转:Sed使用
awk于1977年出生,今年36岁本命年,sed比awk大2-3岁,awk就像林妹妹,sed就是宝玉哥哥了。所以 林妹妹跳了个Topless,他的哥哥sed坐不住了,也一定要出来抖一抖。
sed全名叫stream editor,流编辑器,用程序的方式来编辑文本,相当的hacker啊。sed基本上就是玩正则模式匹配,所以,玩sed的人,正则表达式一般都比较强。
同样,本篇文章不会说sed的全部东西,你可以参看sed的手册,我这里主要还是想和大家竞争一下那些从手机指缝间或马桶里流走的时间,用这些时间来学习一些东西。当然,接下来的还是要靠大家自己双手。
用s命令替换
我使用下面的这段文本做演示:
|
1
2
3
4
5
6
7
8
9
|
$ cat pets.txtThis is my cat my cat's name is bettyThis is my dog my dog's name is frankThis is my fish my fish's name is georgeThis is my goat my goat's name is adam |
把其中的my字符串替换成Hao Chen’s,下面的语句应该很好理解(s表示替换命令,/my/表示匹配my,/Hao Chen’s/表示把匹配替换成Hao Chen’s,/g 表示一行上的替换所有的匹配):
|
1
2
3
4
5
6
7
8
9
|
$ sed "s/my/Hao Chen's/g" pets.txtThis is Hao Chen's cat Hao Chen's cat's name is bettyThis is Hao Chen's dog Hao Chen's dog's name is frankThis is Hao Chen's fish Hao Chen's fish's name is georgeThis is Hao Chen's goat Hao Chen's goat's name is adam |
注意:如果你要使用单引号,那么你没办法通过\’这样来转义,就有双引号就可以了,在双引号内可以用\”来转义。
再注意:上面的sed并没有对文件的内容改变,只是把处理过后的内容输出,如果你要写回文件,你可以使用重定向,如:
|
1
|
$ sed "s/my/Hao Chen's/g" pets.txt > hao_pets.txt |
或使用 -i 参数直接修改文件内容:
|
1
|
$ sed -i "s/my/Hao Chen's/g" pets.txt |
在每一行最前面加点东西:
|
1
2
3
4
5
6
7
8
9
|
$ sed 's/^/#/g' pets.txt#This is my cat# my cat's name is betty#This is my dog# my dog's name is frank#This is my fish# my fish's name is george#This is my goat# my goat's name is adam |
在每一行最后面加点东西:
|
1
2
3
4
5
6
7
8
9
|
$ sed 's/$/ --- /g' pets.txtThis is my cat --- my cat's name is betty ---This is my dog --- my dog's name is frank ---This is my fish --- my fish's name is george ---This is my goat --- my goat's name is adam --- |
顺手介绍一下正则表达式的一些最基本的东西:
- ^ 表示一行的开头。如:/^#/ 以#开头的匹配。
- $ 表示一行的结尾。如:/}$/ 以}结尾的匹配。
- \< 表示词首。 如 \<abc 表示以 abc 为首的詞。
- \> 表示词尾。 如 abc\> 表示以 abc 結尾的詞。
- . 表示任何单个字符。
- * 表示某个字符出现了0次或多次。
- [ ] 字符集合。 如:[abc]表示匹配a或b或c,还有[a-zA-Z]表示匹配所有的26个字符。如果其中有^表示反,如[^a]表示非a的字符
正规则表达式是一些很牛的事,比如我们要去掉某html中的tags:
|
1
|
<b>This</b> is what <span style="text-decoration: underline;">I</span> meant. Understand? |
看看我们的sed命令
|
1
2
3
4
5
6
7
8
|
# 如果你这样搞的话,就会有问题$ sed 's/<.*>//g' html.txt Understand?# 要解决上面的那个问题,就得像下面这样。# 其中的'[^>]' 指定了除了>的字符重复0次或多次。$ sed 's/<[^>]*>//g' html.txtThis is what I meant. Understand? |
我们再来看看指定需要替换的内容:
|
1
2
3
4
5
6
7
8
9
|
$ sed "3s/my/your/g" pets.txtThis is my cat my cat's name is bettyThis is your dog my dog's name is frankThis is my fish my fish's name is georgeThis is my goat my goat's name is adam |
下面的命令只替换第3到第6行的文本。
|
1
2
3
4
5
6
7
8
9
|
$ sed "3,6s/my/your/g" pets.txtThis is my cat my cat's name is bettyThis is your dog your dog's name is frankThis is your fish your fish's name is georgeThis is my goat my goat's name is adam |
|
1
2
3
4
5
|
$ cat my.txtThis is my cat, my cat's name is bettyThis is my dog, my dog's name is frankThis is my fish, my fish's name is georgeThis is my goat, my goat's name is adam |
