实时统计每天pv,uv的sparkStreaming结合redis结果存入mysql供前端展示
最近有个需求,实时统计pv,uv,结果按照date,hour,pv,uv来展示,按天统计,第二天重新统计,当然了实际还需要按照类型字段分类统计pv,uv,比如按照date,hour,pv,uv,type来展示。这里介绍最基本的pv,uv的展示。
| id | uv | pv | date | hour |
|---|---|---|---|---|
| 1 | 155599 | 306053 | 2018-07-27 | 18 |
关于什么是pv,uv,可以参见这篇博客:https://blog.csdn.net/petermsh/article/details/78652246
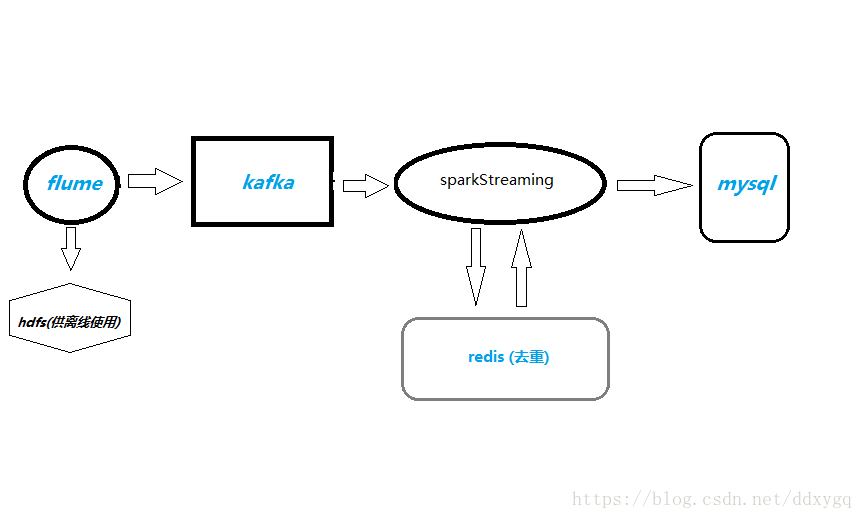
1、项目流程
日志数据从flume采集过来,落到hdfs供其它离线业务使用,也会sink到kafka,sparkStreaming从kafka拉数据过来,计算pv,uv,uv是用的redis的set集合去重,最后把结果写入mysql数据库,供前端展示使用。
2、具体过程
1)pv的计算
拉取数据有两种方式,基于received和direct方式,这里用direct直拉的方式,用的mapWithState算子保存状态,这个算子与updateStateByKey一样,并且性能更好。当然了实际中数据过来需要经过清洗,过滤,才能使用。
定义一个状态函数
// 实时流量状态更新函数
val mapFunction = (datehour:String, pv:Option[Long], state:State[Long]) => {
val accuSum = pv.getOrElse(0L) + state.getOption().getOrElse(0L)
val output = (datehour,accuSum)
state.update(accuSum)
output
}
计算pv
val stateSpec = StateSpec.function(mapFunction)
val helper_count_all = helper_data.map(x => (x._1,1L)).mapWithState(stateSpec).stateSnapshots().repartition(2)
这样就很容易的把pv计算出来了。
2)uv的计算
uv是要全天去重的,每次进来一个batch的数据,如果用原生的reduceByKey或者groupByKey对配置要求太高,在配置较低情况下,我们申请了一个93G的redis用来去重,原理是每进来一条数据,将date作为key,guid加入set集合,20秒刷新一次,也就是将set集合的尺寸取出来,更新一下数据库即可。
helper_data.foreachRDD(rdd => {
rdd.foreachPartition(eachPartition => {
// 获取redis连接
val jedis = getJedis
eachPartition.foreach(x => {
val date:String = x._1.split(":")(0)
val key = date
// 将date作为key,guid(x._2)加入set集合
jedis.sadd(key,x._2)
// 设置存储每天的数据的set过期时间,防止超过redis容量,这样每天的set集合,定期会被自动删除
jedis.expire(key,ConfigFactory.rediskeyexists)
})
// 关闭连接
closeJedis(jedis)
})
})
3)结果保存到数据库
结果保存到mysql,数据库,20秒刷新一次数据库,前端展示刷新一次,就会重新查询一次数据库,做到实时统计展示pv,uv的目的。
/**
* 插入数据
* @param data (addTab(datehour)+helperversion)
* @param tbName
* @param colNames
*/
def insertHelper(data: DStream[(String, Long)], tbName: String, colNames: String*): Unit = {
data.foreachRDD(rdd => {
val tmp_rdd = rdd.map(x => x._1.substring(11, 13).toInt)
if (!rdd.isEmpty()) {
val hour_now = tmp_rdd.max() // 获取当前结果中最大的时间,在数据恢复中可以起作用
rdd.foreachPartition(eachPartition => {
try {
val jedis = getJedis
val conn = MysqlPoolUtil.getConnection()
