爬虫 crawlSpider 分布式 增量式 提高效率
crawlSpider
作用:为了方便提取页面整个链接url,不必使用创参寻找url,通过拉链提取器,将start_urls的全部符合规则的URL地址全部取出
使用:
创建文件scrapy startproject xxx(文件名)
cd xxx
scrapy genspider -t crawl xxx www.xxx.com
运行:
scrapy crawl xxx(文件名)
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule class ChoutiSpider(CrawlSpider):
# name = 'chouti'
# # allowed_domains = ['www.xxx.com']
# start_urls = ['https://dig.chouti.com/r/scoff/hot/1']
#
# #连接提取器:
# #allow:表示的就是链接提取器提取连接的规则(正则)
# link = LinkExtractor(allow=r'/r/scoff/hot/\d+')
#
# rules = (
# #规则解析器:将链接提取器提取到的连接所对应的页面数据进行指定形式的解析
# Rule(link, callback='parse_item', follow=True),
# # 让连接提取器继续作用到链接提取器提取到的连接所对应的页面中
# )
#
# def parse_item(self, response):
# print(response) name = 'qiubai'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.qiushibaike.com/pic/'] # 连接提取器:
# allow:表示的就是链接提取器提取连接的规则(正则)/pic/page/3?s=5172496
link = LinkExtractor(allow=r'/pic/page/\d+\?s=\d+')
link1 = LinkExtractor(allow=r'/pic/$')
# link1 = LinkExtractor(allow=r'')
rules = (
# 规则解析器:将链接提取器提取到的连接所对应的页面数据进行指定形式的解析
Rule(link, callback='parse_item', follow=True),
# 让连接提取器继续作用到链接提取器提取到的连接所对应的页面中 Rule(link1, callback='parse_item', follow=True),
) def parse_item(self, response):
print(response)
分布式
作用:为了进行多台机器一起进行爬取数据,倘若单纯使用继承原生的scrapy的话,有两个问题无法解决
- 调度器不能被共享 (你不知道这条url有没有被爬取)
- 管道无法被共享 (获取的数据不在同一个存储的数据库中)
使用分布式的scrapy-redis组件会为我们提供什么:
- 提供了可以被共享的调度器和管道
为什么分布式没有初始start_urls
- 因为是多台电脑操作,无法将start_urls 初始到哪一个主机上,所以在redis 是输入 url ,哪个主机抢到了算那个
- 分布式爬虫实现流程
1.环境安装:pip install scrapy-redis
2.创建工程
3.创建爬虫文件:RedisCrawlSpider RedisSpider
- scrapy genspider -t crawl xxx www.xxx.com
4.对爬虫文件中的相关属性进行修改:
- 导报:from scrapy_redis.spiders import RedisCrawlSpider
- 将当前爬虫文件的父类设置成RedisCrawlSpider
- 将起始url列表替换成redis_key = 'xxx'(调度器队列的名称)
5.在配置文件中进行配置:
- 使用组件中封装好的可以被共享的管道类:
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 400
}
- 配置调度器(使用组件中封装好的可以被共享的调度器)
# 增加了一个去重容器类的配置, 作用使用Redis的set集合来存储请求的指纹数据, 从而实现请求去重的持久化
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 使用scrapy-redis组件自己的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 配置调度器是否要持久化, 也就是当爬虫结束了, 要不要清空Redis中请求队列和去重指纹的set。如果是True, 就表示要持久化存储, 就不清空数据, 否则清空数据
SCHEDULER_PERSIST = True
- 指定存储数据的redis:
REDIS_HOST = 'redis服务的ip地址'
REDIS_PORT = 6379
- 配置redis数据库的配置文件
- 取消保护模式:protected-mode no #50多行
- bind绑定: #bind 127.0.0.1 #70多行
- 启动redis
6.执行分布式程序
scrapy runspider xxx.py
7.向调度器队列中仍入一个起始url:
在redis-cli中执行:
lpsuh xxx(文件名) https://www.baidu.com #启动公共的url
lrange xxx:items 0 -1 #查看数据
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy_redis.spiders import RedisCrawlSpider
from redisChoutiPro.items import RedischoutiproItem
class ChoutiSpider(RedisCrawlSpider):
name = 'chouti'
# allowed_domains = ['www.xxx.com']
# start_urls = ['http://www.xxx.com/']
redis_key = 'chouti'#调度器队列的名称
rules = (
Rule(LinkExtractor(allow=r'/all/hot/recent/\d+'), callback='parse_item', follow=True),
) def parse_item(self, response):
div_list = response.xpath('//div[@class="item"]')
for div in div_list:
title = div.xpath('./div[4]/div[1]/a/text()').extract_first()
author = div.xpath('./div[4]/div[2]/a[4]/b/text()').extract_first()
item = RedischoutiproItem()
item['title'] = title
item['author'] = author yield item
setting配置
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 400
}
# 增加了一个去重容器类的配置, 作用使用Redis的set集合来存储请求的指纹数据, 从而实现请求去重的持久化
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 使用scrapy-redis组件自己的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 配置调度器是否要持久化, 也就是当爬虫结束了, 要不要清空Redis中请求队列和去重指纹的set。如果是True, 就表示要持久化存储, 就不清空数据, 否则清空数据
