MySQL插入大量数据探讨
笔者想进行数据库查询优化探索,但是前提是需要一个很大的表,因此得先导入大量数据至一张表中。
准备工作
准备一张表,id为主键且自增:

方案一
首先我想到的方案就是通过for循环插入
xml文件:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.zy.route.mapper.BigBiaoMapper"> <resultMap id="BaseResultMap" type="com.zy.route.DO.BigBiao">
<id column="id" property="id"/>
<result column="menu" property="menu"/>
<result column="operation" property="operation"/>
<result column="uri" property="uri"/>
<result column="msg" property="msg"/>
<result column="creator" property="creator"/>
</resultMap> <sql id="tableName">
bigbiao
</sql> <sql id="BaseColumn">
`id`, `menu`, `operation`, `uri`, `msg`,`creator`
</sql> <sql id="set">
<if test="id != null">
`id` = #{id},
</if>
<if test="menu != null">
`menu` = #{menu},
</if>
<if test="operation != null">
`operation` = #{operation},
</if>
<if test="uri != null">
`uri` = #{uri},
</if>
<if test="msg != null">
`msg` = #{msg},
</if>
<if test="creator != null">
`creator` = #{creator},
</if>
</sql> <insert id="insertIntoBiao" parameterType="com.zy.route.DO.BigBiao">
insert
<include refid="tableName"/>
<set>
<include refid="set"/>
</set>
</insert> </mapper>
这里我就直接使用SpringBoot的测试类进行插入操作
@SpringBootTest
@RunWith(SpringRunner.class)
public class BigBiaoMapperTest { @Autowired
private BigBiaoMapper bigBiaoMapper; @Test
public void insert() {
BigBiao bigBiao = new BigBiao()
.setMenu("项目资料")
.setOperation("查询项目目录")
.setUri("/project/big/biao")
