python爬虫学习(三):使用re库爬取"淘宝商品",并把结果写进txt文件
第二个例子是使用requests库+re库爬取淘宝搜索商品页面的商品信息
(1)分析网页源码
打开淘宝,输入关键字“python”,然后搜索,显示如下搜索结果
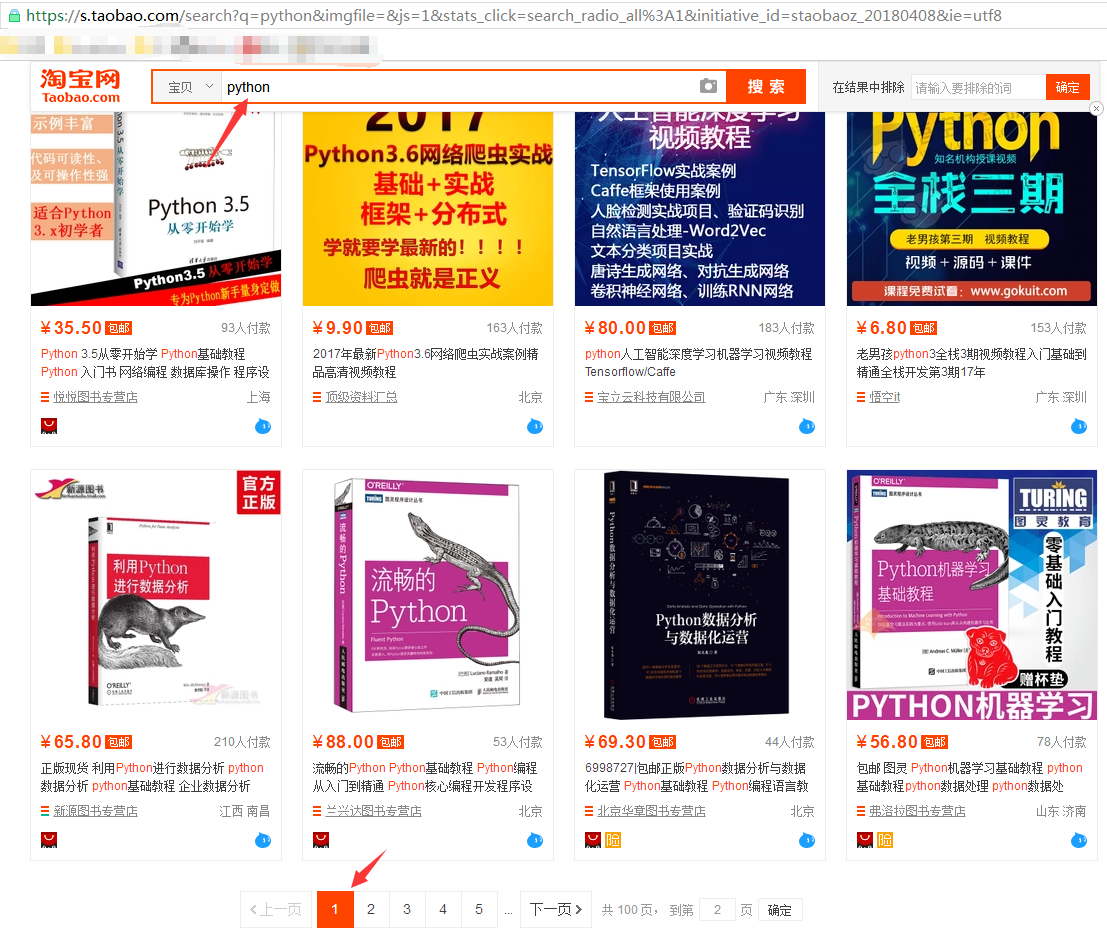
从url连接中可以得到搜索商品的关键字是“q=”,所以我们要用的起始url为:https://s.taobao.com/search?q=python
然后翻页,先跳到第二页,url变为:

再跳到第三页,url变为:

经过对比发现,翻页后,变化的关键字是s,每次翻页,s便以44的倍数增长(可以数一下每页显示的商品数量,刚好是44)
所以可以根据关键字“s=”,来设置爬取的深度(爬取多少页)
右键查看源码:

分析商品名称和商品价格分别由哪个关键字控制:
商品名称可能的关键字是“title”和“raw_title”,进一步多看几个商品的名称,发现选取“raw_title”比较合适;商品价格自然就是“view_price”(通过比对淘宝商品展示页面);
所以商品名称和商品价格分别是以 "raw_title":"名称" 和 "view_price":"价格",这样的键/值对的形式展示的。
(2)分析如何实现
与上一个例子爬取“最好大学排名”不同,淘宝商品信息不像之前的大学信息是以HTML格式嵌入的,这里的商品信息并未以HTML标签的形式处理数据,而是直接以脚本语言放进来的,所以不需要用BeautifulSoup来解析,直接用正则表达式提取 关键字信息即可
(3)提取信息
写个demo,看看是如何一步步解析信息的
# coding:utf-8 import requests
import re goods = '水杯'
url = 'https://s.taobao.com/search?q=' + goods r = requests.get(url=url, timeout=10)
html = r.text tlist = re.findall(r'\"raw_title\"\:\".*?\"', html) # 正则提取商品名称
plist = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html) # 正则提示商品价格 print(tlist)
print(plist)
print(type(plist)) # 正则表达式提取出的商品名称和商品价格都是以列表形式存储数据的

去掉列表中的键,只留下值,也就是去掉每组数据的“raw_title”和“view_price”
print('第一个商品的键值对信息:', tlist[0]) # 查看第一个商品的键值对信息
a = tlist[0].split(':')[1] # 使用split()方法以":"为切割点,将商品的键值分开,提取值,即商品名称
print('第一个商品的名称', a)
print(type(a)) # 查看a的类型
b = eval(a) # 使用eval()函数,去掉字符串的引号
print('把商品名称去掉引号后', b) # 查看去掉引号后的效果
print(type(b)) # 查看b的类型

利用for循环,把每个商品的名称和价格组成一个列表,然后把这写列表再追加到一个大列表中:
goodlist = []
for i in range(len(tlist)):
title = eval(tlist[i].split(':')[1]) # eval()函数简单说就是用于去掉字符串的引号
price = eval(plist[i].split(':')[1])
goodlist.append([title, price]) # 把每个商品的名称和价格组成一个小列表,然后把所有商品组成的列表追加到一个大列表中
print(goodlist)

完整代码:
# coding: utf-8 import requests
import re # def getHTMLText(url):
# try:
# r = requests.get(url, timeout=30)
# r.raise_for_status()
# r.encoding = r.apparent_encoding
# return r.text
# except:
# return ""
#
#
# def parsePage(ilt, html):
# try:
# plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html)
# tlt = re.findall(r'\"raw_title\"\:\".*?\"', html)
# for i in range(len(plt)):
# price = eval(plt[i].split(':')[1])
# title = eval(tlt[i].split(':')[1])
# ilt.append([price, title])
# except:
# print()
#
#
# def printGoodsList(ilt):
# tplt = "{:4}\t{:8}\t{:16}"
# print(tplt.format("序号", "价格", "商品名称"))
# count = 0
# for t in ilt:
# count = count + 1
# print(tplt.format(count, t[0], t[1]))
#
#
# def main():
# goods = '高达'
# depth = 3
# start_url = 'https://s.taobao.com/search?q=' + goods
# infoList = []
# for i in range(depth):
# try:
# url = start_url + '&s=' + str(44 * i)
# html = getHTMLText(url)
# parsePage(infoList, html)
# except:
# continue
# printGoodsList(infoList)
#
#
# main() def get_html(url):
"""获取源码html"""
try:
r = requests.get(url=url, timeout=10)
r.encoding = r.apparent_encoding
return r.text
except:
print("获取失败") def get_data(html, goodlist):
"""使用re库解析商品名称和价格
tlist:商品名称列表
plist:商品价格列表"""
tlist = re.findall(r'\"raw_title\"\:\".*?\"', html)
plist = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html)
for i in range(len(tlist)):
title = eval(tlist[i].split(':')[1]) # eval()函数简单说就是用于去掉字符串的引号
price = eval(plist[i].split(':')[1])
goodlist.append([title, price]) def write_data(list, num):
# with open('E:/Crawler/case/taob2.txt', 'a') as data:
# print(list, file=data)
for i in range(num): # num控制把爬取到的商品写进多少到文本中
u = list[i]
with open('E:/Crawler/case/taob.txt', 'a') as data:
print(u, file=data) def main():
goods = '水杯'
depth = 3 # 定义爬取深度,即翻页处理
start_url = 'https://s.taobao.com/search?q=' + goods
infoList = []
for i in range(depth):
try:
url = start_url + '&s=' + str(44 * i) # 因为淘宝显示每页44个商品,第一页i=0,一次递增
html = get_html(url)
get_data(html, infoList)
except:
continue
write_data(infoList, len(infoList)) if __name__ == '__main__':
main()

