Kesci: Keras 实现 LSTM——时间序列预测
博主之前参与的一个科研项目是用 LSTM 结合 Attention 机制依据作物生长期内气象环境因素预测作物产量。本篇博客将介绍如何用 keras 深度学习的框架搭建 LSTM 模型对时间序列做预测。所用项目和数据集来自:真实业界数据的时间序列预测挑战。
1 项目简单介绍
1.1 背景介绍
本项目的目标是建立内部与外部特征结合的多时序协同预测系统。数据集采用来自业界多组相关时间序列(约40组)与外部特征时间序列(约5组)。课题通过进行数据探索,特征工程,传统时序模型探索,机器学习模型探索,深度学习模型探索(RNN,LSTM等),算法结合,结果分析等步骤来学习时序预测问题的分析方法与实战流程。
1.2 数据集说明
** 训练数据有8列:**
- 日期 - 年: int
- 日期 - 月: int
- 日期 - 日: int, 时间跨度为2015年2月1日 - 2016年8月31日
- 当日最高气温 - 摄氏度(下同): float
- 当日最低气温: float
- 当日平均气温: float
- 当日平均湿度: float
- 输出 - float
预测数据没有输出部分,其他与预测一样。时间跨度为2016年9月1日 - 2016年11月30日
训练与预测都各自包含46组数据,每组数据代表不同数据源,组之间的温度与湿度信息一样而输出不同.
2 导入库并读取查看数据
#查看其中一个地区的训练数据
import pandas as pd
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, LSTM, Dropout
import matplotlib.pyplot as plt
% matplotlib inline
import glob, os
import seaborn as sns
import sys
from sklearn.preprocessing import MinMaxScalercolumns = ['YEAR','MONTH','DAY','TEMP_HIG','TEMP_COL','AVG_TEMP','AVG_WET','DATA_COL']
data = pd.read_csv('../input/industry/industry_timeseries/timeseries_train_data/1.csv',
names=columns)
data.head()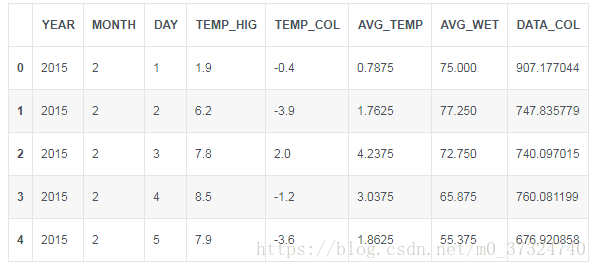
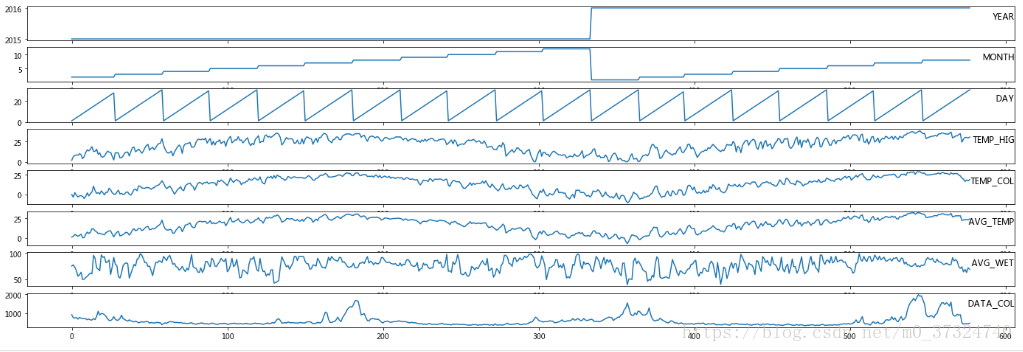
# 查看数据采集区1的数据
plt.figure(figsize=(24,8))
for i in range(8):
plt.subplot(8, 1, i+1)
plt.plot(data.values[:, i])
plt.title(columns[i], y=0.5, loc='right')
plt.show()
3 数据预处理
3.1 时间序列数据转化为监督问题数据
def series_to_supervised(data, n_in=1, n_out=1, dropnan=True):
n_vars = 1 if type(data) is list else data.shape[1]
df = pd.DataFrame(data)
cols, names = list(), list()
# input sequence (t-n, ... t-1)
for i in range(n_in, 0, -1):
