深入详解美团点评CAT跨语言服务监控(六)消息分析器与报表(一)
大众点评CAT微服务监控架构对于消息的具体处理,是由消息分析器完成的,消息分析器会轮训读取PeriodTask中队列的消息来处理,一共有12类消息分析器,处理后的结果就是生成各类报表。
消息分析器的构建
在周期Period构造函数中,我们会通过m_analyzerManager.getAnalyzer(name, startTime)获取分析器(MessageAnalyzer)列表。getAnalyzer函数源码如下,首先会清理2小时之前的分析器,然后从m_analyzers中获取分析器(MessageAnalyzer),我们先来看看m_analyzers 的结构
Map<Long, Map<String, List<MessageAnalyzer>>>
最外层Map的key的类型为long,代表由startTime对应的周期。value还是一个Map,Map的key类型是String,是分析器的名字,代表一类分析器,value是MessageAnalyzer列表,同一类分析器,至少有一个MessageAnalyzer实例,对于复杂耗时的分析任务,我们通常会开启更多的实例处理。
如果在Map中没有找到我们需要的分析器,我们就创建,创建的过程函数会通过synchronized给map上锁,以保证创建过程map同时只能被一个线程访问,保证了线程安全。
分析器创建之后会被初始化,然后放入m_analyzers中,
public class DefaultMessageAnalyzerManager extends ContainerHolder implements MessageAnalyzerManager, Initializable,LogEnabled {
private Map<Long, Map<String, List<MessageAnalyzer>>> m_analyzers = new HashMap<Long, Map<String, List<MessageAnalyzer>>>();
@Override
public List<MessageAnalyzer> getAnalyzer(String name, long startTime) {
// remove last two hour analyzer
Map<String, List<MessageAnalyzer>> temp = m_analyzers.remove(startTime - m_duration * 2);
...
Map<String, List<MessageAnalyzer>> map = m_analyzers.get(startTime);
if (map == null) {
synchronized (m_analyzers) {
map = m_analyzers.get(startTime);
if (map == null) {
map = new HashMap<String, List<MessageAnalyzer>>();
m_analyzers.put(startTime, map);
}
}
}
List<MessageAnalyzer> analyzers = map.get(name);
if (analyzers == null) {
synchronized (map) {
analyzers = map.get(name);
if (analyzers == null) {
analyzers = new ArrayList<MessageAnalyzer>();
MessageAnalyzer analyzer = lookup(MessageAnalyzer.class, name);
analyzer.setIndex(0);
analyzer.initialize(startTime, m_duration, m_extraTime);
analyzers.add(analyzer);
int count = analyzer.getAnalyzerCount();
for (int i = 1; i < count; i++) {
MessageAnalyzer tempAnalyzer = lookup(MessageAnalyzer.class, name);
tempAnalyzer.setIndex(i);
tempAnalyzer.initialize(startTime, m_duration, m_extraTime);
analyzers.add(tempAnalyzer);
}
map.put(name, analyzers);
}
}
}
return analyzers;
}
}
我们再来看看分析器的大体结构

每个分析器都包含有多个报表,报表交由报表管理器(ReportManage)管理,报表在报表管理器中存储结构如下:
Map<Long, Map<String, T>> m_reports
最外层是个Map, key 为long类型,代表的是当前时间周期的报表,value还是一个Map,key类型为String,代表的是不同的domain,一个domain可以理解为一个 Project,value是不同report对象,在分析器处理报表的时候,我们会通过周期管理器(DefaultReportManage)的getHourlyReport方法根据周期时间和domain获取对应的Report。
分析器分析上报的消息之后,生成相应的报表存于Report对象中,报表实体类XxxReport的结构都是由上一章讲的代码自动生成器生成的,配置位于 cat-sonsumer/src/main/resources/META-INFO/dal/model/*.xml 中。
TopAnalyzer
TopAnalyzer分析生成每个周期的报表,不区分domain,所有domain的数据都会汇总到所在周期的domain='cat'的这个报表下去:
getHourlyReport(getStartTime(), Constants.CAT, true);
TopAnalyzer会处理指定Type类型的Event消息,具体有哪些类型会被处理会在 plexus/components-cat-consumer.xml 文件中配置。如下
<implementation>com.dianping.cat.consumer.top.TopAnalyzer</implementation>
<instantiation-strategy>per-lookup</instantiation-strategy>
<configuration>
<errorType>Error,RuntimeException,Exception</errorType>
</configuration>
再来看看TopAnalyzer对Event的处理过程,他会统计当前小时周期内上面类型消息的3个计数。
