nGrinder 参数使用
背景:
性能测试中为了更加接近真实模拟现实应用,对于提交的信息每次都需要提交不同的数据,或使用不同的值,最为典型的就是登录时的账号。
性能测试工具需要提供动态参数化功能,如商业化的LoadRunner就提供了非常强大的参数化支持,可支持各种参数取值方式,循环取值,或随机取值
而且还提供了参数模拟测试的功能,可以说非常完善
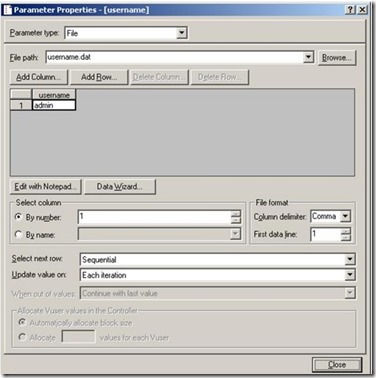
另外目前常用的性能测试工具Jmeter也提供了参数化的支持,如提供了"CSV Data Set Config"组件,可设置取值出的变量和取值结束后是否循环等
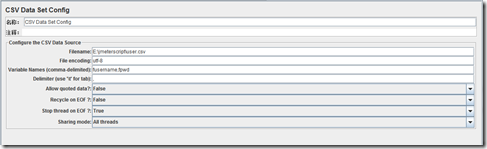
在nGrinder中怎么设置参数呢,它并没有提供现成的参数化工具,你无法直观的设置参数取值方法,都只能在脚本中处理
在开始之前我们需要更深刻得去理解测试场景中进程,线程等的概念
线程,进程,测试次数:
在测试场景设置中,我们先简单假设不根据时间测试,只根据次数来测试,那么在测试场景中,需要设置的参数就包括了
进程数,线程数,测试数
虚拟用户数=进程数*线程数
测试总数=虚拟用户数*测试数
就是说,如果进程数设置为5,线程数设置为2,那么虚拟用户数为10
如测试数设为3,那么一共运行的测试总次数为10*3=30

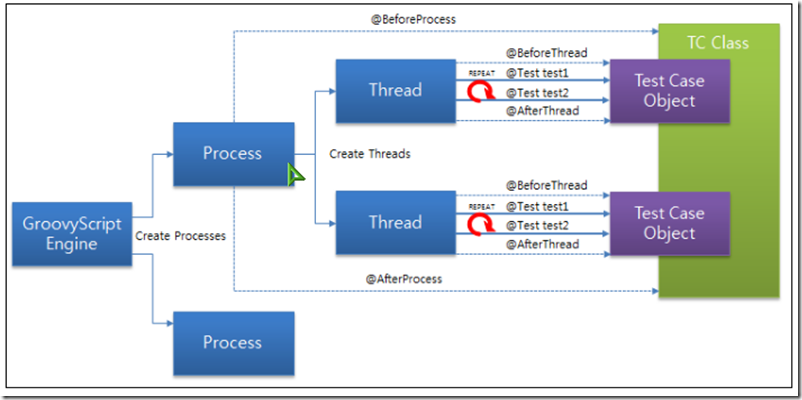
再回想一下,之前Groovy脚本中的结构,BeforeThread,或者AfterThread,在帮助中的这幅图,可以更清楚的说明整个过程,在图中
每个进程下有若干的线程,每个线程,执行若干次测试
Groovy脚本获取相关的值:
在Groovy中,通过提供的方法可获取包括当前的进程号,当前的线程号,总的进程数,总的线程数,当前的测试数,总测试数等信息
如测试进程数设置为5,测试线程数设置为2,测试数为3
在Groovy脚本中
1 processnumber=grinder.processNumber //获取当前的进程号,应该会相应返回0,1,2,3,4
2 totalprocess=grinder.getProperties().getInt("grinder.processes", 1) //获取测试的进程总数,返回5
3 threadnumber=grinder.threadNumber //获取当前的线程号,应该会相应返回0,1
4 totalthread=grinder.getProperties().getInt("grinder.threads", 1) //获取测试的线程总数,应该返回2
5 run=grinder.runNumber;//获取当前的测试号,应该相应返回1,2,3
6 totalrun=grinder.getProperties().getInt("grinder.runs", 1); //返回测试的总数,如3
因此现在在每个测试中,我们都可以明确获取测试的进程,线程和测试数的相关信息
当我们需要做参数化的时候,就可以根据这些信息来进行计算
nGrinder中有线程,有进程,还有测试数的概念,所以计算参数的时候,其实比LoadRunner或Jmeter更复杂,Jmeter中只有线程的概念。
