基于RDD实现简单的WordCount程序
写在前面
因为觉得自己的代码量实在是太少了,所以,想着,每周至少写5个小的demo程序。现在的想法是,写一些Spark,Storm,MapReduce,Flume,kafka等等单独或组合使用的一些小的Demo。
然后,我会尽力记录好,自己编码过程中遇到的问题,方便自己巩固复习。
废话不多说,我们直接干吧。
开发环境
本地开发
| 工具 | 版本 |
|---|---|
| Spark | 2.2.0 |
| Scala | 2.11.8 |
| Sbt | 1.2.8 项目构建管理,类似maven |
集群提交,启动的是Spark集群
| 工具 | 版本 |
|---|---|
| Spark | 2.2.0 |
| Hadoop | cdh-2.6.0-5.7.0 |
因为之前我只是使用的是Maven进行管理的,然后,后面的Spark项目还是打算使用SBT进行管理,所以,本机IDEA需要安装SBT。IDEA在安装Scala插件的时候,就自带了SBT工具的。很方便。
仅仅需要简单的配置一下,国内源会比较快一些
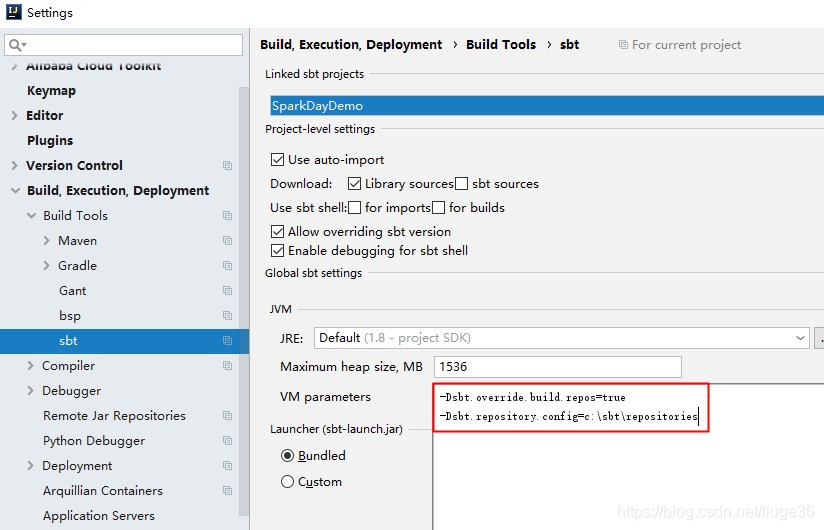
-Dsbt.override.build.repos=true
-Dsbt.repository.config=c:\sbt\repositories
c:\sbt\repositories文件内容如下:
[repositories]
local
aliyun: http://maven.aliyun.com/nexus/content/groups/public
typesafe-ivy-releases: http://repo.typesafe.com/typesafe/ivy-releases/, [organization]/[module]/[revision]/[type]s/[artifact](-[classifier]).[ext], bootOnly
sonatype-oss-releases
maven-central
sonatype-oss-snapshots
新建项目
在IDEA中新建Scala项目,注意这里选择的Scala版本为2.11.8,其余的按照常规来就行。
过一会儿,项目就构建完成了。
接着,为项目,添加,需要的依赖build.sbt
ps:需要什么依赖,可以去maven镜像仓库百度
name := "SparkDayDemo"
version := "0.1"
scalaVersion := "2.11.8"
//依赖库
libraryDependencies ++= Seq(
"org.apache.spark" %% "spark-core" % "2.2.0"
)
// https://mvnrepository.com/artifact/org.apache.spark/spark-sql
libraryDependencies += "org.apache.spark" %% "spark-sql" % "2.2.0"
本地wordCount代码
package february
import org.apache.spark.{SparkConf, SparkContext}
/**
* Description: 本地运行模式
*
* @Author: 留歌36
* @Date: 2019/2/20 15:30
*/
object LocalWordCountFromTxt {
def main(args: Array[String]): Unit = {
val conf=new SparkConf()
.setAppName("LocalWordCountFromTxt")
.setMaster("local[2]") //注意submit模式 需要注释掉
val sc=new SparkContext(conf)
val textFile=sc.textFile("f:\\hello.txt")
// flatMap就是把每一行,拿来进行split ,切分后的每个元素,独占一行
val lines=textFile.flatMap(line=>line.split(","))
lines.foreach(println)
val count=lines.map(word=>(word,1)).reduceByKey{case(x,y)=>x+y}
val output=count.saveAsTextFile("f:\\tmp3")
}
}
这里是可以直接右键,运行的,一般来说,在开发阶段,都是这样子运行方式,本地测试过了,才会提交到集群中去运行
提交Submit 模式代码
package february
import org.apache.spark.{SparkConf, SparkContext}
/**
* Description: 独立运行模式
* spark集群模式(独立运行模式)下textFile读取file本地文件报错解决
* 前言
* 如果在spark-shell中使用textFile("file:///path")演示,在local模式下是没有问题的,
* 因为毕竟就是在本机运行,读取本地的文件。但是如果spark-shell --master指定spark集群的话,
* 这样运行就会有问题,会报找不到文件的错误。