1、当前小时周期内每分钟,每个domain,也就是每个project的错误计数
2、每个名字对应的错误计数
3、每个IP对应的错误计数
public class TopAnalyzer extends AbstractMessageAnalyzer<TopReport> implements LogEnabled {
private void processEvent(TopReport report, MessageTree tree, Event event) {
String type = event.getType();
if (m_errorTypes.contains(type)) {
String domain = tree.getDomain();
String ip = tree.getIpAddress();
String exception = event.getName();
long current = event.getTimestamp() / 1000 / 60;
int min = (int) (current % (60));
Segment segment = report.findOrCreateDomain(domain).findOrCreateSegment(min).incError();
segment.findOrCreateError(exception).incCount();
segment.findOrCreateMachine(ip).incCount();
}
}
}
EventAnalyzer - 事件发生次数分析

时间分析分析报表会记录Event类型消息的统计汇总信息,每个周期时间,每个domain对应一个EventReport,每个Event报表包含多个Machine对象,按IP区分,注意一下这里的Machine类与后面其它报表的Machine类是有区别的,相同IP下不同类型(Type)的Event信息存在于不同的EventType对象中,EventType记录了该类型消息的总数,失败总数,失败百分比,成功的MessageID,失败的MessageID,tps,以及该类型下各种命名消息。
同一类型但是不同名字(Name)的Event信息存在于不同的EventName对象中,他也会记录该命名消息的总数,失败总数,失败百分比,成功的MessageID,失败的MessageID,tps。
每个EventName对象会存储当前周期时间内,不同类型不同名字的Event消息每分钟的消息总数和失败总数,放在m_ranges字段中。
大家可能疑惑为什么存的成功与失败的MessageID只有一个,而不是一个列表,因为Event报表仅仅只是统计一类事件发生的次数,同类消息做的事情本质上是一样的,所以仅取一条MessageID对应的消息树作为这一类消息的代表。
public class EventAnalyzer extends AbstractMessageAnalyzer<EventReport> implements LogEnabled {
private void processEvent(EventReport report, MessageTree tree, Event event, String ip) {
int count = 1;
EventType type = report.findOrCreateMachine(ip).findOrCreateType(event.getType());
EventName name = type.findOrCreateName(event.getName());
String messageId = tree.getMessageId();
report.addIp(tree.getIpAddress());
type.incTotalCount(count);
name.incTotalCount(count);
if (event.isSuccess()) {
type.setSuccessMessageUrl(messageId);
name.setSuccessMessageUrl(messageId);
} else {
type.incFailCount(count);
name.incFailCount(count);
type.setFailMessageUrl(messageId);
name.setFailMessageUrl(messageId);
}
type.setFailPercent(type.getFailCount() * 100.0 / type.getTotalCount());
name.setFailPercent(name.getFailCount() * 100.0 / name.getTotalCount());
processEventGrpah(name, event, count);
}
private void processEventGrpah(EventName name, Event t, int count) {
long current = t.getTimestamp() / 1000 / 60;
int min = (int) (current % (60));
Range range = name.findOrCreateRange(min);
range.incCount(count);
if (!t.isSuccess()) {
range.incFails(count);
}
}
}
MetricAnalyzer - 业务分析
Metric主要监控业务系统,业务指标,在讲Metric业务报表之前,我们首先讲一下产品线的概念,先看下面类图:

metricProductLine-业务监控是需要配置产品线的,产品线可以认为是一系列project的集合,我们之前说过,每个domain可以认为是一个project,所以产品线也可以认为由多个domain组成,metric产品线的配置文件为 metricProductLine.xml,默认配置如下,最外面是一个company,company下面可以有多条产品线,每条产品线下面又有多个domain。
<?xml version="1.0" encoding="utf-8"?>
<company>
<product-line id="Platform" order="10.0" title="架构" >
<domain id="Cat"/>
<domain id="PumaServer"/>
<domain id="SessionService"/>
</product-line>
</company>
每个domain对应哪条产品线是由产品线配置管理类(ProductLineConfigManager)维护的,产品线配置管理类通过一个Map存储domain id 与 product-line id的映射关系,这些映射关系在产品线配置管理类初始化的时候被创建,通过buildMetricProductLines函数。
