Spark学习之路(五)—— Spark运行模式与作业提交
一、作业提交
1.1 spark-submit
Spark所有模式均使用spark-submit命令提交作业,其格式如下:
./bin/spark-submit \
--class <main-class> \ # 应用程序主入口类
--master <master-url> \ # 集群的Master Url
--deploy-mode <deploy-mode> \ # 部署模式
--conf <key>=<value> \ # 可选配置
... # other options
<application-jar> \ # Jar包路径
[application-arguments] #传递给主入口类的参数
需要注意的是:在集群环境下,application-jar必须能被集群中所有节点都能访问,可以是HDFS上的路径;也可以是本地文件系统路径,如果是本地文件系统路径,则要求集群中每一个机器节点上的相同路径都存在该Jar包。
1.2 deploy-mode
deploy-mode有cluster和client两个可选参数,默认为client。这里以Spark On Yarn模式对两者的区别进行说明 :
- 在cluster模式下,Spark Drvier在应用程序的Master进程内运行,该进程由群集上的YARN管理,提交作业的客户端可以在启动应用程序后关闭;
- 在client模式下,Spark Drvier在提交作业的客户端进程中运行,Master进程仅用于从YARN请求资源。
1.3 master-url
master-url的所有可选参数如下表所示:
| Master URL | Meaning |
|---|---|
local |
使用一个线程本地运行Spark |
local[K] |
使用 K 个 worker 线程本地运行 Spark |
local[K,F] |
使用 K 个 worker 线程本地运行 , 第二个参数为Task的失败重试次数 |
local[*] |
使用与CPU核心数一样的线程数在本地运行Spark |
local[*,F] |
使用与CPU核心数一样的线程数在本地运行Spark 第二个参数为Task的失败重试次数 |
spark://HOST:PORT |
连接至指定的 standalone 集群的 master 节点。端口号默认是 7077。 |
spark://HOST1:PORT1,HOST2:PORT2 |
如果standalone集群采用Zookeeper实现高可用,则必须包含由zookeeper设置的所有master主机地址。 |
mesos://HOST:PORT |
连接至给定的Mesos集群。端口默认是 5050。对于使用了 ZooKeeper 的 Mesos cluster 来说,使用 mesos://zk://...来指定地址,使用 --deploy-mode cluster模式来提交。 |
yarn |
连接至一个 YARN 集群,集群由配置的 HADOOP_CONF_DIR 或者 YARN_CONF_DIR 来决定。使用--deploy-mode参数来配置client 或cluster 模式。 |
下面主要介绍三种常用部署模式及对应的作业提交方式。
二、Local模式
Local模式下提交作业最为简单,不需要进行任何配置,提交命令如下:
# 本地模式提交应用
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
/usr/app/spark-2.4.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.4.0.jar \
100 # 传给SparkPi的参数
spark-examples_2.11-2.4.0.jar是Spark提供的测试用例包,SparkPi用于计算Pi值,执行结果如下:
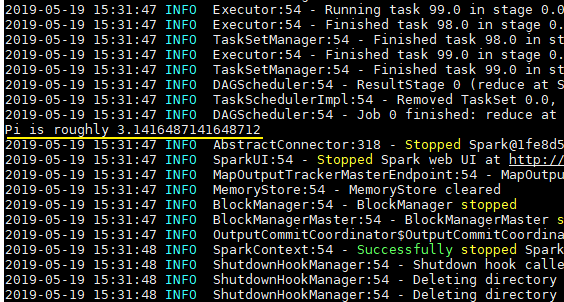
三、Standalone模式
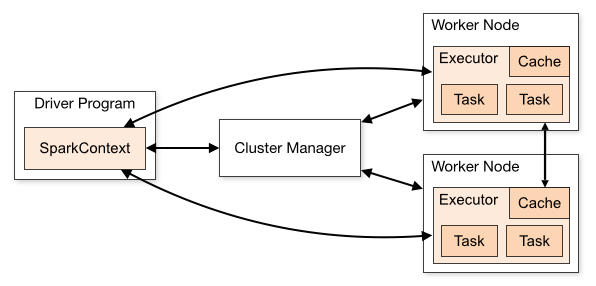
Standalone是Spark提供的一种内置的集群模式,采用内置的资源管理器进行管理。下面按照如图所示演示1个Mater和2个Worker节点的集群配置,这里使用两台主机进行演示:
- hadoop001: 由于只有两台主机,所以hadoop001既是Master节点,也是Worker节点;
- hadoop002 : Worker节点。
3.1 环境配置
