PromQL的简单使用
PromQL的简单使用
- 一、背景
- 二、PromQL的数据类型
- 三、字面量
- 四、时间序列选择器
- 五、运算符
- 六、一些内置函数
- 1、abs 绝对值
- 2、absent 判断指标名称或标签是否有值
- 3、absent_over_time 和 absent类似,只是多了一个时间范围
- 4、ceil 四舍五入
- 5、changes 返回区间变量每个样本值变化的次数
- 6、delta 计算区间向量第一个值和最后一个值的差值
- 7、floor 向下取整
- 8、increase 返回区间向量第一个和最后一个样本的增量值
- 9、rate 计算区间向量 v 在时间窗口内平均每秒增长速率
- 10、irate 计算区间向量的增长率,但是它反应的是瞬时增长率
- 11、predict_linear 预测时间序列在n秒后的值
- 12、sort 对向量按元素的值进行升序排序
- 13、sort_desc 对向量按元素的值进行降序排序
- 七、参考文章
一、背景
在prometheus中存在各种时间序列数据,那么我们如何根据时间序列查询想要的数据呢?prometheus为我们提供了强大的PromQL,借助PromQL我们可以查询到自己想要的数据。
二、PromQL的数据类型
- Instant vector(即时向量):一组时间序列,每个时间序列包含一个样本,所有样本共享相同的时间戳。
- Range vector(范围向量):一组时间序列,其中包含每个时间序列随时间变化的一系列数据点。
- Scalar(标量):一个浮点型的数据值。
- String(字符串):一个字符串,当前没有使用到。
注意:
1、如果我们要绘制图形,那么必须返回 Instant vector 类型的数据。
三、字面量
1、字符串字面量
字符串可以使用 ‘’(单引号),""(双引号),``(反引号)来表示。在单引号和双引号中,反斜杠成为了转义字符,后面可以跟着a,b, f, n, r, t, v或者\。
eg:
“this is a string”
‘these are unescaped: \n \ \t’
these are not unescaped: \n ' " \t
2、浮点数字面量
浮点数可以写成以下这种格式
[-+]?(
[0-9]*.?[0-9]+([eE][-+]?[0-9]+)?
| 0[xX][0-9a-fA-F]+
| [nN][aA][nN]
