服务容错保护断路器Hystrix之七:做到自动降级
从《高可用服务设计之二:Rate limiting 限流与降级》中的“自动降级”中,我们这边将系统遇到“危险”时采取的整套应急方案和措施统一称为降级或服务降级。想要帮助服务做到自动降级,需要先做到如下几个步骤:
- 可配置的降级策略:降级策略=达到降级的条件+降级后的处理方案,策略一定得可配置,因为不同的服务对服务的质量定义不一样,降级的方案也将不一样。
- 可识别的降级边界:一定要精确的知道需要对谁进行降级,可以是一个对外服务、对下游的一个依赖或者是内部一段处理逻辑。降级边界主要用来植入降级逻辑。
- 数据采集:是否达到降级条件依赖于采集的数据,这些数据可以是当前某段时间的数据,也可以是很长一段时间的历史数据。
- 行为干预:进入降级状态后将会对正常的业务流程产生干预,可能是限流、熔断,也可能是同步流程变为异步流程等(比如发送MQ的变成oneway的形式)等。
- 结果干预:是返回null,还是默认值,还是流程上的同步改异步等。
- 快速恢复:即如何从降级状态变回正常状态,这也需要达到某些条件。
我们来逐步看下Hystrix是如何做到以上几点的,
### 可配置的降级策略 ###
Hystrix提供了三种降级策略:并发、耗时和错误率,而Hystrix的设计本身就能很好的支持动态的调整这些策略(简单的说就是调整并发、耗时和错误率的阈值),当然,如何去动态调整需要用户自己来实现,Hystrix只提供了入口,就是说,Hystrix并没有提供一个服务端界面来动态调整这些策略,这多少有点让人遗憾。如果要了解Hystrix具体的策略配置,可以看看HystrixCommandProperties 和 HystrixThreadPoolProperties两个类。
### 可识别的降级边界 ###
降级工具面临的第一个难题就是如何在业务代码中植入降级逻辑,业务研发人员得提前明确和定义哪些地方是风险点,然后将这些地方的逻辑抽取出来,Hystrix包装需降级的业务逻辑采用的是Command设计模式,我们知道,命令模式主要是将请求封装到对象内部,让我们使用对象一样来使用请求。这样对Hystrix大有好处,因为你需要降级的业务逻辑和数据已经封装成一个Command对象交给Hystrix了,Hystrix直接来接管业务逻辑的执行权,该何时调用,或者甚至不调用都可以,我们来看看Hystrix定义的命令接口。
只需要简单继承HystrixCommand,就相当于接入了Hystrix,泛型R代表返回值类型,在run()方法中直接实现正常的业务逻辑,并返回R类型的结果,如果降级后需要返回特殊的值,你只需要覆盖getFallback()方法即可。
举个例子,见《服务容错保护断路器Hystrix之六:缓存功能的使用》
可以看出,我们创建了一个BookCommand 的实例,然后调用了execute方法来获取结果,这样就基本完成了,Hystrix库类已经给逻辑附上了缓存、自动降级等逻辑了,当然里面使用了大量Hystrix默认的降级策略配置(本文不是Hystrix使用的详细教程,所以这里主要突出的是用法而不强调具体的策略配置)。这里同样也说明了为什么动态调整配置是很容易的,因为每个请求都会新建Command对象(注意,Command对象是有状态的,不能重用),你只需要在创建时调整策略参数就行了,当然,这得用户自己来实现。
虽然看起来很简单,但老司机马上会发现问题:
- 系统中每一处需要降级的逻辑都需要将其封装成一个Command类,哪怕需要降级的方法只有一行代码。如果一个系统有一百个需要降级的点,那么我们需要在系统中新增一百个Command类,有时候这让人难以接受。
- 对老的业务系统来说,接入Hystrix将意味着巨大的工作量,因为你要把很多逻辑都封装成Command,你能接受但测试同学未必愿意。
- 每次请求都将创建一个Command对象,因为Command对象包含了降级逻辑的大部分操作,是个重状态的对象,不能复用,如果QPS过高,将产生大量的朝生夕死的对象,对内存分配和GC将产生一定的压力。
很多用户确实也提出过抱怨,为何Hystrix的侵入性那么强?但Hystrix设计者们这么做自然有他们的道理(详见:https://github.com/Netflix/Hystrix/wiki/FAQ%20:%20General 的Why is it so intrusive?部分),他们认为,我们需要给应用的依赖提供一个清晰的屏障,使用Command模式不仅仅是出于功能上的原因,也是作为一种标准机制,通过Command对象来向用户传递它是受保护的资源。可见,Hystrix的设计者们并不建议我们使用基于注解或AOP来作为接入Hystrix的方式,但他们仍然说:If you still feelstrongly that you shouldn't have to modify libraries and add command objectsthen perhaps you can contribute an AOP module.(直译过来就是如果你嫌麻烦不想创建这么多Command对象,有本事你自己去实现AOP啊!开个玩笑(*^__^*) )。
### 数据采集 ###
收集数据是必不可少的一步,每个降级点(需要采取降级保护的点)的数据是独立的,所以我们可以给每个降级点配置单独的策略。这些策略一般是建立在我们对这些降级点的了解之上的,初期甚至可以先观察一下采集的数据来指定降级策略。采集哪些数据?数据如何存储?数据如何上报?这都是Hystrix需要考虑的问题,Hystrix采用的是滑动窗口+分桶的形式来采集数据(具体细节见另一篇),这样既解决了数据在统计周期间切换而带来的跳变问题(通过时间窗口),也控制了切换了力度(通过桶大小)。另一个有意思的地方是,与常规的同步统计数据的方式不同,Hystrix采用的是RxJava来进行事件流的异步统计数据,类似于观察者模式(具体细节见另一篇),这样做的好处是降低统计时阻塞业务逻辑的风险,在某些情况下还能享受多核CPU所带来的性能上的收益。
### 行为干预 ###
一旦发现采集的数据命中了降级策略,那么降级工具就将对请求进行行为干预,行为干预是评价一个降级工具好坏的重要指标,它的设计直接关系到系统的“弹性”到底有多大。但有时候行为干预和上面提到的数据采集这两个动作是同时完成的,比如使用信号量、线程池或者令牌桶算法来进行降级的时候。行为干预的设计是很有技巧的,一般来说有如下两种方案:
- 实时采集(当前某段时间周期的)数据,对每笔请求都进行策略判断(每笔请求都会加入数据并进行分析),一旦命中策略,当即对这笔请求进行行为干预,如果没有命中,则执行正常的业务逻辑。
- 实时采集(当前某段时间周期的)数据,对每笔请求都进行策略判断(每笔请求都会加入数据并进行分析),一旦有一笔请求命中了策略,接下来的一段时间(可配)内的所有请求都会被行为干预,哪怕接下来再也没有请求命中策略,一直到该段时间过去。