.setMsg("{\"method\":\"Get\"\",\"\"costTime:95\"\",\"\"ip:255.255.255.0\"}")
.setCreator("LonZyuan");
long start = System.currentTimeMillis();
for (int i = 0; i < 1000; i++) {
bigBiaoMapper.insertIntoBiao(bigBiao);
}
long end = System.currentTimeMillis();
System.out.println("执行时间:" + (end - start) + "ms");
}
}
执行,查看执行时间:

可以发现,就单单1000条数据,就花了29s多
原因分析(参考MySQL45讲)
首先我们需要了解一条SQL更新语句是如何执行的:
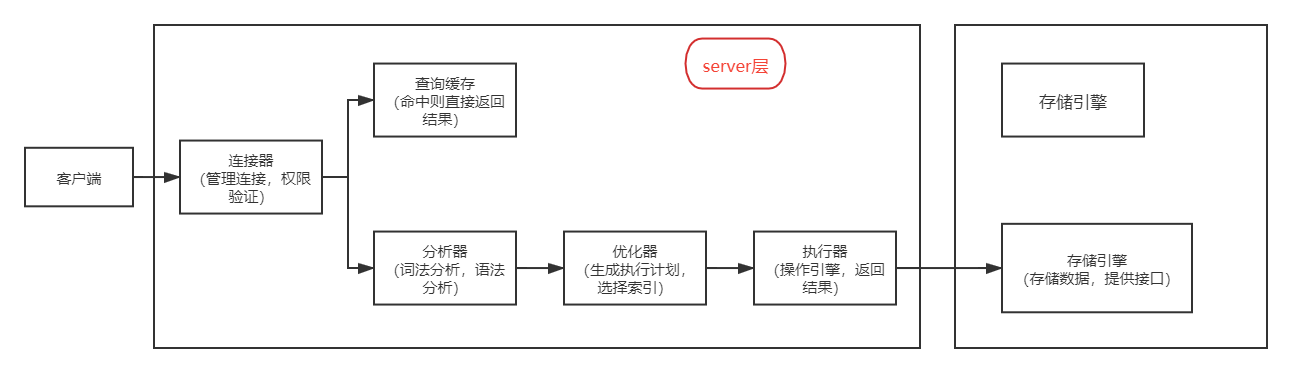
而我方案一中的操作就是,通过for循环,进行了1000次的客户端与数据库的开闭连接,然后每次就写入一条数据,
并且由于表更新后,与该表相关的查询缓存会失效,查询缓存也没用,因此低效是必然的。
方案二
既然一条条插入很慢,那我通过List一次性插入多个不就行了。
xml语句:
<insert id="batchInsert">
insert into
bigbiao
(`menu`, `operation`, `uri`, `msg`,`creator`)
values
<foreach collection="list" item="item" separator=",">
(#{item.menu},#{item.operation},#{item.uri},#{item.msg},#{item.creator})
</foreach>
</insert>
测试类:
@SpringBootTest
@RunWith(SpringRunner.class)
public class BigBiaoMapperTest { @Autowired
private BigBiaoMapper bigBiaoMapper; @Test
public void batchInsert() {
BigBiao bigBiao = new BigBiao()
.setMenu("批量添加2号")
.setOperation("batchAdd")
.setUri("/begin/batch/add/big/biao")
.setMsg("{\"method:Insert\",\"costTime:88\",\"ip:0.0.0.255\",\"添加一堆东西\"}")
.setCreator("LonZyuan");
List<BigBiao> bigBiaos = new ArrayList<>();
long start = System.currentTimeMillis();
for (int i = 0; i < 1000; i++) {
bigBiaos.add(bigBiao);
}
bigBiaoMapper.batchInsert(bigBiaos);