*
* 解决方案
* 那么解决的方案其实也比较简单,就是在所有的集群节点上相同的path下上传该文件。
* 然后在textFile("file:///path")中指定该path即可。
*
* 注意: 各个节点的文件必须相同,否则依然会报错。
*
* @Author: 留歌36
* @Date: 2019/2/20 15:30
*/
object StandaloneWordCountFromTxt {
def main(args: Array[String]): Unit = {
val conf=new SparkConf()
.setAppName("StandaloneWordCountFromTxt")
val sc=new SparkContext(conf)
val textFile=sc.textFile("file:///home/liuge36/feb/wordCountFrom.txt")
val lines=textFile.flatMap(line=>line.split(","))
val count=lines.map(word=>(word,1)).reduceByKey{case(x,y)=>x+y}
val output=count.saveAsTextFile("file:///home/liuge36/feb/wordCountFrom")
}
}
这里,再想说明一下,集群中去提交代码,千万注意集群中的每一个节点都必要要有相同的一份文件才行,不然,会报错的。
代码,开发完毕,就可以打包上传,打包方式值是,菜单栏的Build
集群中需要启动:
关闭所有jps出现的进程先
启动hadoop start-all.sh
启动saprk start-all.sh
启动mysql元数据库 service mysqld restart (spark003)
启动hive metastore服务 nohup hive --service metastore &
这里可能和你不太一致,其实,如果你没有配置Hadoop或Hive连接SparkSQL的话,你只需要启动Spark就可以了
到这里,你应该有一个待运行的jar包了
这里为了效果方便,我使用的是直接输出结果的jar包
提交到spark集群中去,
StandAlone 独立运行模式,不需要Hadoop
模式一 client模式
[root@spark001 bin]# spark-submit --master spark://spark001:7077 --deploy-mode client --class february.StandaloneWordCountFromTxt /home/liuge36/jars/SparkDayDemo.jar
19/02/14 09:09:21 WARN Utils: Service 'SparkUI' could not bind on port 4040. Attempting port 4041.
==================华丽分割线开始============================
(Zookeeper,1)
(Kafka,1)
(Hello,5)
(,1)
(World,1)
(Hive,1)
(Sqoop,1)
(Spark,1)
(People,1)
(Storm,1)
(Flume,1)
(Person,1)
(Hbase,1)
(Hadoop,1)
==================华丽分割线结束============================
其中 需要注意的是你的Spark集群的地址,这个可以从你Master节点的8080 (8081)详情页面查看到,这个地址一定要写对才行
如果,一切顺利的话,那么你就可以在保存的目录中找到结果文件了
模式二 cluster模式
spark-submit --master spark://spark001:7077 --deploy-mode cluster --class february.StandaloneWordCountFromTxt /home/liuge36/jars/SparkDayDemo.jar
Spark On Yarn
Spark可以和Yarn整合,将Application提交到Yarn上运行,和StandAlone提交模式一样,Yarn也有两种提交任务的方式。
1提交到代码到Yarn,Spark On Yarn 模式1
在client节点配置中spark-env.sh添加Hadoop_HOME的配置目录即可提交yarn 任务,具体步骤如下:
export HADOOP_CONF_DIR=/root/apps/hadoop-2.6.0-cdh5.7.0/etc/hadoop
[root@spark001 bin]# spark-submit --master yarn --deploy-mode client --class february.StandaloneWordCountFromTxt /home/liuge36/jars/SparkDayDemo.jar
19/02/14 08:57:26 WARN Utils: Service 'SparkUI' could not bind on port 4040. Attempting port 4041.
