netty源码解解析(4.0)-25 ByteBuf内存池:PoolArena-PoolChunk
PoolArena实现了用于高效分配和释放内存,并尽可能减少内存碎片的内存池,这个内存管理实现使用PageRun/PoolSubpage算法。分析代码之前,先熟悉一些重要的概念:
- page: 页,一个页是可分配的最小的内存块单元,页的大小:pageSize = 1 << n (n <= 12)。
- chunk: 块,块是多个页的集合。chunkSize是块中所有page的pageSize之和。
- Tiny: <512B的内存块。
- Small: >=512B, <pageSize的内存块。
- Normal: >=pageSize, <=chunkSize的内存块。
- Huge: >chunkSize的内存块。
PoolArena维护了一个PoolChunkList组成的双向链表,每个PoolChunkList内部维护了一个PoolChunk双向链表。分配内存时,PoolArena通过在PoolChunkList找到一个合适的PoolChunk,然后从PoolChunk中分配一块内存。
关键属性
pageSize: page的大小。必须满足 pageSize = 1 << n (n>=12)。
maxOrder: 完全平衡二叉树的高度。
chunkSize: chunk的大小。chunkSize = pageSize * (1 << maxOrder)。
memory: chunk的内存,大小必须>=chunkSize。
offset: chunk内存在memory中的起始位置。 memory大小必须>=offet+chunkSize。
page管理
chunk以完全平衡二叉树的数据结构管理page, 这颗树的节点以堆的方式保存在数组中, 如果这棵树的高度maxOrder=4, 它的结构如下图所示:
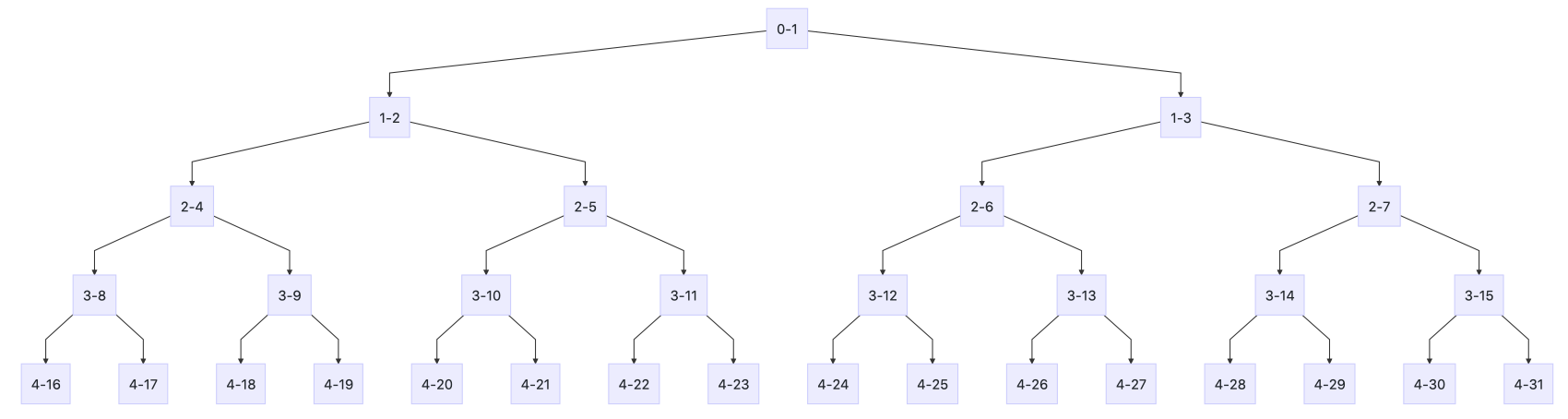
图-1
节点名字格式是d-i, d是节点在树中的深度,i是节点在数组中的索引。
它有如下一些性质:
- 任意一个节点i, i的取值范围是: [1, 1 << (maxOrder + 1) )。i == 1节点是根节点。
- 如果节点i在区间[1 << maxOrder,1 << (maxOrder +1) ), 那么这些节点都是叶节点。
- 除叶节点以外的节点i, i << 1是它的左子节点,(i << 1) + 1 是它的右子节点。除根节点以外的节点i, i >> 1是它的父节点, i ^ 1是它的另外一个兄弟节点。
- 对于一个节点i, 它树中的深度d = log2(i) (d是整数)。 d相同的节点位于树中的同一层上,他们包含相同的页节点数,有相同的最大可分配内存。
- 任意节点i, 深度为d, 如果把同一层的节点放在一个单独的数组中,那么节点i在这个数据组中的偏移量doffset=i ^ (1 << d)。
- 任意节点i, 深度为d, 它包含的页节点的数量是1 << (maxOrder - d), 内存大小是(1 << (maxOrder - d)) * pageSize。
- 已知深度d, [1 << d, 1 << (d + 1) )区间内的所有节点的深度都是d。
- 任意节点i, 深度d,在memory中的起始位置偏移量是offset + (1 ^ (1 << d) * (1 << (maxOrder - d)) * pageSize。
请记住这些性质。PoolChunk的代码很简洁,可是如果不熟悉这些性质,这些简洁的代码也会难以理解。
完全平衡二叉树的初始化
PoolChunk(PoolArena<T> arena, T memory, int pageSize, int maxOrder, int pageShifts, int chunkSize, int offset) {
unpooled = false;
this.arena = arena;
this.memory = memory;
this.pageSize = pageSize;
this.pageShifts = pageShifts;
this.maxOrder = maxOrder;
this.chunkSize = chunkSize;
this.offset = offset;
unusable = (byte) (maxOrder + 1);
log2ChunkSize = log2(chunkSize);
subpageOverflowMask = ~(pageSize - 1);
freeBytes = chunkSize;
assert maxOrder < 30 : "maxOrder should be < 30, but is: " + maxOrder;
maxSubpageAllocs = 1 << maxOrder;
// Generate the memory map.
memoryMap = new byte[maxSubpageAllocs << 1];
depthMap = new byte[memoryMap.length];
int memoryMapIndex = 1;
