Python数模笔记-Sklearn(1) 介绍
1、SKlearn 是什么
Sklearn(全称 SciKit-Learn),是基于 Python 语言的机器学习工具包。
Sklearn 主要用Python编写,建立在 Numpy、Scipy、Pandas 和 Matplotlib 的基础上,也用 Cython编写了一些核心算法来提高性能。
Sklearn 包括六大功能模块:
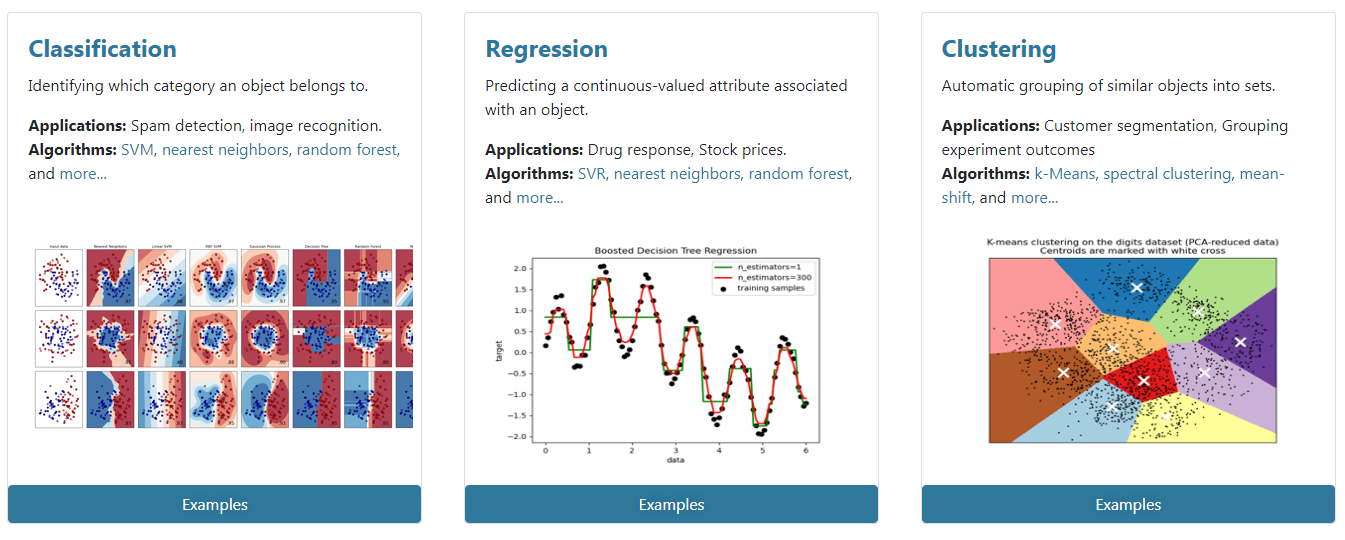
分类(Classification):识别样本属于哪个类别,常用算法有 SVM(支持向量机)、nearest neighbors(最近邻)、random forest(随机森林)
回归(Regression):预测与对象相关联的连续值属性,常用算法有 SVR(支持向量机)、 ridge regression(岭回归)、Lasso
聚类(Clustering):对样本进行无监督的自动分类,常用算法有 k-Means(k均值)、spectral clustering(特征聚类)、mean-shift(均值漂移)
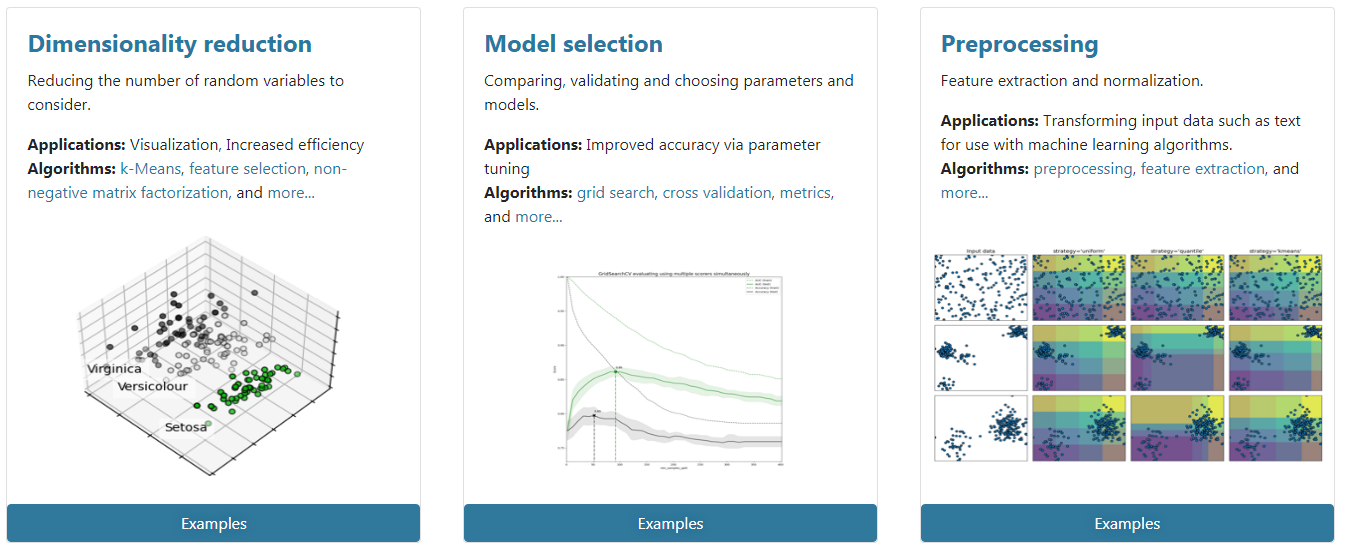
数据降维(Dimensionality reduction):减少相关变量维数,常用算法有 PCA(主成分分析)、feature selection(特征选择)、non-negative matrix factorization(非负矩阵分解)
模型选择(Model Selection):比较,验证,选择参数和模型,常用模块有 grid search(网格搜索)、cross validation(交叉验证)、 metrics(度量)
数据处理 (Preprocessing):特征提取和归一化,常用模块有 preprocessing(预处理),feature extraction(特征提取)
这六个功能模块涉及 4类算法,分类、回归 属于监督学习,聚类属于非监督学习。
官网地址:https://scikit-learn.org/
官方文档中文版: https://www.scikitlearn.com.cn/
内置数据集:https://scikit-learn.org/stable/datasets.html
2、SKlearn 的安装
Sklearn 的安装要求:Python 3.5 以上版本,需要安装 NumPy、SciPy、Pandas 工具包的支持,部分内容需要使用 Matplotlib、joblib 工具包。
pip 安装命令:
pip3 install -U scikit-learn
pip3 install -U scikit-learn -i https://pypi.douban.com/simple
注意 Sklearn 建议安装 Numpy+mkl,可以在网址http://www.lfd.uci.edu/~gohlke/pythonlibs/ 找到你需要的numpy+mkl版本,下载后 pip3安装:
pip install numpy-1.11.1+mkl-cp27-cp27m-win_amd64.whl
3、SKlearn 内置数据集
Sklearn 内置了一些标准数据集可以用于练习和测试,都是经常被引用的经典问题,数据网址:https://scikit-learn.org/stable/datasets.html
Sklearn 标准数据集主要包括:
- 测试问题数据集
- 波士顿房价:Boston house prices dataset
- 鸢尾花问题:Iris plants dataset
- 糖尿病数据:Diabetes dataset
- 手写数字的识别:Optical recognition of handwritten digits dataset
- 葡萄酒鉴别:Linnerrud dataset
- 葡萄酒鉴别Wine recognition dataset
- 威斯康星州癌症诊断:reast cancer wisconsin (diagnostic) dataset
- 实际问题数据集
- 人脸数据:The Olivetti faces dataset
- 20个新闻文本数据:The 20 newsgroups text dataset
- 标记的人脸数据:The Labeled Faces in the Wild face recognition dataset
- 森林覆盖类型:Forest covertypes
- 路透社新闻数据:RCV1 dataset
- 网络入侵检测数据:Kddcup 99 dataset
- 加州住房数据:California Housing dataset
4、Sklearn 数模笔记的计划
粗略看看 Sklearn 的文档,是一个功能强大和丰富的机器学习库,远远超出了数学建模学习的范围。
基于数模教学的目的,本系列主要对应数模学习中的分类、聚类、降维问题,并不打算全面讲解 Sklearn 的各种算法,而是以典型问题为例来介绍原理简单、使用广泛的基本方法,以便新手入门。
版权说明:
YouCans 原创作品
Copyright 2021 YouCans, XUPT
Crated:2021-05-09
Python数模笔记-Sklearn(1) 介绍的更多相关文章
- Python数模笔记-Sklearn(4)线性回归
1.什么是线性回归? 回归分析(Regression analysis)是一种统计分析方法,研究自变量和因变量之间的定量关系.回归分析不仅包括建立数学模型并估计模型参数,检验数学模型的可信度,也包括利 ...
- Python数模笔记-Sklearn(2)样本聚类分析
1.分类的分类 分类的分类?没错,分类也有不同的种类,而且在数学建模.机器学习领域常常被混淆. 首先我们谈谈有监督学习(Supervised learning)和无监督学习(Unsupervised ...