==================华丽分割线开始============================
(Zookeeper,1)
(Kafka,1)
(Hello,5)
(,1)
(World,1)
(Hive,1)
(Sqoop,1)
(Spark,1)
(People,1)
(Storm,1)
(Flume,1)
(Person,1)
(Hbase,1)
(Hadoop,1)
==================华丽分割线结束============================
执行流程
客户端提交一个Application,在客户端启动一个Driver进程。
Driver进程会向RS(ResourceManager)发送请求,启动AM(ApplicationMaster)的资源。
RS收到请求,随机选择一台NM(NodeManager)启动AM。这里的NM相当于Standalone中的Worker节点。
AM启动后,会向RS请求一批container资源,用于启动Executor.
RS会找到一批NM返回给AM,用于启动Executor。
AM会向NM发送命令启动Executor。
Executor启动后,会反向注册给Driver,Driver发送task到Executor,执行情况和结果返回给Driver端。
总结:
1、Yarn-client模式同样是适用于测试,因为Driver运行在本地,Driver会与yarn集群中的Executor进行大量的通信,会造成客户机网卡流量的大量增加.
2、 ApplicationMaster的作用:
为当前的Application申请资源
给NodeManager发送消息启动Executor。
注意:ApplicationMaster有launchExecutor和申请资源的功能,并没有作业调度的功能。
2提交到代码到Yarn,Spark On Yarn 模式2
spark-submit --master yarn --deploy-mode cluster --class february.StandaloneWordCountFromTxt /home/liuge36/jars/SparkDayDemo.jar
执行流程
客户机提交Application应用程序,发送请求到RS(ResourceManager),请求启动AM(ApplicationMaster)。
RS收到请求后随机在一台NM(NodeManager)上启动AM(相当于Driver端)。
AM启动,AM发送请求到RS,请求一批container用于启动Executor。
RS返回一批NM节点给AM。
AM连接到NM,发送请求到NM启动Executor。
Executor反向注册到AM所在的节点的Driver。Driver发送task到Executor。
总结
1、Yarn-Cluster主要用于生产环境中,因为Driver运行在Yarn集群中某一台nodeManager中,每次提交任务的Driver所在的机器都是随机的,不会产生某一台机器网卡流量激增的现象,缺点是任务提交后不能看到日志。只能通过yarn查看日志。
2.ApplicationMaster的作用:
为当前的Application申请资源 给nodemanager发送消息 启动Excutor。
任务调度。(这里和client模式的区别是AM具有调度能力,因为其就是Driver端,包含Driver进程)
3、 停止集群任务命令:yarn application -kill applicationID
yarn logs -applicationId application_1517538889175_2550 > logs.txt
参考:https://blog.csdn.net/LHWorldBlog/article/details/79300050
基于RDD实现简单的WordCount程序的更多相关文章
- 实验一:基于Winsock完成简单的网络程序开发
第一部分:简答的UDP网络通信程序 // UDP5555.cpp : Defines the entry point for the application. //================== ...
- 55、Spark Streaming:updateStateByKey以及基于缓存的实时wordcount程序
一.updateStateByKey 1.概述 SparkStreaming 7*24 小时不间断的运行,有时需要管理一些状态,比如wordCount,每个batch的数据不是独立的而是需要累加的,这 ...