for (int d = 0; d <= maxOrder; ++ d) { // move down the tree one level at a time
int depth = 1 << d;
for (int p = 0; p < depth; ++ p) {
// in each level traverse left to right and set value to the depth of subtree
memoryMap[memoryMapIndex] = (byte) d;
depthMap[memoryMapIndex] = (byte) d;
memoryMapIndex ++;
}
}
subpages = newSubpageArray(maxSubpageAllocs);
}
在构造方法中,19-30行初始化了两棵完全一样的完全平衡二叉树(形如图-1): memoryMap, depthMap。这两个map都是以数组的方式保存二叉树,数组的长度都是maxSubpageAllocs << 1, 由于maxSubpageAllocs = 1 << maxOrder, 因此长度还可以表示为 1 << (maxOrder + 1)。 map数组的0项保留,[1, 1 << maxOrder)区间中的每个项是二叉树的一个节点,每个项的值是节点在树中的深度。
depthMap用来记录每个节点在树中的深度,初始化之后,值不会发生变化。已知一个节点在数组中的索引id, 可以使用这个id查找节点在树中的深度: depthMap[id]。
memoryMap用来记录树中节点被分配出去的情况,每个项的值会随着节点分配情况变化而变化。已知一个节点在数组中的索引id,memoryMap[id]的值会有三中情况:
- memoryMap[id] == depth[id]: 所有子节点都没被分配出去。
- memoryMap[id] > depth[id]: 至少有一个子节点被分配出去了, 还有可以分配的子节点。
- memoryMap[id] == maxOrder + 1: 这个节点以及完全被分配出去了,没有可分配的子节点了。
从二叉树中分配一个内存大小合适的节点
long allocate(int normCapacity) {
if ((normCapacity & subpageOverflowMask) != 0) { // >= pageSize
return allocateRun(normCapacity);
} else {
return allocateSubpage(normCapacity);
}
}
这个方法是分配内存节点的入口方法,参数normCapacity必须满足normCapacity = 1 << n。第2行判断normCapacity和pageSize的大小关系,在前面的构造方法中,subpageOverflowMask = ~(pageSize - 1), 如果pageSize=2048, subpageOverflowMask的0-11位是0, 12-31位是1,它的二进制值是: 1111111111111111111100000000000, (normCapacity & subpageOverflowMask) != 0表示,normCapacity的12-31位中至少有一位是1,此时它>=pageSize, 反之比pageSize小。
如果normCapacity >= pageSize, 调用allocateRun分配一个深度d < maxOrder的节点。
如果normaCapacity < pageSize, 调用allocateSubpage分配一个d == maxOrder的叶叶节点, 即一个page。
PoolChunk分配内存的最小单元是一个page,不能分配比一个page更小的内存了。
private long allocateRun(int normCapacity) {
int d = maxOrder - (log2(normCapacity) - pageShifts);
int id = allocateNode(d);
if (id < 0) {
return id;
}
freeBytes -= runLength(id);
return id;
}
第2行,计算normCapacity大小的内存在二叉树的最大深度d, 只有深度<=d的节点才有可以分配到>=normCapacity的内存。normCapacity可以表示为normCapacity = 2k, log2(normCapacity)就是已知normCapacity求解k。pageShifts可表示为pageSize = 2pageShifts, pageShifts = log2(pageSize)。 normCapacity在二叉树上的反向深度 rd = log2(mormCapacity) - pageShifts, 这个表达式比较难以理解,这样会更加直观一些:
pageCount = normCapacity >> log2(pageSize)
rd = log2(pageCount)
