第3次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC
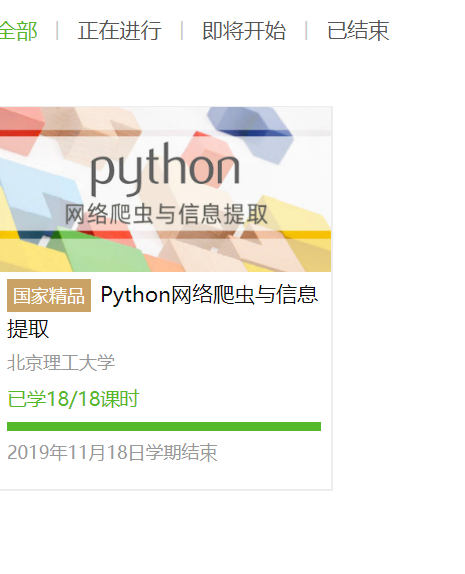
2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
3.学习完成第0周至第4周的课程内容,并完成各周作业


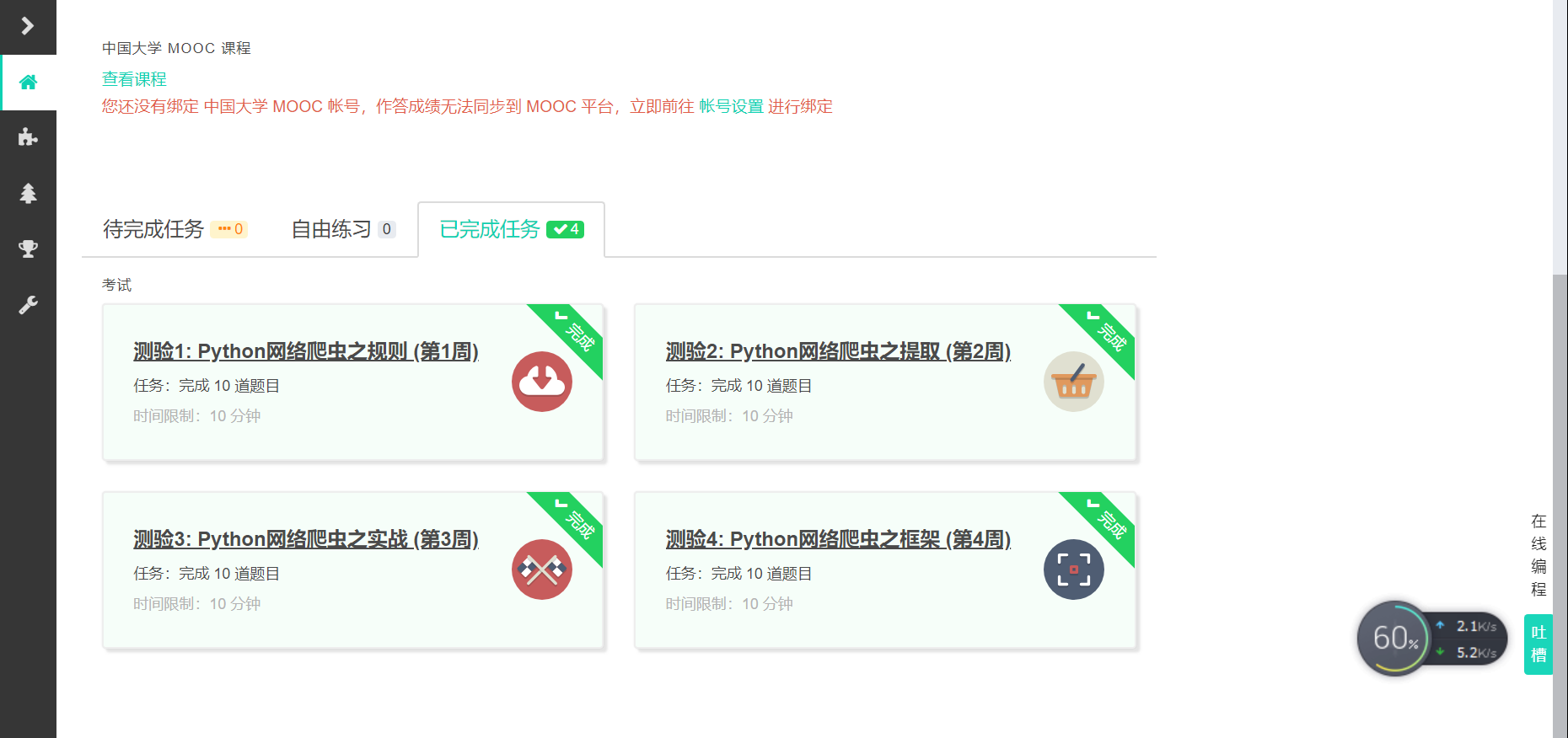
4.提供图片或网站显示的学习进度,证明学习的过程。
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
很高兴能有机会在网上学习 Python 网络爬虫与信息提取这门课,通过这门课的学习,我一步步加深了对Python的理解,教学主要分为网络爬虫之前奏,规则,提取,实战,框架,这五个五部分。
在前奏中,个给我们介绍了常用的Python IDE 工具,以及各类开发工具的选择。在网络爬虫之规则中着重介绍了Requests 库,requests库是Python实现的最简单易用的HTTP库,是网络爬虫入学推荐使用的。在此单元中的网络爬虫的盗亦有道中还介绍了网络爬虫会遇到的一系列问题:1性能骚扰:受限于编写水平和目的,网络爬虫将会为web服务器带来巨大的资源开销2法律风险:服务器上的数据有产权归属,网路爬虫获取数据后牟利将带来法律风险。3隐私泄露:网络爬虫可能具备突破简单访问控制的能力,获得被保护数据从而泄露个人隐私。以及如何遵守Robots协议,及其重要性危险性。在requests库网络爬虫实战中介绍了五个实例,分别为京东商品页面亚马逊商品页面的抓取等。
在第二周网络爬虫之提取中,我们继续学习了beautiful soup库入门,信息组织与提取方法以及一个实例。
在第三周中我们认识了Re库(正则表达式)的入门,则表达式(英文名称:regular expression,regex,RE)是用来简洁表达一组字符串特征的表达式。最主要应用在字符串匹配中。
.re.I(re.IGNORECASE): 忽略大小写
2).re.M(MULTILINE): 多行模式,改变’^‘和’$‘的行为
3).re.S(DOTALL): 点任意匹配模式,改变’.'的行为
