Windowsx64位安装pymssql并完成与数据库链接
常流程只需要打开下载并按照常规方法安装mssql包即可在程序中import pymssql,不过安装mssql确实有些小麻烦。
从开始安装就开始出现了各种异常错误
首先出现sqlfront.h文件找不多,查了很多资料也没有看明白是什么个原因。。
最终在这里仔细阅读了一下文档,开始一步步尝试往下解决
大致的意思是讲其实pymssql是依赖于一个叫FreeTDS的东西,查了一下它是一个C语言链接sqlserve的公共开源库。
在windows下安装接下来参照这篇文档说明开始准备下载freetds-v0.95.95-win-x86-vs2008.zip
当然这里可以根据自己的Python版本去下载对应的包,下载地址
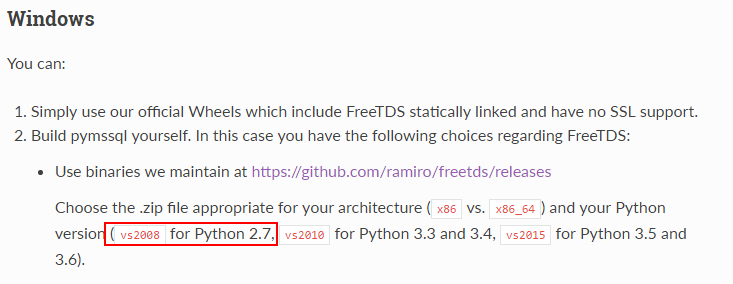
下载完后发现里边的文件目录大致是这样的

打开include一看,原来我需要的文件都在这个文件里,然后就把这个的所有文件bin+include+lib+lib-nossl全部copy到python的安装目录再试一下没有原来的错误了
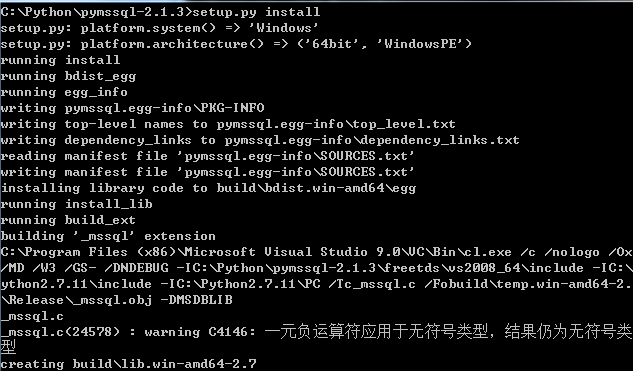
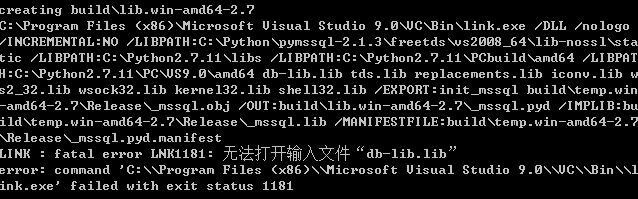
新的问题又出现了,无法打开输入文件“db-lib.lib”
这里就比较蛋疼了,单仔细阅读以下,翻到文章结尾的安装包
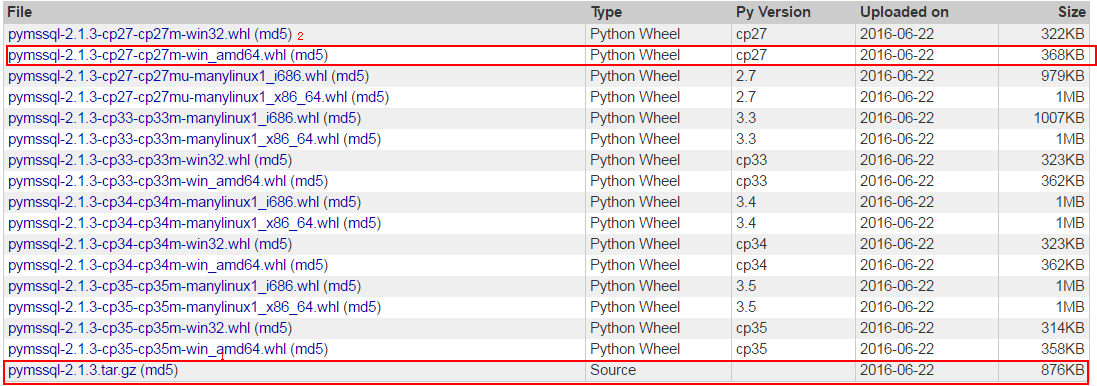
既然用pymssql-2.1.3.tar.gz不能正确安装,就换一种方式,于是下载了2中的whl文件
下载完后将 pymssql-2.1.3-cp27-cp27m-win_amd64.whl放在安装文件目录中,运行CMD到指定文件目录
这时出现以下错误:
Requirement already satisfied: pymssql==2.1.3 from file:///C:/Python/pymssql-2.1
.3-cp27-cp27m-win_amd64.whl in c:\python2.7.11\lib\site-packages
错误提示很明显示因为之前安装时已经将文件放在了c:\python2.7.11\lib\site-packages文件中,因此在site-packages中删掉pymssql的安装,再试一次顺利完成!
