Spark GraphX图算法应用【分区策略、PageRank、ConnectedComponents,TriangleCount】
一.分区策略
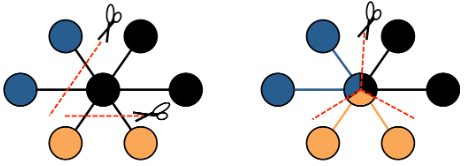
GraphX采用顶点分割的方式进行分布式图分区。GraphX不会沿着边划分图形,而是沿着顶点划分图形,这可以减少通信和存储的开销。从逻辑上讲,这对应于为机器分配边并允许顶点跨越多台机器。分配边的方法取决于分区策略PartitionStrategy并且对各种启发式方法进行了一些折中。用户可以使用Graph.partitionBy运算符重新划分图【可以使用不同分区策略】。默认的分区策略是使用图形构造中提供的边的初始分区。但是,用户可以轻松切换到GraphX中包含的2D分区或其他启发式方法。
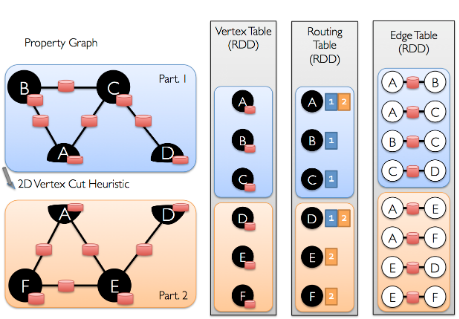
一旦对边进行了划分,高效图并行计算的关键挑战就是将顶点属性和边有效结合。由于现实世界中的图通常具有比顶点更多的边,因此我们将顶点属性移到边上。由于并非所有分区都包含与所有顶点相邻的边,因此我们在内部维护一个路由表,该路由表在实现诸如triplets操作所需要的连接时,标示在哪里广播顶点aggregateMessages。
二.测试数据
1.users.txt

2.followers.txt

3.数据可视化

三.PageRank网页排名
1.简介
使用PageRank测量图中每个顶点的重要性,假设从边u到v表示的认可度x。例如,如果一个Twitter用户被许多其他用户关注,则该用户将获得很高的排名。GraphX带有PageRank的静态和动态实现,作为PageRank对象上的方法。静态PageRant运行固定的迭代次数,而动态PageRank运行直到排名收敛【变化小于指定的阈值】。GraphOps运行直接方法调用这些算法。
2.代码实现
package graphx
import org.apache.log4j.{Level, Logger}
import org.apache.spark.graphx.GraphLoader
import org.apache.spark.sql.SparkSession
/**
* Created by Administrator on 2019/11/27.
*/
object PageRank {
Logger.getLogger("org").setLevel(Level.WARN)
def main(args: Array[String]) {
val spark = SparkSession.builder()
.master("local[2]")
.appName(s"${this.getClass.getSimpleName}")
.getOrCreate()
val sc = spark.sparkContext
val graph = GraphLoader.edgeListFile(sc, "D:\\software\\spark-2.4.4\\data\\graphx\\followers.txt")
// 调用PageRank图计算算法
val ranks = graph.pageRank(0.0001).vertices
// join
val users = sc.textFile("D:\\software\\spark-2.4.4\\data\\graphx\\users.txt").map(line => {
val fields = line.split(",")
(fields(0).toLong, fields(1))
})
// join
val ranksByUsername = users.join(ranks).map{
case (id, (username, rank)) => (username, rank)
}
// print
ranksByUsername.foreach(println)
}
}
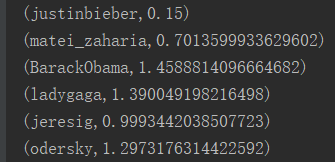
3.执行结果
四.ConnectedComponents连通体算法
1.简介
连通体算法实现把图划分为多个子图【不进行节点切分】,清除孤岛子图【只要一个节点的子图】。其使用子图中编号最小的顶点ID标记子图。
2.代码实现
package graphx
import org.apache.log4j.{Level, Logger}
import org.apache.spark.graphx.GraphLoader
import org.apache.spark.sql.SparkSession
/**
* Created by Administrator on 2019/11/27.