| [iI][nN][fF]
)
eg:
23
-2.43
3.4e-9
0x8f
-Inf
NaN
四、时间序列选择器

1、即时向量选择器
即时向量选择器允许在给定的时间戳(即时)上选择一组时间序列和每个样本的单个样本值。
1、组成部分
指标名称:用于限定特定指标下的时间序列,可选。
匹配器:用于过滤时间序列上的标签,可选。定义在
{}中。
2、指标名称和匹配器的组合
1、只给定指标名称,或者在指标名称上指定空匹配器,这将返回给定指标下的所有时间序列的即时样本数据。
eg:
up 等价于 up{}
2、只给定匹配器,返回符合该匹配器的所有时间序列的即时样本。
eg:
{instance=~".*", job=“prometheus”}
3、同时指定指标名称和匹配器,返回符合给定指标名称和匹配器的即时样本。
eg:
up{job=“prometheus”}
注意:
1、指标名称和匹配器必须要选择一个。
3、匹配器
匹配器主要是用于标签过滤,目前支持如下4种格式。
=: 精确的匹配给定的标签值!=: 不匹配给定的标签值=~: 正则表达式匹配给定的标签值!~: 不匹配正则表格式给定的标签值
eg:
1、查询出指标名称up中标签job等于prometheus的时间序列数据
up{job=“prometheus”}
2、查询出指标名称up中标签job不等于prometheus的时间序列数据
up{job!=“prometheus”}
3、查询出指标名称up中标签job以pro开头的的时间序列数据
up{job=~“pro.*”}
4、查询出指标名称up中标签job不以pro开头的的时间序列数据
up{job!~“pro.*”}
5、查询出指标名称up中不存在标签env的时间序列数据
up{env=""}
5、查询指标名称是以prometheus开头的所有的时间序列数据
{name =~“prometheus.*”}
注意:
=~和!=必须要指定一个标签名字或者匹配的标签必须要有值。eg:{job=~""} 或者 {job=~".*"}都是错的。 {job=".+"}是正确的。上方的正则表达式使用的语法是 RE2 语法
2、区间向量选择器
区间向量选择器和即时向量选择器大致类似,唯一的不同在于表达式之后需要跟一个[]表达需要返回那个区间范围的时间序列数据。
up[5m]表示查询5分钟时间内各实例的状态
1、时间格式
ms(毫秒)、s(秒)、m(分钟)、h(小时)、d(天)、w(周)、y(年)