首先需要保证Spark已经解压在两台主机的相同路径上。然后进入hadoop001的${SPARK_HOME}/conf/目录下,拷贝配置样本并进行相关配置:
# cp spark-env.sh.template spark-env.sh
在spark-env.sh中配置JDK的目录,完成后将该配置使用scp命令分发到hadoop002上:
# JDK安装位置
JAVA_HOME=/usr/java/jdk1.8.0_201
3.2 集群配置
在${SPARK_HOME}/conf/目录下,拷贝集群配置样本并进行相关配置:
# cp slaves.template slaves
指定所有Worker节点的主机名:
# A Spark Worker will be started on each of the machines listed below.
hadoop001
hadoop002
这里需要注意以下三点:
- 主机名与IP地址的映射必须在
/etc/hosts文件中已经配置,否则就直接使用IP地址; - 每个主机名必须独占一行;
- Spark的Master主机是通过SSH访问所有的Worker节点,所以需要预先配置免密登录。
3.3 启动
使用start-all.sh代表启动Master和所有Worker服务。
./sbin/start-master.sh
访问8080端口,查看Spark的Web-UI界面,,此时应该显示有两个有效的工作节点:
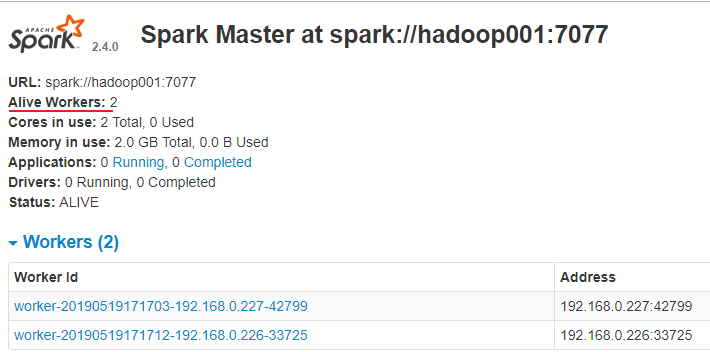
3.4 提交作业
# 以client模式提交到standalone集群
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop001:7077 \
--executor-memory 2G \
--total-executor-cores 10 \
/usr/app/spark-2.4.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.4.0.jar \
100
# 以cluster模式提交到standalone集群
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://207.184.161.138:7077 \
--deploy-mode cluster \
--supervise \ # 配置此参数代表开启监督,如果主应用程序异常退出,则自动重启Driver
--executor-memory 2G \
--total-executor-cores 10 \
/usr/app/spark-2.4.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.4.0.jar \
100
3.5 可选配置
在虚拟机上提交作业时经常出现一个的问题是作业无法申请到足够的资源:
Initial job has not accepted any resources;
check your cluster UI to ensure that workers are registered and have sufficient resources

这时候可以查看Web UI,我这里是内存空间不足:提交命令中要求作业的executor-memory是2G,但是实际的工作节点的Memory只有1G,这时候你可以修改--executor-memory,也可以修改 Woker 的Memory,其默认值为主机所有可用内存值减去1G。

关于Master和Woker节点的所有可选配置如下,可以在spark-env.sh中进行对应的配置:
| Environment Variable(环境变量) | Meaning(含义) |
|---|---|
SPARK_MASTER_HOST |
master 节点地址 |
SPARK_MASTER_PORT |
master 节点地址端口(默认:7077) |
SPARK_MASTER_WEBUI_PORT |
master 的 web UI 的端口(默认:8080) |
SPARK_MASTER_OPTS |
仅用于 master 的配置属性,格式是 “-Dx=y”(默认:none),所有属性可以参考官方文档:spark-standalone-mode |
SPARK_LOCAL_DIRS |
spark 的临时存储的目录,用于暂存map的输出和持久化存储RDDs。多个目录用逗号分隔 |
SPARK_WORKER_CORES |