*/
object ConnectedComponents {
Logger.getLogger("org").setLevel(Level.WARN)
def main(args: Array[String]) {
val spark = SparkSession.builder()
.master("local[2]")
.appName(s"${this.getClass.getSimpleName}")
.getOrCreate()
val sc = spark.sparkContext
val graph = GraphLoader.edgeListFile(sc, "D:\\software\\spark-2.4.4\\data\\graphx\\followers.txt")
// 调用connectedComponents连通体算法
val cc = graph.connectedComponents().vertices
// join
val users = sc.textFile("D:\\software\\spark-2.4.4\\data\\graphx\\users.txt").map(line => {
val fields = line.split(",")
(fields(0).toLong, fields(1))
})
// join
val ranksByUsername = users.join(cc).map {
case (id, (username, rank)) => (username, rank)
}
val count = ranksByUsername.count().toInt
// print
ranksByUsername.map(_.swap).takeOrdered(count).foreach(println)
}
}
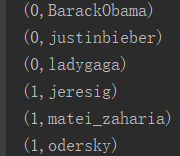
3.执行结果

五.TriangleCount三角计数算法
1.简介
当顶点有两个相邻的顶点且它们之间存在边时,该顶点是三角形的一部分。GraphX在TriangleCount对象中实现三角计数算法,该算法通过确定经过每个顶点的三角形的数量,从而提供聚类的度量。注意,TriangleCount要求边定义必须为规范方向【srcId < dstId】,并且必须使用Graph.partitionBy对图进行分区。
2.代码实现
package graphx
import org.apache.log4j.{Level, Logger}
import org.apache.spark.graphx.{PartitionStrategy, GraphLoader}
import org.apache.spark.sql.SparkSession
/**
* Created by Administrator on 2019/11/27.
*/
object TriangleCount {
Logger.getLogger("org").setLevel(Level.WARN)
def main(args: Array[String]) {
val spark = SparkSession.builder()
.master("local[2]")
.appName(s"${this.getClass.getSimpleName}")
.getOrCreate()
val sc = spark.sparkContext
val graph = GraphLoader.edgeListFile(sc, "D:\\software\\spark-2.4.4\\data\\graphx\\followers.txt", true)
.partitionBy(PartitionStrategy.RandomVertexCut)
// 调用triangleCount三角计数算法
val triCounts = graph.triangleCount().vertices
// map
val users = sc.textFile("D:\\software\\spark-2.4.4\\data\\graphx\\users.txt").map(line => {
val fields = line.split(",")
(fields(0).toLong, fields(1))
})
// join
val triCountByUsername = users.join(triCounts).map { case (id, (username, tc)) =>
(username, tc)
}
val count = triCountByUsername.count().toInt
// print
triCountByUsername.map(_.swap).takeOrdered(count).foreach(println)
}
}
3.执行结果
Spark GraphX图算法应用【分区策略、PageRank、ConnectedComponents,TriangleCount】的更多相关文章
- 大数据技术之_19_Spark学习_05_Spark GraphX 应用解析 + Spark GraphX 概述、解析 + 计算模式 + Pregel API + 图算法参考代码 + PageRank 实例
第1章 Spark GraphX 概述1.1 什么是 Spark GraphX1.2 弹性分布式属性图1.3 运行图计算程序第2章 Spark GraphX 解析2.1 存储模式2.1.1 图存储模式 ...
- Spark GraphX从入门到实战
第1章 Spark GraphX 概述 1.1 什么是 Spark GraphX Spark GraphX 是一个分布式图处理框架,它是基于 Spark 平台提供对图计算和图挖掘简洁易用的而丰 ...
- Spark Graphx编程指南
问题导读1.GraphX提供了几种方式从RDD或者磁盘上的顶点和边集合构造图?2.PageRank算法在图中发挥什么作用?3.三角形计数算法的作用是什么?Spark中文手册-编程指南Spark之一个快 ...