d 表示一天总是24小时
w 表示一周总是7天
y 表示一年总是365天
可以将多个不同的时间单位串联起来使用,但是大的时间单位必须在前面,小的时间单位在后面,且不同的时间单位只能出现一次。且不能是小数。
eg: 1h30m可以,但是1.5h则不才可以。
3、偏移量修改器
默认情况下,即时向量和区间向量选择器都是以当前时间为准,但是偏移量修改器offset可以修改该基准。偏移量选择器是紧跟在表达式之后使用 offset 来指定的。
eg:
1、表示获取指标名称prometheus_http_requests_total的所有时间序列在过去1分钟的即时样本。
prometheus_http_requests_total offset 1m
2、表示获取指标名称prometheus_http_requests_total的所有时间序列在距离此刻1分钟之前的5分钟之内的样本。
prometheus_http_requests_total[5m] offset 1m
五、运算符
Prometheus的查询语言支持基本的逻辑和算术运算符。
1、算术运算符
支持的算术运算符:
+(加)、-(减)、*(乘)、/(除)、%(取模)、^(幂等)
二元运算操作符可以在scalar/scalar(标量/标量)、vector/scalar(向量/标量)、和vector/vector(向量/向量)之间运算。
- 在两个标量之间运算:得到的结果也是一个标量。
- 在即时向量和标量之间运算:将运算符应用于这个向量中的每个数据样本的值。 eg: 如果时间序列即时向量乘以2,则结果是另外一个向量,另外一个向量中的值是原始向量的每个样本值乘以2。
- 在两个即时向量之间运算:运算符会依次找到与左边向量元素匹配(标签完全一致)的右边向量元素进行运算,如果没找到匹配元素,则直接丢弃。同时新的时间序列将不会包含指标名称。
2、比较运算符
支持的比较运算符:
== (等于)、!=(不等于)、>(大于)、<(小于)、>=(大于或等于)、<=(小于或等于)
比较二元运算符被应用于scalar/scalar(标量/标量)、vector/scalar(向量/标量) ,和 vector/vector(向量/向量)之间。比较运算符得到的结果是 bool 布尔类型值,返回1或者0值。
两个标量之间d额布尔运算:必须要提供一个bool修饰符,运算的结果会产生一个新的标量,值为0(假)或1(真)。