只替换每一行的第一个s:
|
1
2
3
4
5
|
$ sed 's/s/S/1' my.txtThiS is my cat, my cat's name is bettyThiS is my dog, my dog's name is frankThiS is my fish, my fish's name is georgeThiS is my goat, my goat's name is adam |
只替换每一行的第二个s:
|
1
2
3
4
5
|
$ sed 's/s/S/2' my.txtThis iS my cat, my cat's name is bettyThis iS my dog, my dog's name is frankThis iS my fish, my fish's name is georgeThis iS my goat, my goat's name is adam |
只替换第一行的第3个以后的s:
|
1
2
3
4
5
|
$ sed 's/s/S/3g' my.txtThis is my cat, my cat'S name iS bettyThis is my dog, my dog'S name iS frankThis is my fiSh, my fiSh'S name iS georgeThis is my goat, my goat'S name iS adam |
多个匹配
如果我们需要一次替换多个模式,可参看下面的示例:(第一个模式把第一行到第三行的my替换成your,第二个则把第3行以后的This替换成了That)
|
1
2
3
4
5
|
$ sed '1,3s/my/your/g; 3,$s/This/That/g' my.txtThis is your cat, your cat's name is bettyThis is your dog, your dog's name is frankThat is your fish, your fish's name is georgeThat is my goat, my goat's name is adam |
上面的命令等价于:(注:下面使用的是sed的-e命令行参数)
|
1
|
sed -e '1,3s/my/your/g' -e '3,$s/This/That/g' my.txt |
我们可以使用&来当做被匹配的变量,然后可以在基本左右加点东西。如下所示:
|
1
2
3
4
5
|
$ sed 's/my/[&]/g' my.txtThis is [my] cat, [my] cat's name is bettyThis is [my] dog, [my] dog's name is frankThis is [my] fish, [my] fish's name is georgeThis is [my] goat, [my] goat's name is adam |
圆括号匹配
使用圆括号匹配的示例:(圆括号括起来的正则表达式所匹配的字符串会可以当成变量来使用,sed中使用的是\1,\2…)
|
1
2
3
4
5
|
$ sed 's/This is my \([^,]*\),.*is \(.*\)/\1:\2/g' my.txtcat:bettydog:frankfish:georgegoat:adam |
上面这个例子中的正则表达式有点复杂,解开如下(去掉转义字符):
正则为:This is my ([^,]*),.*is (.*)
匹配为:This is my (cat),……….is (betty)
然后:\1就是cat,\2就是betty
sed的命令
让我们回到最一开始的例子pets.txt,让我们来看几个命令:
N命令
先来看N命令 —— 把下一行的内容纳入当成缓冲区做匹配。
下面的的示例会把原文本中的偶数行纳入奇数行匹配,而s只匹配并替换一次,所以,就成了下面的结果:
|
1
2
3
4
5
6
7
8
9
|
$ sed 'N;s/my/your/' pets.txtThis is your cat my cat's name is bettyThis is your dog my dog's name is frankThis is your fish my fish's name is georgeThis is your goat my goat's name is adam |
也就是说,原来的文件成了:
|
1
2
3
4
|
This is my cat\n my cat's name is bettyThis is my dog\n my dog's name is frankThis is my fish\n my fish's name is georgeThis is my goat\n my goat's name is adam |
这样一来,下面的例子你就明白了,
|
1
2
3
4
5
|
$ sed 'N;s/\n/,/' pets.txtThis is my cat, my cat's name is bettyThis is my dog, my dog's name is frankThis is my fish, my fish's name is georgeThis is my goat, my goat's name is adam |
a命令和i命令
a命令就是append, i命令就是insert,它们是用来添加行的。如:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# 其中的1i表明,其要在第1行前插入一行(insert)$ sed "1 i This is my monkey, my monkey's name is wukong" my.txtThis is my monkey, my monkey's name is wukongThis is my cat, my cat's name is bettyThis is my dog, my dog's name is frankThis is my fish, my fish's name is georgeThis is my goat, my goat's name is adam# 其中的1a表明,其要在最后一行后追加一行(append)$ sed "$ a This is my monkey, my monkey's name is wukong" my.txtThis is my cat, my cat's name is bettyThis is my monkey, my monkey's name is wukongThis is my dog, my dog's name is frankThis is my fish, my fish's name is georgeThis is my goat, my goat's name is adam |
