排序算法<No.3>【桶排序】
算法,是永恒的技能,今天继续算法篇,将研究桶排序。
算法思想:
桶排序,其思想非常简单易懂,就是是将一个数据表分割成许多小数据集,每个数据集对应于一个新的集合(也就是所谓的桶bucket),然后每个bucket各自排序,或用不同的排序算法,或者递归的使用bucket sort算法,往往采用快速排序。是一个典型的divide-and-conquer分而治之的策略。
其中核心思想在于如何将原始待排序的数据划分到不同的桶中,也就是数据映射过程f(x)的定义,这个f(x)关乎桶数据的平衡性(各个桶内的数据尽量数量不要差异太大),也关乎桶排序能处理的数据类型(整形,浮点型;只能正数,或者正负数都可以)
另外,桶排序的具体实现,需要考虑实际的应用场景,因为很难找到一个通吃天下的f(x)。
基本实现步骤:
1. 根据数据类型,定义数据映射函数f(x)
2. 对数据进行分别规划进入桶内
3. 对桶做基于序号的排序
4. 对每个桶内的数据进行排序(快排或者其他排序算法)
5. 将排序后的数据映射到原始输入数组中,作为输出
桶排序,通常情况下速度非常快,比快速排序还要快,但是,依据我的理解,这个快,应该是建立在大数据量的排序。若待排序的数据元素个数比较少,桶排序的优势就不是那么明显了,因为桶排序就是基于分而治之的策略,可以将数据进行分布式排序,充分发挥并行计算的优势。
特性说明:
1. 桶排序的时间复杂度通常是O(N+N*logM),其中,N表示桶的个数,M表示桶内元素的个数(这里,M取的是一个大概的平均数,这也说明,为何桶内的元素尽量不要出现有的很多,有的很少这种分布不均的事情,分布不均的话,算法的性能优势就不能最大发挥)。
2. 桶排序是稳定的(是可以做到平衡排序的)。
3. 桶排序,在内存方面消耗是比较大的,可以说其时间性能优势是由牺牲空间换来的。
下面,我们直接上代码,我的实现过程中,考虑了数据的重复性,考虑到了数据有正有负的情况!
/**
* @author "shihuc"
* @date 2017年1月17日
*/
package bucketSort; import java.io.File;
import java.io.FileNotFoundException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Scanner; /**
* @author shihuc
*
* 桶排序的实现过程,算法中考虑到了元素的重复性
*/
public class BucketSortDemo { /**
* @param args
*/
public static void main(String[] args) {
File file = new File("./src/bucketSort/sample.txt");
Scanner sc = null;
try {
sc = new Scanner(file);
//获取测试例的个数
int T = sc.nextInt();
for(int i=0; i<T; i++){
//获取每个测试例的元素个数
int N = sc.nextInt();
//获取桶的个数
int M = sc.nextInt();
int A[] = new int[N];
for(int j=0; j<N; j++){
A[j] = sc.nextInt();
}
bucketSort(A, M);
printResult(i, A);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} finally {
if(sc != null){
sc.close();
}
}
} /**
* 计算输入元素经过桶的个数(M)求商运算后,存入那个桶中,得到桶的下标索引。
* 步骤1
* 注意:
* 这个方法,其实就是桶排序中的相对核心的部分,也就是常说的待排序数组与桶之间的映射规则f(x)的定义部分。
* 这个映射规则,对于桶排序算法的不同实现版本,规则函数不同。
*
* @param elem 原始输入数组中的元素值
* @param m 桶的商数(影响桶的个数)
* @return 桶的索引号(编号)
*/
private static int getBucketIndex(int elem, int m){
