Kafka 通过python简单的生产消费实现
使用CentOS6.5、python3.6、kafkaScala 2.10 - kafka_2.10-0.8.2.2.tgz (asc, md5)
一、下载kafka
下载地址
https://kafka.apache.org/downloads
里面包含zookeeper
二、安装Kafka
1、安装zookeeper
mkdir /root/kafka/
tar -vzxf kafka_2.10-0.8.2.2

cd /root/kafka/kafka_2.10-0.8.2.2
cat config/zookeeper.properties | grep -v '#' >> config/zk.properties
mkdir -p /home/kafka/zk
vi zk.properties
dataDir=/home/kafka/zk #因为zookeeper变更为zk,所以需要在这里修改一下
启动zookeeper(后台启动)
/root/kafka/kafka_2.10-0.8.2.2/bin/zookeeper-server-start.sh /root/kafka/kafka_2.10-0.8.2.2/config/zk.properties &
2、安装Kafka
cd /root/kafka/kafka_2.10-0.8.2.2
cat config/server.properties | grep -v '#' >> config/kafka_01.properties
启动Kafka(后台启动)
/root/kafka/kafka_2.10-0.8.2.2/bin/kafka-server-start.sh /root/kafka/kafka_2.10-0.8.2.2/config/kafka_01.properties &
三、新建Kafka topic
1、新建topic
cd /root/kafka/kafka_2.10-0.8.2.2
./bin/kafka-topics.sh --create --zookeeper 192.168.50.33:2181 --replication-factor 1 --partitions 1 --topic test
2、查看topic
./bin/kafka-topics.sh --list --zookeeper 192.168.50.33:2181
四、kafka生产者脚本
1、安装python的Kafka模块
pip3 install kafka-python(之前已安装)

2、kafka生产者脚本
from kafka import KafkaProducer
from kafka import KafkaConsumer
from kafka.errors import KafkaError
import json
import time
'''
使用kafka的生产模块
'''
self.kafkaHost = kafkahost
self.kafkaPort = kafkaport
self.kafkatopic = kafkatopic
self.producer = KafkaProducer(bootstrap_servers='{kafka_host}:{kafka_port}'.format(
kafka_host=self.kafkaHost,
kafka_port=self.kafkaPort
))
try:
parmas_message = json.dumps(params)
producer = self.producer
producer.send(self.kafkatopic, parmas_message.encode('utf-8'))
producer.flush()
except KafkaError as e:
print(e)
'''
测试consumer和producer
:return:
'''
# 测试生产模块
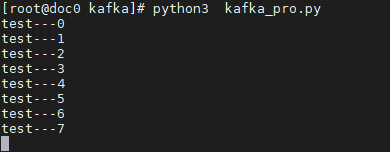
producer = Kafka_producer("127.0.0.1",9092,"test")
for i in range(1000000000000):
params = 'test---' + str(i)
print(params)
producer.sendjsondata(params)
time.sleep(1)
main()
import os
print(os.uname)
五、kafka消费者脚本
from kafka import KafkaProducer
from kafka import KafkaConsumer
from kafka.errors import KafkaError
import json
import time
'''
使用Kafka—python的消费模块
'''
self.kafkaHost = kafkahost
self.kafkaPort = kafkaport
self.kafkatopic = kafkatopic
self.groupid = groupid
self.consumer = KafkaConsumer(self.kafkatopic, group_id=self.groupid,
bootstrap_servers='{kafka_host}:{kafka_port}'.format(
kafka_host=self.kafkaHost,
kafka_port=self.kafkaPort))
try:
for message in self.consumer:
# print json.loads(message.value)
yield message
except KeyboardInterrupt as e:
print(e)
'''
测试consumer和producer
:return:
'''
# 测试消费模块
# 消费模块的返回格式为ConsumerRecord(topic=u'ranktest', partition=0, offset=202, timestamp=None,
# \timestamp_type=None, key=None, value='"{abetst}:{null}---0"', checksum=-1868164195,
# \serialized_key_size=-1, serialized_value_size=21)
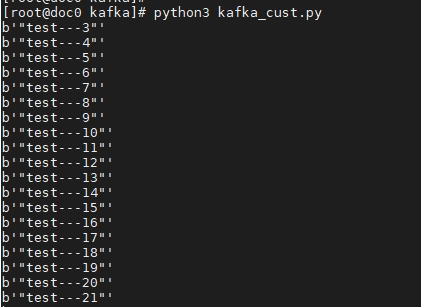
consumer = Kafka_consumer('127.0.0.1',
9092,
"test",
'test-python-test')
message = consumer.consume_data()
for i in message:
print(i.value)
main()
Kafka 通过python简单的生产消费实现的更多相关文章
- Python并发编程-生产消费模型
生产消费模型初步 #产生两个子进程,Queue可以在子进程之间传递消息 from multiprocessing import Queue,Process import random import t ...