除此之外,在初始化函数中,ProductLineConfigManager类还会根据配置初始化ProductLineConfig中指定的其它6中监控类型的产品线,分别是userProductLine-外部监控,applicationProductLine-应用监控,networkProductLine-网络监控,systemProductLine-系统监控,databaseProductLine-数据库监控,cdnProductLine-CDN监控,我们可以在上一章的配置列表中找到这些监控类别的配置。
public class ProductLineConfigManager implements Initializable, LogEnabled {
private volatile Map<String, String> m_metricProductLines = new HashMap<String, String>();
private Map<String, String> buildMetricProductLines() {
Map<String, String> domainToProductLines = new HashMap<String, String>();
for (ProductLine product : ProductLineConfig.METRIC.getCompany().getProductLines().values()) {
for (Domain domain : product.getDomains().values()) {
domainToProductLines.put(domain.getId(), product.getId());
}
}
return domainToProductLines;
}
@Override
public void initialize() throws InitializationException {
for (ProductLineConfig productLine : ProductLineConfig.values()) {
initializeConfig(productLine);
}
m_metricProductLines = buildMetricProductLines();
}
}
接下来我们看看MetricAnalyzer做了什么事情,他会根据domain获取消息所属的产品线,然后生成对应的业务报表(MetricReport) ,也就是说,一条产品线对应一个业务报表,一个业务报表,一共包含3个维度的统计,总条数、总额度、平均数,我们来看一个客户端的案例。
MessageProducer cat = Cat.getProducer();
Transaction t = cat.newTransaction("URL", "WebPage"); cat.logMetric("payCount", "C", "1");
cat.logMetric("totalfee", "S", "30.5");
cat.logMetric("avgfee", "T", "25.6");
cat.logMetric("order", "S,C", "3,25.6"); Metric event = Cat.getProducer().newMetric("kingsoft", "praise");
event.setStatus("C");
event.addData("3");
event.complete(); ...
status = "C" 表示总条数, 默认加1, "S"表示总额度,"T"表示平均数,"S,C"表示总条数+总金额,logMetric函数的第一个参数 payCount/totalfee/avgfee/order 都是表示的业务名,大家可以看到这里并没有上报type类型,实际上type表示的就是统计到哪条产品线下面,但是我们cat客户端默认会上送domain字段,MetricAnalyzer可以通过根据domain找到对应的产品线,生成相应报表。
然而,我们也可以通过添加type类型对指定产品线做统计,比如案例中的 newMetric("kingsoft", "praise") 调用,我们就指定向 kingsoft 产品线统计,这时候MetricAnalyzer会调用 insertIfNotExsit 函数匹配所有监控类型的 product-line和domain,找到与客户端上报的type、domain匹配的产品线。找到则返回,没有找到的话,会为此新建一条产品线,放入到Metric监控类型中,并更新到数据库。然后为新的产品线创建一个report报表。
public class MetricAnalyzer extends AbstractMessageAnalyzer<MetricReport> implements LogEnabled {
private int processMetric(MetricReport report, MessageTree tree, Metric metric) {
String group = metric.getType();
String metricName = metric.getName();
String domain = tree.getDomain();
String data = (String) metric.getData();
String status = metric.getStatus();
ConfigItem config = parseValue(status, data);
if (StringUtils.isNotEmpty(group)) {
boolean result = m_productLineConfigManager.insertIfNotExsit(group, domain);
if (!result) {
m_logger.error(String.format("error when insert product line info, productline %s, domain %s", group,
domain));
}
report = findOrCreateReport(group);
}
if (config != null && report != null) {
...
}
return 0;
}
private ConfigItem parseValue(String status, String data) {
ConfigItem config = new ConfigItem();
if ("C".equals(status)) {
...
} else if ("T".equals(status)) {
...
} else if ("S".equals(status)) {
...
} else if ("S,C".equals(status)) {
...
