Spark 基础操作
1. Spark 基础
2. Spark Core
3. Spark SQL
4. Spark Streaming
5. Spark 内核机制
6. Spark 性能调优
1. Spark 基础
1.1 Spark 中的相应组件
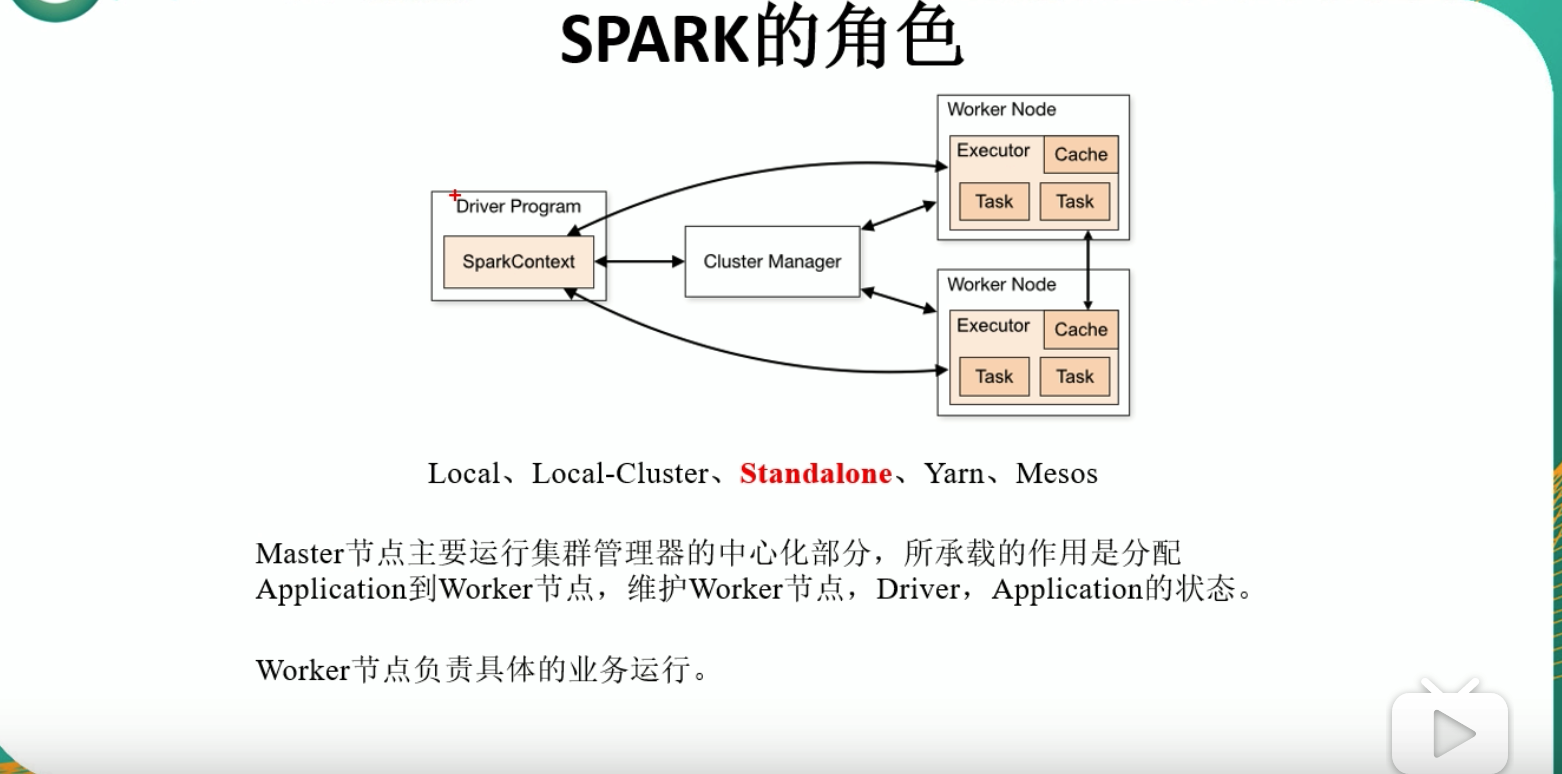
1.2 Standalone 模式安装
// 1. 准备安装包(见下方参考资料): spark-2.1.3-bin-hadoop2.7.tgz
// 2. 修改配置文件
// 2.1 spark-env.sh.template
mv spark-env.sh.template spark-env.sh
SPARK_MASTER_HOST=IP地址
SPARK_MASTER_PORT=7077
// 3. 启动
sbin/start-all.sh
// 4. 浏览器访问
http://IP地址:8080
// 5. 测试官方案例
bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://IP地址:7077 --executor-memory 1G --total-executor-cores 2 ./examples/jars/spark-examples_2.11-2.1.3.jar 100
// 6. 使用 Spark Shell 测试 WordCount
bin/spark-shell --master spark://10.110.147.193:7077
sc.textFile("./RELEASE").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
1.2.1 提交应用程序概述
bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://IP地址:7077 --executor-memory 1G --total-executor-cores 2 ./examples/jars/spark-examples_2.11-2.1.3.jar 100--class: 应用程序的启动类,例如,org.apache.spark.examples.SparkPi;--master: 集群的master URL;deploy-mode: 是否发布你的驱动到worker节点(cluster)或者作为一个本地客户端(client);--conf: 任意的Spark配置属性,格式:key=value,如果值包含空格,可以加引号"key=value";application-jar:打包好的应用 jar,包含依赖,这个URL在集群中全局可见。比如hdfs://共享存储系统,如果是file://path,那么所有节点的path都包含同样的jar;application-arguments: 传给main()方法的参数;
1.3 JobHistoryServer 配置
- 修改