pageCount是normCapacity需要的page数量。 反向深度的含义是,d=0对应二叉树的最大深度maxOrder, d=1对应maxOrder -1,依次类推。因此maxOrder - rd会得到最大深度d,d <= maxOrder。
第3行,如果能够根据d找到一个合适的节点,就会把这个节点记录为已经使用的状态,然后返回这个节点的索引id, id的取值区间是[0, 1 << maxOrder)。
第7行,重新计算剩余内存数。
rungLength方法用于计算节点id的内存长度:
private int runLength(int id) {
// represents the size in #bytes supported by node 'id' in the tree
return 1 << log2ChunkSize - depth(id);
}
log2ChunkSize=log2(chunkSize)在构造方法中初始化。 有性质(6)可以得到节点id的长度 length = (1 << maxOrder - depth(id)) * pageSize,它和代码中表达式是等价的,推导过程如下:
已知:
log2ChunkSize = log2(chunkSize)
chunkSize = (1 << maxOrder) * pageSize
pageSize = 2k = 1 << k
=> chunkSize = (1 << maxOrder) * 2k
= 2maxOrder * 2k
= 2maxOrder + k
=> log2ChunkSize = log2(chunkSize)
= log2(2maxOrder + k)
= maxOrder + k
=> log2ChunkSize - depth(id) = maxOrder + k - depth(id)
=> 1 << log2ChunkSize - depth(id) = 1 << maxOrder + k - depth(id)
= (1 << maxOrder - depth(id)) * (1 << k)
= (1 << maxOrder - depth(id)) * pageSize
如果需要的内存>=pageSize, 就会调用allocateNode方法,这个方法的作用是从二叉树中分配一个节点,返回值id是这个节点的索引。
private int allocateNode(int d) {
int id = 1;
int initial = - (1 << d); // has last d bits = 0 and rest all = 1
byte val = value(id);
if (val > d) { // unusable
return -1;
}
while (val < d || (id & initial) == 0) { // id & initial == 1 << d for all ids at depth d, for < d it is 0
id <<= 1;
val = value(id);
if (val > d) {
id ^= 1;
val = value(id);
}
}
byte value = value(id);
assert value == d && (id & initial) == 1 << d : String.format("val = %d, id & initial = %d, d = %d",
value, id & initial, d);
setValue(id, unusable); // mark as unusable
updateParentsAlloc(id);
return id;
}
allocateNode方法的功能是从memoryMap树中深度[1, d]的节点中找出一个没有被分配出去的节点,然后把这个节点记录为已分配的状态。寻找顺序是自上而下,从左到到右。
第2行,从第一个节点开始,这个节点是二叉树的根节点。
第3行,计算一个32位initial,它的[0, d)位都是0,[d, 31]位都是1。
第4-6行,检查是否可以分配一个深度<=d节点, 如果不能分配内存失败,返回-1。 val == maxOrder + 1时表示这个节点的内存已经被分配完了,val在[0, maxOrder]区间内时,表示可以分配一个深度在[val, maxOder]区间内的节点。所以在第5行检查到val>d时表示不能分配到内存了。
8-15行,能够运行到第8行,说明在这个chunk中,二叉树中一定至少有一个节点满足深度等于d, 且没有任何子节点被分配出去的节点。循环,满足 val < d或(id & initial) == 0会增加一个深度继续寻找。也就是说如果满足val == d 且 (id & initial) == 1时,表示找到了符合调条件的节点了。第9行,增加一个深度。 第10,11行检查左节点。 12,13行检查右节点。
19行, 把选中的节点id, 设置成unusable(maxOrder+1)状态。
20行,更新所有父节点的值。