SCHEDULER_PERSIST = True #数据指纹
REDIS_HOST = '127.0.0.1'
REDIS_PORT = 6379
最后启动项目:
scrapy runspider xxx
在进行redis 的传入 url 的操作
增量式
作用:进行爬取数据时,为了避免爬取重复的数据而产生的
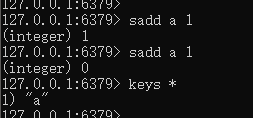
增量式的核心,利用sadd判断是否爬取数据了
sadd xx(文件名) 1
print(1)
sadd xx(文件名) 1
print(0)
继续用到crawlSpider来创建文件
关于url 使用sadd 作为判断
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from redis import Redis
from increment1_Pro.items import Increment1ProItem
class MovieSpider(CrawlSpider):
name = 'movie'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.4567tv.tv/index.php/vod/show/id/7.html'] rules = (
Rule(LinkExtractor(allow=r'/index.php/vod/show/id/7/page/\d+\.html'), callback='parse_item', follow=True),
) def parse_item(self, response):
conn = Redis(host='127.0.0.1',port=6379)
detail_url_list = 'https://www.4567tv.tv'+response.xpath('//li[@class="col-md-6 col-sm-4 col-xs-3"]/div/a/@href').extract()
for url in detail_url_list:
#ex == 1:set中没有存储url
ex = conn.sadd('movies_url',url)
if ex == 1:
yield scrapy.Request(url=url,callback=self.parse_detail)
else:
print('网站没有更新数据,暂无新数据可爬!') def parse_detail(self,response):
item = Increment1ProItem()
item['name'] = response.xpath('/html/body/div[1]/div/div/div/div[2]/h1/text()').extract_first()
item['actor'] = response.xpath('/html/body/div[1]/div/div/div/div[2]/p[3]/a/text()').extract_first() yield item
items.py
import scrapy class Increment1ProItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
actor = scrapy.Field()
pipelines.py
from redis import Redis
class Increment1ProPipeline(object):
conn = None
def open_spider(self,spider):
self.conn = Redis(host='127.0.0.1',port=6379)
def process_item(self, item, spider):
# dic = {
# 'name':item['name'],
# 'axtor':item['actor']
# }
print('有新数据被爬取到,正在入库......')
self.conn.lpush('movie_data',item)
return item
setting 配置user-agent 和 robot = False
关于文件内容基于sadd 的判断
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule from increment2_Pro.items import Increment2ProItem
from redis import Redis
import hashlib
class QiubaiSpider(CrawlSpider):
name = 'qiubai'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.qiushibaike.com/text/'] rules = (
Rule(LinkExtractor(allow=r'/text/page/\d+/'), callback='parse_item', follow=True),
) def parse_item(self, response): div_list = response.xpath('//div[@class="article block untagged mb15 typs_hot"]')
conn = Redis(host='127.0.0.1',port=6379)
for div in div_list:
item = Increment2ProItem()
item['content'] = div.xpath('.//div[@class="content"]/span//text()').extract()
item['content'] = ''.join(item['content'])
item['author'] = div.xpath('./div/a[2]/h2/text() | ./div[1]/span[2]/h2/text()').extract_first()
source = item['author']+item['content']
#自己制定了一种形式的数据指纹
hashValue = hashlib.sha256(source.encode()).hexdigest() ex = conn.sadd('qiubai_hash',hashValue)
if ex == 1:
yield item
else:
print('没有更新数据可爬!!!')
剩下的都一样
如何提高爬虫效率
增加并发:
默认scrapy开启的并发线程为32个,可以适当进行增加。在settings配置文件中修改CONCURRENT_REQUESTS = 100值为100,并发设置成了为100。
降低日志级别:
在运行scrapy时,会有大量日志信息的输出,为了减少CPU的使用率。可以设置log输出信息为INFO或者ERROR即可。在配置文件中编写:LOG_LEVEL = ‘INFO’
禁止cookie:
如果不是真的需要cookie,则在scrapy爬取数据时可以进制cookie从而减少CPU的使用率,提升爬取效率。在配置文件中编写:COOKIES_ENABLED = False
禁止重试:
对失败的HTTP进行重新请求(重试)会减慢爬取速度,因此可以禁止重试。在配置文件中编写:RETRY_ENABLED = False
减少下载超时:
如果对一个非常慢的链接进行爬取,减少下载超时可以能让卡住的链接快速被放弃,从而提升效率。在配置文件中进行编写:DOWNLOAD_TIMEOUT = 10 超时时间为10s爬虫 crawlSpider 分布式 增量式 提高效率的更多相关文章
- python爬虫---CrawlSpider实现的全站数据的爬取,分布式,增量式,所有的反爬机制
CrawlSpider实现的全站数据的爬取 新建一个工程 cd 工程 创建爬虫文件:scrapy genspider -t crawl spiderName www.xxx.com 连接提取器Link ...