return elem / m;
} private static void bucketSort(int src[], int m){
//定义一个初步排序的桶与原始数据大小的映射关系
HashMap<Integer, ArrayList<Integer>> buckets = new HashMap<Integer, ArrayList<Integer>>(); //规划数据入桶 【步骤2】
programBuckets(src, m, buckets); //对桶基于桶的标号进行排序(序号可能是负数)【步骤3】
Integer bkIdx[] = new Integer[buckets.keySet().size()];
buckets.keySet().toArray(bkIdx);
quickSort(bkIdx, 0, bkIdx.length - 1); //计算每个桶对应于输出数组空间的其实位置
HashMap<Integer, Integer> bucketIdxPosMap = new HashMap<Integer, Integer>();
int startPos = 0;
for(Integer idx: bkIdx){
bucketIdxPosMap.put(idx, startPos);
startPos += buckets.get(idx).size();
} //对桶内的数据采取快速排序,并将排序后的结果映射到原始数组中作为输出
for(Integer bId : buckets.keySet()){
ArrayList<Integer> bk = buckets.get(bId);
Integer[] org = new Integer[bk.size()];
bk.toArray(org);
quickSort(org, 0, bk.size() - 1); //对桶内数据进行排序 【步骤4】
//将排序后的数据映射到原始数组中作为输出 【步骤5】
int stPos = bucketIdxPosMap.get(bId);
for(int i=0; i<org.length; i++){
src[stPos++] = org[i];
}
}
} /**
* 基于原始数据和桶的个数,对数据进行入桶规划。
*
* 这个过程,就体现了divide-and-conquer的思想
*
* @param src
* @param m
* @param buckets
*/
private static void programBuckets(int[] src, int m, HashMap<Integer, ArrayList<Integer>> buckets) {
for(int i=0; i<src.length; i++){
int bucketIdx = getBucketIndex(src[i], m); ArrayList<Integer> bucket = buckets.get(bucketIdx);
if(bucket == null){
//定义桶,用来存放初步划分好的原始数据
bucket = new ArrayList<Integer>();
buckets.put(bucketIdx, bucket);
}
bucket.add(src[i]);
}
} /**
* 采用类似两边夹逼的方式,向输入数组的中间某个位置夹逼,将原输入数组进行分割成两部分,左边的部分全都小于某个值,
* 右边的部分全都大于某个值。
*
* 快排算法的核心部分。
*
* @param src 待排序数组
* @param start 数组的起点索引
* @param end 数组的终点索引
* @return 中值索引
*/
private static int middle(Integer src[], int start, int end){
int middleValue = src[start];
while(start < end){
//找到右半部分都比middleValue大的分界点
while(src[end] >= middleValue && start < end){
end--;
}
