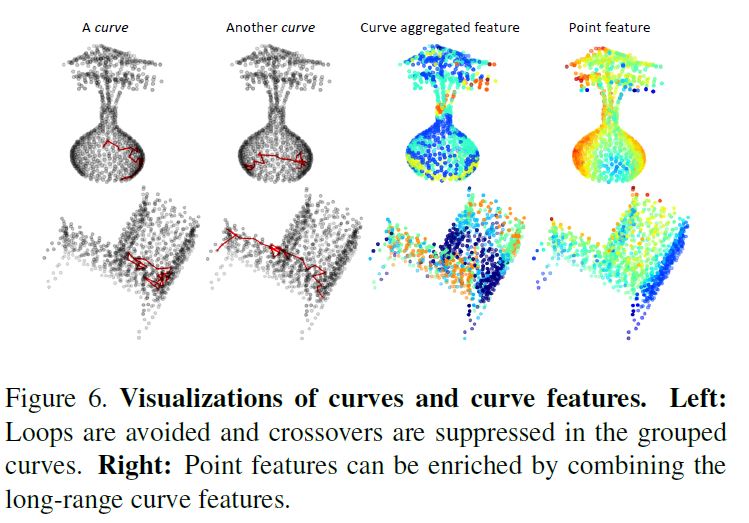
图6。曲线和曲线特征的可视化。左:在分组的曲线中避免循环并抑制交叉。右:点特征可以通过组合长程曲线特征来丰富。
物体部件分割
我们在shapenet零件数据集[45]上验证了我们的方法,用于三维形状零件分割任务。该数据集收集了16个类别的16881个形状模型。数据集中的大多数对象都标记了不到6个部分,结果总共有50个不同的部分。我们的训练和测试分割方案遵循[26,28],这样12137个单独的模型被用作训练样本,而其余的被用作验证和测试。从每个模型中统一抽取2048个点作为我们网络的输入。我们训练了150个epochs的模型,批次大小为32,从学习率为0.05开始,在140和180个阶段衰减为0.1。动量衰减和重量衰减分别设置为0.9和0.0001。我们在CurveNet的最后一个线性层之前插入了一个简单的SE[5]模块。与[19,1]相同,还采用了一个热类标签向量和全局特征向量。
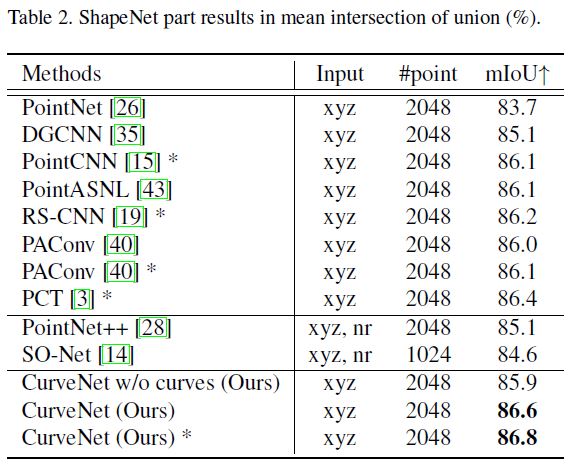
各实例的平均交并比(mIoU)结果见表2,各类别的mIoU分数见补充材料。我们的方法达到了86.6%的最高水平,超过了现有的所有方法。在不分组任何曲线的情况下,我们的基本结构达到85.9%,证明了在点云形状分割任务中引入曲线的有效性。此外,我们定性地观察了四个案例以及图7中的学习曲线。分组曲线能够探索短距离和长距离形状关系。补充材料中报告并分析了模型复杂性。

图7。曲线和分割结果的可视化。随机选择的曲线用随机颜色绘制。
物体法向量估计 物体表面法线是三维建模和渲染的关键。与逐部分理解对象不同,估计法线需要全面了解整个对象的形状和几何体。我们使用ModelNet40数据集验证了我们的CurveNet在估计法线上的有效性,其中点云中的每个点都用其三个方向的法线进行了标记。CurveNet结构的构造与分割任务中使用的结构类似,不包括一个热类标签向量和全局特征向量。模型的初始学习率为0.05,余弦为0.0005。