conn.setAutoCommit(false)
val stmt = conn.createStatement()
eachPartition.foreach(x => {
val datehour = x._1.split("\t")(0)
val helperversion = x._1.split("\t")(1)
val date_hour = datehour.split(":")
val date = date_hour(0)
val hour = date_hour(1).toInt
val colName0 = colNames(0) // date
val colName1 = colNames(1) // hour
val colName2 = colNames(2) // count_all
val colName3 = colNames(3) // count
val colName4 = colNames(4) // helperversion
val colName5 = colNames(5) // datehour
val colName6 = colNames(6) // dh
val colValue0 = addYin(date)
val colValue1 = hour
val colValue2 = x._2.toInt
val colValue3 = jedis.scard(date + "_" + helperversion) // // 2018-07-08_10.0.1.22
val colValue4 = addYin(helperversion)
var colValue5 = if (hour < 10) "'" + date + " 0" + hour + ":00 " + helperversion + "'" else "'" + date + " " + hour + ":00 " + helperversion + "'"
val colValue6 = if(hour < 10) "'" + date + " 0" + hour + ":00'" else "'" + date + " " + hour + ":00'"
var sql = ""
if (hour == hour_now) { // uv只对现在更新
sql = s"insert into ${tbName}(${colName0},${colName1},${colName2},${colName3},${colName4},${colName5}) values(${colValue0},${colValue1},${colValue2},${colValue3},${colValue4},${colValue5}) on duplicate key update ${colName2} = ${colValue2},${colName3} = ${colValue3}"
} else {
sql = s"insert into ${tbName}(${colName0},${colName1},${colName2},${colName4},${colName5}) values(${colValue0},${colValue1},${colValue2},${colValue4},${colValue5}) on duplicate key update ${colName2} = ${colValue2}"
}
stmt.addBatch(sql)
})
closeJedis(jedis)
stmt.executeBatch() // 批量执行sql语句
conn.commit()
conn.close()
} catch {
case e: Exception => {
logger.error(e)
logger2.error(HelperHandle.getClass.getSimpleName + e)
}
}
})
}
})
}
// 计算当前时间距离次日零点的时长(毫秒)
def resetTime = {
val now = new Date()
val todayEnd = Calendar.getInstance
todayEnd.set(Calendar.HOUR_OF_DAY, 23) // Calendar.HOUR 12小时制
todayEnd.set(Calendar.MINUTE, 59)
todayEnd.set(Calendar.SECOND, 59)
todayEnd.set(Calendar.MILLISECOND, 999)
todayEnd.getTimeInMillis - now.getTime
}
4)数据容错
流处理消费kafka都会考虑到数据丢失问题,一般可以保存到任何存储系统,包括mysql,hdfs,hbase,redis,zookeeper等到。这里用SparkStreaming自带的checkpoint机制来实现应用重启时数据恢复。