当我们试图要弄明白里面的这些概念时,要慢慢来,先尝试着把设置弄简单点,然后再逐步逐步设置的复杂,才更容易理解
下面我们假设几种场景来说明如何取值,假设把一份账号存放在资源中,我们要取的参数就是这个账号,可能需要循环取,可能需要不重复的取
脚本参数_循环取数,单进程,账号资源冗余:
设置的场景如下:

这个场景中,我们简单得把进程设置为1,这样就只需要考虑多线程,然后测试次数设置为5,但线程数量小于资源账号数
假设资源中账号为QAARKTESR_0001,QAARKTESR_0002.。。。QAARKTESR_0010
我们预期的取值应该是:

在Groovy中,在一开始先就把文件读取过来,然后转换为字符数组
def array = new File('./resources/accountlist.txt') as String[]
那在每次测试的时候,只要使用当前的线程号,0,1,2就可以取得账号
为了简单说明,在Groovy中,打印当前的线程,当前的测试次数,和取得的账号
grinder.logger.info("thread number, run, account {},{},{}",grinder.threadNumber,grinder.runNumber,array[grinder.threadNumber]);
测试执行之后,查看日志输出
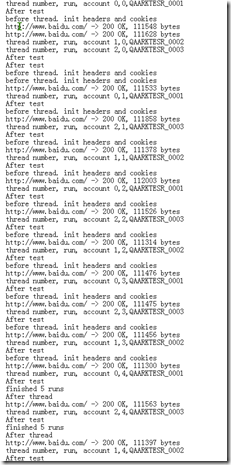
检查日志,可以看到输出符合我们的预期,线程从0到2,执行次数从0到4,取了三个账号,每个执行了5次
脚本参数_循环取数,但进程,账号资源缺乏
还是刚才的场景,只是我们让线程数大于资源数量

此时账号只有了三个,QAARKTESR_0001,QAARKTESR_0002,QAARKTESR_0003
这样的时候,我们预期的参数取值应该是这样,其中,账号循环取值

仍然是把账号读取到数组中,我们仍然是通过线程的号去取数组中的账号,但因为数组长度要小于线程数,所以此时需要用取余的操作
int len=array.size(); //先取数组的长度,此时应该返回3
int arrayindex=grinder.threadNumber%len; //每次循环的账号应该是等于线程数%长度
grinder.logger.info("thread number, run, account {},{},{}",grinder.threadNumber,grinder.runNumber,array[arrayindex]);
测试场景设置
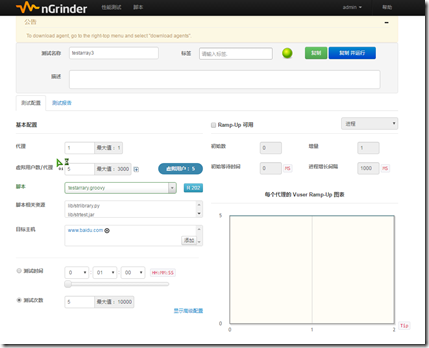
查看测试日志:
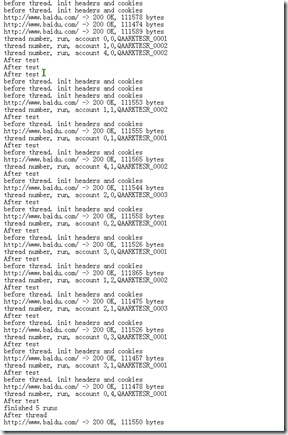
可以看到线程3,此时循环取得的账号是账号1 thread number, run, account 3,0,QAARKTESR_0001
线程4 ,此时循环取的账号是账号2 ,thread number, run, account 4,0,QAARKTESR_0002
脚本参数_循环取数,多进程,账号资源冗余
刚才在1,2两种场景中,我们都把进程设置为1,这样我们就可以只考虑线程,但如果我们把进程也添加进来,那么如何循环取参数呢?
