12、基于yarn的提交模式
一、三种提交模式
1、Spark内核架构,其实就是第一种模式,standalone模式,基于Spark自己的Master-Worker集群。 2、第二种,是基于YARN的yarn-cluster模式。 3、第三种,是基于YARN的yarn-client模式。 4、如果,你要切换到第二种和第三种模式,很简单,将我们之前用于提交spark应用程序的spark-submit脚本,加上--master参数,设置为yarn-cluster,或yarn-client,即可。
如果你没设置,那么,就是standalone模式。
二、基于YARN的提交模式
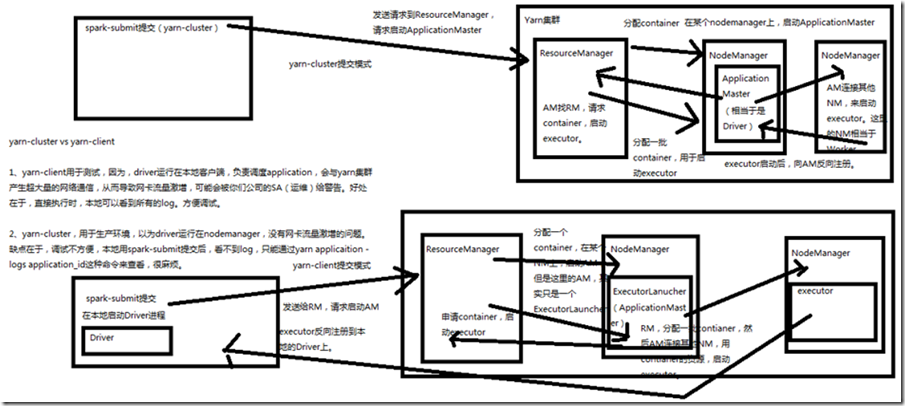
1、基于YARN的yarn-cluster模式
流程详细分析: spark-submit提交(yarn-cluster),发送请求到ResourceManager,请求启动ApplicationMaster,ResourceManager接收到请求后,会在某个NodeManager上分配container,启动ApplicationMaster
ResourceManager分配Container,在某个NodeManager上,启动ApplicationMaster ApplicationMaster(相当于是Driver) ApplicationMaster找ResourceManager,请求container,启动Executor ResourceManager分配一批container,用于启动Executor
ApplicationMaster所在的NodeManager上,可能会启动Executor ApplicationMaster连接其他NodeManager,来启动Executor,这里的NameNode相当于Wroker
Executor启动后,向ApplicationMaster反向注册
2、基于YARN的yarn-client模式
流程详细分析:
spark-submit提交(yarn-client),会在本地启动Driver进程
发送给ResourceManager,请求启动ApplicationMaster ResourceManager分配Container,在某个NodeManager上启动ApplicationMaster,但这里的ApplicationMaster,其实只是一个ExecutorLauncher ExecutorLauncher(ApplicationMaster)申请Container,启动executor ResourceManager分配一批Container
,ExecutorLauncher(ApplicationMaster)所在的NodeManager上,可能会启动Executor ExecutorLauncher(ApplicationMaster)连接其他NodeManager,用Container资源,启动Executor
Executor反向注册到本地的Driver上
3、以上两种模式对比
1、yarn-client模式用于测试,因为driver运行在本地客户端,负责调度application,会与yarn集群产生超大量的网络通信,从而导致网卡流量激增,
可能会被公司的运维给警告,好处在于,直接执行时,本地可以看到所有log,方便调试 2、
yarn-cluster,用于生产环境,因为driver运行在NodeManager,没有网卡流量激增的问题,缺点在于,调试不方便,本地用spark-submit提交后,看不到log,
只能通过yarn application -logs application_id这种命令来查看,很麻烦
4、设置
##修改spark-env.sh
[root@spark1 ~]# vim /usr/local/spark/conf/spark-env.sh #写入hadoop的home
export HADOOP_HOME=/usr/local/hadoop ###脚本文件 yarn-cluster: /opt/module/spark/bin/spark-submit \ --class com.zj.spark.core.WordCountCluster \ --master yarn-cluster \ --num-executors 3 \ --driver-memory 100m \ --executor-memory 100m \ --executor-cores 3 \
/opt/module/datas/sparkstudy/java/mysparkstudy-1.0-SNAPSHOT-jar-with-dependencies.jar \ yarn-client:
/opt/module/spark/bin/spark-submit \ --class com.zj.spark.core.WordCountCluster \ --master yarn-client \ --num-executors 3 \ --driver-memory 100m \ --executor-memory 100m \ --executor-cores 3 \ /opt/module/datas/sparkstudy/java/mysparkstudy-1.0-SNAPSHOT-jar-with-dependencies.jar \
12、基于yarn的提交模式的更多相关文章
- spark基于yarn的两种提交模式
一.spark的三种提交模式 1.第一种,Spark内核架构,即standalone模式,基于Spark自己的Master-Worker集群. 2.第二种,基于YARN的yarn-cluster模式. ...