cols.append(df.shift(i))
names += [('var%d(t-%d)' % (j+1, i)) for j in range(n_vars)]
# forecast sequence (t, t+1, ... t+n)
for i in range(0, n_out):
cols.append(df.shift(-i))
if i == 0:
names += [('var%d(t)' % (j+1)) for j in range(n_vars)]
else:
names += [('var%d(t+%d)' % (j+1, i)) for j in range(n_vars)]
# put it all together
agg = pd.concat(cols, axis=1)
agg.columns = names
# drop rows with NaN values
if dropnan:
agg.dropna(inplace=True)
return agg关于上段代码的理解可以参考:How to Convert a Time Series to a Supervised Learning Problem in Python
# 将数据归一化到0-1之间,无量纲化
scaler = MinMaxScaler(feature_range=(0,1))
scaled_data = scaler.fit_transform(example[['DATA_COL','TEMP_HIG','TEMP_COL','AVG_TEMP','AVG_WET']].values)
# 将时序数据转换为监督问题数据
reframed = series_to_supervised(scaled_data, 1, 1)
#删除无用的label数据
reframed.drop(reframed.columns[[6,7,8,9]], axis=1, inplace=True)print(redf.info())
redf.head()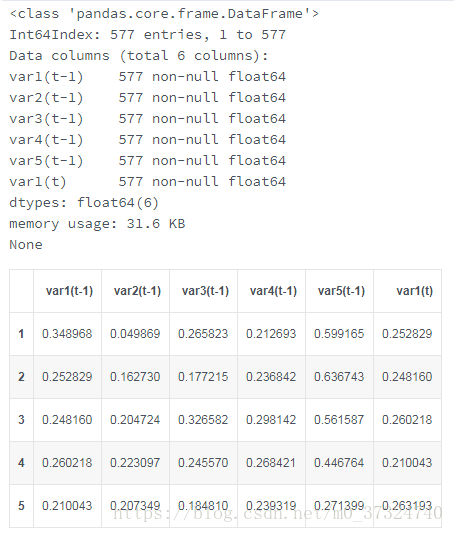
3.2 数据集划分及规整
# 数据集划分,选取前400天的数据作为训练集,中间150天作为验证集,其余的作为测试集
train_days = 400
valid_days = 150
values = redf.values
train = values[:train_days, :]
valid = values[train_days:train_days+valid_days, :]
test = values[train_days+valid_days:, :]
train_X, train_y = train[:, :-1], train[:, -1]
valid_X, valid_y = valid[:, :-1], valid[:, -1]
test_X, test_y = test[:, :-1], test[:, -1]
# 将数据集重构为符合LSTM要求的数据格式,即 [样本,时间步,特征]
train_X = train_X.reshape((train_X.shape[0], 1, train_X.shape[1]))
valid_X = valid_X.reshape((valid_X.shape[0], 1, valid_X.shape[1]))
test_X = test_X.reshape((test_X.shape[0], 1, test_X.shape[1]))