spark-defaults.conf.template名称:mv spark-defaults.conf.template spark-defaults.conf; - 修改
spark-defaults.conf文件,开启 Log:spark.eventLog.enabled true;spark.eventLog.dir hdfs://IP地址:9000/directory;- 注意:HDFS 上的目录需要提前存在;
- 修改
spark-env.sh文件,添加如下配置:export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://IP地址:9000/directory";
- 开启历史服务:
sbin/start-history-server.sh; - 执行上面的程序:
org.apache.spark.examples.SparkPi; - 访问:
http//IP地址:4000;
1.4 Spark HA 配置
- zookeeper 正常安装并启动;
- 修改
spark-env.sh文件,添加如下配置:- 注释掉:
SPARK_MASTER_HOST=IP地址;SPARK_MASTER_PORT=7077
export SPARK_DEAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=IP地址1, IP地址2, IP地址3 -Dspark.deploy.zookeeper.dir=/spark"
- 注释掉:
1.5 Yarn 模式安装
- 修改 hadoop 配置文件
yarn-site.xml,添加如下内容:
<!--是否启动一个线程,检查每个任务正在使用的物理内容量,如果任务超出分配值,则直接将其杀掉,默认为true-->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程,检查每个任务正在使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
- 修改
spark-env.sh,添加如下配置:YARN_CONF_DIR=/opt/module/hadoop-2.8.5/etc/hadoopHADOOP_CONF_DIR=/opt/module/hadoop-2.8.5/etc/hadoop
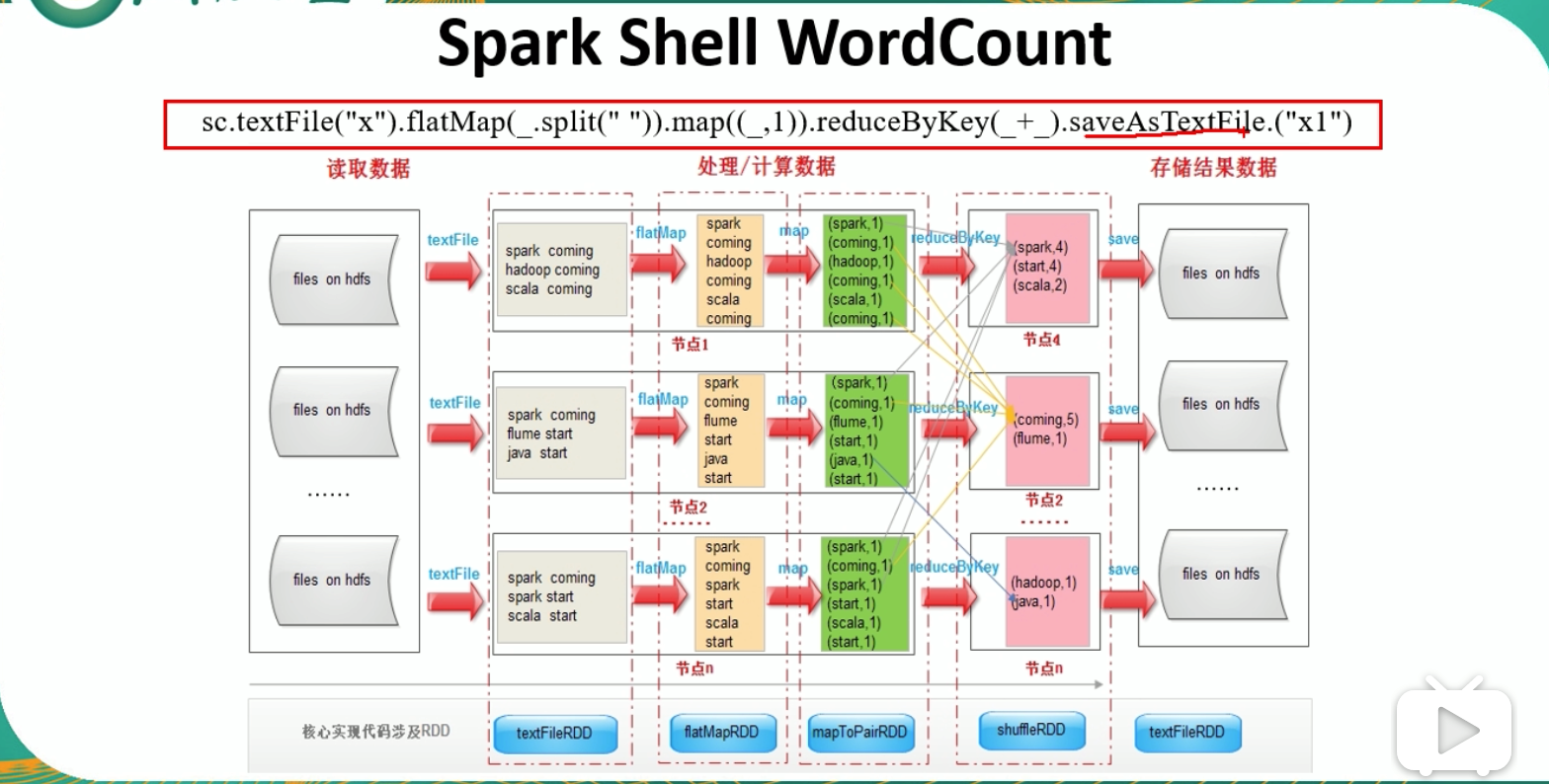
1.6 Spark Shell WordCount 流程
sc.textFile("文件地址").flatMap(_.split("")).map((_,1)).reduceByKey(_+_).saveAsTextFile.("输出结果")
1.6 Eclipse 编写 WordCount 程序
// ===== 1. 创建 Maven Project
// ===== 2. 导入依赖 pom.xml
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.3</version>