//当遇到比middleValue小的时候或者start不再小于end,将比较的起点值替换为新的最小值起点
src[start] = src[end];
//找到左半部分都比middleValue小的分界点
while(src[start] <= middleValue && start < end){
start++;
}
//当遇到比middleValue大的时候或者start不再小于end,将比较的起点值替换为新的终值起点
src[end] = src[start];
}
//当找到了分界点后,将比较的中值进行交换,将中值放在start与end之间的分界点上,完成一次对原数组分解,左边都小于middleValue,右边都大于middleValue
src[start] = middleValue;
return start;
} /**
* 通过递归的方式,对原始输入数组,进行快速排序。
*
* @param src 待排序的数组
* @param st 数组的起点索引
* @param nd 数组的终点索引
*/
public static void quickSort(Integer src[], int st, int nd){ if(st > nd){
return;
}
int middleIdx = middle(src, st, nd);
//将分隔后的数组左边部分进行快排
quickSort(src, st, middleIdx - 1);
//将分隔后的数组右半部分进行快排
quickSort(src, middleIdx + 1, nd);
} /**
* 打印最终的输出结果
*
* @param idx 测试例的编号
* @param B 待输出数组
*/
private static void printResult(int idx, int B[]){
System.out.print(idx + "--> ");
for(int i=0; i<B.length; i++){
System.out.print(B[i] + " ");
}
System.out.println();
}
}
下面附上测试用到的数据:
3
9 2
2 3 1 4 6 -10 8 11 -21
15 5
2 6 3 4 5 10 9 21 17 31 1 2 21 11 18
9 4
2 3 1 4 6 -10 8 11 -21
上面第1行表示有几个测试案例,第二行表示第一个测试案例的熟悉数据,15表示案例元素个数,5表示桶商数(对参与排序的桶的个数有影响)。第3行表示第一个测试案例的待排序数据,第4第5行参照第2和第3行理解。
运行的结果如下:
0--> -21 -10 1 2 3 4 6 8 11
1--> 1 2 2 3 4 5 6 9 10 11 17 18 21 21 31
2--> -21 -10 1 2 3 4 6 8 11
下面附上一个上述测试案例中的一个,通过图示展示算法逻辑
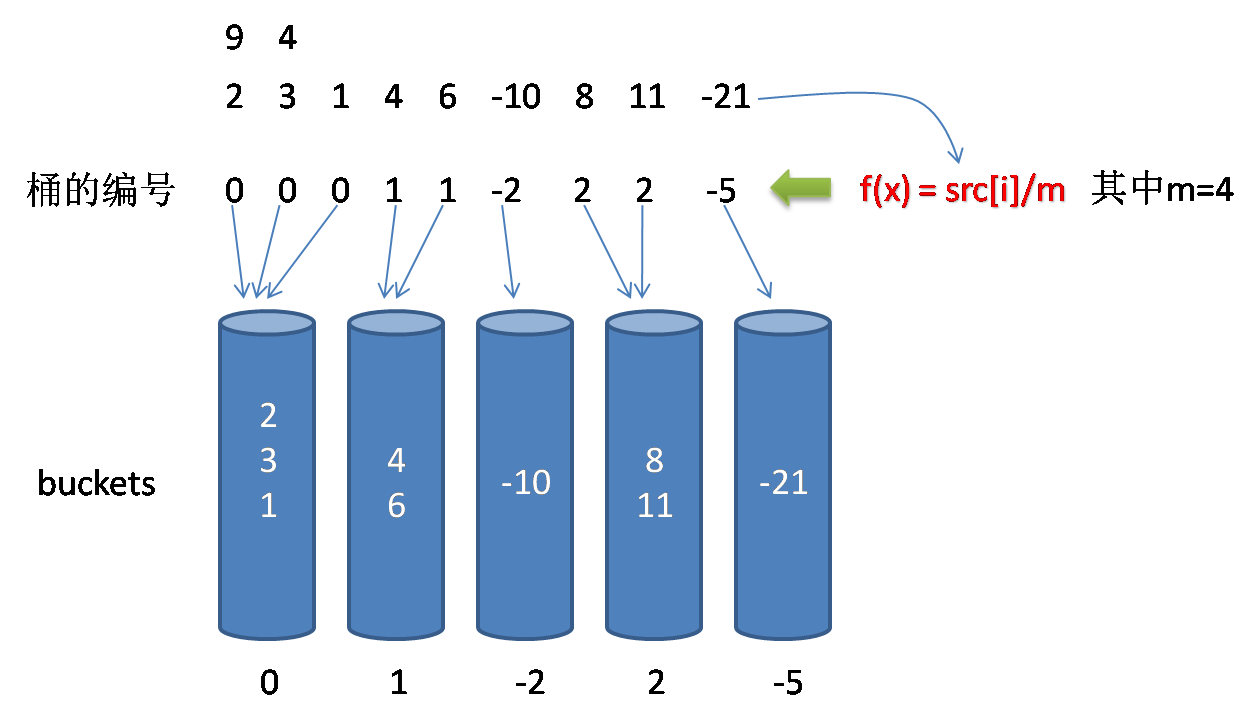
上述算法实现过程中,桶的个数没有直接指定,是有桶的商数决定的。当然,也可以根据实际场景,指定桶的个数,与此同时,算法的实现过程就要做相应的修改,但是整体的思想是没有什么本质差别的。
桶排序,其优势在于处理大数据量的排序场景,数据相对比较集中,这样性能优势很明显。
排序算法<No.3>【桶排序】的更多相关文章
- JavaScript 数据结构与算法之美 - 桶排序、计数排序、基数排序
1. 前言 算法为王. 想学好前端,先练好内功,只有内功深厚者,前端之路才会走得更远. 笔者写的 JavaScript 数据结构与算法之美 系列用的语言是 JavaScript ,旨在入门数据结构与算 ...
- Java常见排序算法之直接选择排序
在学习算法的过程中,我们难免会接触很多和排序相关的算法.总而言之,对于任何编程人员来说,基本的排序算法是必须要掌握的. 从今天开始,我们将要进行基本的排序算法的讲解.Are you ready?Let ...
- Java排序算法之直接选择排序
Java排序算法之直接选择排序 基本过程:假设一序列为R[0]~R[n-1],第一次用R[0]和R[1]~R[n-1]相比较,若小于R[0],则交换至R[0]位置上.第二次从R[1]~R[n-1]中选 ...
