(三)分布式数据库tidb-隔离级别详解
tidb隔离级别详解:
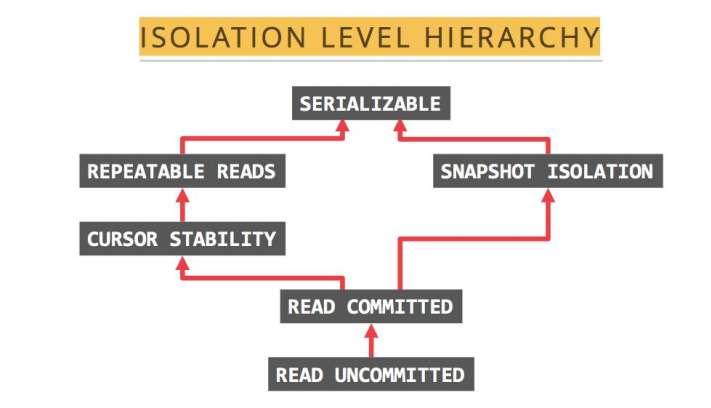
1.TiDB 支持的隔离级别是 Snapshot Isolation(SI),它和 Repeatable Read(RR) 隔离级别基本等价,详细情况如下:
| 姓名 | 值班状态 |
| 张三 | 0 |
| 李四 | 0 |
| 王五 | 0 |
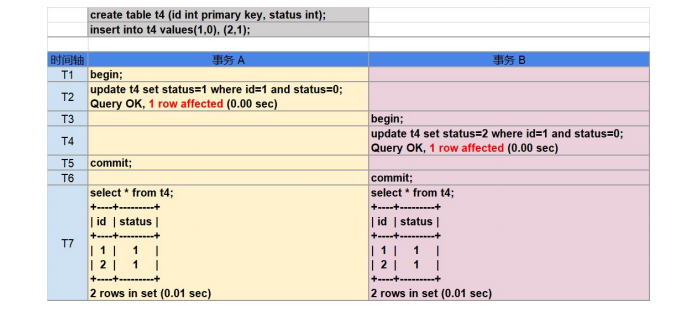
这是由于在显式执行的事务中 DML 操作与提交操作分开被执行,在事务提交过程中,如果由于事务冲突,找不到 TiKV,网络不稳定等原因而发生了重试,TiDB 将获取新的时间戳
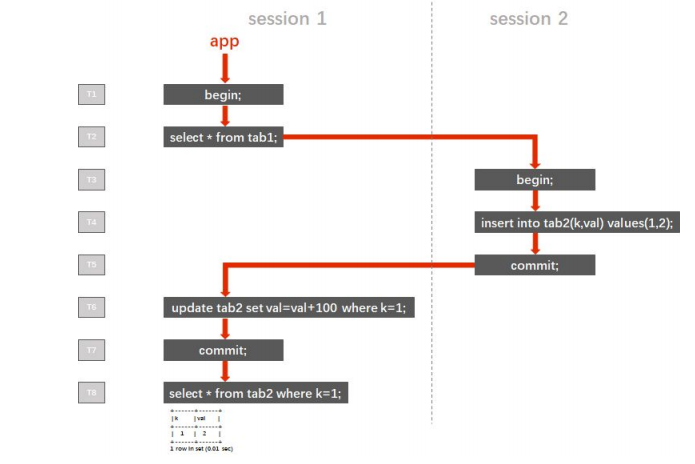
在 RC 隔离级别下,T8 时查询的返回值为 102,看上去似乎满足了“嵌套事务”的功能 需求。但实际上这是错误的,案例中仅使用单线程模拟了“嵌套事务”的场景,在实际业务的并 发请求下,多个事务在时间轴上交错执行,交错提交,将使“嵌套事务”的执行结果变得不可预 知。 在 SI 或 RR 隔离级别下,直到提交或回滚之前的任何读取(不限于 tab1 表)所返回 的结果都对应事务开始的那个瞬间的一致性状态。也就是说,在 T2 时,session 1 中的事务所能读取到的数据就已经确定了,它就像是给数据库在 T2 时的留下了一个快照,即使之后的 T3 ~ T5 开启了新的 session 2,写入数据并提交,也不会影响 T6 时 session 1 所读取到的数 据,T6 未读取到 k=1 的行,因此更新了 0 行。在 T8 时,查询的返回值为 2。在 SI 或 RR 隔 离级别下,事务间的隔离度更高了,在并发请求下,其结果也是可预期的。 在这个案例中,如果只是想实现 session 1 能够更新到 session 2 写入的数据的需求, 只需要控制程序逻辑,在 T2 时的查询语句之后添加 commit 步骤,及时提交这个查询事务, 再执行后续步骤即可。
6. 不支持 Spring 框架的 PROPAGATION_NESTED 传播行为 (依赖 savepoint 机制) Spring 支持的 PROPAGATION_NESTED 传播行为会启动一个嵌套的事务,它是当前事 务之上独立启动的一个子事务。嵌套事务开始时会记录一个 savepoint, 如果嵌套事务执行失 败,事务将会回滚到 savepoint 的状态,嵌套事务是外层事务的一部分,它将会在外层事务提 交时一起被提交。下面案例展示了 savepoint 机制:
mysql> BEGIN; mysql> INSERT INTO T2 VALUES(100);
mysql> SAVEPOINT svp1;
mysql> INSERT INTO T2 VALUES(200);
mysql> ROLLBACK TO SAVEPOINT svp1;
mysql> RELEASE SAVEPOINT svp1;
mysql> COMMIT;
mysql> SELECT * FROM T2; +------+ | ID | +------+ | 100 | +------+ TiDB
