多分类-- ROC曲线
本文主要介绍一下多分类下的ROC曲线绘制和AUC计算,并以鸢尾花数据为例,简单用python进行一下说明。如果对ROC和AUC二分类下的概念不是很了解,可以先参考下这篇文章:http://blog.csdn.net/ye1215172385/article/details/79448575
由于ROC曲线是针对二分类的情况,对于多分类问题,ROC曲线的获取主要有两种方法:
假设测试样本个数为m,类别个数为n(假设类别标签分别为:0,2,...,n-1)。在训练完成后,计算出每个测试样本的在各类别下的概率或置信度,得到一个[m, n]形状的矩阵P,每一行表示一个测试样本在各类别下概率值(按类别标签排序)。相应地,将每个测试样本的标签转换为类似二进制的形式,每个位置用来标记是否属于对应的类别(也按标签排序,这样才和前面对应),由此也可以获得一个[m, n]的标签矩阵L。
比如n等于3,标签应转换为:
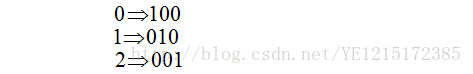
方法1:每种类别下,都可以得到m个测试样本为该类别的概率(矩阵P中的列)。所以,根据概率矩阵P和标签矩阵L中对应的每一列,可以计算出各个阈值下的假正例率(FPR)和真正例率(TPR),从而绘制出一条ROC曲线。这样总共可以绘制出n条ROC曲线。最后对n条ROC曲线取平均,即可得到最终的ROC曲线。
方法2:首先,对于一个测试样本:1)标签只由0和1组成,1的位置表明了它的类别(可对应二分类问题中的‘’正’’),0就表示其他类别(‘’负‘’);2)要是分类器对该测试样本分类正确,则该样本标签中1对应的位置在概率矩阵P中的值是大于0对应的位置的概率值的。基于这两点,将标签矩阵L和概率矩阵P分别按行展开,转置后形成两列,这就得到了一个二分类的结果。所以,此方法经过计算后可以直接得到最终的ROC曲线。
上面的两个方法得到的ROC曲线是不同的,当然曲线下的面积AUC也是不一样的。 在python中,方法1和方法2分别对应sklearn.metrics.roc_auc_score函数中参数average值为'macro'和'micro'的情况。

下面以方法2为例,直接上代码,概率矩阵P和标签矩阵L分别对应代码中的y_score和y_one_hot:
#!/usr/bin/python
# -*- coding:utf-8 -*- import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegressionCV
from sklearn import metrics
from sklearn.preprocessing import label_binarize if __name__ == '__main__':
np.random.seed(0)
data = pd.read_csv('iris.data', header = None) #读取数据
iris_types = data[4].unique()
n_class = iris_types.size
x = data.iloc[:, :2] #只取前面两个特征
y = pd.Categorical(data[4]).codes #将标签转换0,1,...
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size = 0.6, random_state = 0)
y_one_hot = label_binarize(y_test, np.arange(n_class)) #装换成类似二进制的编码
alpha = np.logspace(-2, 2, 20) #设置超参数范围
model = LogisticRegressionCV(Cs = alpha, cv = 3, penalty = 'l2') #使用L2正则化
model.fit(x_train, y_train)
print '超参数:', model.C_
# 计算属于各个类别的概率,返回值的shape = [n_samples, n_classes]
y_score = model.predict_proba(x_test)
# 1、调用函数计算micro类型的AUC
print '调用函数auc:', metrics.roc_auc_score(y_one_hot, y_score, average='micro')
# 2、手动计算micro类型的AUC
#首先将矩阵y_one_hot和y_score展开,然后计算假正例率FPR和真正例率TPR
fpr, tpr, thresholds = metrics.roc_curve(y_one_hot.ravel(),y_score.ravel())
auc = metrics.auc(fpr, tpr)
print '手动计算auc:', auc
#绘图
mpl.rcParams['font.sans-serif'] = u'SimHei'
mpl.rcParams['axes.unicode_minus'] = False
#FPR就是横坐标,TPR就是纵坐标
plt.plot(fpr, tpr, c = 'r', lw = 2, alpha = 0.7, label = u'AUC=%.3f' % auc)
plt.plot((0, 1), (0, 1), c = '#808080', lw = 1, ls = '--', alpha = 0.7)
plt.xlim((-0.01, 1.02))
plt.ylim((-0.01, 1.02))
plt.xticks(np.arange(0, 1.1, 0.1))
plt.yticks(np.arange(0, 1.1, 0.1))
plt.xlabel('False Positive Rate', fontsize=13)
plt.ylabel('True Positive Rate', fontsize=13)
plt.grid(b=True, ls=':')
plt.legend(loc='lower right', fancybox=True, framealpha=0.8, fontsize=12)
plt.title(u'鸢尾花数据Logistic分类后的ROC和AUC', fontsize=17)
plt.show()
实验输出结果:

可以从上图看出,两者计算结果一致!
实验绘图结果:

这里是micro average ROC:
https://blog.csdn.net/YE1215172385/article/details/79443552
macro average ROC 可以参考:
https://blog.csdn.net/xyz1584172808/article/details/81839230
多分类-- ROC曲线的更多相关文章
- 机器学习:分类算法性能指标之ROC曲线
在介绍ROC曲线之前,先说说混淆矩阵及两个公式,因为这是ROC曲线计算的基础. 1.混淆矩阵的例子(是否点击广告): 说明: TP:预测的结果跟实际结果一致,都点击了广告. FP:预测结果点击了,但是 ...
- 【sklearn】性能度量指标之ROC曲线(二分类)
原创博文,转载请注明出处! 1.ROC曲线介绍 ROC曲线适用场景 二分类任务中,positive和negtive同样重要时,适合用ROC曲线评价 ROC曲线的意义 TPR的增长是以FPR的增长为代价 ...
- 多分类下的ROC曲线和AUC
本文主要介绍一下多分类下的ROC曲线绘制和AUC计算,并以鸢尾花数据为例,简单用python进行一下说明.如果对ROC和AUC二分类下的概念不是很了解,可以先参考下这篇文章:http://blog.c ...
- ROC曲线是通过样本点分类概率画出的 例如某一个sample预测为1概率为0.6 预测为0概率0.4这样画出来,此外如果曲线不是特别平滑的话,那么很可能存在过拟合的情况
ROC和AUC介绍以及如何计算AUC from:http://alexkong.net/2013/06/introduction-to-auc-and-roc/ ROC(Receiver Operat ...
- 机器学习:评价分类结果(ROC 曲线)
一.基础理解 1)定义 ROC(Receiver Operation Characteristic Curve) 定义:描述 TPR 和 FPR 之间的关系: 功能:应用于比较两个模型的优劣: 模型不 ...
- scikit-learn机器学习(二)逻辑回归进行二分类(垃圾邮件分类),二分类性能指标,画ROC曲线,计算acc,recall,presicion,f1
数据来自UCI机器学习仓库中的垃圾信息数据集 数据可从http://archive.ics.uci.edu/ml/datasets/sms+spam+collection下载 转成csv载入数据 im ...
- 【分类模型评判指标 二】ROC曲线与AUC面积
转自:https://blog.csdn.net/Orange_Spotty_Cat/article/details/80499031 略有改动,仅供个人学习使用 简介 ROC曲线与AUC面积均是用来 ...
- 分类问题(四)ROC曲线
ROC曲线 ROC曲线是二元分类器中常用的工具,它的全称是 Receiver Operating Characteristic,接收者操作特征曲线.它与precision/recall 曲线特别相似, ...
- [机器学习]-分类问题常用评价指标、混淆矩阵及ROC曲线绘制方法
分类问题 分类问题是人工智能领域中最常见的一类问题之一,掌握合适的评价指标,对模型进行恰当的评价,是至关重要的. 同样地,分割问题是像素级别的分类,除了mAcc.mIoU之外,也可以采用分类问题的一些 ...
随机推荐
- 大数据在教育中的应用 part2笔记
什么是交叉检验(K-fold cross-validation) K层交叉检验就是把原始的数据随机分成K个部分.在这K个部分中,选择一个作为测试数据,剩下的K-1个作为训练数据. 交叉检验的过程实 ...
- python学习之for循环
Python for循环可以遍历任何序列的项目,如一个列表或者一个字符串. 实例: #!/usr/bin/env python for letter in 'Python': # 第一个实例 prin ...
- C#连接oracle连接字符串
/// <summary> /// Oracle 的数据库连接字符串. /// </summary> private const String connString = @&q ...
- Codeforces 815C Karen and Supermarket 树形dp
Karen and Supermarket 感觉就是很普通的树形dp. dp[ i ][ 0 ][ u ]表示在 i 这棵子树中选择 u 个且 i 不用优惠券的最小花费. dp[ i ][ 1 ][ ...
- 【Java】 剑指offer(37) 序列化二叉树
本文参考自<剑指offer>一书,代码采用Java语言. 更多:<剑指Offer>Java实现合集 题目 请实现两个函数,分别用来序列化和反序列化二叉树. 思路 一般情况下 ...
- 023 SpringMVC拦截器
一:拦截器的HelloWorld 1.首先自定义拦截器 只要实现接口就行. package com.spring.it.interceptors; import javax.servlet.http. ...
- 016 Spark中关于购物篮的设计,以及优化(两个点)
一:介绍 1.购物篮的定义 2.适用场景 3.相关概念 4.步骤 5.编程实现 6.步骤 二:程序 1.程序 package com.ibeifeng.senior.mba.association i ...
- char与unsigned char的区别
#include <stdio.h> int main() { unsigned ; char b = a; printf("a = %d , b = %d",a,b) ...
- Python库资源大全
转载地址:https://zhuanlan.zhihu.com/p/27350980 本文是一个精心设计的Python框架.库.软件和资源列表,是一个Awesome XXX系列的资源整理,由BigQu ...
- Python常用模块--logging
(转载) 原文:http://www.cnblogs.com/dahu-daqing/p/7040764.html 1 logging模块简介 logging模块是Python内置的标准模块,主要用于 ...