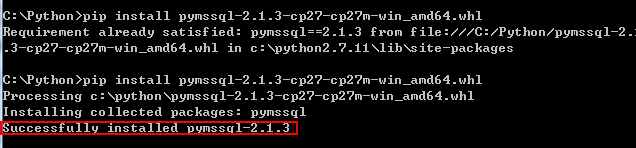
最后为了验证以下,在文件中链接当前数据库看一下是否可以连通。。
#coding:utf-8
import urllib2
import os
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
import urllib
import string
from bs4 import BeautifulSoup #导入解析html源码模块
import pymssql #导入mssql数据库连接包
conn=pymssql.connect(host='127.0.0.1',user='testdb',password='testdb@123',database='IM_CRM')
cur=conn.cursor()
cur.execute('select top 5 * from [dbo].[crm_Cart]')
#如果update/delete/insert记得要conn.commit()
#否则数据库事务无法提交
print (cur.fetchall())
cur.close()
conn.close()
打印结果看一下

对比以下数据库

仔细观察没有问题,用这种方式一样可以链接数据库,到这里就开始后面的详细业务编写吧。
最后再附一个抓取的py文件吧
#coding:utf-8
import urllib2
import os
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
import time
import datetime
import urllib
import string
from bs4 import BeautifulSoup #导入解析html源码模块
import pymssql #导入mssql数据库连接包 print "开始时间:"+datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f') #抓取页面逻辑
for num in range(101,200+1):#页数控制
url = "http://xxx/Suppliers.asp?page="+str(num)+"&hdivision=" #循环ip地址
header = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0",
"Referer":"http://xxx/suppliers.asp"
}
req = urllib2.Request(url,data=None,headers=header)
req.encding="utf-8"
ope = urllib2.urlopen(req)
#请求创建完成
soup = BeautifulSoup(ope.read(), 'html.parser') COMCount = 0
tableTrList=soup.select("table tr")
tableTrList.remove(tableTrList[0])
for trtag in tableTrList:
COMCount+=1
companyname= trtag.contents[1].a.string # 公司名称
area=trtag.contents[3].string # 地区
tel=trtag.contents[5].string # 电话
web = trtag.contents[7].a.string # 网址
prolisturl=trtag.contents[11].a['href']#产品列表链接
companyID=prolisturl[20:] #获取公司对应ID
print str(COMCount)+'获取产品列表链接:http://www.xxx/'+prolisturl
if companyname is None:
companyname=""
if area is None:
area = ""
if tel is None:
tel = ""
if web is None:
web = "" print "公司名称:"+companyname
print "地区:" + area
print "电话:" + tel
print "网址:" + web
print str(COMCount)+"公司信息开始写入:"+"INSERT INTO [dbo].[Company](BioID,ComName,Area,Tel,WebSite,InDate) VALUES ('"+companyID+"','"+companyname+"','"+area+"','"+tel+"','"+web+"','"+datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f')+"') " #写入企业信息起
conn = pymssql.connect(host='GAOMS-PC\SQLEXPRESS', user='test', password='abc123!@#', database='BIO-EQUI')
cur = conn.cursor()
cur.execute("INSERT INTO [dbo].[Company](BioID,ComName,Area,Tel,WebSite,InDate) VALUES ('"+companyID+"','"+companyname+"','"+area+"','"+tel+"','"+web+"','"+datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f')+"') ")
conn.commit()
cur.close()
conn.close()
#写入企业信息止
print str(COMCount)+"公司信息写入完成" #验证公司下是否有产品
urlpropage="http://xxx/otherproduct.asp?id="+companyID
#urlpropage="http://xxx/otherproduct.asp?id=64356"#测试某一产品地址排查异常使用
headerpropage = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0",
"Referer": "" + url
}
reqpropage = urllib2.Request(urlpropage, data=None, headers=headerpropage)
