Triton 学习
介绍
Triton 是一款动态二进制分析框架,它支持符号执行和污点分析,同时提供了 pintools 的 python 接口,我们可以使用 python 来使用 pintools 的功能。 Triton 支持的架构有 x86, x64, AArch64.
所有相关文件位于
https://gitee.com/hac425/data/tree/master/triton
安装
首先需要安装依赖
sudo apt-get install libz3-dev libcapstone-dev libboost-dev libopenmpi-dev
然后根据官网教程进行安装
$ git clone https://github.com/JonathanSalwan/Triton.git
$ cd Triton
$ mkdir build
$ cd build
$ cmake ..
$ sudo make -j install
报错的解决方案
缺少 openmp 库
[ 86%] Built target python-triton
[ 87%] Linking CXX executable simplification
../../libtriton/libtriton.so: undefined reference to `omp_get_thread_num'
../../libtriton/libtriton.so: undefined reference to `omp_get_num_threads'
../../libtriton/libtriton.so: undefined reference to `omp_destroy_nest_lock'
../../libtriton/libtriton.so: undefined reference to `omp_set_nest_lock'
../../libtriton/libtriton.so: undefined reference to `omp_get_num_procs'
../../libtriton/libtriton.so: undefined reference to `omp_unset_nest_lock'
../../libtriton/libtriton.so: undefined reference to `GOMP_critical_name_end'
../../libtriton/libtriton.so: undefined reference to `omp_in_parallel'
../../libtriton/libtriton.so: undefined reference to `omp_init_nest_lock'
../../libtriton/libtriton.so: undefined reference to `GOMP_parallel'
../../libtriton/libtriton.so: undefined reference to `omp_set_nested'
../../libtriton/libtriton.so: undefined reference to `GOMP_critical_name_start'
collect2: error: ld returned 1 exit status
在 CMakeLists.txt 增加编译参数
在 CMakeLists.txt 增加编译参数
set(CMAKE_C_FLAGS "-fopenmp")
set(CMAKE_CXX_FLAGS "-fopenmp")
z3版本太老
如果使用 ubuntu 16.04 由于 apt 的 z3 版本太老,需要下载最新版的 z3 进行编译, 然后使用新版的 z3 来编译.
cmake .. -DZ3_INCLUDE_DIRS="/home/hac425/z3-4.8.4.d6df51951f4c-x64-ubuntu-16.04/include" -DZ3_LIBRARIES="/home/hac425/z3-4.8.4.d6df51951f4c-x64-ubuntu-16.04/bin/libz3.a"
使用介绍
下面以一些使用示例来介绍 Triton 的使用, Triton 的基本使用流程是提取出指令的字节码和指令的地址,然后传递给 Triton 去执行指令,在指令的执行过程中会维持符号量和污点值的传播。
模拟执行
Triton 首先的一个应用场景就是模拟执行,在 Triton 中执行的执行是由我们控制的,污点分析和符号执行都是基于模拟执行实现的。
下面是一个模拟执行的示例
#!/usr/bin/env python2
# -*- coding: utf-8 -*-
from __future__ import print_function
from triton import TritonContext, ARCH, Instruction, OPERAND
import sys
# 每一项的结构是 (指令的地址, 指令的字节码)
code = [
(0x40000, b"\x40\xf6\xee"), # imul sil
(0x40003, b"\x66\xf7\xe9"), # imul cx
(0x40006, b"\x48\xf7\xe9"), # imul rcx
(0x40009, b"\x6b\xc9\x01"), # imul ecx,ecx,0x1
(0x4000c, b"\x0f\xaf\xca"), # imul ecx,edx
(0x4000f, b"\x48\x6b\xd1\x04"), # imul rdx,rcx,0x4
(0x40013, b"\xC6\x00\x01"), # mov BYTE PTR [rax],0x1
(0x40016, b"\x48\x8B\x10"), # mov rdx,QWORD PTR [rax]
(0x40019, b"\xFF\xD0"), # call rax
(0x4001b, b"\xc3"), # ret
(0x4001c, b"\x80\x00\x01"), # add BYTE PTR [rax],0x1