4).re.L(LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
.re.U(UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性6).re.X(VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释
在最后一周的学习中我们了解了Scrapy 爬虫架构,在基本使用中,介绍了yield关键字和生成器,requests,response,item,selector,scrapy是应用最广泛的爬虫框架,没有之一,而且是成熟度最高的框架,可利用成熟产品,避免重复“造轮子”,可以更快速的构建项目。Scrap也是Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。是你学习爬虫绝对会用到的一个框架。学习一些抓包知识,有些网站防爬,需要人工浏览一些页面,抓取数据包分析防爬机制,然后做出应对措施。比如解决cookie问题,或者模拟设备等。
“互联网是功能集合,更是存储空间;海量数据孕育巨大价值,数据采集需求迫切。网络爬虫已经成为自动获取互联网数据的主要方式,数据就在那里,它是你的吗?”正如课程介绍的这句话说的一样,掌握利用Python爬取网络数据并提取信息的"小"本领是一个对我们十分受用的。通过这一系列的学习,对网络爬虫不敢说有多大程度的认知。但也有了初步了解,希望在将来有机会进一步对其深入了解,学以致用!
第3次作业-MOOC学习笔记:Python网络爬虫与信息提取的更多相关文章
- 第三次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 第一周 Requests库的爬 ...
- 第三次作业-Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 过程. 5.写一篇不少于100 ...
- python3.4学习笔记(十七) 网络爬虫使用Beautifulsoup4抓取内容
python3.4学习笔记(十七) 网络爬虫使用Beautifulsoup4抓取内容 Beautiful Soup 是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖 ...
- python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息,抓取政府网新闻内容
python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息PySpider:一个国人编写的强大的网络爬虫系统并带有强大的WebUI,采用Python语言编写 ...
- Python网络爬虫与信息提取
1.Requests库入门 Requests安装 用管理员身份打开命令提示符: pip install requests 测试:打开IDLE: >>> import requests ...
- Python网络爬虫与信息提取笔记
直接复制粘贴笔记发现有问题 文档下载地址//download.csdn.net/download/hide_on_rush/12266493 掌握定向网络数据爬取和网页解析的基本能力常用的 Pytho ...
- 【学习笔记】PYTHON网络爬虫与信息提取(北理工 嵩天)
学习目的:掌握定向网络数据爬取和网页解析的基本能力the Website is the API- 1 python ide 文本ide:IDLE,Sublime Text集成ide:Pychar ...
- Python网络爬虫与信息提取(一)
学习 北京理工大学 嵩天 课程笔记 课程体系结构: 1.Requests框架:自动爬取HTML页面与自动网络请求提交 2.robots.txt:网络爬虫排除标准 3.BeautifulSoup框架:解 ...
- Python网络爬虫与信息提取[request库的应用](单元一)
---恢复内容开始--- 注:学习中国大学mooc 嵩天课程 的学习笔记 request的七个主要方法 request.request() 构造一个请求用以支撑其他基本方法 request.get(u ...
随机推荐
- Rsync 服务部署与参数详解
Rsync 简介 rsync 是一款开源的.快速的.多功能的.可实现全量及增量的本地或远程数据同步备份的优秀工具.Rsync软件适用于unix/linux/windows等多种操作系统平台. 传统的 ...
- 夯实Java基础系列5:Java文件和Java包结构
目录 Java中的包概念 包的作用 package 的目录结构 设置 CLASSPATH 系统变量 常用jar包 java软件包的类型 dt.jar rt.jar *.java文件的奥秘 *.Java ...
- (2)安装elastic6.1.3及插件kibana,x-pack,essql,head,bigdesk,cerebro,ik
5.2kibana安装 5.2.1解压kibana安装包,修改config/kibana.yml中端口,服务器地址,elastic连接地址 -linux-x86_64.tar.gz cd kibana ...
- lvm创建逻辑卷技巧
公司使用的服务器都是虚拟机,是虚拟机管理员通过模板创建的. 创建的所有逻辑卷都是使用的sda盘. 而我们在部署应用时需要和系统所在盘分离.(提高磁盘读写速度,避免系统盘被占满) 以前都是先创建新的逻辑 ...
- 一步步构建.NET Core Web应用程序---基本项目结构
前言 随着.NET Core日益成熟, 我作为C#&.NET体系中的一份子也加入了.NET Core 这一体系中,随着不断学习, 接触到的各种框架日益庞杂,接下来我会由一个新手的角度把整个基于 ...
- 【Django】url(路由系统)
1.单一路由对应 url(r'^index/',views.index), 2.基于正则的路由 url(r'^index/(\d*)', views.index), url(r'^manage/(?P ...
- 讨论c/c++计算小数的精度问题
求出所有100以下整数与一位小数相乘等于相加的浮点数这个有Bug浮点数计算时精度会出现误差 除非使用非常精确的类型或限制浮点的位数 比如 #include <iostream> int m ...
- vue 单页应用点击某个链接,跳转到新页面的方式
<router-link class="goDetail" :to="{name: 'detail',params: {id:item.id}}" tar ...
- 卷积神经网络CNN识别MNIST数据集
这次我们将建立一个卷积神经网络,它可以把MNIST手写字符的识别准确率提升到99%,读者可能需要一些卷积神经网络的基础知识才能更好的理解本节的内容. 程序的开头是导入TensorFlow: impor ...
- XCTF-upload
这道题的话,看了一下是RCTF-2015的原题....可是这也太难了吧QAQ,文件名作为注入点可也是太秀了,害的我一直以为是文件上传QAQ,并且这道题的坑还不少,就是注入时的输出只能为10进制.... ...