- 2. Spark GraphX解析
2.1 存储模式 2.1.1 图存储模式 巨型图的存储总体上有边分割和点分割两种存储方式 1)边分割(Edge-Cut):每个顶点都存储一次,但有的边会被打断分到两台机器上.这样做的好处是节省存储空间 ...
- Spark—GraphX编程指南
Spark系列面试题 Spark面试题(一) Spark面试题(二) Spark面试题(三) Spark面试题(四) Spark面试题(五)--数据倾斜调优 Spark面试题(六)--Spark资源调 ...
- 明风:分布式图计算的平台Spark GraphX 在淘宝的实践
快刀初试:Spark GraphX在淘宝的实践 作者:明风 (本文由团队中梧苇和我一起撰写,并由团队中的林岳,岩岫,世仪等多人Review,发表于程序员的8月刊,由于篇幅原因,略作删减,本文为完整版) ...
- Apache Spark GraphX的体系结构
1. 整体架构 GraphX 的整体架构(如图 1所示)可以分为三部分. 图 1 GraphX 架构 存储和原语层: Graph 类是图计算的核心类.内部含有 VertexRDD. EdgeRDD ...
- 1. Spark GraphX概述
1.1 什么是Spark GraphX Spark GraphX是一个分布式图处理框架,它是基于Spark平台提供对图计算和图挖掘简洁易用的而丰富的接口,极大的方便了对分布式图处理的需求.那么什么是图 ...
- Spark Graphx
Graphx 概述 Spark GraphX是一个分布式图处理框架,它是基于Spark平台提供对图计算和图挖掘简洁易用的而丰富的接口,极大的方便了对分布式图处理的需求. ...
随机推荐
- python-分割url字符串
url = ' http://images.jupiterimages.com/common/detail/27/68/22986827.jpg' url.strip().split('/')[-1] ...
- ASP.NET开发实战——(五)ASP.NET MVC & 分层
上一篇文章简要说明了MVC所代表的含义并提供了详细的项目及其控制器.视图等内容的创建步骤,最终完成了一个简单ASP.NET MVC程序. 注:MVC与ASP.NET MVC不相等,MVC是一种开发模式 ...
- ASP.NET开发实战——(二)为什么使用ASP.NET
本文主要内容是通过分析<博客系统>需求,确定使用Web应用的形式来开发,然后介绍了HTML.HTTP的概念,并使用IIS搭建了一个静态的HTML“页面”,从而引出“动态”的ASP.NET. ...
- 爬虫,爬取景点信息采用pandas整理数据
一.首先需要导入我们的库函数 导语:通过看网上直播学习得到,如有雷同纯属巧合. import requests#请求网页链接import pandas as pd#建立数据模型from bs4 imp ...
- windows下sed回车换行符处理
windows下sed回车换行符处理如果用sed for windows对整个文件进行了编辑,编辑之后一般需要处理回车换行符:rem windows的回车换行符是\r\n,linux的是\n,所以要替 ...
- 做作业时看到的 Demo
public class HelloWorld { public static void main(String[] args) { outer: for(int i = 0;i < 3; i+ ...
- Visual Studio 调试系列7 查看变量占用的内存(使用内存窗口)
系列目录 [已更新最新开发文章,点击查看详细] 在调试期间,“内存”窗口显示应用程序正在使用的内存空间. 调试器窗口(如监视窗口.自动窗口.局部变量窗口和快速监视对话框)显示变量,这些变量存储 ...
- 分布式数据库缓存系统Apache Ignite
Apache Ignite内存数据组织是高性能的.集成化的以及分布式的内存平台,他可以实时地在大数据集中执行事务和计算,和传统的基于磁盘或者闪存的技术相比,性能有数量级的提升. 将数据存储在缓存中能够 ...
- PHP的小技巧
PHP的小技巧fdd()[0]函数后面可以直接加数组索引 这样可以省内存占用啦 代码也更简洁
- tk.mybatis 中一直报...table doesn't exists
首先检查你在实体类中可有加上@Table(name="数据库中的表名") 第二:如果你加了@Table注解, 那么只有一种可能就是.xml中定义了与通用mapper中的相同的方法名 ...