这个方法展示了已知memoryMap中索引为id的值val = memoryMap[id], 找到一个深度为d的空闲节点的算法。前面已经讲过val值的三种情况,其中第2中情况的时候,表示只有节点id下面只能找到深度>=val的空闲节点,索引d<val情况下,无法找到满足深度等于d的空闲节点。影响memoryMapy[id]值的算法在updateParentsAlloc中实现:
private void updateParentsAlloc(int id) {
while (id > 1) {
int parentId = id >>> 1;
byte val1 = value(id);
byte val2 = value(id ^ 1);
byte val = val1 < val2 ? val1 : val2;
setValue(parentId, val);
id = parentId;
}
}
3行,得到id的父节点。
4-6行,取memoryMap中,取节点id和它的兄弟节点的值中交小的一个,如果相等的话就随意取一个。
7行,把上一步中的取值设置到父节点上。
8,2行,深度减1,重复这个过程直到根节点为止。
分配一个小于pageSize的子页subpage
当需要分配的内存小于pageSize时,仍然会分配一个page,因为PoolChunk能分配的最小内存单元是一个page。这时候只需分配一个也节点就可以了。
private long allocateSubpage(int normCapacity) {
// Obtain the head of the PoolSubPage pool that is owned by the PoolArena and synchronize on it.
// This is need as we may add it back and so alter the linked-list structure.
PoolSubpage<T> head = arena.findSubpagePoolHead(normCapacity);
synchronized (head) {
int d = maxOrder; // subpages are only be allocated from pages i.e., leaves
int id = allocateNode(d);
if (id < 0) {
return id;
}
final PoolSubpage<T>[] subpages = this.subpages;
final int pageSize = this.pageSize;
freeBytes -= pageSize;
int subpageIdx = subpageIdx(id);
PoolSubpage<T> subpage = subpages[subpageIdx];
if (subpage == null) {
subpage = new PoolSubpage<T>(head, this, id, runOffset(id), pageSize, normCapacity);
subpages[subpageIdx] = subpage;
} else {
subpage.init(head, normCapacity);
}
return subpage.allocate();
}
}
6-10行,分配一个深度d=maxOrder的叶节点。
17,18行,从subpages取出一个PoolSubpage缓存。subpages在构造方法中初始化,subpages = new PoolSubpage[maxSubpageAllocs], maxSubpageAllocs = 1 << maxOrder。subpages的长度就是chunk中的page数量。
19-24行,如果缓存中没有,创建一个新的。如果有直接初始PoolSubpage。
25行,分配一个子页。
关于PoolSubpage子页面管理的功能,后面会详细分析,这里只涉及和PoolChunk相关的内容。
释放内存
分配内存成功后会返回一个long型的handle,64位的handle被分为两部分,[0, 32)位是二叉树中的节点索引,可以使用memoryMapIdx(handle)方法取出。[32, 64)位是PoolSubpage中子页面的索引,可以使用bitMapIdx(handler)方法取出。释放一个handle时,可能需要同时释放二叉树中的节点和PoolSubpage中子页面,free(int handle)方法实现了这个内存释放过程:
void free(long handle) {
int memoryMapIdx = memoryMapIdx(handle);
int bitmapIdx = bitmapIdx(handle);
if (bitmapIdx != 0) { // free a subpage
PoolSubpage<T> subpage = subpages[subpageIdx(memoryMapIdx)];
assert subpage != null && subpage.doNotDestroy;
// Obtain the head of the PoolSubPage pool that is owned by the PoolArena and synchronize on it.