即时向量和标量之间的布尔运算:时序数列中的每个值都会与这个运算符进行运算。
存在
bool修饰符:比较的结果为0和1,指标名称会被删除。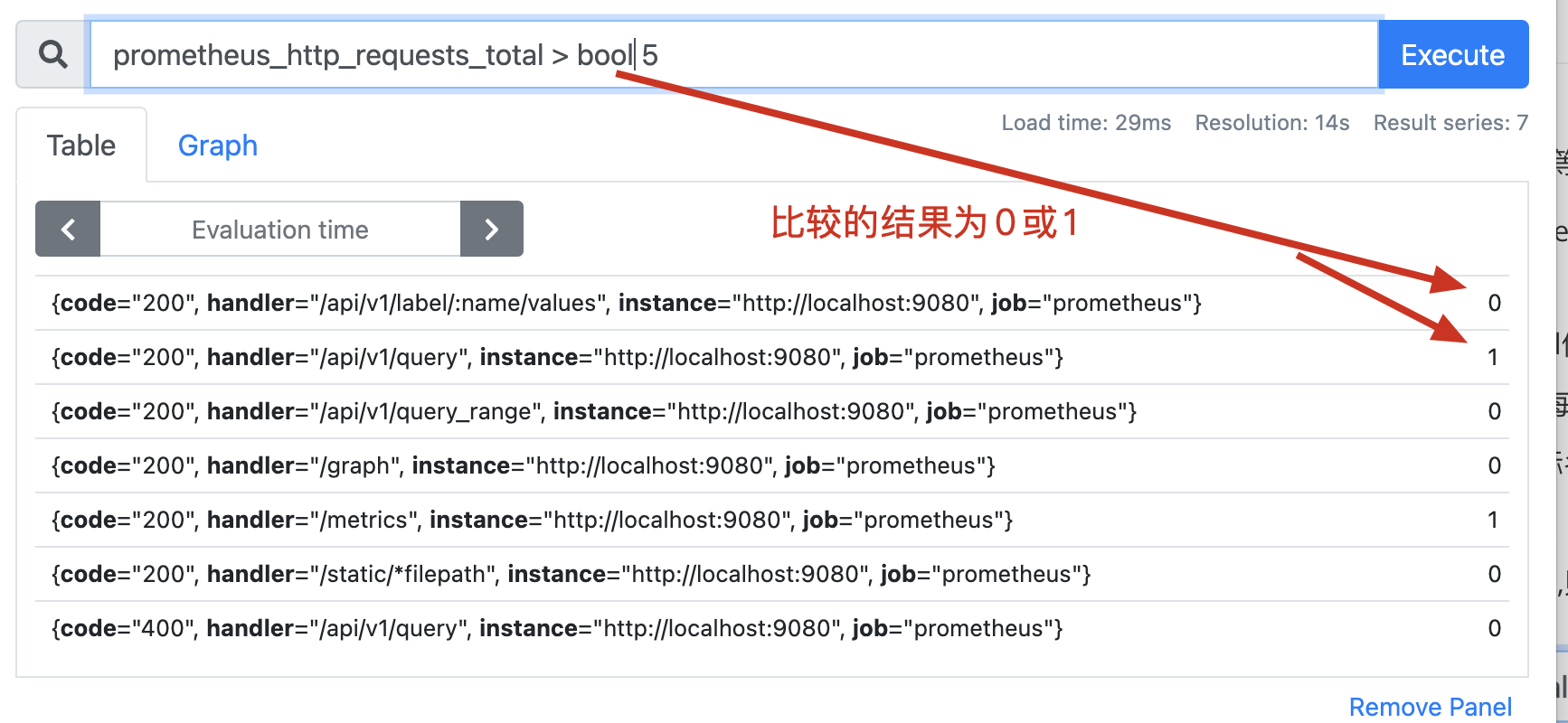
不存在
bool修饰符:如果比较的结果为false,则这个时序数据会被删除,结果为true的保留。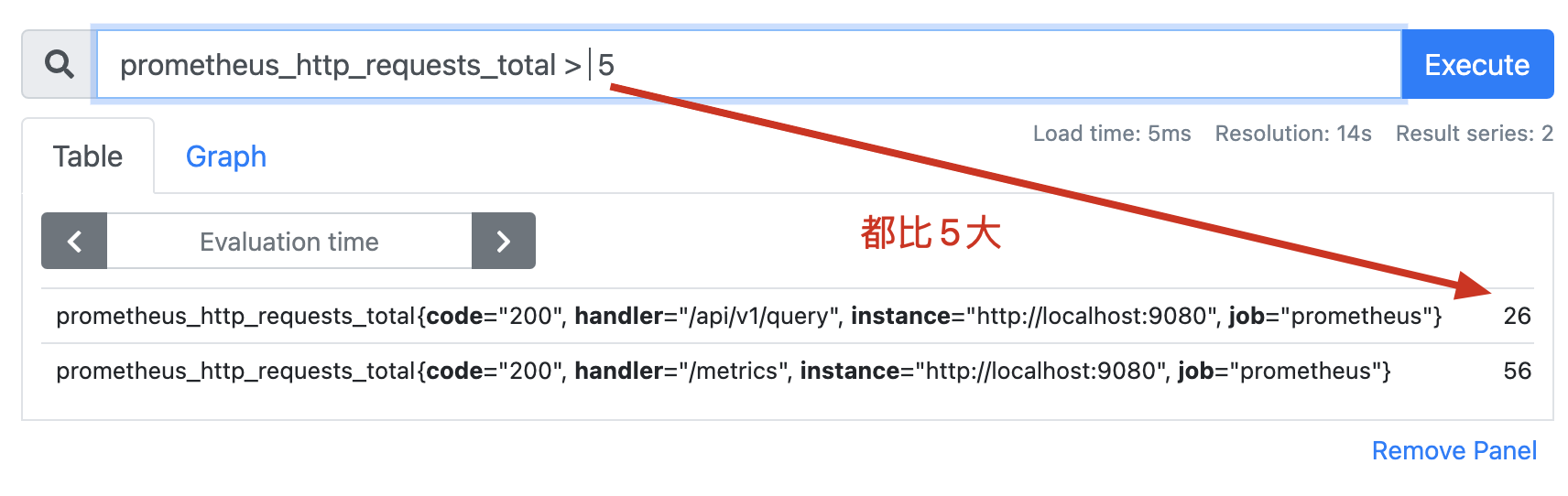
即时量与即时量直接进行布尔运算时,默认情况下,这些运算符的行为类似于过滤器,应用于匹配的条目。
表达式为false或在表达式的另一侧未找到匹配项的向量元素将从结果中删除,而其他元素将传播到结果向量中,分组标签将成为输出标签集。
如果提供了bool修饰符,则将被删除的向量元素的值为0,而将被保留的向量元素的值为1,
分组标签将再次成为输出标签集。如果提供了bool修饰符,则会删除指标名称。
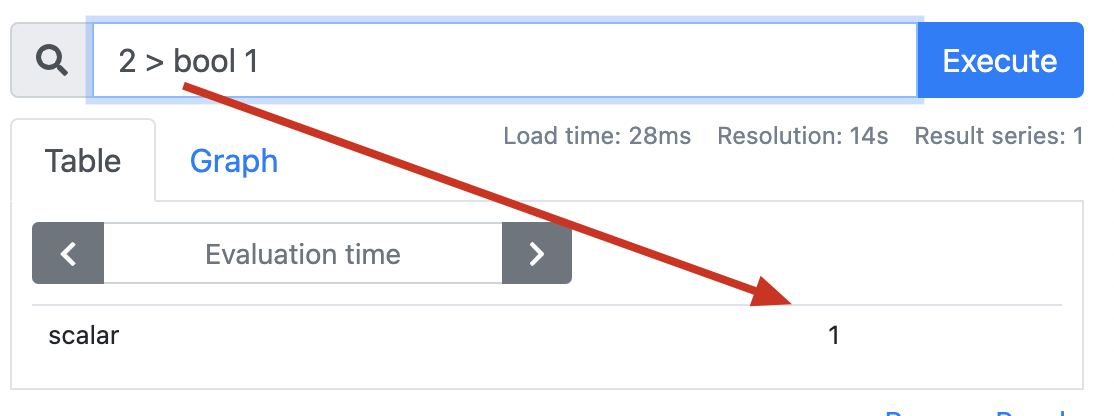
3、集合运算符
集合运算符只支持在2个即时变量之间的运算。
支持的集合运算符:
and(并且-交集)、or(或者-并集)、unless(除非-补集)
vector1 and vector2: 会产生一个由 vector1 的元素组成的新的向量。该向量包含 vector1 中完全匹配 vector2 中的元素组成。其它的元素会被删除,指标名称和值从左侧即vector1继承。
**vector1 or vector2:**生成的向量包含vector1中所有的原始数据(标签+值),以及vector2在vector1中没有匹配到的数据。
**vector1 unless vector2:**结果产生一个新的向量,新向量中的元素由vector1中没有与vector2匹配的元素组成。匹配到的元素都会被删除。
4、运算符的优先级
运算符优先级从高到低依次为:
^
*、/、%
+、-
==、!=、<=、<、>=、>
and、unless
or
注意:
优先级相同的运算符,依次从左往右进行运算,但是 ^是从右开始的。
eg:
2 * 3 * 4 等价于 (2 * 3) * 4
2 ^ 3 ^ 4 等价于 2 ^ (3 ^ 4)
5、向量匹配
向量之间的运算尝试为左侧的每个条目在右侧向量中找到匹配的元素。
匹配行为有两种基本类型:一对一和 一对多或多对一。
1、基础知识
1、向量之间的匹配是在2个即时向量之间进行匹配,不能是区间向量。
2、那么2个向量如何算匹配上呢?