(0x4001f, b"\x64\x48\x8B\x03"), # mov rax,QWORD PTR fs:[rbx]
]
if __name__ == '__main__':
Triton = TritonContext()
# 首先设置后面需要模拟执行的代码的架构, 这里是 x64 架构
Triton.setArchitecture(ARCH.X86_64)
for (addr, opcode) in code:
# 新建一个指令对象
inst = Instruction()
inst.setOpcode(opcode) # 传递字节码
inst.setAddress(addr) # 传递指令的地址
# 执行指令
Triton.processing(inst)
# 打印指令的信息
print(inst)
print(' ---------------')
print(' Is memory read :', inst.isMemoryRead())
print(' Is memory write:', inst.isMemoryWrite())
print(' ---------------')
for op in inst.getOperands():
print(' Operand:', op)
if op.getType() == OPERAND.MEM:
print(' - segment :', op.getSegmentRegister())
print(' - base :', op.getBaseRegister())
print(' - index :', op.getIndexRegister())
print(' - scale :', op.getScale())
print(' - disp :', op.getDisplacement())
print(' ---------------')
print()
sys.exit(0)
这个脚本的功能是 code 列表中的指令,并打印指令的信息。
- 首先需要新建一个
TritonContext,TritonContext用于维护指令执行过程的状态信息,比如寄存器的值,符号量的传播等,后面指令的执行过程中会修改TritonContext里面的一些状态。 - 然后调用
setArchitecture设置后面处理指令集的架构类型,在这里是ARCH.X86_64表示的是x64架构,其他两个可选项分别为:ARCH.AARCH64和ARCH.X86. - 之后就可以去执行指令了,首先需要用
Instruction类封装每条指令,设置指令的地址和字节码。 - 然后通过
Triton.processing(inst)就可以执行一条指令。 - 同时
Instruction对象里面还有一些与指令相关的信息可以使用,比如是否会读写内存,操作数的类型等,在这个示例中就是简单的打印这些信息。
下面再以 cmu 的 bomb 题目中 phase_4 为实例,加深 Triton 执行指令的流程。
首先看看 phase_4 的代码逻辑
unsigned int __cdecl phase_4(int a1)
{
unsigned int v2; // [esp+4h] [ebp-14h]
int v3; // [esp+8h] [ebp-10h]
unsigned int v4; // [esp+Ch] [ebp-Ch]
v4 = __readgsdword(0x14u);
if ( __isoc99_sscanf(a1, "%d %d", &v2, &v3) != 2 || v2 > 0xE )
explode_bomb();
if ( func4(v2, 0, 14) != 5 || v3 != 5 )
explode_bomb();
return __readgsdword(0x14u) ^ v4;
}
要求输入两个数字存放到 v2, v3 , 其中 v3 为 5, v2不能大于 0xe, 之后 v2 会传入 func4 , 并且要求 func4 的返回值为 5。这里 v2 的可能取值只有 0xe 次,这里使用 Triton 来模拟执行这段代码,然后爆破 v2 的解。我们的目标是让 func4 的返回值为 5 , 所以只需要在调用 func4 函数前开始模拟执行即可。
调用 func4 的汇编代码如下
.text:08048CED push 0Eh
.text:08048CEF push 0
.text:08048CF1 push [ebp+var_14] # var_14 --> -14
.text:08048CF4 call func4
.text:08048CF9 add esp, 10h
.text:08048CFC cmp eax, 5
v2 保存在 ebp-14 的位置,在爆破的过程中不断的重新设置 v2 (ebp-14 ) 即可。
具体代码如下
# -*- coding: utf-8 -*-
from __future__ import print_function
from triton import ARCH, TritonContext, Instruction, MODE, MemoryAccess, CPUSIZE
from triton import *
import os
import sys
EBP_ADDR = 0x100000
# 存放参数的地址
ARG_ADDR = 0x200000
Triton = TritonContext()
Triton.setArchitecture(ARCH.X86)
def init_machine():
Triton.concretizeAllMemory()
Triton.concretizeAllRegister()
Triton.clearPathConstraints()
Triton.setConcreteRegisterValue(Triton.registers.ebp, EBP_ADDR)
# 设置栈
Triton.setConcreteRegisterValue(Triton.registers.ebp, EBP_ADDR)
Triton.setConcreteRegisterValue(Triton.registers.esp, EBP_ADDR - 0x2000)
