基于Flink构建全场景实时数仓
目录:
一. 实时计算初期
二. 实时数仓建设
三. Lambda架构的实时数仓
四. Kappa架构的实时数仓
五. 流批结合的实时数仓
实时计算初期
虽然实时计算在最近几年才火起来,但是在早期也有部分公司有实时计算的需求,但是数据量比较少,所以在实时方面形成不了完整的体系,基本所有的开发都是具体问题具体分析,来一个需求做一个,基本不考虑它们之间的关系,开发形式如下:
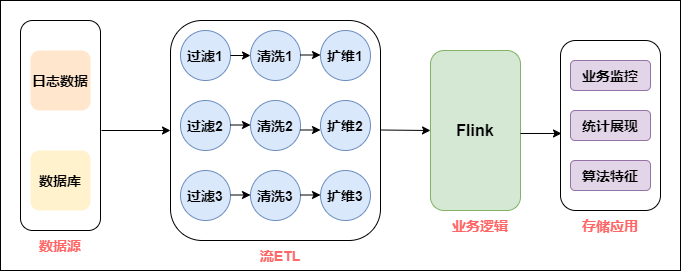 早期实时计算
早期实时计算
如上图所示,拿到数据源后,会经过数据清洗,扩维,通过Flink进行业务逻辑处理,最后直接进行业务输出。把这个环节拆开来看,数据源端会重复引用相同的数据源,后面进行清洗、过滤、扩维等操作,都要重复做一遍,唯一不同的是业务的代码逻辑是不一样的。
随着产品和业务人员对实时数据需求的不断增多,这种开发模式出现的问题越来越多:
数据指标越来越多,“烟囱式”的开发导致代码耦合问题严重。
需求越来越多,有的需要明细数据,有的需要 OLAP 分析。单一的开发模式难以应付多种需求。
每个需求都要申请资源,导致资源成本急速膨胀,资源不能集约有效利用。
缺少完善的监控系统,无法在对业务产生影响之前发现并修复问题。
大家看实时数仓的发展和出现的问题,和离线数仓非常类似,后期数据量大了之后产生了各种问题,离线数仓当时是怎么解决的?离线数仓通过分层架构使数据解耦,多个业务可以共用数据,实时数仓是否也可以用分层架构呢?当然是可以的,但是细节上和离线的分层还是有一些不同,稍后会讲到。
实时数仓建设
从方法论来讲,实时和离线是非常相似的,离线数仓早期的时候也是具体问题具体分析,当数据规模涨到一定量的时候才会考虑如何治理。分层是一种非常有效的数据治理方式,所以在实时数仓如何进行管理的问题上,首先考虑的也是分层的处理逻辑。
实时数仓的架构如下图:
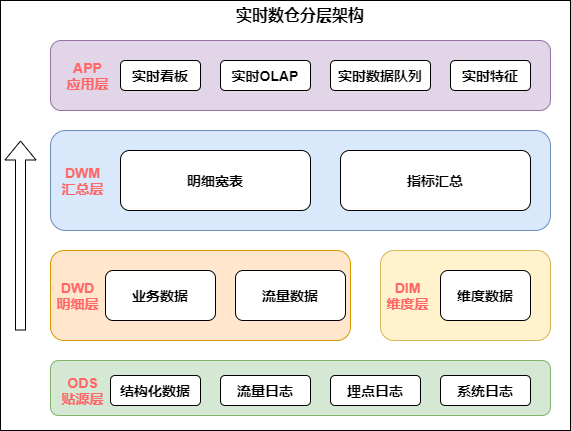 实时数仓架构
实时数仓架构
从上图中我们具体分析下每层的作用:
数据源:在数据源的层面,离线和实时在数据源是一致的,主要分为日志类和业务类,日志类又包括用户日志,埋点日志以及服务器日志等。
实时明细层:在明细层,为了解决重复建设的问题,要进行统一构建,利用离线数仓的模式,建设统一的基础明细数据层,按照主题进行管理,明细层的目的是给下游提供直接可用的数据,因此要对基础层进行统一的加工,比如清洗、过滤、扩维等。
汇总层:汇总层通过Flink的简洁算子直接可以算出结果,并且形成汇总指标池,所有的指标都统一在汇总层加工,所有人按照统一的规范管理建设,形成可复用的汇总结果。
我们可以看出,实时数仓和离线数仓的分层非常类似,比如 数据源层,明细层,汇总层,乃至应用层,他们命名的模式可能都是一样的。但仔细比较不难发现,两者有很多区别:
与离线数仓相比,实时数仓的层次更少一些:
从目前建设离线数仓的经验来看,数仓的数据明细层内容会非常丰富,处理明细数据外一般还会包含轻度汇总层的概念,另外离线数仓中应用层数据在数仓内部,但实时数仓中,app 应用层数据已经落入应用系统的存储介质中,可以把该层与数仓的表分离。
应用层少建设的好处:实时处理数据的时候,每建一个层次,数据必然会产生一定的延迟。
汇总层少建的好处:在汇总统计的时候,往往为了容忍一部分数据的延迟,可能会人为的制造一些延迟来保证数据的准确。举例,在统计跨天相关的订单事件中的数据时,可能会等到 00:00:05 或者 00:00:10 再统计,确保 00:00 前的数据已经全部接受到位了,再进行统计。所以,汇总层的层次太多的话,就会更大的加重人为造成的数据延迟。
与离线数仓相比,实时数仓的数据源存储不同:
- 在建设离线数仓的时候,基本整个离线数仓都是建立在 Hive 表之上。但是,在建设实时数仓的时候,同一份表,会使用不同的方式进行存储。比如常见的情况下,明细数据或者汇总数据都会存在 Kafka 里面,但是像城市、渠道等维度信息需要借助 Hbase,MySQL 或者其他 KV 存储等数据库来进行存储。
Lambda架构的实时数仓
Lambda和Kappa架构的概念已在前文中解释,不了解的小伙伴可点击链接:一文读懂大数据实时计算
下图是基于 Flink 和 Kafka 的 Lambda 架构的具体实践,上层是实时计算,下层是离线计算,横向是按计算引擎来分,纵向是按实时数仓来区分:
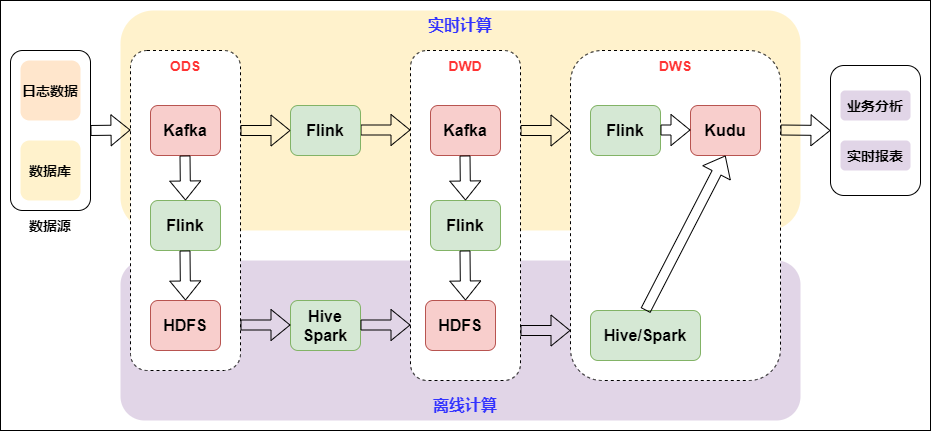 Lambda架构的实时数仓
Lambda架构的实时数仓
Lambda架构是比较经典的架构,以前实时的场景不是很多,以离线为主,当附加了实时场景后,由于离线和实时的时效性不同,导致技术生态是不一样的。Lambda架构相当于附加了一条实时生产链路,在应用层面进行一个整合,双路生产,各自独立。这在业务应用中也是顺理成章采用的一种方式。
双路生产会存在一些问题,比如加工逻辑double,开发运维也会double,资源同样会变成两个资源链路。因为存在以上问题,所以又演进了一个Kappa架构。
Kappa架构的实时数仓
Kappa架构相当于去掉了离线计算部分的Lambda架构,具体如下图所示:
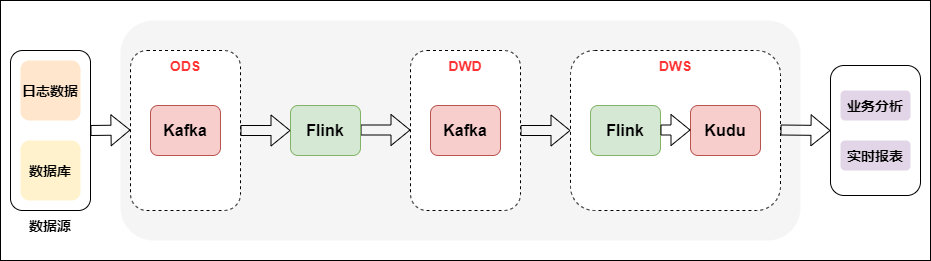 Kappa架构的实时数仓
Kappa架构的实时数仓
Kappa架构从架构设计来讲比较简单,生产统一,一套逻辑同时生产离线和实时。但是在实际应用场景有比较大的局限性,因为实时数据的同一份表,会使用不同的方式进行存储,这就导致关联时需要跨数据源,操作数据有很大局限性,所以在业内直接用Kappa架构生产落地的案例不多见,且场景比较单一。
关于 Kappa 架构,熟悉实时数仓生产的同学,可能会有一个疑问。因为我们经常会面临业务变更,所以很多业务逻辑是需要去迭代的。之前产出的一些数据,如果口径变更了,就需要重算,甚至重刷历史数据。对于实时数仓来说,怎么去解决数据重算问题?