方案a似乎是比较合理的,它总是将系统的行为尽可能的控制在我们预期之内(即各项指标都在配置的策略之下),但多数情况下,我们配置策略会比较宽泛,不那么严格,那这时候采用方案a对系统来说还是有一定的风险。这时候就出现了相对更激进的方案b!一但某些请求导致统计数据触犯了降级策略,那么系统会对后续一段时间的所有请求进行降级处理,即我们熟知的降级延长。而Hystrix将两者结合起来了,让行为干预更加灵活。
### 结果干预 ###
被降级后的请求是应该返回null?还是默认值?还是抛异常?这些都要根据业务而定。Hystrix也在HystrixCommand提供了getFallback方法来方便用户返回降级后的结果。
### 快速恢复 ###
快速恢复功能在那些经常由于外部因素而导致进入降级状态的系统来说尤为重要,降级系统或工具的一个重大目标就是自动性,摆脱需要人为控制开关来保证功能熔断的“原始时代”,所以当外部条件已经恢复,系统也应该在最短的时间内恢复到正常服务状态,这就要求降级系统能够在让业务系统进入降级状态的同时,让业务系统有探测外界环境的机会。大多数降级系统都会在一段时间后“放”一笔请求进来,让它去“试一试”,如果结果是成功的,那么将让业务系统恢复到正常状态,Hystrix同样也是采用这种做法。
如果看到这里,其实大家已经对Hystrix的功能有一定的了解,这里再给一张官方的图:
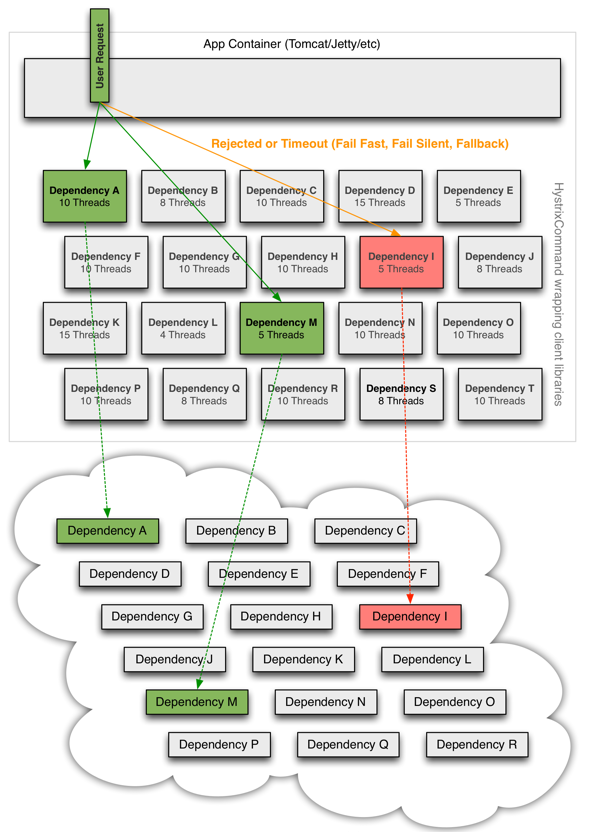
这张图已经充分说明了官方推荐的是通过Command+线程池的模式来进行业务功能的剥离和管理,这些大大小小的线程池,使用不当,将产生隐患,所以千万不要让Hystrix的这种用法变成反模式。
在最后,我们来简单总结下Hystrix的特色:
- Hystrix内部大量使用了响应式编程模型,通过RxJava库,把能异步做的都做成异步了。这似乎能降低代码复杂度(我是指对RxJava了解的人),并且在多核CPU的服务器上能带来意外性能收获。
- Hystrix能做到通过并发、耗时和异常来进行降级,并能在(并发、限流或内部产生的异常导致的)错误率达到一定阈值时进行服务熔断,并且还能做到从降级状态快速恢复。
- Hystrix通过Command模式来包装降级业务,这有时候提高了接入成本。
- Hystrix只提供了策略变更的入口,但具体的策略可视化和动态配置还是得用户来实现,这确实非常尴尬。
- Hystrix默认的仪表盘只提供了简单的实时数据显示,如果要持久化历史数据,也得用户来实现。
服务容错保护断路器Hystrix之七:做到自动降级的更多相关文章
- 服务容错保护断路器Hystrix之二:Hystrix工作流程解析
一.总运行流程 当你发出请求后,hystrix是这么运行的 红圈 :Hystrix 命令执行失败,执行回退逻辑.也就是大家经常在文章中看到的“服务降级”. 绿圈 :四种情况会触发失败回退逻辑( fal ...
- 服务容错保护断路器Hystrix之五:配置
接着<服务容错保护断路器Hystrix之二:Hystrix工作流程解析>中的<2.8.关于配置>再列举重要的配置如下 一.hystrix在生产中的建议 1.保持timeout的 ...
- 服务容错保护断路器Hystrix之三:断路器监控(Hystrix Dashboard)-单体监控
turbine:英 [ˈtɜ:baɪn] 美 [ˈtɜ:rbaɪn] n.汽轮机;涡轮机;透平机 一.Hystrix Dashboard简介 在微服务架构中为了保证程序的可用性,防止程序出错导致网络阻 ...