- Netty学习——基于netty实现简单的客户端聊天小程序
Netty学习——基于netty实现简单的客户端聊天小程序 效果图,聊天程序展示 (TCP编程实现) 后端代码: package com.dawa.netty.chatexample; import ...
- 输入DStream之基础数据源以及基于HDFS的实时wordcount程序
输入DStream之基础数据源以及基于HDFS的实时wordcount程序 一.Java方式 二.Scala方式 基于HDFS文件的实时计算,其实就是,监控一个HDFS目录,只要其中有新文件出现,就实 ...
- 09、高级编程之基于排序机制的wordcount程序
package sparkcore.java; import java.util.Arrays; import java.util.Iterator; import org.apache.spark. ...
- Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码
Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本文主要是记录一写我在学习MapReduce时的一些 ...
- 在Spark上运行WordCount程序
1.编写程序代码如下: Wordcount.scala package Wordcount import org.apache.spark.SparkConf import org.apache.sp ...
- 编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本]
编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本] 1. 开发环境 Jdk 1.7.0_72 Maven 3.2.1 Scala 2.10.6 Spark 1.6 ...
- Hive数据分析——Spark是一种基于rdd(弹性数据集)的内存分布式并行处理框架,比于Hadoop将大量的中间结果写入HDFS,Spark避免了中间结果的持久化
转自:http://blog.csdn.net/wh_springer/article/details/51842496 近十年来,随着Hadoop生态系统的不断完善,Hadoop早已成为大数据事实上 ...
随机推荐
- Kibana 管理界面使用教程
使用浏览器访问 ip:5601 默认端口,进入首页 Discover:日志管理视图 Visualize:统计视图 Dashboard:仪表视图 Timelion:时间轴视图 APM:性能管理视图 De ...
- 浅谈jQuery中的Ajax
浅谈jQuery中的Ajax 一.前言 jQuery 对 Ajax 操作进行了封装, 在 jQuery 中最底层的方法时 $.ajax(), 第二层是 load(), $.get() 和 $.post ...
- 1.Sentinel源码分析—FlowRuleManager加载规则做了什么?
最近我很好奇在RPC中限流熔断降级要怎么做,hystrix已经1年多没有更新了,感觉要被遗弃的感觉,那么我就把眼光聚焦到了阿里的Sentinel,顺便学习一下阿里的源代码. 这一章我主要讲的是Flow ...
- MSIL实用指南-数学运算
C#支持的数学运算是加.减.乘.除.取模,它们对应的指令是Add.Sub.Mul.Div.Rem. 这五个运算都需要两个参数,它们的通用步骤1.生成加载左边变量2.生成加载右边变量3.生成运算指令 实 ...
- Oracle数据库测试和优化最佳实践: OTest介绍 (转)
当前Oracle数据库最佳测试工具OTest * Otest是用于Oracle数据库测试.优化.监控软件. * Otest是免费提供给Oracle客户和广大DBA工程师使用的软件.由原厂技术专家王 ...
- Delphi - cxGrid设定字段类型为CheckBox
cxGrid设定字段类型为CheckBox 1:设定OraQuery属性 CachedUpdates设定为True: 双击打开OraQuery,选中Update SQLs页面,Insert.Updat ...
- Linux系统简介以及基本操作(一)
Linux简介(操作系统) Linux发展史(了解) Linux出现于1991年,是由芬兰赫尔辛基大学学生李纳斯·托瓦兹(Linus Torvalds)偶然发现的,他当时是为了方便下载学校网站的一些视 ...
- CF 551 E GukiZ and GukiZiana
https://codeforces.com/contest/551/problem/E 分块真强. 题意就是1.区间加,2.询问整个区间中,最远的两个x的距离. 分块,然后,每次找位子用二分找即可. ...
- hdu2586 How far away ?(lca模版题)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=2586 题意:给出一棵树还有两个点然后求这两个点的最短距离. 题解:val[a]+val[b]-2*va ...
- CH4301 Can you answer on these queries III 题解
给定长度为N的数列A,以及M条指令 (N≤500000, M≤100000),每条指令可能是以下两种之一: "2 x y",把 A[x] 改成 y. "1 x y&quo ...