reqpropage.encding = "utf-8"
opepropage = urllib2.urlopen(urlpropage)
souppropage = BeautifulSoup(opepropage.read(), 'html.parser')
tableTrPageCount = souppropage.select("table tr")
ProPageCount=''
if (len(tableTrPageCount) > 0):
try:
ProPageCount=str(souppropage.select("form p")[0])
dijiye=ProPageCount[ProPageCount.index("第"):].replace("\r\n"," ").replace("</p>"," ").strip()
ProPageCount=dijiye[dijiye.index("/")+1:].replace("页"," ").strip()
print "产品"+str(COMCount)+"下包含"+ProPageCount+"页产品__________________________________"
PROCount = 0
# 循环获取产品列表内容 if (int(ProPageCount)>2):
ProPageCount=2 #如果产品页数过多只去前2页 for numpro in range(1, int(ProPageCount)+1):
urlprolist = "http://www.bio-equip.com/" + str(prolisturl) + "&page=" + str(numpro) + "&hdivision=" # 循环链接
headerprolist = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0",
"Referer": "" + url
}
reqprolist = urllib2.Request(urlprolist, data=None, headers=headerprolist)
reqprolist.encding = "utf-8"
opeprolist = urllib2.urlopen(reqprolist)
soupprolist = BeautifulSoup(opeprolist.read(), 'html.parser')
tableTrListCount = soupprolist.select("table tr")
#print tableTrListCount 打印获取的表格数据
tableTrListCount.remove(tableTrListCount[0])
for trtagPro in tableTrListCount:
PROCount += 1
proname = trtagPro.contents[0].a.string # 产品名称
proPlace = trtagPro.contents[2].string # 产品产地
ProType = trtagPro.contents[4].string # 产品型号
if proPlace is None:
proPlace = ""
if area is None:
area = ""
if ProType is None:
ProType = ""
print "产品名称:" + proPlace
print "产品产地:" + area
print "产品型号:" + ProType
print "获取" + str(COMCount) + "下产品:" + str(PROCount) + proname + "第" + str(numpro) + "页" print str(COMCount)+"_"+str(PROCount)+"产品写入开始"+"INSERT INTO [dbo].[Product](ComID,ProName,ProPlace,ProType) VALUES ('" + companyID + "','" + proname + "','" + proPlace + "','" + ProType + "') " # 写入企业产品信息起
connpro = pymssql.connect(host='GAOMS-PC\SQLEXPRESS', user='test', password='abc123!@#',database='BIO-EQUI')
curpro = connpro.cursor()
curpro.execute("INSERT INTO [dbo].[Product](ComID,ProName,ProPlace,ProType,InDate) VALUES ('" + companyID + "','" + proname + "','" + proPlace + "','" + ProType + "','"+datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f')+"') ")
connpro.commit()
curpro.close()
connpro.close()
# 写入企业产品信息止 except Exception:
pass
print "结束时间:" + time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))
Windowsx64位安装pymssql并完成与数据库链接的更多相关文章
- Win7 64位安装VS2013无法连接远程数据库
win7 64位安装vs2013后连接远程数据库出现下面的问题:A first chance exception of type 'System.AccessViolationException' o ...
- Windows10 64位 安装 Postgresql 数据库
1,下载Postgresql 10.7 版本,下载地址 https://www.enterprisedb.com/downloads/postgres-postgresql-downloads 2 ...
- Windos 下python2.7安装 pymssql 解决方案
最近在学python,到安装pymssql这一块遇到了不少问题. 第一:如何安装python 模块,也是最主要的问题. 可以这么理解:在安装python其它模块之前,可以先安装一个负责安装模块的模块. ...