spark worker节点可以使用CPU Cores的数量。(默认:全部可用) |
SPARK_WORKER_MEMORY |
spark worker节点可以使用的内存数量(默认:全部的内存减去1GB); |
SPARK_WORKER_PORT |
spark worker节点的端口(默认: random(随机)) |
SPARK_WORKER_WEBUI_PORT |
worker 的 web UI 的 Port(端口)(默认:8081) |
SPARK_WORKER_DIR |
worker运行应用程序的目录,这个目录中包含日志和暂存空间(default:SPARK_HOME/work) |
SPARK_WORKER_OPTS |
仅用于 worker 的配置属性,格式是 “-Dx=y”(默认:none)。所有属性可以参考官方文档:spark-standalone-mode |
SPARK_DAEMON_MEMORY |
分配给 spark master 和 worker 守护进程的内存。(默认: 1G) |
SPARK_DAEMON_JAVA_OPTS |
spark master 和 worker 守护进程的 JVM 选项,格式是 “-Dx=y”(默认:none) |
SPARK_PUBLIC_DNS |
spark master 和 worker 的公开 DNS 名称。(默认:none) |
三、Spark on Yarn模式
Spark支持将作业提交到Yarn上运行,此时不需要启动Master节点,也不需要启动Worker节点。
3.1 配置
在spark-env.sh中配置hadoop的配置目录的位置,可以使用YARN_CONF_DIR或HADOOP_CONF_DIR进行指定:
YARN_CONF_DIR=/usr/app/hadoop-2.6.0-cdh5.15.2/etc/hadoop
# JDK安装位置
JAVA_HOME=/usr/java/jdk1.8.0_201
3.2 启动
必须要保证Hadoop已经启动,这里包括YARN和HDFS都需要启动,因为在计算过程中Spark会使用HDFS存储临时文件,如果HDFS没有启动,则会抛出异常。
# start-yarn.sh
# start-dfs.sh
3.3 提交应用
# 以client模式提交到yarn集群
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
--executor-memory 2G \
--num-executors 10 \
/usr/app/spark-2.4.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.4.0.jar \
100
# 以cluster模式提交到yarn集群
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--executor-memory 2G \
--num-executors 10 \
/usr/app/spark-2.4.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.4.0.jar \
100
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
Spark学习之路(五)—— Spark运行模式与作业提交的更多相关文章
- Spark 系列(五)—— Spark 运行模式与作业提交
一.作业提交 1.1 spark-submit Spark 所有模式均使用 spark-submit 命令提交作业,其格式如下: ./bin/spark-submit \ --class <ma ...
- [转]Spark学习之路 (三)Spark之RDD
Spark学习之路 (三)Spark之RDD https://www.cnblogs.com/qingyunzong/p/8899715.html 目录 一.RDD的概述 1.1 什么是RDD? ...
- Spark on YARN的两种运行模式
Spark on YARN有两种运行模式,如下 1.yarn-cluster:适合于生产环境. Spark的Driver运行在ApplicationMaster中,它负责向YARN Re ...
- Spark On Yarn搭建及各运行模式说明
之前记录Yarn:Hadoop2.0之YARN组件,这次使用Docker搭建Spark On Yarn 一.各运行模式 1.单机模式 该模式被称为Local[N]模式,是用单机的多个线程来模拟Spa ...