print(train_X.shape, train_y.shape, valid_X.shape, valid_y.shape, test_X.shape, test_y.shape)(400, 1, 5) (400,) (150, 1, 5) (150,) (27, 1, 5) (27,)
4 建立模型并训练
model1 = Sequential()
model1.add(LSTM(50, activation='relu',input_shape=(train_X.shape[1], train_X.shape[2]), return_sequences=True))
model1.add(Dense(1, activation='linear'))
model1.compile(loss='mean_squared_error', optimizer='adam') # fit network
LSTM = model.fit(train_X, train_y, epochs=100, batch_size=32, validation_data=(valid_X, valid_y), verbose=2, shuffle=False)
# plot history
plt.plot(LSTM.LSTM['loss'], label='train')
plt.plot(LSTM.LSTM['val_loss'], label='valid')
plt.legend()
plt.show()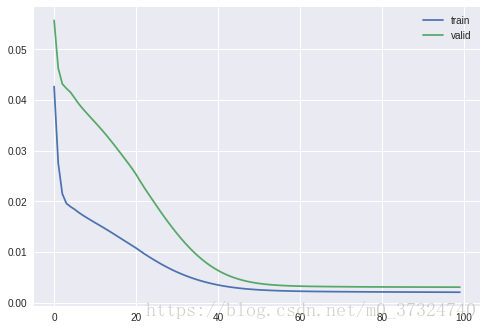
5 模型预测并可视化
plt.figure(figsize=(24,8))
train_predict = model.predict(train_X)
valid_predict = model.predict(valid_X)
test_predict = model.predict(test_X)
plt.plot(values[:, -1], c='b')
plt.plot([x for x in train_predict], c='g')
plt.plot([None for _ in train_predict] + [x for x in valid_predict], c='y')
plt.plot([None for _ in train_predict] + [None for _ in valid_predict] + [x for x in test_predict], c='r')
plt.show()
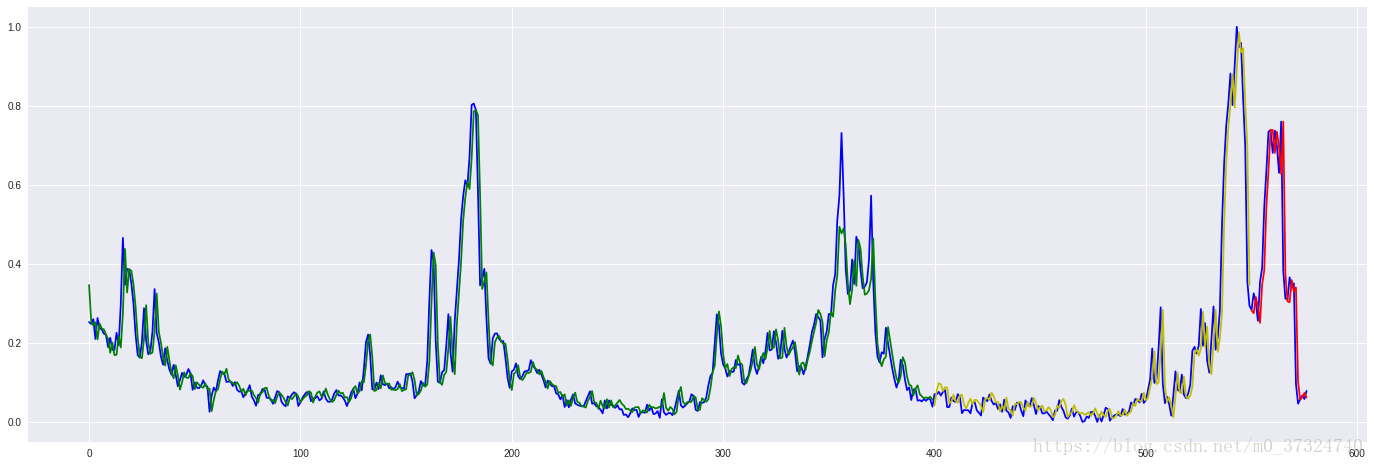
蓝色曲线为真实输出
绿色曲线为训练数据的预测输出
黄色曲线为验证数据集的预测输出
红色曲线为测试数据的预测输出(能看出来模型预测效果还是比较好的)
6 小结
本次只采用了一个地区的数据用来训练模型,在后续的工作中可以增加多任务学习内容。
Kesci: Keras 实现 LSTM——时间序列预测的更多相关文章
- (数据科学学习手札40)tensorflow实现LSTM时间序列预测
一.简介 上一篇中我们较为详细地铺垫了关于RNN及其变种LSTM的一些基本知识,也提到了LSTM在时间序列预测上优越的性能,本篇就将对如何利用tensorflow,在实际时间序列预测任务中搭建模型来完 ...
- Pytorch循环神经网络LSTM时间序列预测风速
#时间序列预测分析就是利用过去一段时间内某事件时间的特征来预测未来一段时间内该事件的特征.这是一类相对比较复杂的预测建模问题,和回归分析模型的预测不同,时间序列模型是依赖于事件发生的先后顺序的,同样大 ...