- 试用vSphere 6(三):安装vCenter 6(独立数据库)之:vCenter安装与配置
------------------------------------------ 一.VMware vSphere 6(RC版)安装配置系列文章: 1.试用vSphere 6(一):安装ESXi ...
- CentOS6.0(64位)安装Apache+PHP+Mysql教程,安装Magento(解决DOM,Mcrypt,GD问题)完整教程
CentOS6.0(64位)安装Apache+PHP+Mysql教程,安装Magento(解决DOM,Mcrypt,GD问题)完整教程 0 Posted by :小黑 On : 2012 年 9 ...
- Windows7 64位安装最新版本MySQL服务器
Windows7 64位安装最新版本MySQL服务器 近期,一直在研究MySQL数据库,经常修改配置文件,导致MySQL数据库无法使用,不得不反复重装MySQL数据库.以下是在Windows7 64位 ...
- Python3.6及以上pip安装pymssql错误的解决办法[Windows&Linux freetds安装]
只有由于Python3.6装不上 pymssql,所以一直用Python3.5的版本. 报错界面 现在有了新的解决方法: 原帖如下: https://docs.microsoft.com/en-us/ ...
- Win7 32位安装Oracle11g R2 图解示例
Win7 32位操作系统安装Oracle11g R2 图解示例.废话不说了,直接上图. 1.下载的两个oracle 11gR2压缩包解压到单独的文件夹中. 2.找到解压的database文件夹中的Se ...
- Windows7 64位安装最新版本号MySQLserver
Windows7 64位安装最新版本号MySQLserver 最近,一直在研究MySQL数据库.常常改动配置文件.导致MySQL数据库无法使用.不得不重复重装MySQL数据库.下面是在Windows7 ...
随机推荐
- XXS level5
(1)用第四关的方法尝试,发现不行,查看页面源代码,发现on中间有了下划线 (2)查看PHP源代码 <?php ini_set("display_errors", 0); $ ...
- Python简单介绍
一.变量名命名规则 1).变量名要由字母数字下划线组成 2)变量名禁止以数字开头 3)变量名禁止使用Python自带关键字 4)变量名不要用中文和拼音 5)变量名大小写敏感 6)变量名推荐写法:下划线 ...
- Java中动态获取项目根目录的绝对路径
https://www.cnblogs.com/zhouqing/archive/2012/11/10/2757774.html 序言 在开发过程中经常会用到读写文件,其中就必然涉及路径问题.使用固定 ...
- CH4701 天使玩偶
题意 4701 天使玩偶 0x40「数据结构进阶」例题 描述 题目PDF 样例输入 2 3 1 1 2 3 2 1 2 1 3 3 2 4 2 样例输出 1 2 来源 石家庄二中Violet 3杯省选 ...
- torchvision库简介(翻译)
部分跟新于:4.24日 torchvision 0.2.2.post3 torchvision是独立于pytorch的关于图像操作的一些方便工具库. torchvision的详细介绍在:http ...
- jenkins安装教程
首先部署java环境 然后部署tomacat(部署之后无需开启tomcat服务) sudo wget -O /etc/yum.repos.d/jenkins.repo https://pkg.jenk ...
- Singer 开源便捷的ETL 工具
singer 是一个强大,灵活的etl 工具,我们可以方便的提取web api,file,queue,基本上各种你可以想到的 数据源. singer 有一套自己的数据处理规范, taps, targe ...
- Laya IDE 快捷键
Laya IDE 快捷键: ctrl+p 快速打开文件,fb中对应的是ctrl+shift+G ctrl+d 删除一行 ctrl+shift+o打开符号 alt+shift+下箭头 复制一行 alt+ ...
- 转-[WebServer] Windows操作系统下 Tomcat 服务器运行 PHP 的环境配置
原文 前言: 由于本人在开发和学习过程中需要同时部署 JavaWeb 和 PHP 项目,于是整理了网上的一些相关资料,并结合自己的实际操作,记录于此,以供参考. 一.环境(64bit): 1.操作系统 ...
- shiro学习笔记
一.概念: shiro是apache旗下一个开源框架,它将软件系统的安全认证相关的功能抽取出来,实现用户身份认证.权限授权.加密.会话管理等功能,组成了一个通用的安全认证框架. (一)shiro的功能 ...