for i in range(2):
Triton.setConcreteMemoryValue(MemoryAccess(EBP_ADDR - 0x14 + i * 4, CPUSIZE.DWORD), 5)
# 加载 elf 文件到内存
def loadBinary(path):
import lief
binary = lief.parse(path)
phdrs = binary.segments
for phdr in phdrs:
size = phdr.physical_size
vaddr = phdr.virtual_address
print('[+] Loading 0x%06x - 0x%06x' % (vaddr, vaddr+size))
Triton.setConcreteMemoryAreaValue(vaddr, phdr.content)
return
def crack():
i = 1
Triton.setConcreteMemoryValue(MemoryAccess(EBP_ADDR - 0x14, CPUSIZE.DWORD), i)
pc = 0x8048CED
while pc:
# x86 指令集的字节码的最大长度为 15
opcode = Triton.getConcreteMemoryAreaValue(pc, 16)
instruction = Instruction()
instruction.setOpcode(opcode)
instruction.setAddress(pc)
Triton.processing(instruction)
if instruction.getAddress() == 0x08048D01:
print("solve! answer: %d" %(i))
break
if instruction.getAddress() == 0x8048D07:
pc = 0x8048CED
i += 1
# 重置运行时
init_machine()
# 再次设置参数
Triton.setConcreteMemoryValue(MemoryAccess(EBP_ADDR - 0x14, CPUSIZE.DWORD), i)
continue
pc = Triton.getConcreteRegisterValue(Triton.registers.eip)
print('[+] Emulation done.')
if __name__ == '__main__':
init_machine()
loadBinary(os.path.join(os.path.dirname(__file__), 'bomb'))
crack()
sys.exit(0)
一些 api 的解释
Triton.setConcreteRegisterValue(Triton.registers.ebp, EBP_ADDR)
设置具体的寄存器值,设置 ebp 为 EBP_ADDR
Triton.setConcreteMemoryValue(MemoryAccess(EBP_ADDR - 0x14, CPUSIZE.DWORD), i)
设置具体的内存值,第一个参数是一个 MemoryAccess 对象,表示一个内存范围,实例化的时候会给出内存的地址和内存的长度, 第二个参数是需要设置的值,设置值的时候会根据架构的情况按大小端设置,比如 x86 就会以小端的方式设置内存值。 这里就是往 EBP_ADDR - 0x14 的位置写入 DWORD (4 字节) 的数据,数据的内容为 i , 按照小端的方式存放、
Triton.getConcreteMemoryAreaValue(pc, 16)
获取内存数据,第一个参数是内存的地址,第二个是需要获取的内存数据的长度。这里表示从 pc 出,取出 16 字节的数据。
instruction.getAddress()
获取指令执行的地址
Triton.getConcreteRegisterValue(Triton.registers.eip)
这里可以获取下一条指令的地址,在 Triton 处理完一条指令后会更新 eip 的值为下一条指令的起始地址
程序的流程如下:
- 首先
init_machine的作用就是初始化TritonContext,同时设置ebp和esp的值,伪造一个栈。因为程序一开始和每次爆破都要保证TritonContext的一致性。 - 然后使用
loadBinary函数把bomb二进制文件加载进内存,加载使用了lief模块。 - 之后调用
crack函数开始暴力破解的过程。crack函数的主要流程是在 栈上设置v2的值 ,然后从0x8048CED开始执行,当返回值不是5时(此时会执行到0x8048D07)初始化TritonContext同时设置栈里面的参数,修改pc回到0x8048CED继续爆破,直到求出结果(此时会执行到0x08048D01)为止。
运行输出如下
hac425@ubuntu:~/pin-2.14-71313-gcc.4.4.7-linux/source/tools/Triton$ /usr/bin/python /home/hac425/pin-2.14-71313-gcc.4.4.7-linux/source/tools/Triton/src/examples/python/ctf-writeups/bomb/p4.py
[+] Loading 0x8048034 - 0x8048154
[+] Loading 0x8048154 - 0x8048167
[+] Loading 0x8048000 - 0x804a998
[+] Loading 0x804bf08 - 0x804c3a0
[+] Loading 0x804bf14 - 0x804bffc
[+] Loading 0x8048168 - 0x80481ac
[+] Loading 0x804a3f4 - 0x804a4f8
[+] Loading 0x000000 - 0x000000
[+] Loading 0x804bf08 - 0x804c000
solve! answer: 10
[+] Emulation done.