- 爬虫07 /scrapy图片爬取、中间件、selenium在scrapy中的应用、CrawlSpider、分布式、增量式
爬虫07 /scrapy图片爬取.中间件.selenium在scrapy中的应用.CrawlSpider.分布式.增量式 目录 爬虫07 /scrapy图片爬取.中间件.selenium在scrapy ...
- 爬虫---scrapy分布式和增量式
分布式 概念: 需要搭建一个分布式的机群, 然后在每一台电脑中执行同一组程序, 让其对某一网站的数据进行联合分布爬取. 原生的scrapy框架不能实现分布式的原因 调度器不能被共享, 管道也不能被共享 ...
- Scrapy 增量式爬虫
Scrapy 增量式爬虫 https://blog.csdn.net/mygodit/article/details/83931009 https://blog.csdn.net/mygodit/ar ...
- 基于Scrapy框架的增量式爬虫
概述 概念:监测 核心技术:去重 基于 redis 的一个去重 适合使用增量式的网站: 基于深度爬取的 对爬取过的页面url进行一个记录(记录表) 基于非深度爬取的 记录表:爬取过的数据对应的数据指纹 ...
- Python爬虫教程-34-分布式爬虫介绍
Python爬虫教程-34-分布式爬虫介绍 分布式爬虫在实际应用中还算是多的,本篇简单介绍一下分布式爬虫 什么是分布式爬虫 分布式爬虫就是多台计算机上都安装爬虫程序,重点是联合采集.单机爬虫就是只在一 ...
- Java 多线程爬虫及分布式爬虫架构探索
这是 Java 爬虫系列博文的第五篇,在上一篇 Java 爬虫服务器被屏蔽,不要慌,咱们换一台服务器 中,我们简单的聊反爬虫策略和反反爬虫方法,主要针对的是 IP 被封及其对应办法.前面几篇文章我们把 ...
- Java 多线程爬虫及分布式爬虫架构
这是 Java 爬虫系列博文的第五篇,在上一篇 Java 爬虫服务器被屏蔽,不要慌,咱们换一台服务器 中,我们简单的聊反爬虫策略和反反爬虫方法,主要针对的是 IP 被封及其对应办法.前面几篇文章我们把 ...
- 增量式PID简单翻板角度控制
1.研究背景 随着电子技术.信息技术和自动控制理论技术的完善与发展,近来微型处理器在控制方面的应用也越来越多.随之逐渐渗透到我们生活的各个领域.如导弹导航装置,飞机上仪表的控制,网络通讯与数据传输,工 ...
随机推荐
- mssql sqlserver text、image字段类型无法使用DISTINCT的处理方法分享
转自: http://www.maomao365.com/?p=9775 摘要: 下文简述sqlserver数据库中 text image类型无法使用distinct的处理方法分享 实验环境:sql ...
- docker swarm 删除节点
有时临时在 docker swarm 集群上增加节点,过后需要删除节点 # 获取 node 信息 docker node ls ID HOSTNAME STATUS AVAILABILITY MANA ...
- ubuntu 桌面版, ssh 连接时使用,x转发进行使用 gnome-terminal 时出现:Error calling StartServiceByName for org.gnome.Terminal: Timeout was reached 错误
当我按照这种情景使用时,出现了这种情况: 考虑着 gnome 桌面正在运行,可能是gnome-terminal 使用了工厂模式进行创建:查找gnome-terminal 文档,有如下解决方案: gno ...
- android 获得一些设备信息的静态函数
1.Brand,IMEI,DeviceOS,DeviceFactoryTime public static String getDeviceBrand(Context context) { Strin ...
- go语言设计模式之Strategy
package main import ( "flag" "fmt" "image" "image/color" &qu ...
- WPF 绑定属性 XAML 时间格式化
原文:WPF 绑定属性 XAML 时间格式化 XAML 时间格式化{Binding Birthday,StringFormat='yyyy-MM-dd '} public class AssetCla ...
- Linux 的 Crond(二)
最近由于工作中用到了crond,之前对crond不是很了解,只知道咋用,但是这次需要考虑好多情况,所以又深入了解了一下crond,下面就以下几个问题来谈谈crond. crond 中指定的job,如果 ...
- Istio修改IngressGateway网络类型
ingressgateway的默认网络类型是LoadBanlancer,在没有外部负载均衡的情况下可以修改为NodePort. 1.修改 kubectl patch service istio-ing ...
- SVO 特征对齐代码分析
SVO稀疏图像对齐之后使用特征对齐,即通过地图向当前帧投影,并使用逆向组合光流以稀疏图像对齐的结果为初始值,得到更精确的特征位置. 主要涉及文件: reprojector.cpp matcher.cp ...
- 内核态发生非法地址访问是否会panic
https://mp.weixin.qq.com/s?__biz=MzAwMDUwNDgxOA==&mid=2652663676&idx=1&sn=b18ab57322594e ...