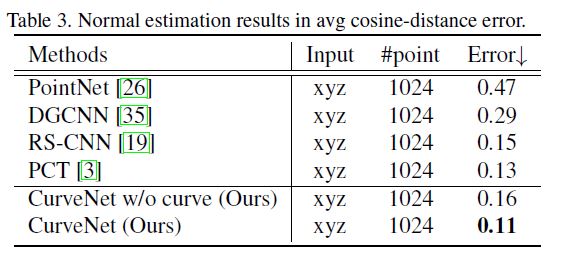
表3显示了CurveNet和最新方法的平均余弦距离误差比较。在没有任何曲线的情况下,我们的基本CurveNet架构实现了0.16的平均误差,接近于[19,3]。当涉及曲线时,我们的全曲线网络表现出了优异的性能,平均误差为0.11,为法向量的估计任务设置了一个新的基准。
4.3 消融研究
我们在ModelNet40数据集上进行了大量的实验,对本文提出的方法进行了全面的研究。除非明确指定,否则实现细节仍然与基准部分中描述的细节相同。所有消融研究均未经投票机制下进行了实验。
成分研究 通过简单地从完整的CurveNet体系结构中移除或替换它们来检查CurveNet的单个组件的影响。我们进行了实验,将LPFA替换为等式1中的公共局部特征聚合,禁用动态动量和交叉抑制策略,并将建议的CA算子替换为普通非局部模块(即内部关系和内部关系不分离)。结果见表4。
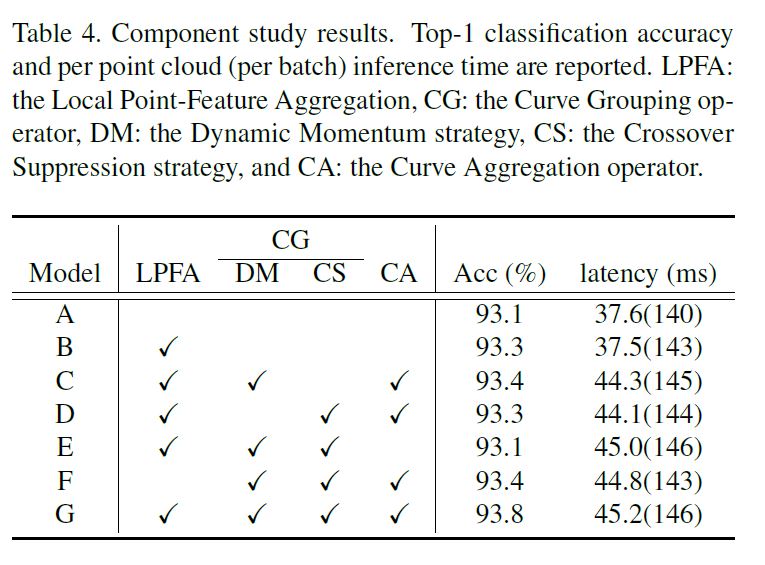
我们观察到,虽然单独使用LPFA不能带来显著的性能改进(模型A和B),但是在曲线的干预下,LPFA的存在能够在分类结果(模型F和G)方面产生巨大的差异。如模型C和D所示,所提出的动态动量和交叉抑制策略在经验上是有效的。此外,从模型E中,我们发现所提出的曲线聚集算子在曲线网络中起着最重要的作用,当通过非局部模式聚集分组的曲线特征时,准确率下降了0.7%,而对推理延迟没有好处。
浅层vs深层 在3.1节中,我们认为局部聚集后的浅层特征缺乏单通道多样性,并且曲线特征在网络的浅层比深层更理想。我们在曲线网络的不同分组上进行了不同数量和长度的聚集曲线的实验,结果显示在补充材料中(图1)。浅层(1/2组)的聚集曲线比深层(3/4组)的结果更好,这从经验上证明了我们的观点。
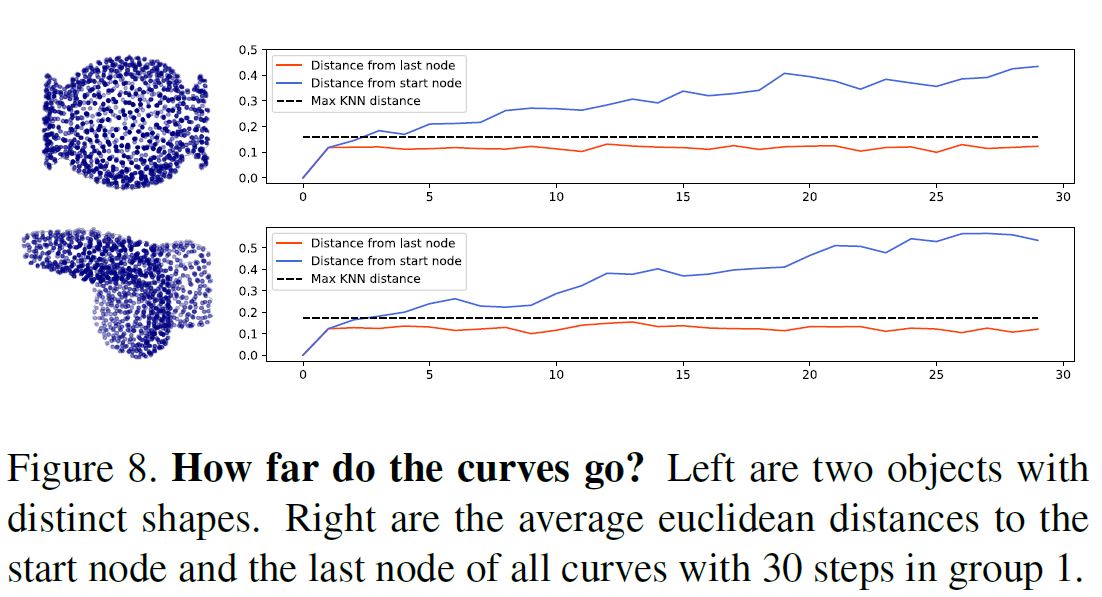