这个就需要2个向量存在完全一致的标签值相同。比如:2个向量都存在标签{code="200"}
完全一致的标签值:
1、2个向量具有完全相同的标签。
2、使用 on 或 ignoring后具有相同的标签。
那如果2个向量就是标签不同,但是存在若干个相同的标签,那么怎么比较呢?
使用 on 指定使用那个标签相同,就认为匹配上。
使用ignoring忽略某些标签相同,就认为匹配上。
3、找不到匹配的值会被忽略,不会出现在比较的结果中。
2、示例数据
示例数据是从prometheus官网上抄的。
method_code:http_errors:rate5m{method="get", code="500"} 24
method_code:http_errors:rate5m{method="get", code="404"} 30
method_code:http_errors:rate5m{method="put", code="501"} 3
method_code:http_errors:rate5m{method="post", code="500"} 6
method_code:http_errors:rate5m{method="post", code="404"} 21
method:http_requests:rate5m{method="get"} 600
method:http_requests:rate5m{method="del"} 34
method:http_requests:rate5m{method="post"} 120
1、一对一
一对一从操作的每一侧查找一对唯一的条目。如果两个条目具有完全相同的标签集和相应的值,则它们匹配。
ignoring:允许在匹配时忽略某些标签。
on:允许在匹配时只匹配指定的标签。
1、语法格式
<vector expr> <bin-op> ignoring(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) <vector expr>
2、示例
1、查询语句:
method_code:http_errors:rate5m{code="500"} / ignoring(code) method:http_requests:rate5m
2、解释:
1、method_code:http_errors:rate5m{code=“500”}可以查询出如下数据
method_code:http_errors:rate5m{method="get", code="500"} 24
method_code:http_errors:rate5m{method="post", code="500"} 6
2、method:http_requests:rate5m可以查询出如下数据
method:http_requests:rate5m{method="get"} 600
method:http_requests:rate5m{method="del"} 34
method:http_requests:rate5m{method="post"} 120
3、ignoring(code)的作用
因为 method_code:http_errors:rate5m 比 method:http_requests:rate5m 多了一个 code的标签,正常匹配匹配不上,如果忽略code标签的匹配,那么那边的标签一样且标签的值也一样,所有就可以匹配上。
4、比较的结果
{method="get"} 0.04 // 24 / 600
==> method_code:http_errors:rate5m{method="get", code="500"} / method:http_requests:rate5m{method="get"}
{method="post"} 0.05 // 6 / 120
==> method_code:http_errors:rate5m{method="post", code="500"} / method:http_requests:rate5m{method="post"}
只有2边都能匹配上的数据才会出现。method等于put和del的样本找不到匹配项,所以没有出现在结果集中。
5、为什么没有出现 method=del 和method=put的数据
因为{method=“del”}在method_code:http_errors:rate5m中没有查询出来,所以在结果中忽略了。即没有在2边都存在并且相匹配上。
2、一对多或多对一
一对多和多对一匹配指的是:“一”的一侧的每个向量元素可以与“多”侧的多个元素进行匹配。必须使用group_left或group_right修饰符显式请求,其中left/right确定哪个向量具有更高的基数。
1、语法格式
<vector expr> <bin-op> ignoring(<label list>) group_left(<label list>) <vector expr>
<vector expr> <bin-op> ignoring(<label list>) group_right(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) group_left(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) group_right(<label list>) <vector expr>
2、示例
1、查询语句:
method_code:http_errors:rate5m / ignoring(code) group_left method:http_requests:rate5m
2、解释:
1、ignoring(code) 表示比较的时候,忽略code标签。
2、group_left表示,左侧即 method_code:http_errors:rate5m 为多的一侧,右侧为一的一侧。
3、没有匹配的直接从结果集中删除。
4、结果如下:
{method="get", code="500"} 0.04 // 24 / 600
==> method_code:http_errors:rate5m{method="get", code="500"} / method:http_requests:rate5m{method="get"}
{method="get", code="404"} 0.05 // 30 / 600
==> method_code:http_errors:rate5m{method="get", code="404"} / method:http_requests:rate5m{method="get"}
{method="post", code="500"} 0.05 // 6 / 120
==> ...