- Spark学习(二) -- Spark整体框架
标签(空格分隔): Spark 还记得上次的wordCount程序嘛?通过这个小程序,我们来一窥Spark的框架是什么样子的. sc.textFile("/usr/local/Cellar/ ...
- 转:Windows下的PHP开发环境搭建——PHP线程安全与非线程安全、Apache版本选择,及详解五种运行模式。
原文来自于:http://www.ituring.com.cn/article/128439 Windows下的PHP开发环境搭建——PHP线程安全与非线程安全.Apache版本选择,及详解五种运行模 ...
- Spark学习笔记2(spark所需环境配置
Spark学习笔记2 配置spark所需环境 1.首先先把本地的maven的压缩包解压到本地文件夹中,安装好本地的maven客户端程序,版本没有什么要求 不需要最新版的maven客户端. 解压完成之后 ...
- PHP语言学习之php-fpm 三种运行模式
本文主要向大家介绍了PHP语言学习之php-fpm 三种运行模式,通过具体的内容向大家展示,希望对大家学习php语言有所帮助. php-fpm配置 配置文件:php-fpm.conf 开启慢日志功能的 ...
- spark学习之路1--用IDEA编写第一个基于java的程序打包,放standalone集群,client和cluster模式上运行
1,首先确保hadoop和spark已经运行.(如果是基于yarn,hdfs的需要启动hadoop,否则hadoop不需要启动). 2.打开idea,创建maven工程.编辑pom.xml文件.增加d ...
随机推荐
- Android官方教程翻译(4)——启动另一个Activity
Starting Another Activity 启动另一个Activity PREVIOUSNEXT THIS LESSON TEACHES YOU TO 这节课教你 1. Respond t ...
- Qt图片自适应窗口控件大小(使用setScaledContents)
最近在用Qt设计一个小程序,想让一幅图片自适应窗口大小,由于本人比较笨,一直找不到好方法.找到了很多方法但都会出一些小问题, 刚刚摸索出解决办法了,在些记录. 思想: 1 显示图像是用QLabel2 ...
- WPF-- 合并资源字典
原文:WPF-- 合并资源字典 1. 合并多个外部资源字典成为本地字典 语言 XAML 示例代码 <Page.Resources> <ResourceDicti ...
- 深入WPF中的图像画刷(ImageBrush)之2——ImageBrush的铺设方式
原文:深入WPF中的图像画刷(ImageBrush)之2--ImageBrush的铺设方式 ------------------------------------------------------ ...
- requireJS简单的学习门户网站
总结 requireJS.这翻译成中国"必须js".说白了就是装js文件与.如何装好了?.这是继AMD标准化的模块化装.除了AMD另一种规范称为CMD规范.跟随CMD兼容模块加载. ...
- python3实现万年历(包括公历、农历、节气、节日)
#!/usr/local/bin/python3 # coding=utf-8 # Created: 20/07/2012 # Copyright: http://www.cnblogs.com/tx ...
- python3批量查询域名是否注册
#!/usr/local/bin/python3 #coding=utf-8 import re,sys,os,random,time, base64 import urllib.parse, url ...
- MIPS之路在何方?
目前市场上还有谁想要MIPS?MIPS接下来将何去何从?如果有一家公司希望能好好地经营MIPS,应该用什么策略呢? MIPS仍然有营收来源.它还拥有ARM所没有的多执行绪技术.有人说,只要想到半导 ...
- Debian7离线升级bash漏洞—然后修复方法
### 昨天还说的传说要又一次出补丁,今天就都出来了.基本操作一致就是測试结果不一样.继续修复 Debian7 wheezy版本号的bash漏洞,例如以下操作: 1.測试是否须要升级 # env x= ...
- x86汇编指令脚本虚拟机
简介 这是一个可以直接解释执行从ida pro里面提取出来的x86汇编代码的虚拟机. 非常精简,整体架构上不能跟那些成熟的虚拟机相比,主要目标是够用.能用.轻量就行,如果觉得代码架构设计的不是很好的话 ...