- Kafka(三)Kafka的高可用与生产消费过程解析
一 Kafka HA设计解析 1.1 为何需要Replication 在Kafka在0.8以前的版本中,是没有Replication的,一旦某一个Broker宕机,则其上所有的Partition数据 ...
- Kafka创建&查看topic,生产&消费指定topic消息
启动zookeeper和Kafka之后,进入kafka目录(安装/启动kafka参考前面一章:https://www.cnblogs.com/cici20166/p/9425613.html) 1.创 ...
- 【Apache Kafka】二、Kafka安装及简单示例
(一)Apache Kafka安装 1.安装环境与前提条件 安装环境:Ubuntu16.04 前提条件: ubuntu系统下安装好jdk 1.8以上版本,正确配置环境变量 ubuntu系统下安 ...
- kafka生产消费原理笔记
一.什么是kafka Kafka是最初由Linkedin公司开发,是一个分布式.支持分区的(partition).多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性 ...
- kafka之三:kafka java 生产消费程序demo示例
kafka是吞吐量巨大的一个消息系统,它是用scala写的,和普通的消息的生产消费还有所不同,写了个demo程序供大家参考.kafka的安装请参考官方文档. 首先我们需要新建一个maven项目,然后在 ...
- 【java并发编程】Lock & Condition 协调同步生产消费
一.协调生产/消费的需求 本文内容主要想向大家介绍一下Lock结合Condition的使用方法,为了更好的理解Lock锁与Condition锁信号,我们来手写一个ArrayBlockingQueue. ...
- Python 简单入门指北(二)
Python 简单入门指北(二) 2 函数 2.1 函数是一等公民 一等公民指的是 Python 的函数能够动态创建,能赋值给别的变量,能作为参传给函数,也能作为函数的返回值.总而言之,函数和普通变量 ...
- Kafka实战-简单示例
1.概述 上一篇博客<Kafka实战-Kafka Cluster>中,为大家介绍了Kafka集群的安装部署,以及对Kafka集群Producer/Consumer.HA等做了相关测试,今天 ...
随机推荐
- flask框架(一)——初识Flask
一.初识flask 1.什么是Flask:Flask是一个python编写的web框架,只是一个内核,默认依赖2个外部库:jinja2模板引擎和WSGI工具集--Werkzeug. 2.安装flask ...
- docker深入学习二
dicker:数据管理 数据管理机制 docker使用union file system来管理数据,docker构建image和container也是采用了同样的技术. image层次 iamge由多 ...
- SpringCloud之Ribbon负载均衡及Feign消费者调用服务
目的: 微服务调用Ribbon Ribbon负载均衡 Feign简介及应用 微服务调用Ribbon Ribbon简介 1. 负载均衡框架,支持可插拔式的负载均衡规则 2. 支持多种协议,如HTTP.U ...
- DDL和DML 的区别
DDL (Data Definition Language 数据定义语言) create table 创建表 alter table 修改表 drop table 删除表 truncate table ...
- MVC4 部署 could not load file or assembly system.web.http.webhost 或是其它文件出误
自从VS2010发布之后使用它来做开发的程序员越来越多,其中很多人使用了MVC来作为新的开发框架,但是在系统部署的时候我们也遇到诸多问题,因为目前大多数windows服务器采用的还是Windows S ...
- 浮动和渐变色,定位position,元素的层叠顺序
浮动: float 是我们网页布局的一种 浮动 可以有 left 左浮动 right 右浮动 两种 浮动的特点: 脱离正常的文档流,原本的空间不占据,浮动的标签都具有块级标签的一些特点,可以手动设置宽 ...
- springboot+security整合(2)自定义校验
说明 springboot 版本 2.0.3源码地址:点击跳转 系列 springboot+security 整合(1) springboot+security 整合(2) springboot+se ...
- Java 之 常用函数式接口
JDK提供了大量常用的函数式接口以丰富Lambda的典型使用场景,它们主要在 java.util.function 包中被提供.下面是最简单的几个接口及使用示例. 一.Supplier 接口 java ...
- MySQL Innodb--共享临时表空间和临时文件
在MySQL 5.7版本中引入Online DDL特性和共享临时表空间特性,临时数据主要存放形式为: 1.DML命令执行过程中文件排序(file sore)操作生成的临时文件,存储目录由参数tmpdi ...
- 多选文件批量上传前端(ajax*formdata)+后台(Request.Files[i])---input+ajax原生上传
1.配置Web.config;设定上传文件大小 <system.web> <!--上传1000M限制(https://www.cnblogs.com/Joans/p/4315411. ...