一旦把进程考虑进来,就要比之前的要复制多了,我们还是先看比较简单的情况
此时我们假设,账号的数要大于虚拟用户的数
账号我们仍然是QAARKTESR_0001一直到QAARKTESR_0010
场景设置如下:
那么我们预期的参数取值,应该是这样的
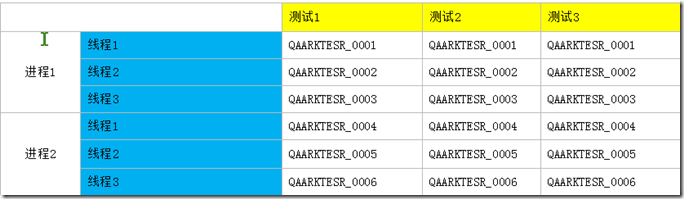
那么这个时候,我们要取的账号就需要进行一下简单的计算
序号=线程总数*当前的进程号+当前的线程号
注意,所有的进程,线程,测试号都是从0开始
如第一个进程,进程号就是0 ,线程总数是3
那么每个线程中,计算的方法,就是0*3+0,1,2
int threadcount=grinder.getProperties().getInt("grinder.threads", 1); //取线程总数,因为是3
int arrayindex=grinder.processNumber*threadcount+grinder.threadNumber;
grinder.logger.info("thread number, run, account {},{},{}",grinder.threadNumber,grinder.runNumber,array[arrayindex]);
场景设置:
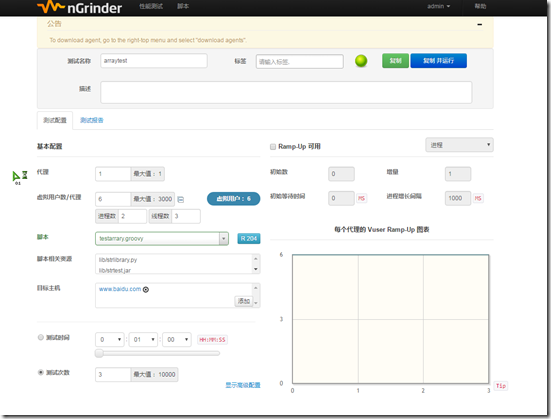
运行之后查看日志,可以发现因为收到日志的限制,直接可以查看的只是一个进程的日志,另外一个进程的日志没办法查看到
本身日志显示或查看的限制,所以只能看到线程1,2,3各自取了账号QAARKTESR_0001,QAARKTESR_0002,QAARKTESR_0003
思考:
如果本身是多进程,多线程,那么如果账号数量还小于总的线程数,那么如何计算呢
其实公式和刚才的公式是一样的,只是在最后取余一下账号总数
即序号=( 进程号*线程总数+线程号)%账号总数
脚本参数_保证参数唯一性:
有时候我们需要在循环取参数的时候保证每个参数都是唯一取一次,比如注册账号,第二重复注册可能就已经是失败了
那么这时,我们需要每次测试的时候都需取唯一的数据
我们还是先设置进程数量为1,此时仍然只需要考虑线程数
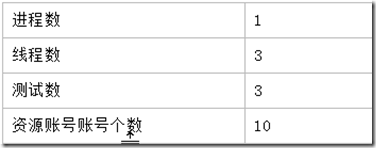
那么这个时候,其实测试次数其实是9,而我们准备的账号总数是10,所以是充分的,准备正好的9个账号也是可以的,应该不会影响最后的取值
按照这样的设置,我们预期的结果应该是这样的
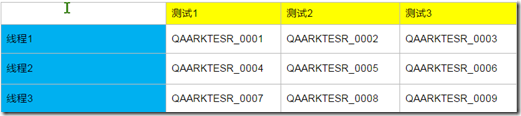
那么如何计算得出这样的参数呢
取账号序号=(当前线程号*循环测试总数)+当前的测试数序号
如当前线程号是1,循环测试总数固定是3 ,当前测试序号是1
那么应该取的序号是 1*3+1=4
