Depth-first search and Breadth-first search 深度优先搜索和广度优先搜索
Depth-first search
Depth-first search (DFS) is an algorithm for traversing or searching tree or graph data structures.
The algorithm starts at the root node (selecting some arbitrary node as the root node in the case of a graph) and explores as far as possible along each branch before backtracking 回溯.
For the following graph:
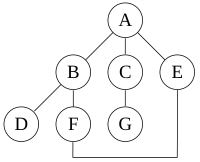
a depth-first search starting at A,
assuming that the left edges in the shown graph are chosen before right edges,
and assuming the search remembers previously visited nodes and will not repeat them (since this is a small graph),
will visit the nodes in the following order: A, B, D, F, E, C, G.
The edges traversed in this search form a Trémaux tree, a structure with important applications in graph theory.
Performing the same search without remembering previously visited nodes results in visiting nodes in the order A, B, D, F, E, A, B, D, F, E, etc. forever, caught in the A, B, D, F, E cycle and never reaching C or G.
Iterative deepening is one technique to avoid this infinite loop and would reach all nodes.
深度优先的算法实现
Input: A graph G and a vertex v of G
Output: All vertices reachable from v labeled as discovered
A recursive implementation of DFS:[5]
1 procedure DFS(G,v):
2 label v as discovered
3 for all edges from v to w in G.adjacentEdges(v) do
4 if vertex w is not labeled as discovered then
5 recursively call DFS(G,w)
The order in which the vertices are discovered by this algorithm is called the lexicographic order.
A non-recursive implementation of DFS with worst-case space complexity O(|E|):[6] (使用栈,先进后出)
1 procedure DFS-iterative(G,v):
2 let S be a stack
3 S.push(v)
4 while S is not empty
5 v = S.pop()
6 if v is not labeled as discovered:
7 label v as discovered
8 for all edges from v to w in G.adjacentEdges(v) do
9 S.push(w)
These two variations of DFS visit the neighbors of each vertex in the opposite order from each other: the first neighbor of v visited by the recursive variation is the first one in the list of adjacent edges, while in the iterative variation the first visited neighbor is the last one in the list of adjacent edges. The recursive implementation will visit the nodes from the example graph in the following order: A, B, D, F, E, C, G. The non-recursive implementation will visit the nodes as: A, E, F, B, D, C, G.
The non-recursive implementation is similar to breadth-first search but differs from it in two ways:
- it uses a stack instead of a queue, and
- it delays checking whether a vertex has been discovered until the vertex is popped from the stack rather than making this check before adding the vertex.
Breadth-first search
Breadth-first search (BFS) is an algorithm for traversing or searching tree or graph data structures.
It starts at the tree root (or some arbitrary node of a graph, sometimes referred to as a 'search key'[1]), and explores all of the neighbor nodes at the present depth prior to moving on to the nodes at the next depth level.
It uses the opposite strategy as depth-first search, which instead explores the highest-depth nodes first before being forced to backtrack回溯 and expand shallower nodes.
shallower是shallow的比较级,较浅的
广度优先的实现 (使用队列,先进先出)
Input: A graph Graph and a starting vertex顶点 root of Graph
Output: Goal state. The parent links trace the shortest path back to root
1 procedure BFS(G,start_v):
2 let S be a queue
3 S.enqueue(start_v)
4 while S is not empty
5 v = S.dequeue()
6 if v is the goal:
7 return v
8 for all edges from v to w in G.adjacentEdges(v) do
9 if w is not labeled as discovered:
10 label w as discovered
11 w.parent = v
12 S.enqueue(w)
More details
This non-recursive implementation is similar to the non-recursive implementation of depth-first search, but differs from it in two ways:
- it uses a queue (First In First Out) instead of a stack and
- it checks whether a vertex顶点 has been discovered before enqueueing the vertex rather than delaying this check until the vertex is dequeued from the queue.
The Q queue contains the frontier along which the algorithm is currently searching.
Nodes can be labelled as discovered by storing them in a set, or by an attribute on each node, depending on the implementation.
Note that the word node is usually interchangeable with the word vertex.
The parent attribute of each vertex is useful for accessing the nodes in a shortest path, for example by backtracking from the destination node up to the starting node, once the BFS has been run, and the predecessors nodes have been set.
Breadth-first search produces a so-called breadth first tree. You can see how a breadth first tree looks in the following example.
Depth-first search and Breadth-first search 深度优先搜索和广度优先搜索的更多相关文章
- DFS_BFS(深度优先搜索 和 广度优先搜索)
package com.rao.graph; import java.util.LinkedList; /** * @author Srao * @className BFS_DFS * @date ...