// This is need as we may add it back and so alter the linked-list structure.
PoolSubpage<T> head = arena.findSubpagePoolHead(subpage.elemSize);
synchronized (head) {
if (subpage.free(head, bitmapIdx & 0x3FFFFFFF)) {
return;
}
}
}
freeBytes += runLength(memoryMapIdx);
setValue(memoryMapIdx, depth(memoryMapIdx));
updateParentsFree(memoryMapIdx);
}
2,3行,分别取出二叉树的节点id和PoolSubpage中子页的id。
5-17行,释放PoolSubpage子页。子页内存被释放之后,subpages数组中仍然保存着PoolSubpages对象。13行只有subpage中所有的子页都释放完了才会释放subpage持有的page。
18-20行,释放二叉树中的节点。调用setValue把被释放的节点memoryMap值设置成它原本的深度depth(memoryMapIdx)。 调用updateParentsFree, 修改memoryMap记录,这个方法实现了updateParentsAlloc的逆过程。
updateParentsFree释放二叉树节点的关键,如果一个节点被释放,它的父节点在memoryMap值可能会发生变化。这个方法的实现如下:
private void updateParentsFree(int id) {
int logChild = depth(id) + 1;
while (id > 1) {
int parentId = id >>> 1;
byte val1 = value(id);
byte val2 = value(id ^ 1);
logChild -= 1; // in first iteration equals log, subsequently reduce 1 from logChild as we traverse up
if (val1 == logChild && val2 == logChild) {
setValue(parentId, (byte) (logChild - 1));
} else {
byte val = val1 < val2 ? val1 : val2;
setValue(parentId, val);
}
id = parentId;
}
}
第2行,计算节点id的子节点深度logChild。
第3行,确保id不是根节点。
第4行,得到父节点id。
第5,6行,得到节点id及其兄弟节点memoryMap值: val1, val2。
第7行,把logChild变成id的深度。
第9,10行, 如果id及其兄弟节点的指定都是depth(id),表示这两个节都已经完全释放,把父节点的指定还原成depth(parentId) == logChild -1 。
第12,13行,如果id及其兄弟节点至少有一个没有完全释放,把较小的值设置到父节点上。
第16行,深度上移,继续上面的过程。
使用分配的内存初始化PooledByteBuf
使用allocate分配内存得到一个handle之后,需要调用PooledByteBuf的init方法使用handle对应的内存初始化。初始化的关键是计算出handle对应的内存在memory中的偏移量和长度。前面讲的lenthRun可以计算出内存的长度,剩下的就是计算内存偏移量方法runOffset。PoolChunk的initBuf方法用来初始化一个PooledByteBuf对象:
void initBuf(PooledByteBuf<T> buf, long handle, int reqCapacity) {
int memoryMapIdx = memoryMapIdx(handle);
int bitmapIdx = bitmapIdx(handle);
if (bitmapIdx == 0) {
byte val = value(memoryMapIdx);
assert val == unusable : String.valueOf(val);
buf.init(this, handle, runOffset(memoryMapIdx) + offset, reqCapacity, runLength(memoryMapIdx),
arena.parent.threadCache());
} else {