不支持 savepoint 机制,因此也不支持 PROPAGATION_NESTED 传播行为,基于 Java Spring 框架的应用如果使用了 PROPAGATION_NESTED 传播行为,需要在应用端做出调 整,将嵌套事务的逻辑移除。
7. 大事务 基于日志的数据库在面对大事务时,需要手动调大可用日志的容量,以避免日志被单 一事务占满。 TiDB 中对于事务量有着硬限制,由于 TiDB 分布式两阶段提交的要求,修改数据的大 事务可能会出现一些问题。因此,TiDB 对事务大小设置了一些限制以减少这种影响(一行数据是一个键值对,一行索引也是一个键值对,当一张表只有 2 个索引时,每 insert 一行数据 会写入 3 个键值对):
● 每个键值对不超过 6MB
● 键值对的总数不超过 300,000
● 键值对的总大小不超过 100MB 据此,涉及大量数据增删改的事务(如批量的对账事务等),需要进行缩减事务量的 改造,最佳实践是将大事务改写为分页 SQL,分段提交,TiDB 中可以利用 order by 配合 limit 的 offset 实现分页功能,写法如下:
update tab set value=’new_value’ where id in (select id from tab order by id limit 0,10000); commit;
update tab set value=’new_value’ where id in (select id from tab order by id limit 10000,10000); commit;
update tab set value=’new_value’ where id in (select id from tab order by id limit 20000,10000); commit;
(三)分布式数据库tidb-隔离级别详解的更多相关文章
- MySQL事务及隔离级别详解
MySQL事务及隔离级别详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MySQL的基本架构 MySQL的基本架构可以分为三块,即连接池,核心功能层,存储引擎层. 1> ...
- 跨时代的分布式数据库 – 阿里云DRDS详解(转)
原文章地址:https://www.csdn.net/article/a/2015-08-28/15827676 跨时代的分布式数据库 – 阿里云DRDS详解 发表于2015-08-28 18:39| ...
- MySQL四种事务隔离级别详解
本文实验的测试环境:Windows 10+cmd+MySQL5.6.36+InnoDB 一.事务的基本要素(ACID) 1.原子性(Atomicity):事务开始后所有操作,要么全部做完,要么全部不做 ...
- SqlServer事务详解(事务隔离性和隔离级别详解)
概述 不少人对于事务的使用局限于begin transaction:开始事务.commit transaction:提交事务.rollback transaction:回滚事务的初步运用. 并且知道使 ...