曲线数量与曲线长度 曲线数量n和长度l是直接决定网络性能的两个超参数。短曲线不能捕捉长距离模式,而长曲线需要更好的引导,可能包含冗余信息。为了研究曲线数量与曲线长度的关系,我们进行了固定曲线总点数的实验。补充资料右下方的图1显示,虽然长曲线(长度50)能够获得最佳结果,但随着曲线的进一步延伸,网络性能会下降。聚合较长的曲线也是计算效率低下的,因为节点的过渡无法并行计算。为了验证曲线是否被困在局部区域,我们在图8中给出了曲线的每个节点到起点/终点的平均欧氏距离。这些曲线能够跳出最大局部KNN范围来探索更大范围的关系。
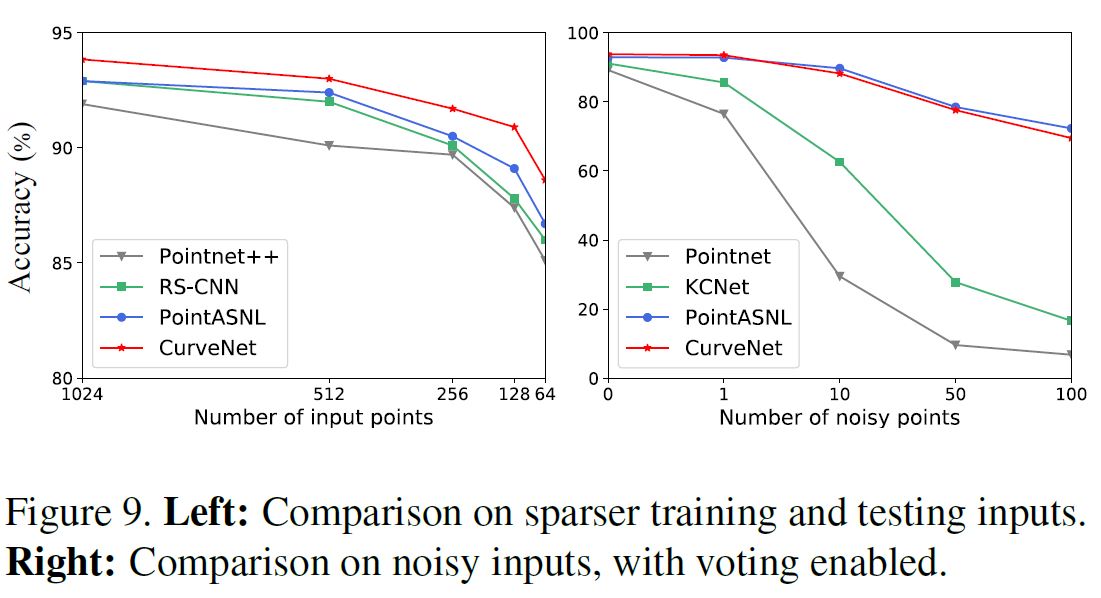
稀疏输入点和噪声测试点 曲线分组对点云稀疏性和噪声敏感。我们进行了广泛的实验:(1)训练和测试稀疏的输入点和(2)训练1024点原始坐标和测试噪声点[43]。如图9所示,我们的CurveNet在所有关于不同输入点数的实验中都取得了最好的结果。对于噪声测试,我们在第一个LPFA块之后添加一个额外的max池层。我们的CurveNet在所有实验中都优于[30,26],并达到了[43]的标准结果,证明了它对噪声的鲁棒性。
5、总结
本文提出了一种用于点云形状分析的长距离特征融合方法,即曲线融合方法。我们首先讨论了现有局部特征聚合范式的潜在缺陷,并提出了点云几何聚合的必要性。然后,我们在两个连续的步骤中提出了我们的方法:在点云中对曲线进行分组的规则,以及分组曲线特征与提取的点特征的集成。在此过程中,确定并解决了潜在的问题。我们的方法在多个点云目标分析任务中取得了最新的成果。
(论文笔记Arxiv2021)Walk in the Cloud: Learning Curves for Point Clouds Shape Analysis的更多相关文章
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- 论文笔记:A Review on Deep Learning Techniques Applied to Semantic Segmentation
A Review on Deep Learning Techniques Applied to Semantic Segmentation 2018-02-22 10:38:12 1. Intr ...
- 论文笔记 — MatchNet: Unifying Feature and Metric Learning for Patch-Based Matching
论文:https://github.com/ei1994/my_reference_library/tree/master/papers 本文的贡献点如下: 1. 提出了一个新的利用深度网络架构基于p ...
- 【论文笔记】A Survey on Federated Learning: The Journey From Centralized to Distributed On-Site Learning and Beyond(综述)
A Survey on Federated Learning: The Journey From Centralized to Distributed On-Site Learning and Bey ...
- 论文笔记 Spatial contrasting for deep unsupervised learning
在我们设计无监督学习模型时,应尽量做到 网络结构与有监督模型兼容 有效利用有监督模型的基本模块,如dropout.relu等 无监督学习的目标是为有监督模型提供初始化的参数,理想情况是"这些 ...
- 论文笔记之:DualGAN: Unsupervised Dual Learning for Image-to-Image Translation
DualGAN: Unsupervised Dual Learning for Image-to-Image Translation 2017-06-12 21:29:06 引言部分: 本文提出 ...
