常用七种排序的python实现
1 算法复杂度
算法复杂度分为时间复杂度和空间复杂度。其中, 时间复杂度是指执行算法所需要的计算工作量;而空间复杂度是指执行这个算法所需要的内存空间。
算法的复杂性体现在运行该算法时的计算机所需资源的多少上,计算机资源最重要的是时间和空间资源,因此复杂度分为时间和空间复杂度。用大O表示。
常见的时间复杂度(按效率排序)
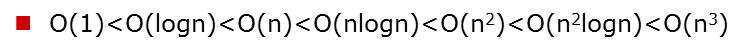
2 冒泡排序
冒泡法:第一趟:相邻的两数相比,大的往下沉。最后一个元素是最大的。
第二趟:相邻的两数相比,大的往下沉。最后一个元素不用比。
def bubble_sort(array):
for i in range(len(array)-1):
for j in range(len(array) - i -1):
if array[j] > array[j+1]:
array[j], array[j+1] = array[j+1], array[j]
时间复杂度:O(n^2)
稳定性:稳定
改进:如果一趟比较没有发生位置变换,则认为排序完成
def bubble_sort(array):
for i in range(len(array)-1):
current_status = False
for j in range(len(array) - i -1):
if array[j] > array[j+1]:
array[j], array[j+1] = array[j+1], array[j]
current_status = True
if not current_status:
break
3 直接选择排序
选择排序法:每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放到序列的起始位置,直到全部排完。
def select_sort(array):
for i in range(len(array)-1):
min = i
for j in range(i+1, len(array)):
if array[j] < array[min]:
min = j
array[i], array[min] = array[min], array[i]
时间复杂度:O(n^2)
稳定性:不稳定
4 直接插入排序
列表被分为有序区和无序区两个部分。最初有序区只有一个元素。
每次从无序区选择一个元素,插入到有序区的位置,直到无序区变空。
其实就相当于摸牌:

def insert_sort(array):
# 循环的是第二个到最后(待摸的牌)
for i in range(1, len(array)):
# 待插入的数(摸上来的牌)
min = array[i]
# 已排好序的最右边一个元素(手里的牌的最右边)
j = i - 1
# 一只和排好的牌比较,排好的牌的牌的索引必须大于等于0
# 比较过程中,如果手里的比摸上来的大,
while j >= 0 and array[j] > min:
# 那么手里的牌往右边移动一位,就是把j付给j+1
array[j+1] = array[j]
# 换完以后在和下一张比较
j -= 1
# 找到了手里的牌比摸上来的牌小或等于的时候,就把摸上来的放到它右边
array[j+1] = min
时间复杂度:O(n^2)
稳定性:稳定
5 快速排序
取一个元素p(通常是第一个元素,但是这是比较糟糕的选择),使元素p归位(把p右边比p小的元素都放在它左边,在把空缺位置的左边比p大的元素放在p右边);
列表被p分成两部分,左边都比p小,右边都比p大;
递归完成排序。
def quick_sort(array, left, right):
if left < right:
mid = partition(array, left, right)
quick_sort(array, left, mid-1)
quick_sort(array, mid+1, right) def partition(array, left, right):
tmp = array[left]
while left < right:
while left < right and array[right] >= tmp:
right -= 1
array[left] = array[right]
while left < right and array[left] <= tmp:
left += 1
array[right] = array[left]
array[left] = tmp
return left
时间复杂度:O(nlogn),一般情况是O(nlogn),最坏情况(逆序):O(n^2)
稳定性:不稳定
特点:就是快
6 堆排序
步骤:
建立堆
得到堆顶元素,为最大元素
去掉堆顶,将堆最后一个元素放到堆顶,此时可通过一次调整重新使堆有序。
堆顶元素为第二大元素。
重复步骤3,直到堆变空。
def sift(array, left, right):
"""调整"""
i = left # 当前调整的小堆的父节点
j = 2*i + 1 # i的左孩子
tmp = array[i] # 当前调整的堆的根节点
while j <= right: # 如果孩子还在堆的边界内
if j < right and array[j] < array[j+1]: # 如果i有右孩子,且右孩子比左孩子大
j = j + 1 # 大孩子就是右孩子
if tmp < array[j]: # 比较根节点和大孩子,如果根节点比大孩子小
array[i] = array[j] # 大孩子上位
i = j # 新调整的小堆的父节点
j = 2*i + 1 # 新调整的小堆中I的左孩子
else: # 否则就是父节点比大孩子大,则终止循环
break
array[i] = tmp # 最后i的位置由于是之前大孩子上位了,是空的,而这个位置是根节点的正确位置。 def heap(array):
n = len(array)
# 建堆,从最后一个有孩子的父亲开始,直到根节点
for i in range(n//2 - 1, -1, -1):
# 每次调整i到结尾
sift(array, i, n-1)
# 挨个出数
for i in range(n-1, -1, -1):
# 把根节点和调整的堆的最后一个元素交换
array[0], array[i] = array[i], array[0]
# 再调整,从0到i-1
sift(array, 0, i-1)
时间复杂度:O(nlogn),
稳定性:不稳定
特点:通常都比快排慢
7 为什么堆排比快排慢?