我们可以运用匹配来添加文本:
|
1
2
3
4
5
6
7
|
# 注意其中的/fish/a,这意思是匹配到/fish/后就追加一行$ sed "/fish/a This is my monkey, my monkey's name is wukong" my.txtThis is my cat, my cat's name is bettyThis is my dog, my dog's name is frankThis is my fish, my fish's name is georgeThis is my monkey, my monkey's name is wukongThis is my goat, my goat's name is adam |
下面这个例子是对每一行都挺插入:
|
1
2
3
4
5
6
7
8
9
|
$ sed "/my/a ----" my.txtThis is my cat, my cat's name is betty----This is my dog, my dog's name is frank----This is my fish, my fish's name is george----This is my goat, my goat's name is adam---- |
c命令
c 命令是替换匹配行
|
1
2
3
4
5
6
7
8
9
10
11
|
$ sed "2 c This is my monkey, my monkey's name is wukong" my.txtThis is my cat, my cat's name is bettyThis is my monkey, my monkey's name is wukongThis is my fish, my fish's name is georgeThis is my goat, my goat's name is adam$ sed "/fish/c This is my monkey, my monkey's name is wukong" my.txtThis is my cat, my cat's name is bettyThis is my dog, my dog's name is frankThis is my monkey, my monkey's name is wukongThis is my goat, my goat's name is adam |
d命令
删除匹配行
|
1
2
3
4
5
6
7
8
9
10
11
12
|
$ sed '/fish/d' my.txtThis is my cat, my cat's name is bettyThis is my dog, my dog's name is frankThis is my goat, my goat's name is adam$ sed '2d' my.txtThis is my cat, my cat's name is bettyThis is my fish, my fish's name is georgeThis is my goat, my goat's name is adam$ sed '2,$d' my.txtThis is my cat, my cat's name is betty |
p命令
打印命令
你可以把这个命令当成grep式的命令
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# 匹配fish并输出,可以看到fish的那一行被打了两遍,# 这是因为sed处理时会把处理的信息输出$ sed '/fish/p' my.txtThis is my cat, my cat's name is bettyThis is my dog, my dog's name is frankThis is my fish, my fish's name is georgeThis is my fish, my fish's name is georgeThis is my goat, my goat's name is adam# 使用n参数就好了$ sed -n '/fish/p' my.txtThis is my fish, my fish's name is george# 从一个模式到另一个模式$ sed -n '/dog/,/fish/p' my.txtThis is my dog, my dog's name is frankThis is my fish, my fish's name is george#从第一行打印到匹配fish成功的那一行$ sed -n '1,/fish/p' my.txtThis is my cat, my cat's name is bettyThis is my dog, my dog's name is frankThis is my fish, my fish's name is george |
几个知识点
好了,下面我们要介绍四个sed的基本知识点:
Pattern Space
第零个是关于-n参数的,大家也许没看懂,没关系,我们来看一下sed处理文本的伪代码,并了解一下Pattern Space的概念:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