python爬虫学习(三):使用re库爬取"淘宝商品",并把结果写进txt文件的更多相关文章
- python爬虫学习之使用BeautifulSoup库爬取开奖网站信息-模块化
实例需求:运用python语言爬取http://kaijiang.zhcw.com/zhcw/html/ssq/list_1.html这个开奖网站所有的信息,并且保存为txt文件和excel文件. 实 ...
- python爬虫实例,一小时上手爬取淘宝评论(附代码)
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 1 明确目的 通过访问天猫的网站,先搜索对应的商品,然后爬取它的评论数据. ...
- Python 爬虫实例(9)—— 搜索 爬取 淘宝
# coding:utf- import json import redis import time import requests session = requests.session() impo ...
- Python爬虫实战八之利用Selenium抓取淘宝匿名旺旺
更新 其实本文的初衷是为了获取淘宝的非匿名旺旺,在淘宝详情页的最下方有相关评论,含有非匿名旺旺号,快一年了淘宝都没有修复这个. 可就在今天,淘宝把所有的账号设置成了匿名显示,SO,获取非匿名旺旺号已经 ...
- Python 爬取淘宝商品数据挖掘分析实战
Python 爬取淘宝商品数据挖掘分析实战 项目内容 本案例选择>> 商品类目:沙发: 数量:共100页 4400个商品: 筛选条件:天猫.销量从高到低.价格500元以上. 爬取淘宝商品 ...
- python3编写网络爬虫16-使用selenium 爬取淘宝商品信息
一.使用selenium 模拟浏览器操作爬取淘宝商品信息 之前我们已经成功尝试分析Ajax来抓取相关数据,但是并不是所有页面都可以通过分析Ajax来完成抓取.比如,淘宝,它的整个页面数据确实也是通过A ...
- 利用Selenium爬取淘宝商品信息
一. Selenium和PhantomJS介绍 Selenium是一个用于Web应用程序测试的工具,Selenium直接运行在浏览器中,就像真正的用户在操作一样.由于这个性质,Selenium也是一 ...
- Selenium+Chrome/phantomJS模拟浏览器爬取淘宝商品信息
#使用selenium+Carome/phantomJS模拟浏览器爬取淘宝商品信息 # 思路: # 第一步:利用selenium驱动浏览器,搜索商品信息,得到商品列表 # 第二步:分析商品页数,驱动浏 ...
- <day003>登录+爬取淘宝商品信息+字典用json存储
任务1:利用cookie可以免去登录的烦恼(验证码) ''' 只需要有登录后的cookie,就可以绕过验证码 登录后的cookie可以通过Selenium用第三方(微博)进行登录,不需要进行淘宝的滑动 ...
随机推荐
- 02: CMDB设计思路
1.1 cmdb理解 参考博客:https://www.cnblogs.com/laowenBlog/p/6825420.html 参考博客2:https://www.cnblogs.com/ ...
- phpstudy手动把mysql数据库从5.5.56升级到5.6.41
查看mysql版本: mysql> select version(); 1.关闭mysql,把原来的D:/phpStudy/PHPTutorial/mysql改名为MySQL_5.5.53作为备 ...
- Codeforces Round #424 (Div. 2, rated, based on VK Cup Finals) Problem C (Codeforces 831C) - 暴力 - 二分法
Polycarp watched TV-show where k jury members one by one rated a participant by adding him a certain ...
- 【linux下多实例Tomcat+Nginx+redis+mysql环境搭建】
一.搭建环境之前最好自己先创建一个文件夹,再次文件夹下在创建文件夹来安放项目包和Tomcat等应用以及性能测试监控的文件 1.项目存放地址: mkdir export (创建一个文件),mkdir a ...
- Access导出excel
SELECT * INTO [excel .xls].Sheet1 FROM tableName
- linux --- 4. 虚拟环境
一.虚拟环境的两种安装方式 1. virtualenv 虚拟环境 ①下载 virtualenv pip3 install -i https://pypi.tuna.tsinghua.edu.cn/s ...
- 转载:Systemd 服务配置文件
目录 一.开机启动 二.启动服务 三.停止服务 四.读懂配置文件 五. [Unit] 区块:启动顺序与依赖关系. 六.[Service] 区块:启动行为 6.1 启动命令 6.2 启动类型 6.3 重 ...
- C# DataTable.Compute()用法
DataTable.Compute()用法 2010-04-07 11:28 一.DataTable.Compute()方法說明如下 作用: 计算用来传递筛选条件的当前行上的给定表达 ...
- IE8下面parseInt('08')、parseInt('09')会转成0
例子: <html> <body> <script type="text/javascript"> for(var i=1;i<=20;i ...
- Python实现机器学习算法:逻辑回归
import numpy as np import matplotlib.pyplot as plt from sklearn.datasets.samples_generator import ma ...