求出解是 10 .
污点分析
污点分析通过标记污点源,然后通过在执行指令时进行污点传播,来最终数据的走向。本节以 crackme_xor 二进制程序为例来介绍污点分析的使用。
程序的主要功能是把命令行参数传给 check 函数去校验, 函数的代码如下:
signed __int64 __fastcall check(__int64 a1)
{
signed int i; // [rsp+14h] [rbp-4h]
for ( i = 0; i <= 4; ++i )
{
if ( ((*(i + a1) - 1) ^ 0x55) != serial[i] )
return 1LL;
}
return 0LL;
}
通过分析代码,输入的字符串的长度为 5 个字节,然后会对输入进行一些简单的变化然后和 serial 数组进行比较。下面我们使用 Triton 的污点分析来看看追踪程序对输入内存的访问情况。
脚本如下:
#!/usr/bin/env python2
# -*- coding: utf-8 -*-
from __future__ import print_function
from triton import TritonContext, ARCH, MODE, AST_REPRESENTATION, Instruction, OPERAND
from triton import *
import sys
import os
import lief
# 加载 elf 文件到内存
INPUT_ADDR = 0x100000
RBP_ADDR = 0x600000
RSP_ADDR = RBP_ADDR - 0x200000
def loadBinary(ctx, path):
binary = lief.parse(path)
phdrs = binary.segments
for phdr in phdrs:
size = phdr.physical_size
vaddr = phdr.virtual_address
print('[+] Loading 0x%06x - 0x%06x' % (vaddr, vaddr+size))
ctx.setConcreteMemoryAreaValue(vaddr, phdr.content)
return
if __name__ == '__main__':
ctx = TritonContext()
ctx.setArchitecture(ARCH.X86_64)
ctx.enableMode(MODE.ALIGNED_MEMORY, True)
loadBinary(ctx, os.path.join(os.path.dirname(__file__), 'crackme_xor'))
ctx.setAstRepresentationMode(AST_REPRESENTATION.PYTHON)
pc = 0x0400556
# 参数是输入字符串的指针
ctx.setConcreteRegisterValue(ctx.registers.rdi, INPUT_ADDR)
# 设置栈的值
ctx.setConcreteRegisterValue(ctx.registers.rsp, RSP_ADDR)
ctx.setConcreteRegisterValue(ctx.registers.rbp, RBP_ADDR)
# ctx.taintRegister(ctx.registers.rdi)
input = "elite\x00"
ctx.setConcreteMemoryAreaValue(INPUT_ADDR, input)
ctx.taintMemory(MemoryAccess(INPUT_ADDR, 8))
while pc != 0x4005B1:
# Build an instruction
inst = Instruction()
opcode = ctx.getConcreteMemoryAreaValue(pc, 16)
inst.setOpcode(opcode)
inst.setAddress(pc)
# 执行指令
ctx.processing(inst)
if inst.isTainted():
# print('[tainted] %s' % (str(inst)))
if inst.isMemoryRead():
for op in inst.getOperands():
if op.getType() == OPERAND.MEM:
print("read:0x{:08x}, size:{}".format(
op.getAddress(), op.getSize()))
if inst.isMemoryWrite():
for op in inst.getOperands():
if op.getType() == OPERAND.MEM:
print("write:0x{:08x}, size:{}".format(
op.getAddress(), op.getSize()))
# 取出下一条指令的地址
pc = ctx.getConcreteRegisterValue(ctx.registers.rip)
sys.exit(0)
这个脚本的作用是打印对参数字符串所在内存的访问情况, 脚本流程如下:
- 程序首先构造好栈帧, 然后把输入字符串存放到
INPUT_ADDR内存处, 同时设置RDI为INPUT_ADDR因为在x64下第一个参数通过RDI寄存器设置。 - 之后把输入字符串所在的内存区域转换为污点源,之后随着指令的执行会执行污点传播过程。
- 通过
inst.isTainted()可以判断该指令的操作数中是否包含污点值,如果指令包含污点值,就把对污点内存的访问情况给打印出来。
脚本的输出如下:
hac425@ubuntu:~/pin-2.14-71313-gcc.4.4.7-linux/source/tools/Triton$ /usr/bin/python /home/hac425/pin-2.14-71313-gcc.4.4.7-linux/source/tools/Triton/src/examples/python/taint/taint.py
[+] Loading 0x400040 - 0x400270
[+] Loading 0x400270 - 0x40028c
[+] Loading 0x400000 - 0x4007f4
[+] Loading 0x600e10 - 0x601048
[+] Loading 0x600e28 - 0x600ff8
[+] Loading 0x40028c - 0x4002ac
[+] Loading 0x4006a4 - 0x4006e0
[+] Loading 0x000000 - 0x000000
[+] Loading 0x600e10 - 0x601000
[+] Loading 0x000000 - 0x000000
read:0x00100000, size:1
read:0x00100001, size:1
read:0x00100002, size:1
read:0x00100003, size:1
read:0x00100004, size:1
可以看到成功监控了对输入字符串(0x00100000 开始的 5 个字节)的访问。
符号执行
符号执行首先要设置符号量,然后随着指令的执行在 Triton 可以维持符号量的传播,然后我们在一些特点的分支出设置约束条件,进而通过符号执行来求出程序的解。
下面还是以 crackme_xor 为例介绍一下符号执行的使用。
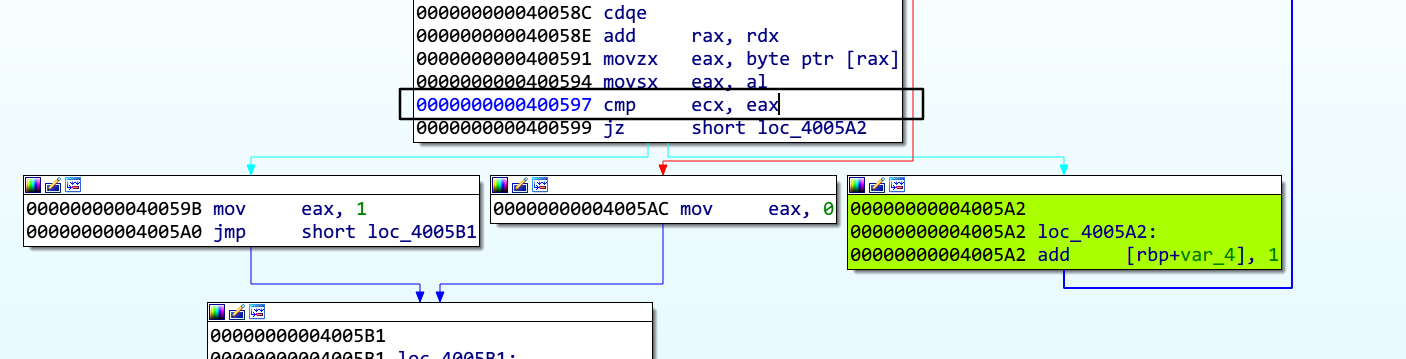
通过分析可知,在对输入字符串的每个字符进行简单变化后,会把变化后的字符与 serial 里面的相应字符进行比较,然后在 0x400599 会根据比较的结果决定是否需要跳转。
如果输入的字符串正确的话,程序会走图中染色的分支,所以我们需要在执行完 0x400597指令设置约束条件为 ZF 寄存器为 1 ,这样就可以跳转到染色的分支进而可以求出程序的解。最终的脚本如下:
#!/usr/bin/env python2
# -*- coding: utf-8 -*-
from __future__ import print_function
from triton import TritonContext, ARCH, MODE, AST_REPRESENTATION, Instruction, OPERAND
from triton import MemoryAccess,CPUSIZE
import sys
import os
import lief
# 加载 elf 文件到内存
INPUT_ADDR = 0x100000
RBP_ADDR = 0x600000
RSP_ADDR = RBP_ADDR - 0x200000
def loadBinary(ctx, path):
binary = lief.parse(path)
