C++ 11 多线程初探-std::memory_order
std::memory_order(可译为内存序,访存顺序)
动态内存模型可理解为存储一致性模型,主要是从行为(behavioral)方面来看多个线程对同一个对象同时(读写)操作时(concurrency)所做的约束,动态内存模型理解起来稍微复杂一些,涉及了内存,Cache,CPU 各个层次的交互,尤其是在共享存储系统中,为了保证程序执行的正确性,就需要对访存事件施加严格的限制。
假设存在两个共享变量a, b,初始值均为 0,两个线程运行不同的指令,如下表格所示,线程 1 设置 a 的值为 1,然后设置 R1 的值为 b,线程 2 设置 b 的值为 2,并设置 R2 的值为 a,请问在不加任何锁或者其他同步措施的情况下,R1,R2 的最终结
果会是多少?
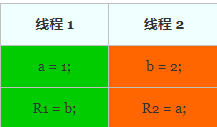
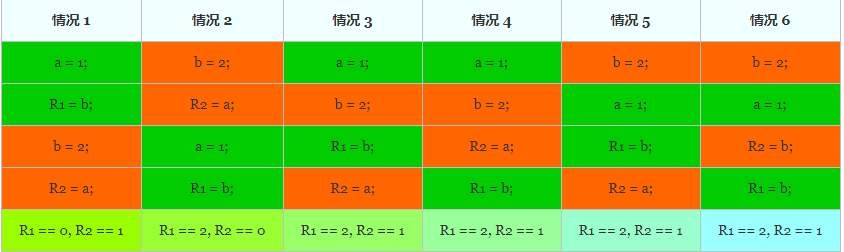
由于没有施加任何同步限制,两个线程将会交织执行,但交织执行时指令不发生重排,即线程 1 中的 a = 1 始终在 R1 = b 之前执行,而线程 2 中的 b = 2 始终在 R2 = a 之前执行 ,因此可能的执行序列共有 4!/(2!*2!) = 6 种
多线程环境下顺序一致性包括两个方面,(1). 从多个线程平行角度来看,程序最终的执行结果相当于多个线程某种交织执行的结果,(2)从单个线程内部执行顺序来看,该线程中的指令是按照程序事先已规定的顺序执行的(即不考虑运行时 CPU 乱序执行和 Memory Reorder)。当然,顺序一致性代价太大,不利于程序的优化,现在的编译器在编译程序时通常将指令重新排序。对编译器和 CPU 作出一定的约束才能合理正确地优化你的程序,那么这个约束是什么呢?答曰:内存模型。C++程序员要想写出高性能的多线程程序必须理解内存模型,编译器会给你的程序做优化(静态),CPU为了提升性能也有乱序执行(动态),总之,程序在最终执行时并不会按照你之前的原始代码顺序来执行,因此内存模型是程序员、编译器,CPU 之间的契约,遵守契约后大家就各自做优化,从而尽可能提高程序的性能。
C++11 中规定了 6 中访存次序(Memory Order),如下:
enum memory_order {
memory_order_relaxed,
memory_order_consume,
memory_order_acquire,
memory_order_release,
memory_order_acq_rel,
memory_order_seq_cst
};
上述 6 中访存次序(内存序)分为 3 类,顺序一致性模型(std::memory_order_seq_cst),Acquire-Release 模型(std::memory_order_consume, std::memory_order_acquire, std::memory_order_release, std::memory_order_acq_rel,) (获取/释放语义模型
)和 Relax 模型(std::memory_order_relaxed)(宽松的内存序列化模型)。
memory_order_relaxed: 只保证当前操作的原子性,不考虑线程间的同步,其他线程可能读到新值,也可能读到旧值。比如 C++ shared_ptr 里的引用计数,我们只关心当前的应用数量,而不关心谁在引用谁在解引用。
memory_order_release:(可以理解为 mutex 的 unlock 操作)
- 对写入施加 release 语义(store),在代码中这条语句前面的所有读写操作都无法被重排到这个操作之后,即 store-store 不能重排为 store-store, load-store 也无法重排为 store-load
- 当前线程内的所有写操作,对于其他对这个原子变量进行 acquire 的线程可见
- 当前线程内的与这块内存有关的所有写操作,对于其他对这个原子变量进行 consume 的线程可见
memory_order_acquire: (可以理解为 mutex 的 lock 操作)
- 对读取施加 acquire 语义(load),在代码中这条语句后面所有读写操作都无法重排到这个操作之前,即 load-store 不能重排为 store-load, load-load 也无法重排为 load-load
- 在这个原子变量上施加 release 语义的操作发生之后,acquire 可以保证读到所有在 release 前发生的写入,举个例子:
c = 0;
thread 1:{
a = 1;
b.store(2, memory_order_relaxed);
c.store(3, memory_order_release);
}
thread 2:{
while (c.load(memory_order_acquire) != 3) ; // 以下 assert 永远不会失败
assert(a == 1 && b == 2);
assert(b.load(memory_order_relaxed) == 2);
}
memory_order_consume:
- 对当前要读取的内存施加 release 语义(store),在代码中这条语句后面所有与这块内存有关的读写操作都无法被重排到这个操作之前
- 在这个原子变量上施加 release 语义的操作发生之后,acquire 可以保证读到所有在 release 前发生的并且与这块内存有关的写入,举个例子:
a = 0;
c = 0;
thread 1:{
a = 1;
c.store(3, memory_order_release);
}
thread 2:{
while (c.load(memory_order_consume) != 3) ;
assert(a == 1); // assert 可能失败也可能不失败
}
memory_order_acq_rel:
- 对读取和写入施加 acquire-release 语义,无法被重排
- 可以看见其他线程施加 release 语义的所有写入,同时自己的 release 结束后所有写入对其他施加 acquire 语义的线程可见
memory_order_seq_cst:(顺序一致性)
- 如果是读取就是 acquire 语义,如果是写入就是 release 语义,如果是读取+写入就是 acquire-release 语义
- 同时会对所有使用此 memory order 的原子操作进行同步,所有线程看到的内存操作的顺序都是一样的,就像单个线程在执行所有线程的指令一样
通常情况下,默认使用 memory_order_seq_cst,所以你如果不确定怎么这些 memory order,就用这个。
C++ 11 多线程初探-std::memory_order的更多相关文章
- 【转】C++ 11 并发指南一(C++ 11 多线程初探)
引言 C++ 11自2011年发布以来已经快两年了,之前一直没怎么关注,直到最近几个月才看了一些C++ 11的新特性,算是记录一下自己学到的东西吧,和大家共勉. 相信Linux程序员都用过Pthrea ...