initBufWithSubpage(buf, handle, bitmapIdx, reqCapacity);
}
}
第2,3行,在分析free代码中解释过。
第4-8行,表示这块内存是二叉树中的一个节点,直接使用init方法初始化。runOffset的算法是 (memoryMapIdx ^ 1 << depth(memoryMapIdx)) * runLength(memoryMapIdx), 根据性质(5)可知,memoryMapIdx ^ depth(memoryMapIdx) 是节点memoryMepIdx在深度为depth(memoryMapIdx)层上的偏移量doffset, 即这一层前面还有doffset个节点,根据性质(4)可知每个节点的内存大小是runLength(memoryMapIdx),所以doffset * runLength(memoryMapIdx)是节点memoryMapIdx在chunk内存上的偏移量。最后还要再加上一个offset,它是chuk在memory上的偏移量。
第10行,表示这块内存是一个subpage,使用initBufWithSubpage初始化。
void initBufWithSubpage(PooledByteBuf<T> buf, long handle, int reqCapacity) {
initBufWithSubpage(buf, handle, bitmapIdx(handle), reqCapacity);
}
private void initBufWithSubpage(PooledByteBuf<T> buf, long handle, int bitmapIdx, int reqCapacity) {
assert bitmapIdx != 0;
int memoryMapIdx = memoryMapIdx(handle);
PoolSubpage<T> subpage = subpages[subpageIdx(memoryMapIdx)];
assert subpage.doNotDestroy;
assert reqCapacity <= subpage.elemSize;
buf.init(
this, handle,
runOffset(memoryMapIdx) + (bitmapIdx & 0x3FFFFFFF) * subpage.elemSize + offset,
reqCapacity, subpage.elemSize, arena.parent.threadCache());
}
关键部分在第二个重载方法。的第14-17行。这个计算内存偏移量的算法是runOffst(memoryMapIdx) + offset + (bitmapIdx & 0x3FFFFFFF) * subpage.elemSize,它可以拆分成两部分:
memoryMapIdx表示的page在内存中的偏移量pageOffset = runOffset(memoryMapIdx) + offset
子页面subpage在page中的偏移量: subpOffset = (bitmapIdx & 0x3FFFFFFF) * subpage.elemSize
其中subpOffset是个陌生的东西,会在后面PoolSubpage相关章节详细分析。
netty源码解解析(4.0)-25 ByteBuf内存池:PoolArena-PoolChunk的更多相关文章
- netty源码解解析(4.0)-23 ByteBuf内存管理:分配和释放
ByteBuf内存分配和释放由具体实现负责,抽象类型只定义的内存分配和释放的时机. 内存分配分两个阶段: 第一阶段,初始化时分配内存.第二阶段: 内存不够用时分配新的内存.ByteBuf抽象层没有定义 ...
- netty源码解解析(4.0)-24 ByteBuf基于内存池的内存管理
io.netty.buffer.PooledByteBuf<T>使用内存池中的一块内存作为自己的数据内存,这个块内存是PoolChunk<T>的一部分.PooledByteBu ...
- netty源码解解析(4.0)-22 ByteBuf的I/O
ByteBuf的I/O主要解决的问题有两个: 管理readerIndex和writerIndex.这个在在AbstractByteBuf中解决. 从内存中读写数据.ByteBuf的不同实现主要 ...
- netty源码解解析(4.0)-11 Channel NIO实现-概览
结构设计 Channel的NIO实现位于io.netty.channel.nio包和io.netty.channel.socket.nio包中,其中io.netty.channel.nio是抽象实 ...
