爬虫学习--Day3(小猿圈爬虫开发_1)
爬虫基础简介
前戏:
1、你是否在夜深人静的时候,想看一些让你更睡不着的图片
2、你是否在考试或者面试前夕,想看一些具有针对性的题目和面试题
3、你是否想在杂乱的网络世界中获取你想要的数据
什么是爬虫:
- 通过编写程序模拟浏览器上网,然后让其去互联网上抓取数据的过程。
爬虫的价值:
- 实际应用
- 就业
爬虫究竟是合法还是违法?
- 在法律中是不备禁止
- 具有违法风险
- 善意爬虫 恶意爬虫
爬虫带来的风险可以体现在如下2方面:
- 爬虫干扰了被访问网站的正常运营
- 爬虫抓取了收到法律保护的特定类型的数据或信息
如何在使用编写爬虫的过程中避免进入局子的厄运呢?
- 市场的优化自己的程序,避免干扰被访问网站的正常运行
- 在使用,传播爬取到的数据时,审查抓取到的内容,如果发现了设计到了用户隐私或者商业机密等敏感内容需要及时停止爬取或传播
爬虫在使用场景中的分类
- 通用爬虫:
抓取系统重要组成部分。
抓取的是互联网中一整张页面数据。
- 聚焦爬虫:
是建立在通用爬虫的基础之上。
抓取的是页面中特定的局部内容 。
- 增量式爬虫:
检测网站中数据更新的情况。
只会爬取网站中最新更新出来的数据。
爬虫的矛与盾
反爬机制
- 门户网站,可以制定相应的策略或者技术手段,防止爬虫程序进行网站数据的爬取。
反反爬策略
- 爬虫程序也可以通过制定相关的策略或者技术手段,破解门户网站中具备的反爬机制,从而可以获取门户网站的数据
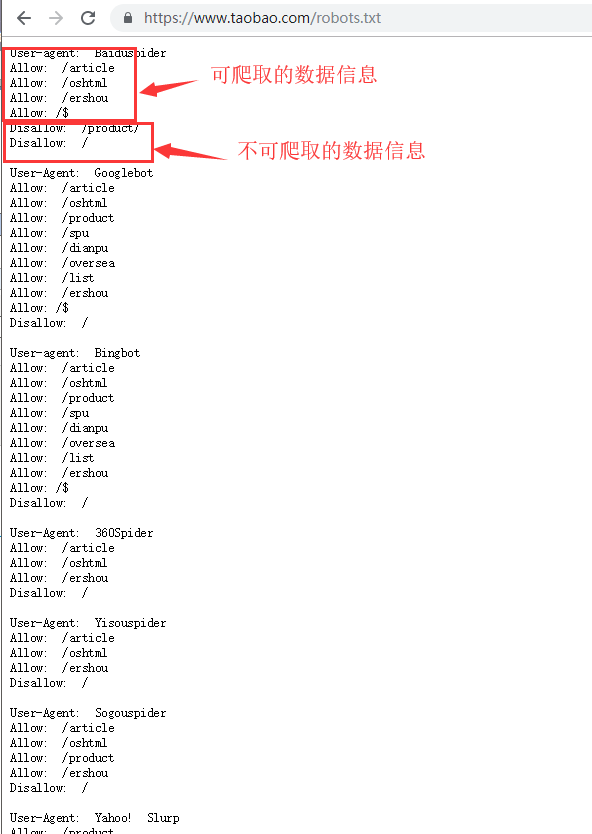
robots.txt协议
- 叫做君子协议。
- 规定了网站中哪些数据可以被爬虫爬取哪些数据不可以被爬取。
例子:www.taobao.com/robots.txt
http协议
- 概念:就是服务器和客户端进行数据交互的一种模式。
常用请求头信息
- User-Agent:请求载体的身份标识
- Connection:表示的是请求完毕后是断开连接还是保持连接
常用的响应头信息
- Content-Type:服务器响应回客户端的数据类型
https协议:
- 安全的超文本传输协议
加密方式
- 对称秘钥加密:客户端向服务器发送一条信息,首先客户端会采用已知的算法对信息进行加密,比如MD5或者Base64加密,接收端对加密的信息进行解密的时候需要用到密钥,中间会传递密钥,(加密和解密的密钥是同一个),密钥在传输中间是被加密的。这种方式看起来安全,但是仍有潜在的危险,一旦被窃听,或者信息被挟持,就有可能破解密钥,而破解其中的信息。因此“共享密钥加密”这种方式存在安全隐患。

- 非对称秘钥加密:“非对称加密”使用的时候有两把锁,一把叫做“私有密钥”,一把是“公开密钥”,使用非对象加密的加密方式的时候,服务器首先告诉客户端按照自己给定的公开密钥进行加密处理,客户端按照公开密钥加密以后,服务器接受到信息再通过自己的私有密钥进行解密,这样做的好处就是解密的钥匙根本就不会进行传输,因此也就避免了被挟持的风险。就算公开密钥被窃听者拿到了,它也很难进行解密,因为解密过程是对离散对数求值,这可不是轻而易举就能做到的事。以下是非对称加密的原理图:

- 但是非对称秘钥加密技术也存在如下缺点:
- 第一个是:如何保证接收端向发送端发出公开秘钥的时候,发送端确保收到的是预先要发送的,而不会被挟持。只要是发送密钥,就有可能有被挟持的风险。
- 第二个是:非对称加密的方式效率比较低,它处理起来更为复杂,通信过程中使用就有一定的效率问题而影响通信速度
- 但是非对称秘钥加密技术也存在如下缺点:
- 证书秘钥加密:在上面我们讲了非对称加密的缺点,其中第一个就是公钥很可能存在被挟持的情况,无法保证客户端收到的公开密钥就是服务器发行的公开密钥。此时就引出了公开密钥证书机制。数字证书认证机构是客户端与服务器都可信赖的第三方机构。证书的具体传播过程如下:
- 服务器的开发者携带公开密钥,向数字证书认证机构提出公开密钥的申请,数字证书认证机构在认清申请者的身份,审核通过以后,会对开发者申请的公开密钥做数字签名,然后分配这个已签名的公开密钥,并将密钥放在证书里面,绑定在一起
- 服务器将这份数字证书发送给客户端,因为客户端也认可证书机构,客户端可以通过数字证书中的数字签名来验证公钥的真伪,来确保服务器传过来的公开密钥是真实的。一般情况下,证书的数字签名是很难被伪造的,这取决于认证机构的公信力。一旦确认信息无误之后,客户端就会通过公钥对报文进行加密发送,服务器接收到以后用自己的私钥进行解密。

爬虫学习--Day3(小猿圈爬虫开发_1)的更多相关文章
- 爬虫学习--Day4(小猿圈爬虫开发_2)
requests模块 - urllib模块 - requests模块 requests模块:python中原生的一款基于网络请求的模块,功能非常强大,简单便捷,效率极高.作用:模拟浏览器发送请求. 如 ...
- 爬虫学习之基于Scrapy的爬虫自动登录
###概述 在前面两篇(爬虫学习之基于Scrapy的网络爬虫和爬虫学习之简单的网络爬虫)文章中我们通过两个实际的案例,采用不同的方式进行了内容提取.我们对网络爬虫有了一个比较初级的认识,只要发起请求获 ...
- scrapy爬虫学习系列一:scrapy爬虫环境的准备
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- Python网络爬虫学习手记(1)——爬虫基础
1.爬虫基本概念 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.--------百度百科 简单的说,爬 ...
- Scrapy爬虫学习笔记 - windows \ linux下搭建开发环境2
四.虚拟环境的安装和配置 virtualenv可以搭建虚拟且独立的python运行环境, 使得单个项目的运行环境与其它项目独立起来. virtualenv本质上是个python包 虚拟环境可以将开发环 ...
- 小猿圈-IT自学人的小圈子 【强力推荐学习】
笔记链接 https://book.apeland.cn/details/322/ 学习视频 https://www.apeland.cn/python
- Scrapy爬虫学习笔记 - windows \ linux下搭建开发环境1
一.pycharm的安装和简单使用 二.mysql和navicat的安装和使用 三.windows和linux下安装pytho ...
- Python爬虫学习==>第六章:爬虫的基本原理
学习目的: 掌握爬虫相关的基本概念 正式步骤 Step1:什么是爬虫 请求网站并提取数据的自动化程序 Step2:爬虫的基本流程 Step3:Request和Response 1.request 2. ...
- Python爬虫学习==>第五章:爬虫常用库的安装
学习目的: 爬虫有请求库(request.selenium).解析库.存储库(MongoDB.Redis).工具库,此节学习安装常用库的安装 正式步骤 Step1:urllib和re库 这两个库在安装 ...
随机推荐
- git远程分支不显示问题解决
因为项目太大,然后直接git clone拉不下来代码 会报error: RPC failed; HTTP 504 curl 22 The requested URL returned error: 5 ...
- selenium+testNG自动化测试框架搭建
自动化测试框架搭建 1 Java环境的搭建 1.1访问oracle的官网下载最新版本的jdk http://www.oracle.com/technetwork/java/javase/downloa ...
- 02-28 scikit-learn库之线朴素贝叶斯
目录 scikit-learn库之朴素贝叶斯 一.MultinomialNB 1.1 使用场景 1.2 代码 1.3 参数详解 1.4 属性 1.5 方法 二.GaussianNB 三.Bernoul ...
- Uber Go 语言编程规范
目录 Uber Go 语言编程规范 1. 介绍 2. 编程指南 3. 性能相关 4. 编程风格 5. 编程模式(Patterns) 6. 总结 Uber Go 语言编程规范 相信很多人前两天都看到 U ...
- 微信小程序前端样式WXSS书写
微信小程序前端样式WXSS书写 一. WXSS的简单介绍 WXSS(WeiXin Style Sheets)是一套样式语言,用于描述 WXML 的组件样式. 与 CSS 相比,WXSS 扩展的特性有: ...
- Ubuntu cd后自动执行ls或ll
编辑 .bashrc 文件 sudo gedit ~/.bashrc 在最后一行加入 cdAndList() { cd "${1}"; ls; } alias cd=cdAndLi ...
- C# 控件 RichTextBox 显示行号,并且与Panel相互联动
我们在使用到WINFORM窗体工作中,要求RichTextBox 加入行号: 之前有看到大牛们写的,但是太复杂繁多,而且有用双TextBox进行联动,非常不错,今天我们尝试RichTextBox +P ...
- 问题:LinkedList 是原始类型。应该将对通用类型 LinkedList<E> 的引用参数化
jdk1.5之后,引入了泛型,类似下面这种写法会出现类似警告,可以忽略, LinkedList llist = new LinkedList();也可以修改一下,指定类型 LinkedList&l ...
- UI测试之元素定位
定位方式优先级选择: ID>Name>CSS>XPath 1.使用id定位 2.使用name定位 3.使用class定位 4.使用css选择器定位 示例xml: <?xml ...
- vue入门笔记(新手入门必看)
一.什么是Vue? 1. vue为我们提供了构建用户界面的渐进式框架,让我们不再去操作dom元素,直接对数据进行操作,让程序员不再浪费时间和精力在操作dom元素上,解放了双手,程序员只需要关心业 ...