Kappa 架构在这一块的思路是:首先要准备好一个能够存储历史数据的消息队列,比如 Kafka,并且这个消息队列是可以支持你从某个历史的节点重新开始消费的。接着需要新起一个任务,从原来比较早的一个时间节点去消费 Kafka 上的数据,然后当这个新的任务运行的进度已经能够和现在的正在跑的任务齐平的时候,你就可以把现在任务的下游切换到新的任务上面,旧的任务就可以停掉,并且原来产出的结果表也可以被删掉。
流批结合的实时数仓
随着实时 OLAP 技术的发展,目前开源的OLAP引擎在性能,易用等方面有了很大的提升,如Doris、Presto等,加上数据湖技术的迅速发展,使得流批结合的方式变得简单。
如下图是流批结合的实时数仓:
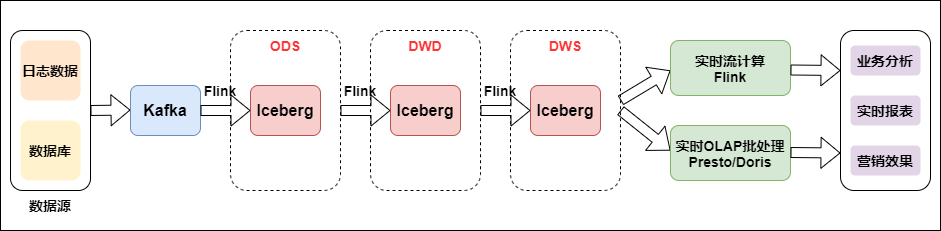 流批结合的实时数仓
流批结合的实时数仓
数据从日志统一采集到消息队列,再到实时数仓,作为基础数据流的建设是统一的。之后对于日志类实时特征,实时大屏类应用走实时流计算。对于Binlog类业务分析走实时OLAP批处理。
我们看到流批结合的方式与上面几种架构的存储方式发生了变化,由Kafka换成了Iceberg,Iceberg是介于上层计算引擎和底层存储格式之间的一个中间层,我们可以把它定义成一种“数据组织格式”,底层存储还是HDFS,那么为什么加了中间层,就对流批结合处理的比较好了呢?Iceberg的ACID能力可以简化整个流水线的设计,降低整个流水线的延迟,并且所具有的修改、删除能力能够有效地降低开销,提升效率。Iceberg可以有效支持批处理的高吞吐数据扫描和流计算按分区粒度并发实时处理。
基于Flink构建全场景实时数仓的更多相关文章
- 大数据之Hudi + Kylin的准实时数仓实现
问题导读:1.数据库.数据仓库如何理解?2.数据湖有什么用途?解决什么问题?3.数据仓库的加载链路如何实现?4.Hudi新一代数据湖项目有什么优势? 在近期的 Apache Kylin × Apach ...
- 美团点评基于 Flink 的实时数仓建设实践
https://mp.weixin.qq.com/s?__biz=MjM5NjQ5MTI5OA==&mid=2651749037&idx=1&sn=4a448647b3dae5 ...