{method="post", code="404"} 0.175 // 21 / 120
==> ...
注意:
group 修饰符只能在比较和数学运算符中使用。在逻辑运算 and,unless 和 or 操作中默认与右向量中的所有元素进行匹配。
6、聚合操作
Prometheus 提供了如下内置的聚合操作符,这些操作符作用于即时向量。
sum(求和)min(求最小值)max(求最大值)avg(求平均值)group(结果向量中的所有值均为1)stddev(求标准差)stdvar(求方差)count(计数)count_values(对 value(样本之) 进行计个数统计)bottomk(用于对样本值进行排序,样本值最小的 k 个元素)topk(用于对样本值进行排序,样本值最大的k个元素)quantile(分布统计,用于评估数据的分布统计 quantile(φ, express) ,其中0 ≤ φ ≤ 1)- 比如:quantile(0.95, http_requests_total) ==> 表示找到当前样本数据中的95%中位数
1、表达式语法:
<aggr-op> [without|by (<label list>)] ([parameter,] <vector expression>)
或
<aggr-op>([parameter,] <vector expression>) [without|by (<label list>)]
**label list:**是未加引号的标签列表,比如(code,method)等。
without: 用于从计算结果中移除列举的标签,而保留其它标签。
**by:**和without的作用想法,表示用于从计算结果中保留列举的标签,而移除其它标签。
**parameter:**只能在count_values、quantile、topk和bottomk中使用。
**count_values:**用于时间序列中每一个样本值出现的次数。count_values 会为每一个唯一的样本值输出一个时间序列,并且每一个时间序列包含一个额外的标签。这个标签的名字由聚合参数指定,同时这个标签值是唯一的样本值。
quantile: 用于计算当前样本数据值的分布情况 quantile(φ, express) ,其中 0 ≤ φ ≤ 1。
2、示例
1、在prometheus_http_requests_total指标中根据code来分组求和
sum( prometheus_http_requests_total) by (code)
2、获取 HTTP 请求数前 5 位的时序样本数据
topk(5,prometheus_http_requests_total)
六、一些内置函数
Prometheus 提供了其它大量的内置函数,可以对时许数据进行一些处理。有些函数有默认参数,例如 year(v=vector(time()) instant-vector)。这意味着有一个参数v,它是一个即时向量,如果没有提供它,它将默认为表达式vector(time())的值。
1、abs 绝对值
abs(v instant-vector) 返回输入向量的所有样本的绝对值。
2、absent 判断指标名称或标签是否有值
absent(v instant-vector)
有值:**不返回数据
没有值:**可能返回指标名称,值返回 1
示例:
# 指标名称存在数据
absent(up)
==> no data,指标名称存在,不返回数据
# 指标名称和标签名称值都存在数据
absent(up{job="prometheus"})
==> no data,指标名称和标签名称值都存在,不返回数据
# 指标名称和标签名称的值对应不上,即没有数据
absent(up{job="不存在的值"})
==> {job="不存在的值"} = 1,返回标签和值
# 指标名称不存在
absent(nonexistent{job="myjob"})
==> {job="myjob"} = 1
# 正则匹配的instance不作为返回的labels的一部分
absent(nonexistent{job="myjob",instance=~".*"})
==> {job="myjob"} = 1
# sum 函数返回的时间序列不带有标签,且没有样本数据
absent(sum(nonexistent{job="myjob"}))
==> {} = 1
3、absent_over_time 和 absent类似,只是多了一个时间范围
absent_over_time(nonexistent{job="myjob"}[1h])
# => {job="myjob"}
absent_over_time(nonexistent{job="myjob",instance=~".*"}[1h])
# => {job="myjob"}
absent_over_time(sum(nonexistent{job="myjob"})[1h:])
# => {}
4、ceil 四舍五入