groovy中的脚本应该
int testcount=grinder.getProperties().getInt("grinder.runs", 1); //测试总数,应该为3
int arrayindex=(grinder.threadNumber*testcount)+grinder.runNumber;// 取在数组中的序号
grinder.logger.info("thread number, run, account {},{},{}",grinder.threadNumber,grinder.runNumber,array[arrayindex]);
实际设置场景
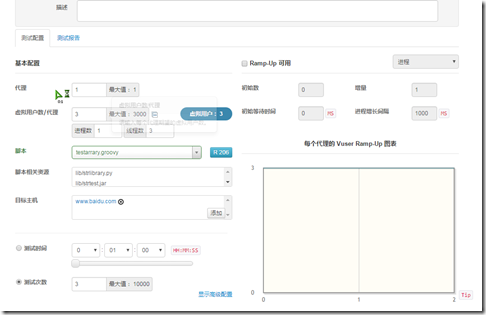
运行,然后查看日志,可以看到实际循环了9个账号,和我们的预期是一样的
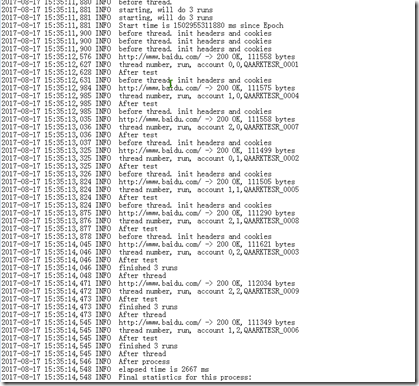
这个方式其实相当于LoanRunner中参数设置中取值方式为Unique的方式,但通过这种方式计算的时候,因为本身是要保证数据不重复,所以测试循环次数,还有数据要自己计算好,日常工作中常常遇到的是不重复的循环注册账号的场景
但这个场景中,我们还是简单的把进程数设置为了1,只考虑多线程
如果循环取数,同样是多线程的时候,怎么计算出这个序号呢
其实思路是一样的,只是公式看上去要复杂一点点
序号=(进程数*线程总数*测试总数)+(线程数*测试总数)+当前的测试序号
只要明白了nGrinder中的进程,线程,循环测试的概念,并且我们本身都是可以从方法中取得这些数据,所以不论多进程,多线程,还是单进程,单线程都是一样的,都是可以计算出来的
参考资料:
1 http://debugtalk.com/post/head-first-locust-advanced-script/
nGrinder 参数使用的更多相关文章
- nGrinder安装指南
NGrinder 由两个模块组成,其运行环境为 Oracle JDK 1.6 nGrinder controller web 应用程序,部署在Tomcat 6.x 或更高的版本 nGrinder A ...
- nGrinder Loadrunner vs nGrinder
s d 功能 参数类型 取值方式 迭代方式 Loadrunner实现方式 nGrinder实现方式 参数化 文件 sequential (顺序取值) Each Iteration (每次迭代) 在参 ...
- 性能测试工具 nGrinder 项目剖析及二次开发
转:https://testerhome.com/topics/4225 0.背景 组内需要一款轻量级的性能测试工具,之前考虑过LR(太笨重,单实例,当然它的地位是不容置疑的),阿里云的PTS(htt ...