</dependency>
</dependencies>
<build>
<finalName>WordCount</finalName>
<plugins>
<!--java 的编译版本 1.8-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.17</version>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>test-compile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<archive>
<manifest>
<mainClass>com.noodles.WordCount</mainClass>
</manifest>
</archive>
<descriptorRefs>jar-with-dependencies</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
// ===== 3. 创建 Maven Module
// ===== 4. 创建 Scala Class: WordCount
object WordCount {
def main(args:Array[String]): Unit = {
// 1. 创建配置信息
val conf = new SparkConf().setAppName("wc")
// 2. 创建 sparkcontext
val sc = new SparkContext(conf)
// 3. 处理逻辑
// 读取数据
val lines = sc.textFile(args(0))
val words = lines.flatMap(_.split(" "))
val k2v = words.map((_, 1))
val result = k2v.reduceByKey(_+_)
// 输出
// result.collect()
// 将输出结果保存到文件
result.saveAsTextFile(args(1))
// 4. 关闭连接
sc.stop()
}
}
**参考资料:**
- [spark-2.1.3-bin-hadoop2.7.tgz下载](https://archive.apache.org/dist/spark/spark-2.1.3/)
- [eclipse的maven、Scala环境搭建](https://blog.csdn.net/u014353787/article/details/50166789)
Spark 基础操作的更多相关文章
- 【原创 Hadoop&Spark 动手实践 5】Spark 基础入门,集群搭建以及Spark Shell
Spark 基础入门,集群搭建以及Spark Shell 主要借助Spark基础的PPT,再加上实际的动手操作来加强概念的理解和实践. Spark 安装部署 理论已经了解的差不多了,接下来是实际动手实 ...