回顾一下堆排的过程: 1. 建立最大堆(堆顶的元素大于其两个儿子,两个儿子又分别大于它们各自下属的两个儿子... 以此类推)
2. 将堆顶的元素和最后一个元素对调(相当于将堆顶元素(最大值)拿走,然后将堆底的那个元素补上它的空缺),然后让那最后一个元素从顶上往下滑到恰当的位置(重新使堆最大化)。
3. 重复第2步。 这里的关键问题就在于第2步,堆底的元素肯定很小,将它拿到堆顶和原本属于最大元素的两个子节点比较,它比它们大的可能性是微乎其微的。实际上它肯定小于其中的一个儿子。而大于另一个儿子的可能性非常小。于是,这一次比较的结果就是概率不均等的,根据前面的分析,概率不均等的比较是不明智的,因为它并不能保证在糟糕情况下也能将问题的可能性削减到原本的1/2。可以想像一种极端情况,如果a肯定小于b,那么比较a和b就会什么信息也得不到——原本剩下多少可能性还是剩下多少可能性。
在堆排里面有大量这种近乎无效的比较,因为被拿到堆顶的那个元素几乎肯定是很小的,而靠近堆顶的元素又几乎肯定是很大的,将一个很小的数和一个很大的数比较,结果几乎肯定是“小于”的,这就意味着问题的可能性只被排除掉了很小一部分。
这就是为什么堆排比较慢(堆排虽然和快排一样复杂度都是O(NlogN)但堆排复杂度的常系数更大)。
MacKay也提供了一个修改版的堆排:每次不是将堆底的元素拿到上面去,而是直接比较堆顶(最大)元素的两个儿子,即选出次大的元素。由于这两个儿子之间的大小关系是很不确定的,两者都很大,说不好哪个更大哪个更小,所以这次比较的两个结果就是概率均等的了
8 归并排序
思路:
一次归并:将现有的列表分为左右两段,将两段里的元素逐一比较,小的就放入新的列表中。比较结束后,新的列表就是排好序的。
然后递归。
# 一次归并
def merge(array, low, mid, high):
"""
两段需要归并的序列从左往右遍历,逐一比较,小的就放到
tmp里去,再取,再比,再放。
"""
tmp = []
i = low
j = mid +1
while i <= mid and j <= high:
if array[i] <= array[j]:
tmp.append(array[i])
i += 1
else:
tmp.append(array[j])
j += 1
while i <= mid:
tmp.append(array[i])
i += 1
while j <= high:
tmp.append(array[j])
j += 1
array[low:high+1] = tmp def merge_sort(array, low, high):
if low < high:
mid = (low + high) // 2
merge_sort(array, low, mid)
merge_sort(array, mid+1, high)
merge(array, low, mid, high)
时间复杂度:O(nlogn)
稳定性:稳定
快排、堆排和归并的小结
三种排序算法的时间复杂度都是O(nlogn) 一般情况下,就运行时间而言:
快速排序 < 归并排序 < 堆排序 三种排序算法的缺点:
快速排序:极端情况下排序效率低
归并排序:需要额外的内存开销
堆排序:在快的排序算法中相对较慢
9 希尔排序
希尔排序是一种分组插入排序算法。
首先取一个整数d1=n/2,将元素分为d1个组,每组相邻量元素之间距离为d1,在各组内进行直接插入排序;
取第二个整数d2=d1/2,重复上述分组排序过程,直到di=1,即所有元素在同一组内进行直接插入排序。希尔排序每趟并不使某些元素有序,而是使整体数据越来越接近有序;最后一趟排序使得所有数据有序。
def shell_sort(li):
"""希尔排序"""
gap = len(li) // 2
while gap > 0:
for i in range(gap, len(li)):
tmp = li[i]
j = i - gap
while j >= 0 and tmp < li[j]:
li[j + gap] = li[j]
j -= gap
li[j + gap] = tmp
gap //= 2
时间复杂度:O((1+τ)n)
不是很快,位置尴尬
10 排序小结

常用七种排序的python实现的更多相关文章
- 模板化的七种排序算法,适用于T* vector<T>以及list<T>
最近在写一些数据结构以及算法相关的代码,比如常用排序算法以及具有启发能力的智能算法.为了能够让写下的代码下次还能够被复用,直接将代码编写成类模板成员函数的方式,之所以没有将这种方式改成更方便的函数模板 ...