checkpoint
这里采用的是checkpoint机制,在重启或者失败后重启可以直接读取上次没有完成的任务,从kafka对应offset读取数据。
// 初始化配置文件
ConfigFactory.initConfig()
val conf = new SparkConf().setAppName(ConfigFactory.sparkstreamname)
conf.set("spark.streaming.stopGracefullyOnShutdown","true")
conf.set("spark.streaming.kafka.maxRatePerPartition",consumeRate)
conf.set("spark.default.parallelism","24")
val sc = new SparkContext(conf)
while (true){
val ssc = StreamingContext.getOrCreate(ConfigFactory.checkpointdir + DateUtil.getDay(0),getStreamingContext _ )
ssc.start()
ssc.awaitTerminationOrTimeout(resetTime)
ssc.stop(false,true)
}
checkpoint是每天一个目录,在第二天凌晨定时销毁StreamingContext对象,重新统计计算pv,uv。
注意
ssc.stop(false,true)表示优雅地销毁StreamingContext对象,不能销毁SparkContext对象,ssc.stop(true,true)会停掉SparkContext对象,程序就直接停了。
应用迁移或者程序升级
在这个过程中,我们把应用升级了一下,比如说某个功能写的不够完善,或者有逻辑错误,这时候都是需要修改代码,重新打jar包的,这时候如果把程序停了,新的应用还是会读取老的checkpoint,可能会有两个问题:
- 执行的还是上一次的程序,因为checkpoint里面也有序列化的代码;
- 直接执行失败,反序列化失败;
其实有时候,修改代码后不用删除checkpoint也是可以直接生效,经过很多测试,我发现如果对数据的过滤操作导致数据过滤逻辑改变,还有状态操作保存修改,也会导致重启失败,只有删除checkpoint才行,可是实际中一旦删除checkpoint,就会导致上一次未完成的任务和消费kafka的offset丢失,直接导致数据丢失,这种情况下我一般这么做。
这种情况一般是在另外一个集群,或者把checkpoint目录修改下,我们是代码与配置文件分离,所以修改配置文件checkpoint的位置还是很方便的。然后两个程序一起跑,除了checkpoint目录不一样,会重新建,都插入同一个数据库,跑一段时间后,把旧的程序停掉就好。以前看官网这么说,只能记住不能清楚明了,只有自己做时才会想一下办法去保证数据准确。
5)日志
日志用的log4j2,本地保存一份,ERROR级别的日志会通过邮件发送到手机。
val logger = LogManager.getLogger(HelperHandle.getClass.getSimpleName)
// 邮件level=error日志
val logger2 = LogManager.getLogger("email")
分享一个大神的人工智能教程。零基础!通俗易懂!风趣幽默!还带黄段子!希望你也加入到人工智能的队伍中来!
微信公众号
我的微信公众号,专注于大数据分析与挖掘,感兴趣可以关注,看一看,瞧一瞧!

实时统计每天pv,uv的sparkStreaming结合redis结果存入mysql供前端展示的更多相关文章
- 网站统计IP PV UV实现原理
网站流量统计可以帮助我们分析网站的访问和广告来访等数据,里面包含很多数据的,比如访问试用的系统,浏览器,ip归属地,访问时间,搜索引擎来源,广告效果等.原来是一样的,这次先实现了PV,UV,IP三个重 ...
- 网站统计IP PV UV
###我只是一个搬运工 网站流量统计可以帮助我们分析网站的访问和广告来访等数据,里面包含很多数据的,比如访问使用的系统,浏览器,ip归属地,访问时间,搜索引擎来源,广告效果等. PV(访问量):Pag ...
- 有关“数据统计”的一些概念 -- PV UV VV IP跳出率等
有关"数据统计"的一些概念 -- PV UV VV IP跳出率等 版权声明:本文为博主原创文章,未经博主允许不得转载. 此文是本人工作中碰到的,随时记下来的零散概念,特此整理一下. ...
- 日志分析_统计每日各时段的的PV,UV
第一步: 需求分析 需要哪些字段(时间:每一天,各个时段,id,url,guid,tracTime) 需要分区为天/时 PV(统计记录数) UV(guid去重) 第二步: 实施步骤 建Hive表,表列 ...