} else {
return null;
}
return config;
}
}
接下来我们看下具体报表统计逻辑。
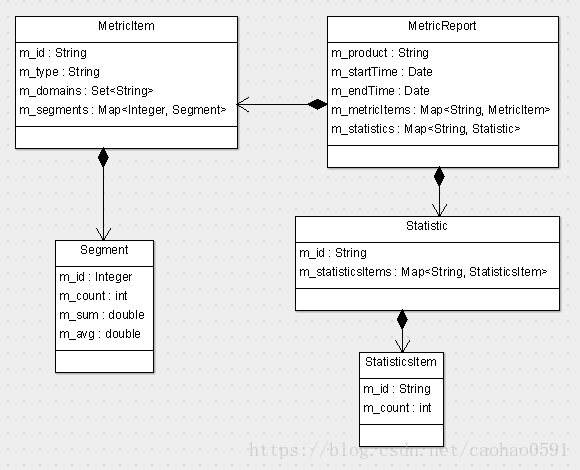
我们知道,每个Metric报表都是一条产品线数据的集合,具体的统计信息记录在 MetricItem 中,domain+METRIC+metricName 用以唯一标识一个MetricItem,MetricItem 的 m_type 字段用于区别统计的维度,所以,我们可以推出, 同一个 domain+metricName 只能用于统计一个维度的数据,Metric报表统计的最小粒度是分钟,MetricItem下每个Segment存储的是每分钟的统计信息。
public class MetricAnalyzer extends AbstractMessageAnalyzer<MetricReport> implements LogEnabled {
private int processMetric(MetricReport report, MessageTree tree, Metric metric) {
...
ConfigItem config = parseValue(status, data);
...
if (config != null && report != null) {
long current = metric.getTimestamp() / 1000 / 60;
int min = (int) (current % (60));
String key = m_configManager.buildMetricKey(domain, METRIC, metricName);
MetricItem metricItem = report.findOrCreateMetricItem(key);
metricItem.addDomain(domain).setType(status);
updateMetric(metricItem, min, config.getCount(), config.getValue());
config.setTitle(metricName);
ProductLineConfig productLineConfig = m_productLineConfigManager.queryProductLine(report.getProduct());
if (ProductLineConfig.METRIC.equals(productLineConfig)) {
boolean result = m_configManager.insertMetricIfNotExist(domain, METRIC, metricName, config);
...
}
}
return 0;
}
private void updateMetric(MetricItem metricItem, int minute, int count, double sum) {
Segment seg = metricItem.findOrCreateSegment(minute);
seg.setCount(seg.getCount() + count);
seg.setSum(seg.getSum() + sum);
seg.setAvg(seg.getSum() / seg.getCount());
}
}
报表展示配置
统计完成之后, 我们会利用ConfigItem对象为Metric报表首次初始化展示配置,并更新到数据库config表。
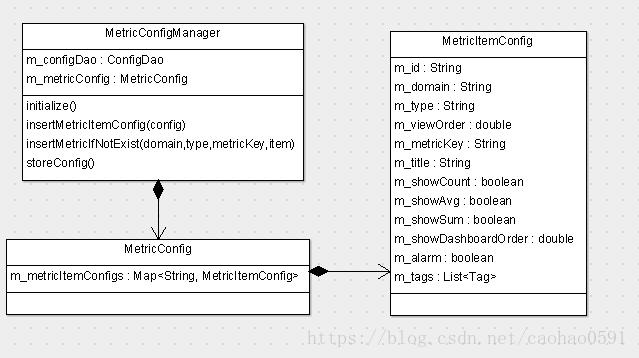
public class MetricConfigManager implements Initializable, LogEnabled {
private volatile MetricConfig m_metricConfig;
public boolean insertMetricIfNotExist(String domain, String type, String metricKey, ConfigItem item) {
String key = buildMetricKey(domain, type, metricKey);
MetricItemConfig config = m_metricConfig.findMetricItemConfig(key);
if (config != null) {
return true;
} else {
config = new MetricItemConfig();
config.setId(key);
config.setDomain(domain);
config.setType(type);
config.setMetricKey(metricKey);
config.setTitle(item.getTitle());
config.setShowAvg(item.isShowAvg());
config.setShowCount(item.isShowCount());
config.setShowSum(item.isShowSum());
m_logger.info("insert metric config info " + config.toString());
return insertMetricItemConfig(config);
}
}
}
ProblemAnalyzer -异常分析
Problem记录整个项目在运行过程中出现的问题,包括一些错误、访问较长的行为。

Problem分析器会通过报表管理器(ReportManager)根据时间和domain,获取对应报表,然后根据IP,找到相应的machine对象,将machine和消息交给问题处理器(ProblemHandler)处理,注意这里的Machine和前面其它报表的Machine不是同一个类。
public class ProblemAnalyzer extends AbstractMessageAnalyzer<ProblemReport> implements LogEnabled, Initializable {
public static final String ID = "problem";
@Inject(ID)
private ReportManager<ProblemReport> m_reportManager;