- 数据结构(三) 用java实现七种排序算法。
很多时候,听别人在讨论快速排序,选择排序,冒泡排序等,都觉得很牛逼,心想,卧槽,排序也分那么多种,就觉得别人很牛逼呀,其实不然,当我们自己去了解学习后发现,并没有想象中那么难,今天就一起总结一下各种排 ...
- C#常用8种排序算法实现以及原理简介
public static class SortExtention { #region 冒泡排序 /* * 已知一组无序数据a[1].a[2].--a[n],需将其按升序排列.首先比较a[1]与a[2 ...
- python实现常用五种排序算法
一.冒泡排序 原理: 比较相邻的元素.如果第一个比第二个大就交换他们两个 每一对相邻元素做同样的工作,直到结尾最后一对 每个元素都重复以上步骤,除了最后一个 第一步: 将乱序中的最大值找出,逐一移到序 ...
- 三种排序算法python源码——冒泡排序、插入排序、选择排序
最近在学习python,用python实现几个简单的排序算法,一方面巩固一下数据结构的知识,另一方面加深一下python的简单语法. 冒泡排序算法的思路是对任意两个相邻的数据进行比较,每次将最小和最大 ...
- C语言中的七种排序算法
堆排序: void HeapAdjust(int *arraydata,int rootnode,int len) { int j; int t; *rootnode+<len) { j=*ro ...
- Collection -集合祖宗的常用七种共性方法
package cn.learn.collection; import java.util.ArrayList; import java.util.Collection; /* 在java.util. ...
- 基于python的七种经典排序算法
参考书目:<大话数据结构> 一.排序的基本概念和分类 所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作.排序算法,就是如何使得记录按照要求排列的方法. ...
- 基于python的七种经典排序算法(转)
一.排序的基本概念和分类 所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作.排序算法,就是如何使得记录按照要求排列的方法. 排序的稳定性:经过某种排序后,如果两个 ...
随机推荐
- P2789 直线交点数
P2789 直线交点数分成两种情况,一种是平行直线,一种是自由直线,在自由直线中可以存在平行直线,但是不能和第一组的直线平行.自由直线和平行直线的交点是i*(n-i). #include<ios ...
- Css实现元素的垂直居中
前言: 在写CSS的时候让元素在高度固定的容器中垂直居中是很简单的,譬如设置容器的padding或者元素的margin之类的都可以做到:让元素在容器中水平居中也有text-align:center.m ...
- Cocos2d-X开发教程-捕鱼达人 Cocos2-x development tutorial - fishing talent
Cocos2d-X开发教程-捕鱼达人 Cocos2-x development tutorial - fishing talent 作者:韩梦飞沙 Author:han_meng_fei_sha 邮箱 ...
- socket 远程命令
# -*- coding: utf-8 -*- # 斌彬电脑 from socket import * import subprocess server = socket(AF_INET, SOCK_ ...
- 数据结构+算法面试100题~~~摘自CSDN
数据结构+算法面试100题~~~摘自CSDN,作者July 1.把二元查找树转变成排序的双向链表(树) 题目:输入一棵二元查找树,将该二元查找树转换成一个排序的双向链表.要求不能创建任何新的结点,只调 ...
- post请求的header
HTTP Headers 中的 HTTP请求 Accept-Encoding Accept-Encoding: gzip,deflate 大部分的现代浏览器都支持gzip压缩,并会把这一信息报告给服务 ...
- webstorm安装教程
之前有些一些破解的,但是独独忘记了安装的这个教程,现在补上:见下: 先来一官方的解释:WebStorm是JetBrains 推出的一款强大的HTML5编辑工具,拥有丰富的代码快速编辑,可以智能的补全代 ...
- Codeforces Round #408 (Div. 2) 题解【ABCDE】
A - Buying A House 题意:给你n个房间,妹子住在第m个房间,你有k块钱,你想买一个离妹子最近的房间.其中相邻的房间之间距离为10,a[i]=0表示已经被别人买了. 题解:扫一遍更新答 ...
- (素材源代码)猫猫学IOS(四)UI之半小时搞定Tom猫
下载地址:http://download.csdn.net/detail/u013357243/8514915 以下是执行图片展示 制作思路以及代码解析 猫猫学IOS(四)UI之半小时搞定Tom猫这里 ...
- vs2013修改书签(vs书签文件位置)
visual studio 2013 的书签功能很好用,可以记录一些代码的位置:方便查阅: 不过当项目被他人修改过后,svn update 更新过后,书签的文件行号不变,但是已经不再是原来记录的哪一行 ...