- Spark剖析-宽依赖与窄依赖、基于yarn的两种提交模式、sparkcontext原理剖析
Spark剖析-宽依赖与窄依赖.基于yarn的两种提交模式.sparkcontext原理剖析 一.宽依赖与窄依赖 二.基于yarn的两种提交模式深度剖析 2.1 Standalne-client 2. ...
- Spark运行模式_基于YARN的Resource Manager的Custer模式(集群)
使用如下命令执行应用程序: 和"基于YARN的Resource Manager的Client模式(集群)"运行模式,区别如下: 在Resource Manager端提交应用程序,会 ...
- Flink源码阅读(一)——Flink on Yarn的Per-job模式源码简析
一.前言 个人感觉学习Flink其实最不应该错过的博文是Flink社区的博文系列,里面的文章是不会让人失望的.强烈安利:https://ververica.cn/developers-resource ...
- 基于事件的异步模式(EAP)
什么是EAP异步编程模式 EAP基于事件的异步模式是.net 2.0提出来的,实现了基于事件的异步模式的类将具有一个或者多个以Async为后缀的方法和对应的Completed事件,并且这些类都支持异步 ...
- Entity Framework 实体框架的形成之旅--基于泛型的仓储模式的实体框架(1)
很久没有写博客了,一些读者也经常问问一些问题,不过最近我确实也很忙,除了处理日常工作外,平常主要的时间也花在了继续研究微软的实体框架(EntityFramework)方面了.这个实体框架加入了很多特性 ...
- Event-based Asynchronous Pattern Overview基于事件的异步模式概览
https://msdn.microsoft.com/zh-cn/library/wewwczdw(v=vs.110).aspx Applications that perform many task ...
- 基于Java 生产者消费者模式(详细分析)
Java 生产者消费者模式详细分析 本文目录:1.等待.唤醒机制的原理2.Lock和Condition3.单生产者单消费者模式4.使用Lock和Condition实现单生产单消费模式5.多生产多消费模 ...
- spark提交模式
spark基本的提交语句: ./bin/spark-submit \ --class <main-class> \ --master <master-url> \ --depl ...
随机推荐
- 你有自信写while(true)吗?
每次写while(true)的时候会不会心虚? 特别逻辑稍微复杂一点
- ADO.NET 一(概述)
在 C# 语言中 ADO.NET 是在 ADO 的基础上发展起来的,ADO (Active Data Object) 是一个 COM 组件类库,用于访问数据库,而 ADO.NET 是在 .NET 平台 ...
- ChipGenius 识别U盘主控信息
ChipGenius 识别U盘主控信息 ================== End
- spring的事务传播行为与隔离级别
具体请参考blog:https://bbs.csdn.net/topics/391875990 要明白2个概念: 1.“spring的事务传播属性” 2.“spring的事务隔离级别” 例如正常的sp ...
- VBA 字符串-相关函数(1-5)
Instr()函数 InStr()函数返回一个字符串第一次出现在一个字符串,从左到右搜索.返回搜索到的字符索引位置. 语法 InStr([start,]string1,string2[,compare ...
- js造成内存泄漏的几种情况
1.介绍js的垃圾回收机制 js的垃圾回收机制就是为了防止内存泄漏的,内存泄漏的含义就是当已经不需要某块内存时这块内存还存在着,垃圾回收机制就是间歇的不定期的寻找到不再使用的变量,并释放掉它们所指向的 ...
- Java必备技能:clone浅克隆与深克隆
介绍 一直以来只知道Java有clone方法,该方法属于Object的,对于什么是浅克隆与深克隆就比较模糊了,现在就来补充学习一下. 概念 浅拷贝(浅克隆)复制出来的对象的所有变量都含有与原来的对象相 ...
- 为群晖加把锁:使用ssh密钥保障数据安全
对每一个使用群晖nas的人而言,能保证群晖里保存的数据不被未经授权的人访问下载甚至破坏可能是最重要的事情.但数据只要上网,就免不了担心密码被破解,群晖被侵入.现在网络上,要破解密码可能是最简单不过的事 ...
- 基于Java+Selenium的WebUI自动化测试框架(十三)-----基础页面类BasePage(Excel)
前面,我们讲了如何使用POI进行Excel的“按需读取”.根据前面我们写的BasePageX,我们可以很轻松的写出来基于这个“按需读取”的BasePage. package webui.xUtils; ...
- pytest使用
安装: pip install pytest pip install pytest-cov utils.py代码 def add(a, b): return a+b def inc(x): retur ...