- Python数模笔记-Sklearn(3)主成分分析
主成分分析(Principal Components Analysis,PCA)是一种数据降维技术,通过正交变换将一组相关性高的变量转换为较少的彼此独立.互不相关的变量,从而减少数据的维数. 1.数据 ...
- Python数模笔记-Sklearn(5)支持向量机
支持向量机(Support vector machine, SVM)是一种二分类模型,是按有监督学习方式对数据进行二元分类的广义线性分类器. 支持向量机经常应用于模式识别问题,如人像识别.文本分类.手 ...
- Python数模笔记-StatsModels 统计回归(4)可视化
1.如何认识可视化? 图形总是比数据更加醒目.直观.解决统计回归问题,无论在分析问题的过程中,还是在结果的呈现和发表时,都需要可视化工具的帮助和支持. 需要指出的是,虽然不同绘图工具包的功能.效果会有 ...
- Python数模笔记-StatsModels 统计回归(1)简介
1.关于 StatsModels statsmodels(http://www.statsmodels.org)是一个Python库,用于拟合多种统计模型,执行统计测试以及数据探索和可视化. 2.文档 ...
- Python数模笔记-Scipy库(1)线性规划问题
1.最优化问题建模 最优化问题的三要素是决策变量.目标函数和约束条件. (1)分析影响结果的因素是什么,确定决策变量 (2)决策变量与优化目标的关系是什么,确定目标函数 (3)决策变量所受的限制条件是 ...
- Python数模笔记-NetworkX(3)条件最短路径
1.带有条件约束的最短路径问题 最短路径问题是图论中求两个顶点之间的最短路径问题,通常是求最短加权路径. 条件最短路径,指带有约束条件.限制条件的最短路径.例如,顶点约束,包括必经点或禁止点的限制:边 ...
- Python数模笔记-(1)NetworkX 图的操作
1.NetworkX 图论与网络工具包 NetworkX 是基于 Python 语言的图论与复杂网络工具包,用于创建.操作和研究复杂网络的结构.动力学和功能. NetworkX 可以以标准和非标准的数 ...
随机推荐
- idea配置struts2.5环境
struts2不是struts1的下一代产品,是在struts1和WebWork技术的基础上进行合并后的全新框架,虽然两个名字相似,但是设计思想却有很大的不同. 使用本地的l ib 或者downloa ...
- Solon 框架详解(九)- 渲染控制之定制统一的接口输出
Springboot min -Solon 详解系列文章: Springboot mini - Solon详解(一)- 快速入门 Springboot mini - Solon详解(二)- Solon ...
- 攻防世界 reverse Newbie_calculations
Newbie_calculations Hack-you-2014 题目名百度翻译成新手计算,那我猜应该是个实现计算器的题目.... IDA打开程序,发现一长串的函数反复调用,而且程序没有输入,只有输 ...
- unable to read askpass response from 'C:\Users\wxy\.IntelliJIdea2019.1\system\tmp\intellij-git-askpass.bat' bash: /dev/tty: No such device or address failed to execute prompt script (exit code 1)
解决方法:
- Java例题_26 请输入星期几的第一个字母来判断一下是星期几,如果第一个字母一样,则继续 判断第二个字母。
1 /*26 [程序 26 求星期] 2 题目:请输入星期几的第一个字母来判断一下是星期几,如果第一个字母一样,则继续 判断第二个字母. 3 程序分析:用情况语句比较好,如果第一个字母一样,则判断用情 ...
- 在M1芯片的Mac系统上做.net core开发靠谱吗?
作为一个7年老.NET程序员,最近几年苹果慢慢接替微软,成为我心中最酷的科技公司. 为什么我会选择Mac os作为我的开发环境? 很多做.net的同学都使用Windows系统作为自己的开发环境,我其实 ...
- 全网最值得推荐的ELKB日志学习博客-博客地址留存
博客地址:https://elasticstack.blog.csdn.net/article/details/102728604 博客地址留存,后续解决疑难问题
- 手摸手教你阅读和调试大型开源项目 ZooKeeper
本文作者:HelloGitHub-老荀 Hi,这里是 HelloGitHub 推出的 HelloZooKeeper 系列,免费开源.有趣.入门级的 ZooKeeper 教程,面向有编程基础的新手. 项 ...
- js--原型和原型链相关问题
前言 阅读本文前先来思考一个问题,我们在 js 中创建一个变量,我们并没有给这个变量添加一些方法,比如 toString() 方法,为什么我们可以直接使用这个方法呢?如以下代码,带着这样的问题,我们来 ...
- Java刷题-list
一.打印两个有序链表的公共部分 补充一个关于节点的链表构造方法 Node next是设置指针域 import java.io.IOException;这个是报错信息 这是两个lO流 import ja ...