ceil(v instant-vector) 将 v 中所有元素的样本值向上四舍五入到最接近的整数。
node_load1 1.902324
ceil(node_load1) 2
5、changes 返回区间变量每个样本值变化的次数
changes(v range-vector)
# 如果1分钟内192.168.0.1:8080的样本值没有发生变化则返回1
changes(node_load1{instance="192.168.0.1:8080"}[1m]) # 结果为 1
6、delta 计算区间向量第一个值和最后一个值的差值
# 返回过去两小时的CPU的温度差
delta(cpu_temp_celsius{host="192.168.0.1"}[2h])
注意:
该函数一般使用在gauge类型的时间序列上。
7、floor 向下取整
node_load1 1.902324
floor(node_load1) 1
8、increase 返回区间向量第一个和最后一个样本的增量值
# 返回区间向量中每个时间序列过去5分钟内HTTP请求数的增长数
increase(http_requests_total{job="prometheus"}[5m])
increase 的返回值类型只能是计数器类型,主要作用是增加图表和数据的可读性。使用 rate 函数记录规则的使用率,以便持续跟踪数据样本值的变化。
9、rate 计算区间向量 v 在时间窗口内平均每秒增长速率
# 计算 prometheus_http_requests_total 在1分钟内平均每秒的增长速率
# 比如:1分钟内,共增长了1000个请求,那么美妙的增长速率为 1000/60
rate(prometheus_http_requests_total[1m])
注意:
- rate() 函数返回值类型只能用计数器,在长期趋势分析或者告警中推荐使用这个函数。
- 当rate()函数和聚合函数一起使用时,需要先使用rate()函数,在使用聚合函数。比如:先使用rate()函数,在使用sum()函数
10、irate 计算区间向量的增长率,但是它反应的是瞬时增长率
irate 函数是通过区间向量中最后两个样本数据来计算区间向量的增长速率,能够体现出更好的灵敏度,通过irate函数绘制的图标能够更好的反应样本数据的瞬时变化状态。
# 计算 prometheus_http_requests_total 在1分钟内最后2个样本数据增长速率
irate(prometheus_http_requests_total[1m])
注意:
- irate() 函数不推荐在在长期趋势分析或者告警中使用这个函数。
- 当irate()函数和聚合函数一起使用时,需要先使用rate()函数,在使用聚合函数。比如:先使用rate()函数,在使用sum()函数
11、predict_linear 预测时间序列在n秒后的值
predict_linear(v range-vector, t scalar) 预测时间序列v在t秒后的值。它基于简单线性回归的方式,对时间窗口内的样本数据进行统计,从而可以对时间序列的变化趋势做出预测。该函数的返回结果不带有度量指标,只有标签列表。
# 预计磁盘在4个小时后是否被占满。
predict_linear(node_filesystem_free{job="prometheus"}[2h], 4 * 3600) < 0
注意:
- 该函数一般使用在
gauge类型的时间序列上。
12、sort 对向量按元素的值进行升序排序
# 样本值升序排序
sort(prometheus_http_requests_total)
13、sort_desc 对向量按元素的值进行降序排序
# 样本值倒序排序
sort_desc(prometheus_http_requests_total)
七、参考文章
1、https://github.com/google/re2/wiki/Syntax
2、https://prometheus.io/docs/prometheus/latest/querying/basics/
PromQL的简单使用的更多相关文章
- rancher 和 Kubernetes有什么区别?
总体来说,Rancher和k8s都是用来作为容器的调度与编排系统.但是rancher不仅能够管理应用容器,更重要的一点是能够管理k8s集群.Rancher2.x底层基于k8s调度引擎,通过Ranche ...
- Prometheus时序数据库-数据的查询
Prometheus时序数据库-数据的查询 前言 在之前的博客里,笔者详细阐述了Prometheus数据的插入过程.但我们最常见的打交道的是数据的查询.Prometheus提供了强大的Promql来满 ...
- Prometheus监控学习笔记之PromQL简单示例
0x00 简单的时间序列选择 返回度量指标 http_requests_total 的所有时间序列样本数据: http_requests_total 返回度量指标名称为 http_requests_t ...