- 【论文笔记】多任务学习(Multi-Task Learning)
1. 前言 多任务学习(Multi-task learning)是和单任务学习(single-task learning)相对的一种机器学习方法.在机器学习领域,标准的算法理论是一次学习一个任务,也就 ...
- 论文笔记——NEURAL ARCHITECTURE SEARCH WITH REINFORCEMENT LEARNING
论文地址:https://arxiv.org/abs/1611.01578 1. 论文思想 强化学习,用一个RNN学一个网络参数的序列,然后将其转换成网络,然后训练,得到一个反馈,这个反馈作用于RNN ...
- 论文笔记:(ICML2020)On Learning Sets of Symmetric Elements
目录 摘要 一.引言 二.先前的工作 三.基础 3.1 符号和基本定义 3.2 G-不变网络 3.3 描述等变层 3.4 Deep sets 四.DSS层 4.1 对称元素集合 4.2 等变层的表征 ...
随机推荐
- Python语言规范之Pylint的使用
1.Pylint是什么 pylint是一个Python源代码中查找bug的工具,能找出错误,和代码规范的运行.也就是你的代码有Error错误的时候能找出来错误,没有错误的时候,能根据Python代码规 ...
- 《MySQL面试小抄》索引考点二面总结
<MySQL面试小抄>索引考点二面总结 我是肥哥,一名不专业的面试官! 我是囧囧,一名积极找工作的小菜鸟! 囧囧表示:小白面试最怕的就是面试官问的知识点太笼统,自己无法快速定位到关键问题点 ...
- Vue(9)购物车练习
购物车案例 经过一系列的学习,我们这里来练习一个购物车的案例 需求:使用vue写一个表单页面,页面上有购买的数量,点击按钮+或者-,可以增加或减少购物车的数量,数量最少不得少于0,点击移除按钮,会 ...
- Fiber 树的构建
我们先来看一个简单的 demo: import * as React from 'react'; import * as ReactDOM from 'react-dom'; class App ex ...
- CosId 1.1.0 发布,通用、灵活、高性能的分布式 ID 生成器
CosId 通用.灵活.高性能的分布式 ID 生成器 介绍 CosId 旨在提供通用.灵活.高性能的分布式系统 ID 生成器. 目前提供了俩大类 ID 生成器:SnowflakeId (单机 TPS ...
- WUSTCTF2020 funnyre
运行起来,发现啥都没反应也没输出,ida直接打开,反编译 .init函数动调了下,发现没啥用,主要核心在于main函数,直接跟进去 发现了核心逻辑,有花指令,直接去掉,发现还挺多,然后似乎不影响观看, ...
- mybatis 配置的log4j文件无效,不能正常显示日志信息
正在学习mybatis,配置好后log4j.properties文件后,日志信息不能正常显示,没有效果. 查看了一下mybatis的相关文档,在日志一栏找到问题愿意 原因是我们的mybatis选了其他 ...
- WPF教程十四:了解元素的渲染OnRender()如何使用
上一篇分析了WPF元素中布局系统的MeasureOverride()和ArrangeOverride()方法.本节将进一步深入分析和研究元素如何渲染它们自身. 大多数WPF元素通过组合方式创建可视化外 ...
- postgresql 使用游标笔记
游标介绍:游标是一种从表中检索数据并进行操作的灵活手段,游标主要用在服务器上,处理由客户端发送给服务端的sql语句,或是批处理.存储过程.触发器中的数据处理请求. 游标的优点在于它允许应用程序对查询语 ...
- 开源的负载测试/压力测试工具 NBomber
负载测试和压力测试对于确保 web 应用的性能和可缩放性非常重要. 尽管它们的某些测试是相同的,但目标不同. 负载测试:测试应用是否可以在特定情况下处理指定的用户负载,同时仍满足响应目标. 应用在正常 ...