- 【Python排序搜索基本算法】之深度优先搜索、广度优先搜索、拓扑排序、强联通&Kosaraju算法
Graph Search and Connectivity Generic Graph Search Goals 1. find everything findable 2. don't explor ...
- 【js数据结构】图的深度优先搜索与广度优先搜索
图类的构建 function Graph(v) {this.vertices = v;this.edges = 0;this.adj = []; for (var i = 0; i < this ...
- DFS或BFS(深度优先搜索或广度优先搜索遍历无向图)-04-无向图-岛屿数量
给定一个由 '1'(陆地)和 '0'(水)组成的的二维网格,计算岛屿的数量.一个岛被水包围,并且它是通过水平方向或垂直方向上相邻的陆地连接而成的.你可以假设网格的四个边均被水包围. 示例 1: 输入: ...
- 深度优先搜索DFS和广度优先搜索BFS简单解析(新手向)
深度优先搜索DFS和广度优先搜索BFS简单解析 与树的遍历类似,图的遍历要求从某一点出发,每个点仅被访问一次,这个过程就是图的遍历.图的遍历常用的有深度优先搜索和广度优先搜索,这两者对于有向图和无向图 ...
- 深度优先搜索(DFS)和广度优先搜索(BFS)
深度优先搜索(DFS) 广度优先搜索(BFS) 1.介绍 广度优先搜索(BFS)是图的另一种遍历方式,与DFS相对,是以广度优先进行搜索.简言之就是先访问图的顶点,然后广度优先访问其邻接点,然后再依次 ...
- 深度优先搜索DFS和广度优先搜索BFS简单解析
转自:https://www.cnblogs.com/FZfangzheng/p/8529132.html 深度优先搜索DFS和广度优先搜索BFS简单解析 与树的遍历类似,图的遍历要求从某一点出发,每 ...
- Unity中通过深度优先算法和广度优先算法打印游戏物体名
前言:又是一个月没写博客了,每次下班都懒得写,觉得浪费时间.... 深度优先搜索和广度优先搜索的定义,网络上已经说的很清楚了,我也是看了网上的才懂的,所以就不在这里赘述了.今天讲解的实例,主要是通过自 ...
- 广度优先搜索(Breadth First Search, BFS)
广度优先搜索(Breadth First Search, BFS) BFS算法实现的一般思路为: // BFS void BFS(int s){ queue<int> q; // 定义一个 ...
随机推荐
- GDTR与LDTR
----段寄存器 一.访问GDT 当TI=0时表示段描述符在GDT中,如上图所示: 段描述符(64位) ①先从GDTR寄存器(48位,其中前32位base+16位长度)中获得GDT基址. ②然后再GD ...
- 《大话设计模式》c++实现 之工厂模式
工厂模式 工厂模式(Factory Pattern)是 Java 中最常用的设计模式之一.这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式. 在工厂模式中,我们在创建对象时不会对客户端 ...
- Sitecore 8.1 - 特性和功能
营销基础 一个新的Sitecore品牌术语取代了体验营销(以前的Sitecore DMS),这是Sitecore体验数据库(xDB)现在所在的位置. Sitecore 7.5和Sitecore 8.0 ...
- sql privot 实现行转列
表结构如下: RefID HRMS Name InsuranceMoney InsuranceNamefb2bdee8-e4c9-4470-8e7f-14550d3212f7 ...
- android Observable api请求参数设置注解问题
android Observable api请求参数设置注解问题 2018-10-29 20:05:24.919 11786-11786/xxx E/wxh: getQuote=USD getBase ...
- 大数据自学5-Python操作Hbase
在Hue环境中本身是可以直接操作Hbase数据库的,但是公司的环境不知道什么原因一直提示"Api Error:timed out",进度条一直在跑,却显示不出表. 但是在CDH后台 ...
- java中的关键字、保留字、标识符
Java关键字(KeyWord): 对Java的编译器有特殊的意义,他们用来表示一种数据类型或者表示程序的结构. Java保留字(Reserved Word):为Java预留的关键字,现在还没有用到 ...
- Linux下php添加memcache扩展
很多时候我们都会遇到在已经安装的php中添加其它的扩展. 那我们应该怎么做呢? 这样做.(我们的nginx和php都是已经安装好了的,这里就不做赘述了) 首先,我们需要下载php的memcache扩展 ...
- django自定义错误响应
在做一个web时,总是会出现各种错误,如400.403.404.500等.一般开发都要做对应的处理,给一些友好提示,或返回一些公益广告等. 在Django中,默认提供了常见的错误处理方式,比如: ha ...
- close yield
close的方法主要是关闭子生成器,需要注意的有4点: 1.如果生成器close后,还继续next,会报错StopIteration [图片] 2.如果我捕获了异常,将GeneratorE ...