- C++11 并发指南一(C++11 多线程初探)
引言 C++11 自2011年发布以来已经快两年了,之前一直没怎么关注,直到最近几个月才看了一些 C++11 的新特性,今后几篇博客我都会写一些关于 C++11 的特性,算是记录一下自己学到的东西吧, ...
- C++11 并发指南一(C++11 多线程初探)(转)
引言 C++11 自2011年发布以来已经快两年了,之前一直没怎么关注,直到最近几个月才看了一些 C++11 的新特性,今后几篇博客我都会写一些关于 C++11 的特性,算是记录一下自己学到的东西吧, ...
- 【C/C++开发】C++11 并发指南一(C++11 多线程初探)
引言 C++11 自2011年发布以来已经快两年了,之前一直没怎么关注,直到最近几个月才看了一些 C++11 的新特性,今后几篇博客我都会写一些关于 C++11 的特性,算是记录一下自己学到的东西吧, ...
- 【C++】c++11多线程初探
相关头文件c++11 新标准中引入了四个头文件来支持多线程编程,他们分别是<atomic> ,<thread>,<mutex>,<condition_vari ...
- C++ 11 多线程下std::unique_lock与std::lock_guard的区别和用法
这里主要介绍std::unique_lock与std::lock_guard的区别用法 先说简单的 一.std::lock_guard的用法 std::lock_guard其实就是简单的RAII封装, ...
- C++11 多线程编程 使用lambda创建std::thread (生产/消费者模式)
要写个tcp server / client的博客,想着先写个c++11多线程程序.方便后面写博客使用. 目前c++11中写多线程已经很方便了,不用再像之前的pthread_create,c++11中 ...
- C++11多线程教学(二)
C++11多线程教学II 从我最近发布的C++11线程教学文章里,我们已经知道C++11线程写法与POSIX的pthreads写法相比,更为简洁.只需很少几个简单概念,我们就能搭建相当复杂的处理图片程 ...
- C++11多线程教学(一)
本篇教学代码可在GitHub获得:https://github.com/sol-prog/threads. 在之前的教学中,我展示了一些最新进的C++11语言内容: 1. 正则表达式(http://s ...
随机推荐
- 使用BeautifulSoup高效解析网页,再也不用担心睡不着觉了
BeautifulSoup是一个可以从 HTML 或 XML 文件中提取数据的 Python 库 那需要怎么使用呢? 首先我们要安装一下这个库 1.pip install beautifulsoup4 ...
- SQL Server将同一列多条数据合并成一行
Sql server中,将同一字段多条数据用字符拼接为一个字符串方式. 原数据查询展示: 使用 STUFF 函数,将结果列拼接成一行.结果如下: STUFF: 1.作用 stuff(param1, s ...
- 如何保证mq不丢消息
1.消息的发送流程 一条消息从生产到被消费,将会经历3个阶段 生产阶段,Producer 新建消息,然后通过网络将消息投递给MQ Broker 存储阶段,消息将会存储在Broker端磁盘中 消费阶段, ...
- MindSpore 高阶优化器
MindSpore 高阶优化器 MindSpore自研优化器THOR(Trace-based Hardware-driven layer-ORiented Natural Gradient Desce ...
- 在NVIDIA-Jetson平台上构建智能多媒体服务器
在NVIDIA-Jetson平台上构建智能多媒体服务器 Building a Multi-Camera Media Server for AI Processing on the NVIDIA Jet ...
- 使用TensorRT集成推理inference
使用TensorRT集成推理inference 使用TensorRT集成进行推理测试. 使用ResNet50模型对每个GPU进行推理,并对其它模型进行性能比较,最后与其它服务器进行比较测试. ResN ...
- NVIDIA TensorRT高性能深度学习推理
NVIDIA TensorRT高性能深度学习推理 NVIDIA TensorRT 是用于高性能深度学习推理的 SDK.此 SDK 包含深度学习推理优化器和运行时环境,可为深度学习推理应用提供低延迟和高 ...
- 【.NET 与树莓派】温度/湿度传感器——SHT30
SHT3XX 系列的传感,常见的有三种:SHT 30.SHT 31.SHT 35.其中,比较便宜性价比较愉快的是 SHT 30. DHT 11 模块也是检测温度.湿度的,但SHT 11 使用的不是我们 ...
- 使用adb命令查看APP包名 和 包入口方法
方法一: 1.查看 前台应用 包名,使用此命令注意:手机只启动要查看包名的app adb shell dumpsys activity | find "mFocusedActivity&qu ...
- Linux学习笔记:Linux命令之权限管理命令
权限管理命令 chmod(重要) 命令名称:chmod 英文原意:change the permissions mode of a file 执行权限:所有用户 功能描述:改变文件或目录权限 语法:c ...