- LSTM时间序列预测及网络层搭建
一.LSTM预测未来一年某航空公司的客运流量 给你一个数据集,只有一列数据,这是一个关于时间序列的数据,从这个时间序列中预测未来一年某航空公司的客运流量.数据形式: 二.实战 1)数据下载 你可以go ...
- keras-anomaly-detection 代码分析——本质上就是SAE、LSTM时间序列预测
keras-anomaly-detection Anomaly detection implemented in Keras The source codes of the recurrent, co ...
- 使用keras的LSTM进行预测----实战练习
代码 import numpy as np from keras.models import Sequential from keras.layers import Dense from keras. ...
- LSTM时间序列预测学习
一.文件准备工作 下载好的例程序 二.开始运行 1.在程序所在目录中(chapter_15)打开终端 输入下面的指令运行 python train_lstm.py 此时出现了报错提示没有安装mat ...
- 基于 Keras 用 LSTM 网络做时间序列预测
目录 基于 Keras 用 LSTM 网络做时间序列预测 问题描述 长短记忆网络 LSTM 网络回归 LSTM 网络回归结合窗口法 基于时间步的 LSTM 网络回归 在批量训练之间保持 LSTM 的记 ...
- Python中利用LSTM模型进行时间序列预测分析
时间序列模型 时间序列预测分析就是利用过去一段时间内某事件时间的特征来预测未来一段时间内该事件的特征.这是一类相对比较复杂的预测建模问题,和回归分析模型的预测不同,时间序列模型是依赖于事件发生的先后顺 ...
- 使用tensorflow的lstm网络进行时间序列预测
https://blog.csdn.net/flying_sfeng/article/details/78852816 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog. ...
随机推荐
- ORACLE中ESCAPE关键字用法
ESCAPE用法 1.使用 ESCAPE 关键字定义转义符: 在模式中,当转义符置于通配符之前时,该通配符就解释为普通字符. 2.ESCAPE 'escape_character' 允许在字符串中搜 ...
- 2017-5-5/PHP实现负载均衡的加权轮询
1. 负载均衡算法有哪些? 轮询法:将请求按顺序轮流地分配到后端服务器上,它均衡地对待后端的每一台服务器,而不关心服务器实际的连接数和当前的系统负载. 随机法:通过系统的随机算法,根据后端服务器的列表 ...
- Spring注解之@validated的使用
spring-boot中可以用@validated来校验数据,如果数据异常则会统一抛出异常,方便异常中心统一处理.比如,我们判断一个输入参数是否合法,可以用如下方式 一 基础使用 因为spring-b ...
- springboot activiti 配置项详解
asyncExecutorEnabled属性设置设置true后将代替那些老的Job executorspring.activiti.async-executor-enabled=false sprin ...
- HTML相关知识点总结
1.表格<table>常用属性 cellspacing:两个单元格之间的距离 注:属性值为数字,效果图如下(左边cellspacing="0",右边cellspacin ...
- ActiveMQ 中 consumer 的优先级,message 的优先级
http://activemq.apache.org/consumer-priority.htmlconsumer 优先级 http://activemq.apache.org/activemq-me ...
- HDU 1005 Number Sequence(数论)
HDU 1005 Number Sequence(数论) Problem Description: A number sequence is defined as follows:f(1) = 1, ...
- 逆袭之旅.DAY07东软实训..封装~继承~抽象~final
2018年7月3日.逆袭之旅DAY07 package day0703.exam1; /** * 狗狗类 使用权限修饰符private和public进行封装 * @author Administrat ...
- Ubuntu下如何访问Windows磁盘?
有些同学的电脑原来是Windows系统的,但为了需要,又下载了一个Ubuntu系统,变成双系统的电脑. 但是,在Ubuntu下,Windows的磁盘是打不开的,用网盘或者U盘又是很不方便,所以ljn教 ...
- 通过改变unity中物体的alpha值实现若隐若现的效果
RawImage logo = mainLogo.transform.FindChild("back/headBack/Logo").GetComponent<RawImag ...