@Inject
private List<ProblemHandler> m_handlers;
@Override
public void process(MessageTree tree) {
String domain = tree.getDomain();
ProblemReport report = m_reportManager.getHourlyReport(getStartTime(), domain, true);
report.addIp(tree.getIpAddress());
Machine machine = report.findOrCreateMachine(tree.getIpAddress());
for (ProblemHandler handler : m_handlers) {
handler.handle(machine, tree);
}
}
}
CAT默认有DefaultProblemHandler和LongExecutionProblemHandler两个问题处理器,我们可以也定义自己的问题处理器,用于收集我们感兴趣的问题,只需要我们的问题处理器继承自ProblemHandler,并且重写了handle方法,然后在components-cat-consumer.xml中相关模块配置了即可,如下:
<component>
<role>com.dianping.cat.analysis.MessageAnalyzer</role>
<role-hint>problem</role-hint>
<implementation>com.dianping.cat.consumer.problem.ProblemAnalyzer</implementation>
<instantiation-strategy>per-lookup</instantiation-strategy>
<requirements>
...
<requirement>
<role>com.dianping.cat.consumer.problem.ProblemHandler</role>
<field-name>m_handlers</field-name>
<role-hints>
<role-hint>default-problem</role-hint>
<role-hint>long-execution</role-hint>
</role-hints>
</requirement>
</requirements>
</component>
我们先来看看DefaultProblemHandler,他主要用于收集3类Problem,
1、状态不为SUCCESS的事务消息
2、components-cat-consumer.xml中指定errorType类型的Event消息,如下Error、RuntimeException、Exception三种类型消息。
3、heartbeat异常。
<component>
<role>com.dianping.cat.consumer.problem.ProblemHandler</role>
<role-hint>default-problem</role-hint>
<implementation>com.dianping.cat.consumer.problem.DefaultProblemHandler</implementation>
<configuration>
<errorType>Error,RuntimeException,Exception</errorType>
</configuration>
...
</component>
接下来我们看下DefaultProblemHandler处理之后生成的Problem报表的组成结构。

不同IP的Problem消息存储于不同的Machine里面,而且我们还会为不同消息类型、消息名称创建相应的Entity存储消息信息,在Entity中,问题以两种方式存储:
一种是按duration存储,这里的duration指事务执行时间所在的阈值,不过DefaultProblemHandler并不关心duration的不同,所以这里duration全部等于0,我们会在超时调用处理器(LongExecutionProblemHandler)中去做讲解。
另外一种是按线程组来存储,线程组内的消息统计最小粒度为分钟,每个分钟数据统计在Segment中,不管是哪种方式,我们存储的都只是消息树的message_id,而且存储的消息总数有限制,默认每分钟最多只能存储60条消息。
public abstract class ProblemHandler {
public static final int MAX_LOG_SIZE = 60;
public void updateEntity(MessageTree tree, Entity entity, int value) {
Duration duration = entity.findOrCreateDuration(value);
List<String> messages = duration.getMessages();
duration.incCount();
if (messages.size() < MAX_LOG_SIZE) {
messages.add(tree.getMessageId());
}
// make problem thread id = thread group name, make report small
JavaThread thread = entity.findOrCreateThread(tree.getThreadGroupName());
if (thread.getGroupName() == null) {
thread.setGroupName(tree.getThreadGroupName());
}
if (thread.getName() == null) {
thread.setName(tree.getThreadName());
}
Segment segment = thread.findOrCreateSegment(getSegmentByMessage(tree));
List<String> segmentMessages = segment.getMessages();
segment.incCount();