long end = System.currentTimeMillis();
System.out.println("执行时间:" + (end - start) + "ms");
} }
运行,查看执行时间:

速度很快,那我现在插10w条进去:
@Test
public void batchInsert() {
BigBiao bigBiao = new BigBiao()
.setMenu("批量添加2号")
.setOperation("batchAdd")
.setUri("/begin/batch/add/big/biao")
.setMsg("{\"method:Insert\",\"costTime:88\",\"ip:0.0.0.255\",\"添加一堆东西\"}")
.setCreator("LonZyuan");
List<BigBiao> bigBiaos = new ArrayList<>();
long start = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
bigBiaos.add(bigBiao);
}
bigBiaoMapper.batchInsert(bigBiaos);
long end = System.currentTimeMillis();
System.out.println("执行时间:" + (end - start) + "ms");
}
但是又翻车了:

查一下Packet for query is too large,原来MySQL会根据配置文件,限制Server接受数据包的大小,
图中(16500100 > 4194304)就是具体问题点,4194304 B = 4MB,所以是这个值小了。
解决:
这个参数为 max_allowed_packet ,在 ini 配置文件中设置一下:
max_allowed_packet = 20M
重启MySQL,然后再次运行:
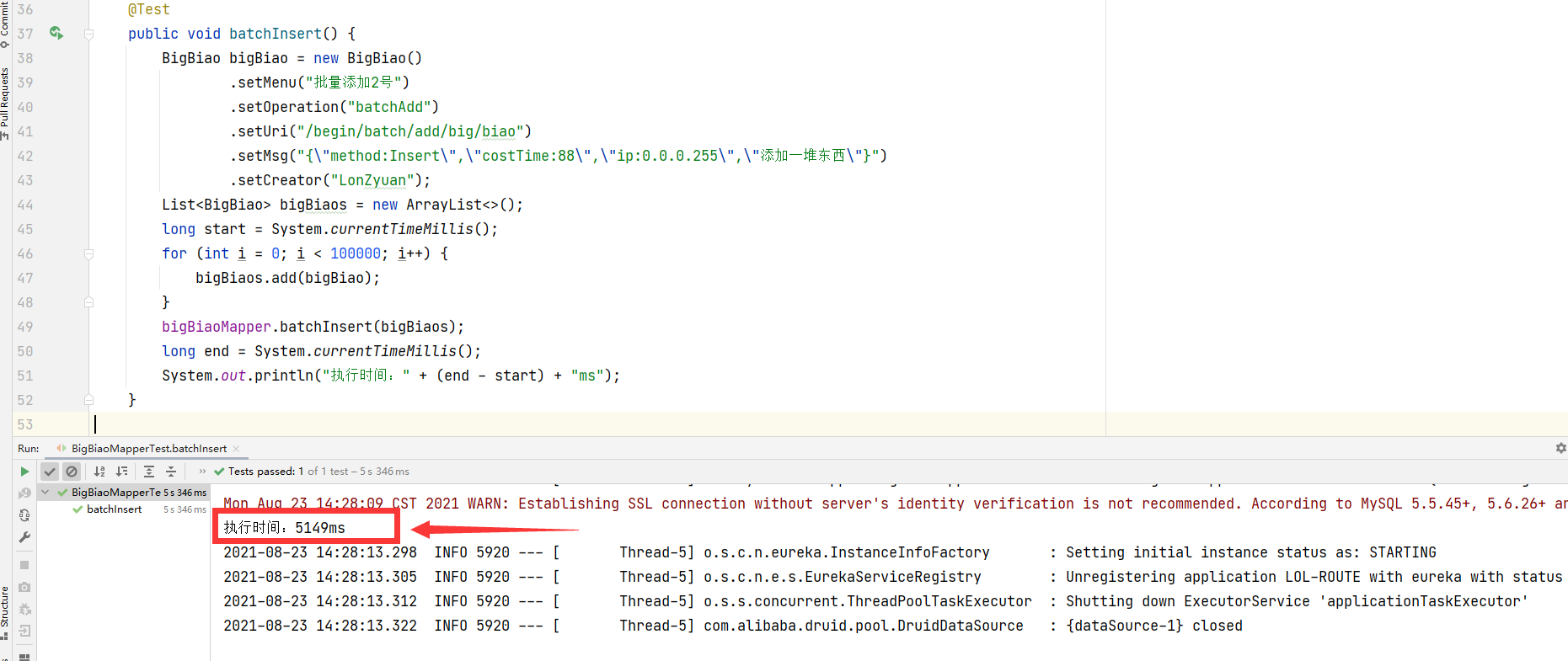
10w条数据插入成功了
这里可能有小伙伴想问那我直接插1000w条进去,那就会发生OOM问题:
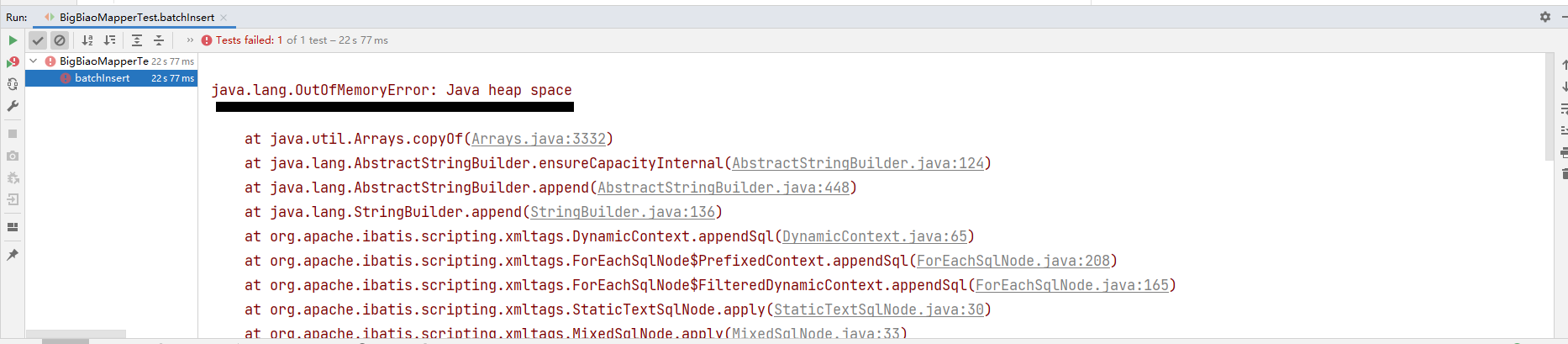
这个问题后续在做探讨。
MySQL插入大量数据探讨的更多相关文章
- mysql 插入/更新数据
mysql 插入/更新数据 INSERT 语句 1.一次性列出全部字段的值,例如: INSERT INTO student VALUES('Chenqi','M', 29); INSERT INTO ...
- [转载]mysql插入大量数据
mysql的批量数据格式, 比如 INSERT INTO TABLES (LABLE1,LABLE2,LABLE3,...) VALUES(NUM11,NUM12,NUM13,...), (NUM ...
- C API向MySQL插入批量数据的快速方法——关于mysql_autocommit
MySQL默认的数据提交操作模式是自动提交模式(autocommit).这就表示除非显式地开始一个事务,否则每个查询都被当做一个单独的事务自动执行.我们可以通过设置autocommit的值改变是否是自 ...