- 服务容错保护断路器Hystrix之六:服务熔断和服务降级
伴随着微服务架构被宣传得如火如荼,一些概念也被推到了我们面前(管你接受不接受),其实大多数概念以前就有,但很少被提的这么频繁(现在好像不提及都不好意思交流了).想起有人总结的一句话,微服务架构的特点就 ...
- 服务容错保护断路器Hystrix之一:入门示例介绍(springcloud引入Hystrix的两种方式)
限流知识<高可用服务设计之二:Rate limiting 限流与降级> 在微服务架构中,我们将系统拆分成了一个个的服务单元,各单元间通过服务注册与订阅的方式互相依赖.由于每个单元都在不同的 ...
- 服务容错保护断路器Hystrix之八:Hystrix资源隔离策略
在一个基于微服务的应用程序中,您通常需要调用多个微服务完成一个特定任务.不使用舱壁模式,这些调用默认是使用相同的线程来执行调用的,这些线程Java容器为处理所有请求预留的.在高服务器请求的情况下,一个 ...
- 服务容错保护断路器Hystrix之六:缓存功能的使用
高并发环境下如果能处理好缓存就可以有效的减小服务器的压力,Java中有许多非常好用的缓存工具,比如Redis.EHCache等,当然在Spring Cloud的Hystrix中也提供了请求缓存的功能, ...
- 服务容错保护断路器Hystrix之四:断路器监控(Hystrix Dashboard)-turbine集群监控
turbine 英[ˈtɜ:baɪn] n. 汽轮机; 涡轮机; 透平机; OK,上文我们看了一个监控单体应用的例子,在实际应用中,我们要监控的应用往往是一个集群,这个时候我们就得采取Turbine集 ...
- Spring Cloud(四):服务容错保护 Hystrix【Finchley 版】
Spring Cloud(四):服务容错保护 Hystrix[Finchley 版] 发表于 2018-04-15 | 更新于 2018-05-07 | 分布式系统中经常会出现某个基础服务不可用 ...
随机推荐
- 同一个页面引用不同版本jquery库
(如有打扰,请忽略)阿里云ECS大羊群,2U4G低至1.4折,限实名新用户,需要的点吧https://promotion.aliyun.com/ntms/act/vm/aliyun-group/tea ...
- scrapy框架学习之路
一.基础学习 - scrapy框架 介绍:大而全的爬虫组件. 安装: - Win: 下载:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted pip3 ...
- 求连续数字的和------------------------------用while的算法思想
前端代码: <%@ Page Language="C#" AutoEventWireup="true" CodeFile="Default.as ...
- 【HAOI2011】 向量
数论好劲啊 原题: 给你一对数a,b,你可以任意使用(a,b), (a,-b), (-a,b), (-a,-b), (b,a), (b,-a), (-b,a), (-b,-a)这些向量,问你能不能拼出 ...
- docker下搭建fastfds集群版
搭建过程参考 作者 https://me.csdn.net/feng_qi_1984 的课程视频 声明:集群版是在我之前写的单机版基础之上进行搭建的,我将安装了fastfds单机版的docker打包成 ...
- 套接字选项——getsockopt和setsockopt
这两个函数仅用于套接字 #include <sys/socket.h> int getsockopt(int sock, int level, int optname, void *opt ...
- 适配器(Adapter)
Adapter:将一个Class的接口转换成另一个Class的接口,使原本因接口不兼容而不能合作的Class可以一起运作.主要有两种:迭代器适配器(Iterator Adpater)和容器适配器(Co ...
- 如何使用百度bae部署web项目
百度bae提供了支持各种开发环境的的应用引擎,包括node.js.php.java等,而且还免费提供了一定容量的mysql.mongodb.redis等数据库,所以,可以把它当作一个云服务器来使用.而 ...
- MyBatis 学习资料
MyBatis 学习资料 table th:first-of-type { width: 90px; } table th:nth-of-type(2) { } table th:nth-of-typ ...
- webpack 4 知识点
相应Github地址:https://github.com/cag2050/webpack4_demo css-loader 让我们能在javascript代码中导入css文件,但这还不能让css起作 ...