- SQL Server 事务隔离级别详解
标签: SQL SEERVER/MSSQL SERVER/SQL/事务隔离级别选项/设置数据库事务级别 SQL 事务隔离级别 概述 隔离级别用于决定如果控制并发用户如何读写数据的操作,同时对性能也有一 ...
- 【转】SQL Server 事务隔离级别详解
SQL 事务隔离级别 概述 隔离级别用于决定如果控制并发用户如何读写数据的操作,同时对性能也有一定的影响作用. 步骤 事务隔离级别通过影响读操作来间接地影响写操作:可以在回话级别上设置事务隔离级别也可 ...
- SQL Server-聚焦SNAPSHOT基于行版本隔离级别详解(三十)
前言 上一篇SQL Server详细讲解了隔离级别,但是对基于行版本中的SNAPSHOT隔离级别仍未完全理解,本节再详细讲解下,若有疑义或不同见解请在评论中提出,一起探讨. SNAPSHOT行版本隔离 ...
- 1031MySQL事务隔离级别详解
转自http://xm-king.iteye.com/blog/770721 SQL标准定义了4类隔离级别,包括了一些具体规则,用来限定事务内外的哪些改变是可见的,哪些是不可见的.低级别的隔离级一般支 ...
- MySQL事务隔离级别详解
原文地址:http://xm-king.iteye.com/blog/770721 SQL标准定义了4类隔离级别,包括了一些具体规则,用来限定事务内外的哪些改变是可见的,哪些是不可见的.低级别的隔离级 ...
随机推荐
- 最简单流处理引擎——Kafka Streaming简介
Kafka在0.10.0.0版本以前的定位是分布式,分区化的,带备份机制的日志提交服务.而kafka在这之前也没有提供数据处理的顾服务.大家的流处理计算主要是还是依赖于Storm,Spark Stre ...
- 第10章 文档对象模型DOM 10.2 Document类型
Document 类型 JavaScript 通过 Document 类型表示文档.在浏览器中, document 对象是 HTMLDocument (继承自 Document 类型)的一个实例,表示 ...
- odoo 恢复数据库前端报错
Could not get content for…… jQuery is not defined 原因:数据库缓存 解决方法: select id, create_date, store_fname ...
- codeforces 389 D. Fox and Minimal path(构造+思维)
题目链接:https://vjudge.net/contest/175446#problem/J 题解:显然要用最多n个点构成的图要使的得到的最短路条数有1e9次个,显然要有几个数相乘容易想到2的几进 ...
- Ryuji doesn't want to study 2018徐州icpc网络赛 树状数组
Ryuji is not a good student, and he doesn't want to study. But there are n books he should learn, ea ...
- CodeForces 601B Lipshitz Sequence
Lipshitz Sequence 题解: 可以通过观察得到,对于任意一个区间来说, 只有相邻的2个点的差值才会是区间的最大值. 具体观察方法,可以用数学分析, 我是通过画图得到的. 那么基于上面的观 ...
- CF1028D Order book 思维
Order book time limit per test 2 seconds memory limit per test 256 megabytes input standard input ou ...
- 跟我学SpringCloud | 第十七篇:服务网关Zuul基于Apollo动态路由
目录 SpringCloud系列教程 | 第十七篇:服务网关Zuul基于Apollo动态路由 Apollo概述 Apollo相比于Spring Cloud Config优势 工程实战 示例代码 Spr ...
- 201871010134-周英杰《面向对象程序设计(java)》第二周学习总结
项目 内容 这个作业属于哪个课程 https://www.cnblogs.com/nwnu-daizh/ 这个作业的要求在哪里 https://www.cnblogs.com/nwnu-daizh/p ...
- Spring的事件监听机制
最近公司在重构广告系统,其中核心的打包功能由广告系统调用,即对apk打包的调用和打包完成之后的回调,需要提供相应的接口给广告系统.因此,为了将apk打包的核心流程和对接广告系统的业务解耦,利用了spr ...