- nGrinder工具进行接口性能测试
1.背景 之前在这篇文章中性能测试初探—接口性能测试介绍过nGrinder,本文将介绍在nGrinder脚本中使用资源文件中数据作为接口参数和解析生成的CSV结果,生成TPS标准差,TPS波动率,最小 ...
- 基于Groovy编写Ngrinder脚本常用方法
1.生成随机字符串(import org.apache.commons.lang.RandomStringUtils) 数字:RandomStringUtils.randomNumeric(lengt ...
- Ngrinder 源码之Maven 项目
Ngrinder支持Maven结构的测试脚本.使用ScriptHandlerFactory来个脚本选择处理器handler,目前有JythonScriptHandler, GroovyScriptHa ...
- Ngrinder脚本开发各细节锦集(groovy)
Ngrinder脚本开发各细节锦集(groovy) 1.生成随机字符串(import org.apache.commons.lang.RandomStringUtils) 数字:RandomStrin ...
- 【.net 深呼吸】细说CodeDom(6):方法参数
本文老周就给大伙伴们介绍一下方法参数代码的生成. 在开始之前,先补充一下上一篇烂文的内容.在上一篇文章中,老周检讨了 MemberAttributes 枚举的用法,老周此前误以为该枚举不能进行按位操作 ...
- Angular2入门系列教程6-路由(二)-使用多层级路由并在在路由中传递复杂参数
上一篇:Angular2入门系列教程5-路由(一)-使用简单的路由并在在路由中传递参数 之前介绍了简单的路由以及传参,这篇文章我们将要学习复杂一些的路由以及传递其他附加参数.一个好的路由系统可以使我们 ...
随机推荐
- Servlet的特点及运行过程
- 刷题-力扣-230. 二叉搜索树中第K小的元素
230. 二叉搜索树中第K小的元素 题目链接 来源:力扣(LeetCode) 链接:https://leetcode-cn.com/problems/kth-smallest-element-in-a ...
- Supervisor服务开机自启动
要解决的问题 在机器上部署自己编写的服务时候,我们可以使用Supervisor作为进程检活工具,用来自动重启服务. 但是当机器重启后,Supervisor却不能自动重启,那么谁来解决这个问题呢? 答案 ...
- 用tinyxml2读写xml文件_C++实现
下载源代码 开源代码github地址: https://github.com/leethomason/tinyxml2 添加工程文件 将源代码目录中 tinyxml2.h 和 tinyxml2.cpp ...
- 笔记:如何使用postgresql做顺序扣减库存
如何使用postgresql做顺序扣减库存 Ⅰ.废话在前面 首先这篇笔记源自于最近的一次需求,这个临时性需求是根据两份数据(库存数据以及出库数据) 算出实际库存给到业务,至于库存为什么不等于剩余库存, ...
- WAMP 2.5 无法访问局域网的解决方法
打开Apache配置文件 httpd.conf (该文件在wamp\bin\apache\apache2.4.9\conf) DocumentRoot "d:/wamp/www/" ...
- MybatisPlus(一)——
MybatisPlus https://www.cnblogs.com/JohanChan/p/14982870.html
- Java 字符串格式化和工具类使用
前言 我们在做项目时候经常需要对字符串进行处理,判断,操作,所以我就总结了一下java 字符串一些常用操作,和推荐比较好用我在自用的工具类,毕竟有轮子我们自己就不用重复去写了,提供开发效率,剩下的时间 ...
- Sentry Web 前端监控 - 最佳实践(官方教程)
系列 1 分钟快速使用 Docker 上手最新版 Sentry-CLI - 创建版本 快速使用 Docker 上手 Sentry-CLI - 30 秒上手 Source Maps Sentry For ...
- SQL Server Management Studio --- SSMS语言更换
问题描述 在安装了En版后,想更换为中文版,但换了中文安装源还是英文. 解决方法 运行 SQL Server Management Studio 通过菜单选择你想要使用的语言: 中文版:"工 ...