- 基于 Flink 的实时数仓生产实践
数据仓库的建设是“数据智能”必不可少的一环,也是大规模数据应用中必然面临的挑战.在智能商业中,数据的结果代表了用户反馈.获取数据的及时性尤为重要.快速获取数据反馈能够帮助公司更快地做出决策,更好地进行 ...
- flink实时数仓从入门到实战
第一章.flink实时数仓入门 一.依赖 <!--Licensed to the Apache Software Foundation (ASF) under oneor more contri ...
- 基于 Kafka 的实时数仓在搜索的实践应用
一.概述 Apache Kafka 发展至今,已经是一个很成熟的消息队列组件了,也是大数据生态圈中不可或缺的一员.Apache Kafka 社区非常的活跃,通过社区成员不断的贡献代码和迭代项目,使得 ...
- (转)用Flink取代Spark Streaming!知乎实时数仓架构演进
转:https://mp.weixin.qq.com/s/e8lsGyl8oVtfg6HhXyIe4A AI 前线导读:“数据智能” (Data Intelligence) 有一个必须且基础的环节,就 ...
- 更强大的实时数仓构建能力!分析型数据库PostgreSQL 6.0新特性解读
阿里云 AnalyticDB for PostgreSQL 为采用MPP架构的分布式集群数据库,完备支持SQL 2003,部分兼容Oracle语法,支持PL/SQL存储过程,触发器,支持标准数据库事务 ...
- HBase实战 | 知乎实时数仓架构演进
https://mp.weixin.qq.com/s/hx-q13QteNvtXRpNsE5Y0A 作者 | 知乎数据工程团队编辑 | VincentAI 前线导读:“数据智能” (Data Inte ...
- Clickhouse实时数仓建设
1.概述 Clickhouse是一个开源的列式存储数据库,其主要场景用于在线分析处理查询(OLAP),能够使用SQL查询实时生成分析数据报告.今天,笔者就为大家介绍如何使用Clickhouse来构建实 ...
随机推荐
- 灵动微电子ARM Cortex M0 MM32F0010 UART1和UART2中断接收数据
灵动微电子ARM Cortex M0 MM32F0010 UART1和UART2中断接收数据 目录: 1.MM32F0010UART简介 2.MM32F0010UART特性 3.MM32F0010使用 ...
- rman备份出现ORA-19625
[oracle@hear adump]$ rman target / Recovery Manager: Release 11.2.0.4.0 - Production on Mon Jun 17 0 ...
- 如何去掉a标签的下划线
首先来了解下<a>标签的一些样式: <a>标签的伪类样式 一组专门的预定义的类称为伪类,主要用来处理超链接的状态.超链接文字的状态可以通过伪类选择符+样式规则来控制.伪类选择符 ...
- jvm调优神器——arthas
在上一篇<jvm调优的几种场景>中介绍了几种常见的jvm方面调优的场景,用的都是jdk自带的小工具,比如jps.jmap.jstack等.用这些自带的工具排查问题时最大的痛点就是过程比较麻 ...
- 总结springboot开启mybatis驼峰命名自动映射的三种方式
方式一:通过springboot的配置文件application.yml mybatis: configuration: map-underscore-to-camel-case: true 此方式是 ...
- VNC 相关
vncserver启动报错root A VNC server is already running as :1 [root@42 ~]# service vncserver startStarting ...
- 【VBA】读取另一个excel工作簿中的内容
后台打开工作簿读取内容源码: Sub subOpenWorkbook() Dim datebase As String datebase = "... ....xlsx" Appl ...
- 基于 Spring Security 的前后端分离的权限控制系统
话不多说,入正题.一个简单的权限控制系统需要考虑的问题如下: 权限如何加载 权限匹配规则 登录 1. 引入maven依赖 1 <?xml version="1.0" enc ...
- 在Intellij IDEA中查看TestNG自带的测试报告
执行TestNG框架的测试用例,会生成测试报告.如果在IDEA中看不到,可做如下配置. 1. 点击IDEA工具栏中Run->Edit Configuration菜单,或者直接点击右上角编辑配置的 ...
- Oracle不知道用户密码情况下,如何在不更改密码的前提下解锁用户或者延期密码有效期
1.问题描述: 生产环境,zabbix告警业务用户密码即将过期,但是如何不知道业务用户密码的情况下来解决该问题? 2.实验一: 1)创建新的用户test,并授予test resource角色和conn ...