- MySQL插入中文数据出现?号
原文转载自:https://blog.csdn.net/LynneZoe/article/details/79174119 运行环境:win10 mysql版本:Mysql5.6 做一个项目的时候,向 ...
- mysql插入中文数据变成问号怎么处理
插入中文数据变成问号,一般都是因为字符集没有设置成utf8的原因 1.修改字符集: ALTER TABLE 表名 MODIFY 列名 类型(50) CHARACTER SET "utf8&q ...
- laravel 解决mysql插入相同数据的问题
1.背景: 每天0点定时任务统计数据,实现目标是统计时如果没有今天的统计数据,那就执行insert操作 如果存在那就执行update操作: 代码逻辑 1 if(报表存在){ 2 update(); 3 ...
- mysql插入表数据中文乱码问题解决方案
一.问题 开发中遇到将其它数据库数据插入到mysql数据库表中一直会报类似如下错误: Incorrect string value: '\xE6\x88\x91' for column 'name' ...
- MySQL插入大批量数据时报错“The total number of locks exceeds the lock table size”的解决办法
事情的原因是:我执行了一个load into语句的SQL将一个很大的文件导入到我的MySQL数据库中,执行了一段时间后报错"The total number of locks exceeds ...
- MySQL 插入 中文数据乱码解决
问题描述: 1.在命令行中进行插入,没有问题.但是显示存在部分乱码 2.在JDBC中插入成功.中文是直接以“??”形式显示. 通过Navicat客户端查看 与在网页中看到的一一致,说明读取没有问题,问 ...
随机推荐
- Noip模拟78 2021.10.16
这次时间分配还是非常合理的,但可惜的是$T4$没开$\textit{long long}$挂了$20$ 但是$Arbiter$上赏了蒟蒻$20$分,就非常不错~~~ T1 F 直接拿暴力水就可以过,数 ...
- Linux多线程实例解析
Linux系统下的多线程遵循POSIX线程接口,称为 pthread.编写Linux下的多线程程序,需要使用头文件pthread.h,连接时需要使用库libpthread.a.顺便说一下,Linux ...
- 树形DP 枚举祖宗的例题
这类题目是真的很头疼....其实这类题目的特征也很明显,叶子结点贡献答案时和其所在链的祖宗有关,也就是说要想得知其贡献必须知道他的所有祖宗的贡献,其实处理方法也不是太难,就是在dfs枚举时顺便把祖宗的 ...
- 面试题系列:工作5年,第一次这么清醒的理解final关键字?
面试题:用过final关键字吗?它有什么作用 面试考察点 考察目的: 了解面试者对Java基础知识的理解 考察人群: 工作1-5年,工作年限越高,对于基础知识理解的深度就越高. 背景知识 final关 ...
- 正则表达式之grep
grep 的五个参数,基本的常用的: -a :将 binary 档案以 text 档案的方式搜寻数据 -c :计算找到 '搜寻字符串' 的次数 -i :忽略大小写的不同,所以大小写视为相同 -n :顺 ...
- 【Go语言学习笔记】hello world
书接上回,上回说到了为什么要学习Go语言,今天我们来实际写一下,感受一下Go语言的精美之处. 环境搭建 安装和设置 Windows: Go安装包下载网址:https://golang.org/dl/ ...
- CURD系统怎么做出技术含量--怎样引导面试
引子 很多朋友可能会因为自己做的工作不是特别核心或者业务简单而引起面试中没有自信.但是很多公司面试的时候是可以接受面试者之前岗位的并发量.交易量低一些的.比如我们要招聘和我们交易量同等级或者以上的出来 ...
- ssh密码登录
https://stackoverflow.com/a/16928662/8025086 https://askubuntu.com/a/634789/861079 #!/usr/bin/expect ...
- 9组-Alpha冲刺-3/6
一.基本情况 队名:不行就摆了吧 组长博客:https://www.cnblogs.com/Microsoft-hc/p/15546622.html 小组人数: 8 二.冲刺概况汇报 卢浩玮 过去两天 ...
- 25.A Famous Music Composer
描述 Mr. B is a famous music composer. One of his most famous work was his set of preludes. These 24 p ...