foreach line in file { //放入把行Pattern_Space Pattern_Space <= line; // 对每个pattern space执行sed命令 Pattern_Space <= EXEC(sed_cmd, Pattern_Space); // 如果没有指定 -n 则输出处理后的Pattern_Space if (sed option hasn't "-n") { print Pattern_Space }} |
Address
第一个是关于address,几乎上述所有的命令都是这样的(注:其中的!表示匹配成功后是否执行命令)
[address[,address]][!]{cmd}
address可以是一个数字,也可以是一个模式,你可以通过逗号要分隔两个address 表示两个address的区间,参执行命令cmd,伪代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
bool bexec = falseforeach line in file { if ( match(address1) ){ bexec = true; } if ( bexec == true) { EXEC(sed_cmd); } if ( match (address2) ) { bexec = false; }} |
关于address可以使用相对位置,如:
|
1
2
3
4
5
6
7
8
9
10
|
# 其中的+3表示后面连续3行$ sed '/dog/,+3s/^/# /g' pets.txtThis is my cat my cat's name is betty# This is my dog# my dog's name is frank# This is my fish# my fish's name is georgeThis is my goat my goat's name is adam |
命令打包
第二个是cmd可以是多个,它们可以用分号分开,可以用大括号括起来作为嵌套命令。下面是几个例子:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
$ cat pets.txtThis is my cat my cat's name is bettyThis is my dog my dog's name is frankThis is my fish my fish's name is georgeThis is my goat my goat's name is adam# 对3行到第6行,执行命令/This/d$ sed '3,6 {/This/d}' pets.txtThis is my cat my cat's name is betty my dog's name is frank my fish's name is georgeThis is my goat my goat's name is adam# 对3行到第6行,匹配/This/成功后,再匹配/fish/,成功后执行d命令$ sed '3,6 {/This/{/fish/d}}' pets.txtThis is my cat my cat's name is bettyThis is my dog my dog's name is frank my fish's name is georgeThis is my goat my goat's name is adam# 从第一行到最后一行,如果匹配到This,则删除之;如果前面有空格,则去除空格$ sed '1,${/This/d;s/^ *//g}' pets.txtmy cat's name is bettymy dog's name is frankmy fish's name is georgemy goat's name is adam |
Hold Space
第三个我们再来看一下 Hold Space
接下来,我们需要了解一下Hold Space的概念,我们先来看四个命令:
g: 将hold space中的内容拷贝到pattern space中,原来pattern space里的内容清除
G: 将hold space中的内容append到pattern space\n后
h: 将pattern space中的内容拷贝到hold space中,原来的hold space里的内容被清除
H: 将pattern space中的内容append到hold space\n后
x: 交换pattern space和hold space的内容
这些命令有什么用?我们来看两个示例吧,用到的示例文件是:
|
1
2
3
4
|
$ cat t.txtonetwothree |
第一个示例:
|
1
2
3
4
5
6
7
8
9
|
$ sed 'H;g' t.txtoneonetwoonetwothree |
是不是有点没看懂,我作个图你就看懂了。
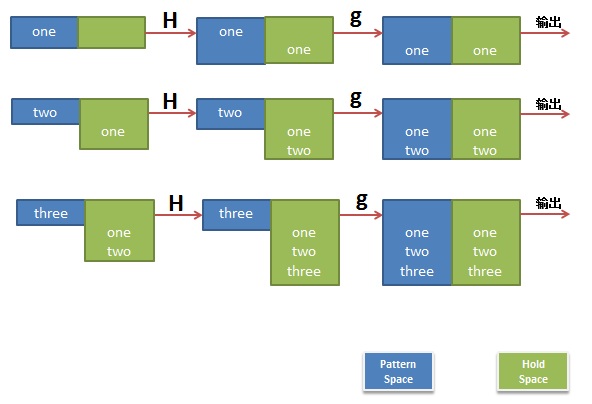
第二个示例,反序了一个文件的行:
|
1
2
3
4
|
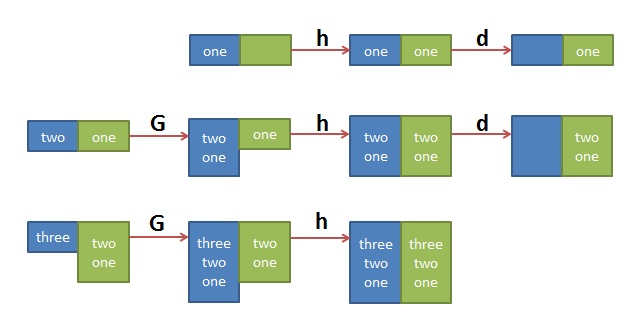
$ sed '1!G;h;$!d' t.txtthreetwoone |
其中的 ‘1!G;h;$!d’ 可拆解为三个命令
- 1!G —— 只有第一行不执行G命令,将hold space中的内容append回到pattern space
- h —— 第一行都执行h命令,将pattern space中的内容拷贝到hold space中
- $!d —— 除了最后一行不执行d命令,其它行都执行d命令,删除当前行
这个执行序列很难理解,做个图如下大家就明白了:
就先说这么多吧,希望对大家有用。
(全文完)
(转载本站文章请注明作者和出处 酷 壳 – CoolShell.cn ,请勿用于任何商业用途)
转:Sed使用的更多相关文章
- sed的应用
h3 { color: rgb(255, 255, 255); background-color: rgb(30,144,255); padding: 3px; margin: 10px 0px } ...
- 文本处理三剑客之sed命令
第十八章.文本处理三剑客之sed命令 目录 sed介绍 sed命令常用选项 sed常用编辑命令 sed使用示例 sed高级语法 18.1.sed简介 sed全名stream editor,流编辑器,s ...