- 网站流量统计PV&UV
统计网站pv和uv PV是网站分析的一个术语,用以衡量网站用户访问的网页的数量. 对于广告主,PV值可预期它可以带来多少广告收入.一般来说,PV与来访者的数量成正比,但是PV并不直接决定页面的真实来访 ...
- 网站流量统计之PV和UV
转自:http://blog.csdn.NET/webdesman/article/details/4062069 如果您是一个站长,或是一个SEO,您一定对于网站统计系统不会陌生,对于SEO新手来说 ...
- Flink统计当日的UV、PV
Flink 统计当日的UV.PV 测试环境: flink 1.7.2 1.数据流程 a.模拟数据生成,发送到kafka(json 格式) b.flink 读取数据,count c. 输出数据到kafk ...
- Kafka项目实战-用户日志上报实时统计之分析与设计
1.概述 本课程的视频教程地址:<Kafka实战项目之分析与设计> 本课程我通过一个用户实时上报日志案例作为基础,带着大家去分析Kafka这样一个项目的各个环节,从而对项目的整体设计做比 ...
- 网站流量分析指标-PV/UV/PR/ip分析及区别
1.什么是pv? PV(page view),即页面浏览量,或点击量;通常是衡量一个网络新闻频道或网站甚至一条网络新闻的主要指标. 高手对pv的解释是,一个访问者在24小时(0点到24点)内到底看了你 ...
随机推荐
- Kubernetes Pod 驱逐详解
原文链接:Kubernetes Pod 驱逐详解 在 Kubernetes 中,Pod 使用的资源最重要的是 CPU.内存和磁盘 IO,这些资源可以被分为可压缩资源(CPU)和不可压缩资源(内存,磁盘 ...
- 浅谈微服务架构与服务治理的Eureka和Dubbo
前言 本来计划周五+周末三天自驾游,谁知人算不如天算,周六恰逢台风来袭,湖州附近的景点全部关停,不得已只能周五玩完之后,于周六踩着台风的边缘逃回上海.周末过得如此艰难,这次就聊点务虚的话题,一是浅谈微 ...
- nodeJs跨域设置(express,koa2,eggJs)
原生跨域 var http=require('http'); var server = http.createServer(function (req,res) { res.setHeader('Ac ...
- Oracle delete和truncate实践操作之一
实践说明 本文章主要记录在Oracle中,delete和truncate进行数据删除之后,如何进行数据恢复.由于网上对delete和truncate的区别说明较多,此处不过多介绍两者区别. 注:由于环 ...
- 物联网时代-跟着Thingsboard学IOT架构-HTTP设备协议及API相关限制
thingsboard官网: https://thingsboard.io/ thingsboard GitHub: https://github.com/thingsboard/thingsboar ...
- (三十九)c#Winform自定义控件-面包屑导航
前提 入行已经7,8年了,一直想做一套漂亮点的自定义控件,于是就有了本系列文章. 开源地址:https://gitee.com/kwwwvagaa/net_winform_custom_control ...
- 阿里巴巴JAVA开发规范学习笔记
一.编程规约 (一)命名规约 1.类名驼峰.领域模型除外VO.BO.DTO.DO统称POJO 4.数组String[] args 8.枚举类 Enum ,其实就是特殊的常量类,构造方法强制私有 ( 二 ...
- ASP.NET Core[源码分析篇] - WebHost
_configureServicesDelegates的承接 在[ASP.NET Core[源码分析篇] - Startup]这篇文章中,我们得知了目前为止(UseStartup),所有的动作都是在_ ...
- Python变量类型说明
Python中的变量不需要声明,直接赋值便是声明和定义的过程 每个变量在内存中创建,都包括变量的标识.名称和数据这些信息 每个变量在使用前必须赋值 counter = 100 #正数变量 miles ...
- Greenplum数据库分享
1. 场景描述 最近做了次Greenplum数据库的分享,如下图,把第三章的的架构介绍简单提出来,分享下. 2. 解决方案 就按照ppt贴图了,部分内容稍微做了下马赛克. (这页ppt的下半部分,有实 ...