if (segmentMessages.size() < MAX_LOG_SIZE) {
segmentMessages.add(tree.getMessageId());
}
}
}
LongExecutionProblemHandler
超时调用处理器(LongExecutionProblemHandler)用于监控系统中用时比较长的调用,可以是缓存调用、数据库查询,也可以是一次RPC调用、微服务请求、还可以是一次HTTP请求。超时调用处理器分析的对象仅仅是 Transaction事务类型消息。
public class LongExecutionProblemHandler extends ProblemHandler implements Initializable {
private void processTransaction(Machine machine, Transaction transaction, MessageTree tree) {
String type = transaction.getType();
if (type.startsWith("Cache.")) {
processLongCache(machine, transaction, tree);
} else if (type.equals("SQL")) {
processLongSql(machine, transaction, tree);
} else if (m_configManager.isRpcClient(type)) {
processLongCall(machine, transaction, tree);
} else if (m_configManager.isRpcServer(type)) {
processLongService(machine, transaction, tree);
} else if ("URL".equals(type)) {
processLongUrl(machine, transaction, tree);
}
List<Message> messageList = transaction.getChildren();
for (Message message : messageList) {
if (message instanceof Transaction) {
processTransaction(machine, (Transaction) message, tree);
}
}
}
}
超时调用处理器(LongExecutionProblemHandler)会计算事务执行时间,首先查看是否超过了默认阈值设置,每种调用的阈值设置都不同,分4-6个级别,如下,
m_defaultLongServiceDuration = { 50, 100, 500, 1000, 3000, 5000 }
m_defaultLongSqlDuration = { 100, 500, 1000, 3000, 5000 }
m_defaultLongUrlDuration = { 1000, 2000, 3000, 5000 }
m_defalutLongCallDuration = { 100, 500, 1000, 3000, 5000 }
m_defaultLongCacheDuration = { 10, 50, 100, 500 }
超时的事务消息将会被存储到指定machine的entity中,逻辑与DefaultProblemHandler相同,只不过,这里的duration就有了实际意义,问题处理器会根据事务所超出的阈值范围来存储到对应的Duration对象里面去。
自定义自己的问题处理器
TransactionAnalyzer - 事务分析
事务分析器会统计事务(Transaction)类型消息的运行时间,次数,错误次数,当然不是所有Transactionx消息都会被统计,Cache.web、ABTest以及serverFilter配置指定需要过滤的事务消息,会在分析器处理时被丢弃。
统计结果存于TransactionReport,依然是以周期时间和domain来划分不同的报表。
checkForTruncatedMessage ??
相同的domain下的不同IP对应的统计信息依然是存于不同的Machine对象中,截止目前我们已经看到很多报表都包含有Machine类,但是一定注意他们的Machine类都是不同的,可以在cat-consumer/target/generated-sources/dal-model/com/dianping/cat/consumer/ 目录下去查看这些类。
每台机器下面,不同类型的事务统计信息会存于不同的TransactionType对象里,在管理页面上,我们展开指定Type,会看到该Type下所有Name的统计信息,相同Type下的不同名称的统计信息就是分别存在于不同的TransactionName下面,点开每条记录前面的 [:: show ::], 我们将会看到该周期小时内每分钟的统计信息,每分钟的统计存储在 Type 的 Range2对象、Name的Range对象内,实际上Range2和Range对象的代码结构完全一致,除了类名不同,你可以认为他们就是同一个东西。
Type和Name都会统计总执行次数、失败次数、示例链接、最小时间、最大调用时间、平均值、标准差等等信息,同时分析器会选取最近一条消息作为他的示例链接,将messageId存于m_successMessageUrl或者m_failMessageUrl中。
我们会根据一定规则划分几个执行时间区间,将该区间的事务消息总数统计在 AllDuration 和 Duration 对象中。
深入详解美团点评CAT跨语言服务监控(六)消息分析器与报表(一)的更多相关文章
- 深入详解美团点评CAT跨语言服务监控(一) CAT简介与部署
前言: CAT是一个实时和接近全量的监控系统,它侧重于对Java应用的监控,除了与点评RPC组件融合的很好之外,他将会能与Spring.MyBatis.Dubbo 等框架以及Log4j 等结合,支持P ...
- 深入详解美团点评CAT跨语言服务监控(七)消息分析器与报表(二)
CrossAnalyzer-调用链分析 在分布式环境中,应用是运行在独立的进程中的,有可能是不同的机器,或者不同的服务器进程.那么他们如果想要彼此联系在一起,形成一个调用链,在Cat中,CrossAn ...
