010 Spark中的监控----日志聚合的配置,以及REST Api
一:History日志聚合的配置
1.介绍
Spark的日志聚合功能不是standalone模式独享的,是所有运行模式下都会存在的情况
默认情况下历史日志是保存到tmp文件夹中的
2.参考官网的知识点位置

3.修改spark-defaults.conf

4.修改env.sh

5.在HDFS上新建/spark-history
bin/hdfs dfs -mkdir /spark-history
6.启动历史服务
sbin/start-history-server.sh

7.测试
webUI: http://192.168.187.146:18080/
local模式:bin/spark-shell
standalone模式:bin/spark-shell --master spark://linux-hadoop3.ibeifeng.com:7070
8.local模式的测试
bin/spark-shell
然后输入程序。
在

9.standalone模式
bin/spark-shell --master spark://linux-hadoop3.ibeifeng.com:7070
输入程序
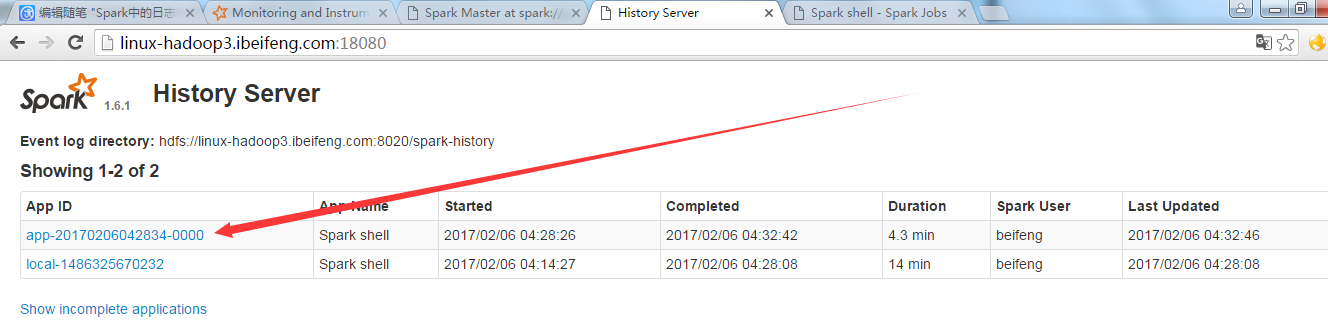
二:RestApi
返回应用程序的执行结果。
1.关于RestApi的官网
也是属于monitor的部分

2.介绍
专门用于获取历史应用的执行结果
用法: http://<server-url>:18080/api/v1
3.使用
http://linux-hadoop3.ibeifeng.com:18080/api/v1/applications

4.进一步使用
http://linux-hadoop3.ibeifeng.com:18080/api/v1/applications/app-20170206042834-0000/jobs