- Hark的数据结构与算法练习之桶排序
算法说明 桶排序的逻辑其实特别好理解,它是一种纯粹的分而治之的排序方法. 举个例子简单说一下大家就知道精髓了. 假如对11,4,2,13,22,24,20 进行排序. 那么,我们将4和2放在一起,将1 ...
- 数据结构与算法-排序(十)桶排序(Bucket Sort)
摘要 桶排序和基数排序类似,相当于基数排序的另外一种逻辑.它是将取值范围当做创建桶的数量,桶的长度就是序列的大小.通过处理比较元素的数值,把元素放在桶的特定位置,然后遍历桶,就可以得到有序的序列. 逻 ...
- 八大排序算法之二希尔排序(Shell Sort)
希尔排序是1959 年由D.L.Shell 提出来的,相对直接排序有较大的改进.希尔排序又叫缩小增量排序 基本思想: 先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录 ...
- 基础排序算法之并归排序(Merge Sort)
并归排序是学习分治法 (Merge Sort) 的好例子.而且它相对于选择,插入,冒泡排序来说,算法性能有一定提升.我首先会描述要解决的问题,并给出一个并归排序的例子.之后是算法的思路以及给出伪代码. ...
- Java排序算法(四):Shell排序
[基本的想法] 将原本有大量记录数的记录进行分组.切割成若干个子序列,此时每一个子序列待排序的记录个数就比較少了,然后在这些子序列内分别进行直接插入排序,当整个序列都基本有序时.再对全体记录进行一次直 ...
- 常见的排序算法(直接插入&选择排序&二分查找排序)
1.直接插入排序算法 源码: package com.DiYiZhang;/* 插入排序算法 * 如下进行的是插入,排序算法*/ public class InsertionSort { pub ...
- PHP算法之排序算法(PHP内置排序函数)
首先用实例来讲述一下PHP内置的一些排序函数 [a / k] sort [/ rsort]:[保留索引关系 / 按键名(保留键名关系,适用于关联数组)] 对数组进行排序,结束时数组单元将被从最低到最高 ...
随机推荐
- 5--Selenium环境准备--firefox与geckodriver
selenium2时打开firefox浏览器是不需要安装firefoxdriver的,但是selenium3不支持向前支持火狐浏览器了,40以后版本的火狐,运行会出现问题. 1.下载geckodriv ...
- JAVA_模糊查询_重点是concat关键字
SELECT * FROM user WHERE username LIKE concat('%',#{username},'%') concat : 类似+ ,拼接sql.sql语句中会将+ 重写. ...
- Eclipse远程调试Tomcat
1.Linux服务器中在Tomcat的catalina.sh文件添加如下内容: CATALINA_OPTS="-Xdebug -Xrunjdwp:transport=dt_socket,ad ...
- Spring Boot 揭秘与实战(九) 应用监控篇 - HTTP 应用监控
文章目录 1. 快速开始 2. 监控和管理端点3. 定制端点 2.1. health 应用健康指标 2.2. info 查看应用信息 2.3. metrics 应用基本指标 2.4. trace 基本 ...
- mysql str_to_date 字符串 转日期时间
SELECT STR_TO_DATE('2018-05-05 14:00:00.5555','%Y-%m-%d %H:%i:%s') from DUAL;
- threejs绘制顺序
renderer.sortObjects = false; 然后,scene.add(),就可以先add先画了,否则add的顺序和渲染出来的顺序不一定一致.
- HTML5 canvas 内部元素事件响应
HTML5 canvas 内部元素事件响应 isPointInPath 只能拿当前上下文的路径 重画每个部分 都isPointInPath判断
- HDACM2021(发工资)
发工资咯:) Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Subm ...
- Web安全 概述
转载自 “余弦”大牛的评论 https://www.zhihu.com/question/21606800 大牛的个人blog:http://evilcos.me/ 作者:余弦链接:https://w ...
- fedora的选择
Fedora 首页包含3种版本: 工作站,服务器,ATOMIC 个人只要使用工作站即可,然后,下载界面有另一个选择:Silverblue ========================== Silv ...