- List基础操作
/** * List基础操作 * Created by zhen on 2018/11/14. */ object ListDemo { def main(args: Array[String]) { ...
- 最全的spark基础知识解答
原文:http://www.36dsj.com/archives/61155 一. Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduc ...
- 【一】Spark基础
Spark基础 什么是spark 也是一个分布式的并行计算框架 spark是下一代的map-reduce,扩展了mr的数据处理流程. Spark架构原理图解 RDD[Resilient Distrib ...
- Update(Stage4):sparksql:第3节 Dataset (DataFrame) 的基础操作 & 第4节 SparkSQL_聚合操作_连接操作
8. Dataset (DataFrame) 的基础操作 8.1. 有类型操作 8.2. 无类型转换 8.5. Column 对象 9. 缺失值处理 10. 聚合 11. 连接 8. Dataset ...
- Spark基础学习精髓——第一篇
Spark基础学习精髓 1 Spark与大数据 1.1 大数据基础 1.1.1 大数据特点 存储空间大 数据量大 计算量大 1.1.2 大数据开发通用步骤及其对应的技术 大数据采集->大数据预处 ...
- StructuredStreaming基础操作和窗口操作
一.流式DataFrames/Datasets的结构类型推断与划分 ◆ 默认情况下,基于文件源的结构化流要求必须指定schema,这种限制确保即 使在失败的情况下也会使用一致的模式来进行流查询. ◆ ...
- python基础操作以及hdfs操作
目录 前言 基础操作 hdfs操作 总结 一.前言 作为一个全栈工程师,必须要熟练掌握各种语言...HelloWorld.最近就被"逼着"走向了python开发之路, ...
- MYSQL基础操作
MYSQL基础操作 [TOC] 1.基本定义 1.1.关系型数据库系统 关系型数据库系统是建立在关系模型上的数据库系统 什么是关系模型呢? 1.数据结构可以规定,同类数据结构一致,就是一个二维的表格 ...
随机推荐
- VMware安装VMwaretools
默认点击“安装VMware Tools(T)”选项下载好安装包 下载的安装包放在计算机的media目录下 进入/media/ubuntu14-04/VMware Tools目录: cd /media/ ...
- 统计单词Java
功能0:输出某个英文文本文件中 26 字母出现的频率,由高到低排列,并显示字母出现的百分比,精确到小数点后面两位. 功能1:输出文件中所有不重复的单词,按照出现次数由多到少排列,出现次数同样多的,以字 ...
- fluent懒人篇之journal的用法【转载】
转载地址:http://blog.sina.cn/dpool/blog/s/blog_63a80e870100oblp.html?type=-1 当你在用fluent计算大量类似算例,重复着相同操作的 ...
- kubernetes(K8S)集群及Dashboard安装配置
环境准备 机器信息 主机名 操作系统 IP地址 K8sm-218 Centos 7.5-x86_64 172.17.0.218 k8s-219 Centos 7.5-x86_64 172.17.0.2 ...
- 纯JavaScript开发飞机大战项目
开发工具: HBuilder 编程语言:JavaScript 其他技术:Html + Css 项目截图: 视频: 源代码: 在线观看地址: (暂无) 百度网盘下载地址: 请加QQ群:915 ...
- Nginx-实践篇(重要)
原文链接:https://blog.csdn.net/Fe_cow/article/details/84672361
- python+opencv图像变换的两种方法cv2.warpAffine和cv2.warpPerspective
本文链接:https://blog.csdn.net/qq_27261889/article/details/80720359 # usr/bin/env python # coding: utf- ...
- linux下apache安装ssl步骤
制作证书: 参考:linux下运用opensll制作ssl证书 生成三个证书 server.crt .server-ca.crt.server.key 安装openssl tar -xzvf open ...
- JDK动态代理在RPC框架中的应用
RPC框架中一般都有3个角色:服务提供者.服务消费者和注册中心.服务提供者将服务注册到注册中心,服务消费者从注册中心拉取服务的地址,并根据服务地址向服务提供者发起RPC调用.动态代理在这个RPC调用的 ...
- 用filter求素数
计算素数的一个方法是埃氏筛法, 所有的奇数: def _odd_iter(): n = 1 while True: n = n + 2 yield n 定义一个筛选函数: def _not_divis ...