010 Spark中的监控----日志聚合的配置,以及REST Api的更多相关文章
- Spark进阶之路-日志服务器的配置
Spark进阶之路-日志服务器的配置 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 如果你还在纠结如果配置Spark独立模式(Standalone)集群,可以参考我之前分享的笔记: ...
- 024 关于spark中日志分析案例
1.四个需求 需求一:求contentsize的平均值.最小值.最大值 需求二:请各个不同返回值的出现的数据 ===> wordCount程序 需求三:获取访问次数超过N次的IP地址 需求四:获 ...
- SQL Server中的事务日志管理(9/9):监控事务日志
当一切正常时,没有必要特别留意什么是事务日志,它是如何工作的.你只要确保每个数据库都有正确的备份.当出现问题时,事务日志的理解对于采取修正操作是重要的,尤其在需要紧急恢复数据库到指定点时.这系列文章会 ...
- Spark中的编程模型
1. Spark中的基本概念 Application:基于Spark的用户程序,包含了一个driver program和集群中多个executor. Driver Program:运行Applicat ...
- 苏宁基于Spark Streaming的实时日志分析系统实践 Spark Streaming 在数据平台日志解析功能的应用
https://mp.weixin.qq.com/s/KPTM02-ICt72_7ZdRZIHBA 苏宁基于Spark Streaming的实时日志分析系统实践 原创: AI+落地实践 AI前线 20 ...
- SQL Server中的事务日志管理(8/9):优化日志吞吐量
当一切正常时,没有必要特别留意什么是事务日志,它是如何工作的.你只要确保每个数据库都有正确的备份.当出现问题时,事务日志的理解对于采取修正操作是重要的,尤其在需要紧急恢复数据库到指定点时.这系列文章会 ...
- 关于Spark中RDD的设计的一些分析
RDD, Resilient Distributed Dataset,弹性分布式数据集, 是Spark的核心概念. 对于RDD的原理性的知识,可以参阅Resilient Distributed Dat ...
- Spark中的键值对操作-scala
1.PairRDD介绍 Spark为包含键值对类型的RDD提供了一些专有的操作.这些RDD被称为PairRDD.PairRDD提供了并行操作各个键或跨节点重新进行数据分组的操作接口.例如,Pa ...
- Spark中的键值对操作
1.PairRDD介绍 Spark为包含键值对类型的RDD提供了一些专有的操作.这些RDD被称为PairRDD.PairRDD提供了并行操作各个键或跨节点重新进行数据分组的操作接口.例如,Pa ...
随机推荐
- L1比L2更稀疏
1. 简单列子: 一个损失函数L与参数x的关系表示为: 则 加上L2正则化,新的损失函数L为:(蓝线) 最优点在黄点处,x的绝对值减少了,但依然非零. 如果加上L1正则化,新的损失函数L为:(粉线) ...
- luogu P4778 Counting swaps
计数套路题?但是我连套路都不会,,, 拿到这道题我一脸蒙彼,,,感谢@poorpool 大佬的博客的指点 先将第\(i\)位上的数字\(p_i\)向\(i\)连无向边,然后构成了一个有若干环组成的无向 ...
- 第18月第16天 statusBar
1. 我们都知道要改状态栏statusBar的颜色很简单,只要如下一行代码就可以, [[UIApplicationsharedApplication]setStatusBarStyle:UIStatu ...
- vue pc端网站项目开发坑点与难度记录
背景 在一pc端的web项目里,由于某些特性需要由动态语言处理,所以只在有需要使用vue来处理数据的页面,直接引入vue.js来处理.由于刚开始并没有打算使用前端来渲染数据和处理交互,所以使用了一些非 ...
- mysql 显示表字段及mysql系统信息
参考链接: http://www.cnblogs.com/zhwl/archive/2012/08/28/2660532.html SHOW DATABASES ...
- 修改weblogic的端口
两种方法可以修改,第一种方法是后台管理界面修改,第二种是配置文件修改,下面分别介绍: 1.后台修改 (1)进入weblogic登陆界面:(默认端口是7001) (2)登陆之后点击服务器----然后管理 ...
- win7防火墙端口开放
https://jingyan.baidu.com/article/f96699bbadafca894f3c1b7a.html
- 【网络编程3】网络编程基础-arp请求(局域网主机扫描)
ARP协议 ARP(Add ress Resolution Protocol)地址解析协议位于数据链路层,是根据IP地址获取MAC地址的一个协议. ARP 查看指令 arp -a 显示所有接口的当前A ...
- Linux动态频率调节系统CPUFreq之一:概述【转】-- 非常好的博客
转自:http://blog.csdn.net/droidphone/article/details/9346981 目录(?)[-] sysfs接口 软件架构 cpufreq_policy ...
- springboot系列十二、springboot集成RestTemplate及常见用法
一.背景介绍 在微服务都是以HTTP接口的形式暴露自身服务的,因此在调用远程服务时就必须使用HTTP客户端.我们可以使用JDK原生的URLConnection.Apache的Http Client.N ...