- 6-2 sed 命令
1. sed : stream editor,流编辑器 是处理纯ASICC纯文本,按行琢行操作的. 编辑器有两种,行编辑器和全屏编辑器 sed:默认不编辑原文件,仅对模式空间中的数据做处理,而后.处理 ...
- 基本shell编程【3】- 常用的工具awk\sed\sort\uniq\od
awk awk是个很好用的东西,大量使用在linux系统分析的结果展示处理上.并且可以使用管道, input | awk '' | output 1.首先要知道形式 awk 'command' fi ...
- sed awk grep三剑客常用
sed的常用用法: awk的常用用法: grep的常用用法: 除了列出符合行之外,并且列出后10行. grep -A 10 Exception kzfinance-front.log 除了列出符合行之 ...
- linux shell 用sed命令在文本的行尾或行首添加字符
转自 http://www.cnblogs.com/aaronwxb/archive/2011/08/19/2145364.html 昨天写一个脚本花了一天的2/3的时间,而且大部分时间都耗在了sed ...
- Sed、Awk单行脚本快速参考
文本间隔: # 在每一行后面增加一空行 sed G awk '{printf("%s\n\n",$0)}' # 将原来的所有空行删除并在每一行后面增加一空行. # 这样在输出的文本 ...
- sed awk 样例
sed [options] '[action]' filename options: -n:一般sed命令会把所有数据都输出到屏幕,如果加入此选项,则只会把经过sed命令处理的行输出到屏幕. -e:允 ...
- linux sed命令详解
简介 sed 是一种在线编辑器,它一次处理一行内容.处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的 ...
- sed命令详解
搜索 纠正错误 添加实例 sed 功能强大的流式文本编辑器 补充说明 sed 是一种流编辑器,它是文本处理中非常中的工具,能够完美的配合正则表达式使用,功能不同凡响.处理时,把当前处理的行存储在临时 ...
随机推荐
- redis集群安装搭建
vi redis-6379.conf #包含通用配置 include "/usr/local/redis/conf/redis-common.conf" pidfile &qu ...
- [cf1349E]Slime and Hats
首先,当发现全场不存在黑色帽子时,显然所有人都知道其是白色帽子,即必然离开 当第一轮时,若第$n$个人发现前面$n-1$个人全是白色时,其自己必然是黑色,必然离开 而第二轮时,若第$n-1$个人发现$ ...
- [loj3339]美食家
令$f[i][j]$表示第$i$个时刻走到点$j$的最小时间,暴力的$dp$复杂度为$o(tm)$ 如果没有限制,由于$w\le 5$,记录前5个时刻的状态即可求出当前状态,用矩阵乘法可优化到$o(n ...
- linux中为何每次修改完配置文件后都需要重新加载配置文件
1.大家刚接触linux时,可能会有这样的疑问:为什么每次修改完配置文件之后,总是要重新加载配置文件才能生效?或者需要重启后才能生效? 之前听过一个解释是这样子的: "修改了文件内容 ...
- windows defender antivirus占用内存解决教程
[windows defender关闭常见问题] windows defender antivirus占用内存解决教程: 1.按下"Win+R"打开"运行" 2 ...
- 多线程06.thread守护线程
package chapter2; public class Demo02 { public static void main(String[] args) { Thread th1=new Thre ...
- 带你了解Typescript的14个基础语法
摘要:Typescript可以说是JavaScript的超集,在JS的基础上新增了许多语法特性,使得类型不再可以随意转换,能大大减少开发阶段的错误. 本文分享自华为云社区<Typescript基 ...
- 洛谷 P4749 - [CERC2017]Kitchen Knobs(差分转换+dp,思维题)
题面传送门 一道挺有意思的思维题. 首先有一个 obvious 的结论,就是对于每个炉子,要么转到哪里都符合条件,要么存在唯一的最大值.对于转到哪儿都符合条件的炉子我们 duck 不必考虑它,故我们只 ...
- Codeforces 1458E - Nim Shortcuts(博弈论+BIT)
Codeforces 题目传送门 & 洛谷题目传送门 首先看到这样的题我们不妨从最特殊的情况入手,再逐渐推广到一般的情况.考虑如果没有特殊点的情况,我们将每个可能的局面看作一个点 \((a,b ...
- R语言与医学统计图形-【17】ggplot2几何对象之热图
ggplot2绘图系统--heatmap.geom_rect 这里不介绍更常见的pheatmap包. 1.heatmap函数 基础包. data=as.matrix(mtcars) #接受矩阵 hea ...