- 深入详解美团点评CAT跨语言服务监控(四)服务端消息分发
这边首先介绍下大众点评CAT消息分发大概的架构如下: 图4 消息分发架构图 分析管理器的初始化 我们在第一章讲到服务器将接收到的消息交给解码器(MessageDecoder)去做解码最后交给具体的消费 ...
- 深入详解美团点评CAT跨语言服务监控(三)CAT客户端原理
cat客户端部分核心类 message目录下面有消息相关的部分接口 internal目录包含主要的CAT客户端内部实现类: io目录包含建立服务端连接.重连.消息队列监听.上报等io实现类: spi目 ...
- 深入详解美团点评CAT跨语言服务监控(二) CAT服务端初始化
Cat模块 Cat-client : cat客户端,编译后生成 cat-client-2.0.0.jar ,用户可以通过它来向cat-home上报统一格式的日志信息,可以集成到 mybatis.spr ...
- 深入详解美团点评CAT跨语言服务监控(八)报表持久化
周期结束 我们从消息分发章节知道,RealtimeConsumer在初始化的时候,会启动一个线程,每隔1秒钟就去从判断是否需要开启或结束一个周期(Period),如下源码,如果 value < ...
- 深入详解美团点评CAT跨语言服务监控(五)配置与数据库操作
CAT配置 在CAT中,有非常多的配置去指导监控的行为,每个配置都有相应的配置管理类来管理,都有一个配置名, 配置在数据库或者配置文件中都是以xml格式存储,在运行时会被解析到具体实体类存储.我们选取 ...
- 深入详解美团点评CAT跨语言服务监控(九)CAT管理平台MVC框架
在第2章我们讲到,服务器在初始化CatServlet 之后, 会初始化 MVC,MVC也是继承自AbstractContainerServlet , 同样也是一个 Servlet 容器,这是一个非常古 ...
- 美团点评CAT监控平台研究
1. 美团点评CAT监控平台研究 1.1. 前言 此文根据我对官方文档阅读并记录整理所得,中间可能会穿插一些自己的思考和遇坑 1.2. 简介 CAT 是基于 Java 开发的实时应用监控平台,为美团点 ...
随机推荐
- SpringMVC配置及使用
SpringMVC基本配置 SpringMVC是基本请求响应模式的框架. 在项目中集成SpringMVC框架首先需要导入相关的jar包,所需包具体如下: commons-dbcp.jar common ...
- matlab中的reshape快速理解,卷积和乘积之间的转换
reshape: THe convertion between convolution and multiplication:
- cxf http 代码自动生成
1.下载 cxf 直接进入镜像下载http://mirrors.tuna.tsinghua.edu.cn/apache/cxf/3.1.12/apache-cxf-3.1.12.zip 2.配置 CX ...
- 八、启动linux内核并修改开机logo
1. 编译并烧写linux内核 1)先准备好内核源码包urbetter-linux2.6.28-v1.0.tgz,输入命令:tar -zxvf urbetter-linux2.6.28-v1.0.tg ...
- 『转』VC++ webbrowser函数使用范例
/*============================说明部分================================= 实现一下函数需包含头文件 #include <Winine ...
- 1.横向滚动条,要设置两个div包裹. 2. 点击切换视频或者图片. overflow . overflow-x
1.横向滚动条. div.1 > div.2 > img img img 第一: 设置 div.1 一个固定的宽度 和高度 . 例如宽度 700px; 高度是 120px; 设置 o ...
- __autolaod
转载自:https://blog.csdn.net/baidu_30000217/article/details/52743139 php实现类文件自动载入有两种办法: 魔术方法:__autoload ...
- Python 私有
class Person: __qie = "潘潘" # 类变量 def __init__(self, name, mimi): self.name = name self.__m ...
- ecmall 主从表的4种模型关系
eccore/model/model.base.php对应关系: 举例:在includes/models goods.model.php 里 因为店铺可以对应多个商品,商品只能对应一个店铺,所以商品B ...
- Selenium之ActionChains(一)
今天,分享的是ActionChains的使用方法. 先来说一下今天要用到的方法: click(element=null) 点击元素,参数 ...