- Prometheus PromQL 简单用法
目录 说明 CPU 内存 磁盘监控 磁盘空间利用率百分比 预计饱和 说明 基于上一篇文章的基础,这里做一些关于 CPU.内存.磁盘的一些基础查询语句. CPU 通过查询 metric值为 node_c ...
- Prometheus监控学习笔记之初识PromQL
0x00 概述 Prometheus 提供了一种功能表达式语言 PromQL,允许用户实时选择和汇聚时间序列数据.表达式的结果可以在浏览器中显示为图形,也可以显示为表格数据,或者由外部系统通过 HTT ...
- Prometheus学习系列(七)之Prometheus PromQL说明
前言 本文来自Prometheus官网手册1.2.3 和 Prometheus简介1.2.3 PromQL操作符 一.二元操作符 Prometheus的查询语言支持基本的逻辑运算和算术运算.对于两个瞬 ...
- prometheus学习系列七: Prometheus promQL查询语言
Prometheus promQL查询语言 Prometheus提供了一种名为PromQL (Prometheus查询语言)的函数式查询语言,允许用户实时选择和聚合时间序列数据.表达式的结果既可以显示 ...
- PromQL
PromQL (Prometheus Query Language) 是 Prometheus 自己开发的数据查询 DSL 语言,语言表现力非常丰富,内置函数很多,在日常数据可视化以及rule 告警中 ...
- TSQL:让监控分析更简单更高效
1. 前言 阿里时序时空数据库TSDB最新推出TSQL,支持标准SQL的语法和函数.用户使用熟悉的SQL,不仅仅查询更简单易用,用户还可以利用SQL强大的功能,实现更加复杂的计算分析. 2. 为什么需 ...
随机推荐
- 第09课:GDB 实用调试技巧(下)
本节课的核心内容: 多线程下禁止线程切换 条件断点 使用 GDB 调试多进程程序 多线程下禁止线程切换 假设现在有 5 个线程,除了主线程,工作线程都是下面这样的一个函数: void thread_p ...
- java线程day-01
综述:下面写的是我学习java线程时做的一些笔记和查阅的一些资料总结而成.大多以问答的形式出现. 一.什么是线程? 答:线程是一个轻量级的进程,现在操作系统中一个基本的调度单位,而且线程是彼此独立执行 ...
- 一些PHP选项参数相关的函数
关于 PHP 的配置,我们大多数情况下都是去查看 php.ini 文件或者通过命令行来查询某些信息,其实,PHP 的一些内置函数也可以帮助我们去查看或操作这些配置参数.比如之前我们学习过的 关于php ...
- 3gcms导航,实现当前栏目高亮的办法
<volist name="menu" id="vo" offset="0" length='8' key='k'> <l ...
- PHP文件包含漏洞小结
参考链接:https://chybeta.github.io/2017/10/08/php文件包含漏洞/ 四大漏洞函数 PHP文件包含漏洞主要由于四个函数引起的: include() include_ ...
- 用Python做了个奇奇怪怪的打篮球游戏
一.前言 准备编写一个篮球游戏,运动员带球跑,跳起投篮.在每帧图片中包括运动员和篮球,使用多帧图片,实现运动员运球跑动的效果. 运动员运球跑动作每帧图形的宽和高可能不同,例如,跨一大步,和两腿并拢,其 ...
- Java基础系列(14)- JavaDoc生成文档
JavaDoc JavaDoc是一种将注释生成HTML文档的技术,生成的HTML文档类似于Java的API,易读且清晰明了 参数信息 @author 作者名 @version 版本号 @since 指 ...
- Linux系列(40) - 自动同步时间chrony
前言 Centos8开始取消了ntp同步时间,改为chrony同步 chrony工具安装 yum -y install chrony 修改配置文件 将配置文件中的同步服务器修改为国内的时间服务器(推荐 ...
- sonar-scanner的使用
在服务器搭建sonarqube后,本地的windows个人电脑如何使用sonar-scanner? 在服务器搭建sonarqube后,每个人都可以在本地使用sonar-scanner扫描代码. son ...
- vue 学习资料
自学资料地址: https://zhuanlan.zhihu.com/p/26535530项目UI部分1.pc站 UI:(1)考虑自己写成本高,需要花费不少时间,好处是可以自己控制维护!(2)引入第三 ...