- netty源码解解析(4.0)-10 ChannelPipleline的默认实现--事件传递及处理
事件触发.传递.处理是DefaultChannelPipleline实现的另一个核心能力.在前面在章节中粗略地讲过了事件的处理流程,本章将会详细地分析其中的所有关键细节.这些关键点包括: 事件触发接口 ...
- netty源码解解析(4.0)-17 ChannelHandler: IdleStateHandler实现
io.netty.handler.timeout.IdleStateHandler功能是监测Channel上read, write或者这两者的空闲状态.当Channel超过了指定的空闲时间时,这个Ha ...
- netty源码解解析(4.0)-18 ChannelHandler: codec--编解码框架
编解码框架和一些常用的实现位于io.netty.handler.codec包中. 编解码框架包含两部分:Byte流和特定类型数据之间的编解码,也叫序列化和反序列化.不类型数据之间的转换. 下图是编解码 ...
- netty源码解解析(4.0)-20 ChannelHandler: 自己实现一个自定义协议的服务器和客户端
本章不会直接分析Netty源码,而是通过使用Netty的能力实现一个自定义协议的服务器和客户端.通过这样的实践,可以更深刻地理解Netty的相关代码,同时可以了解,在设计实现自定义协议的过程中需要解决 ...
- netty源码解解析(4.0)-15 Channel NIO实现:写数据
写数据是NIO Channel实现的另一个比较复杂的功能.每一个channel都有一个outboundBuffer,这是一个输出缓冲区.当调用channel的write方法写数据时,这个数据被一系列C ...
随机推荐
- 浅入浅出 Java 排序算法
Java String 源码的排序算法 一.前言 Q:什么是选择问题? 选择问题,是假设一组 N 个数,要确定其中第 K 个最大值者.比如 A 与 B 对象需要哪个更大?又比如:要考虑从一些数组中找出 ...
- 本地代码上传至github
一. 环境及工具 1.下载并安装git版本管理工具 到 http://git-scm.com/downloads 下载并安装git版本管理工具 2.Windows客户端 3.配置github账号密码及 ...
- Cookie的获取
1.先创建Cookie对象,设置Cookie的键和值: Cookie cookie1="); Cookie cookie2="); Cookie cookie3="); ...
- charles 自动存储/auto_save
本文参考:charles 自动存储 自动保存工具 auto_save "自动保存"工具会在你设定的间隔后,自动保存并清除抓取到的内容.假设你设置了3分钟,则每隔三分钟会保存一次, ...
- Mybatis多数据源读写分离(注解实现)
#### Mybatis多数据源读写分离(注解实现) ------ 首先需要建立两个库进行测试,我这里使用的是master_test和slave_test两个库,两张库都有一张同样的表(偷懒,喜喜), ...
- 25 个 Linux 下最炫酷又强大的命令行神器,你用过其中哪几个呢?
本文首发于:微信公众号「运维之美」,公众号 ID:Hi-Linux. 「运维之美」是一个有情怀.有态度,专注于 Linux 运维相关技术文章分享的公众号.公众号致力于为广大运维工作者分享各类技术文章和 ...
- jenkins自动化部署项目8 -- 新建job(服务代码部署在linux上)
jenkins(windows) ----> 应用服务器(linux): 1.后台java服务: 与部署在windows上不同的是,这里我选择了在[构建后操作]中使用ssh向远程linux服务器 ...
- 使Flask的url支持正则表达式以及一个api小demo
from flask import Flask from flask import jsonify from flask import request from werkzeug.routing im ...
- <反向传播(backprop)>梯度下降法gradient descent的发展历史与各版本
梯度下降法作为一种反向传播算法最早在上世纪由geoffrey hinton等人提出并被广泛接受.最早GD由很多研究团队各自发表,可他们大多无人问津,而hinton做的研究完整表述了GD方法,同时hin ...
- K8s运行dashboard命令启动报错:"no endpoints available for service \"kubernetes-dashboard\""
今天启动k8s dashboard的时候报错:"no endpoints available for service \"kubernetes-dashboard\"&q ...