phdrs = binary.segments
for phdr in phdrs:
size = phdr.physical_size
vaddr = phdr.virtual_address
print('[+] Loading 0x%06x - 0x%06x' % (vaddr, vaddr+size))
ctx.setConcreteMemoryAreaValue(vaddr, phdr.content)
return
if __name__ == '__main__':
ctx = TritonContext()
ctx.setArchitecture(ARCH.X86_64)
ctx.enableMode(MODE.ALIGNED_MEMORY, True)
loadBinary(ctx, os.path.join(os.path.dirname(__file__), 'crackme_xor'))
ctx.setAstRepresentationMode(AST_REPRESENTATION.PYTHON)
pc = 0x0400556
# 参数是输入字符串的指针
ctx.setConcreteRegisterValue(ctx.registers.rdi, INPUT_ADDR)
# 设置栈的值
ctx.setConcreteRegisterValue(ctx.registers.rsp, RSP_ADDR)
ctx.setConcreteRegisterValue(ctx.registers.rbp, RBP_ADDR)
for index in range(5):
ctx.setConcreteMemoryValue(MemoryAccess(INPUT_ADDR + index, CPUSIZE.BYTE), ord('b'))
ctx.convertMemoryToSymbolicVariable(MemoryAccess(INPUT_ADDR + index, CPUSIZE.BYTE))
ast = ctx.getAstContext()
while pc:
# Build an instruction
inst = Instruction()
opcode = ctx.getConcreteMemoryAreaValue(pc, 16)
inst.setOpcode(opcode)
inst.setAddress(pc)
# 执行指令
ctx.processing(inst)
if inst.getAddress() == 0x400597:
zf = ctx.getRegisterAst(ctx.registers.zf)
cstr = ast.land([
ctx.getPathConstraintsAst(),
zf == 1
])
# 为暂时求出的解具体化
model = ctx.getModel(cstr)
for k, v in list(model.items()):
value = v.getValue()
ctx.setConcreteVariableValue(ctx.getSymbolicVariableFromId(k), value)
if inst.getAddress() == 0x4005B1:
model = ctx.getModel(ctx.getPathConstraintsAst())
answer = ""
for k, v in list(model.items()):
value = v.getValue()
answer += chr(value)
print("answer: {}".format(answer))
break
# 取出下一条指令的地址
pc = ctx.getConcreteRegisterValue(ctx.registers.rip)
sys.exit(0)
- 首先使用
convertMemoryToSymbolicVariable将字符串所在的内存转换为符号量 - 然后在运行到
0x400599后, 使用ast.land把之前搜集到的约束和走染色分支需要的约束集合起来,然后求出每个字符对应的解,并设置符号量为具体的解。 - 然后在
0x4005B1说明输入的所有字符都是正确的,此时打印所有的解即可。
运行结果如下:
hac425@ubuntu:~/pin-2.14-71313-gcc.4.4.7-linux/source/tools/Triton$ /usr/bin/python /home/hac425/pin-2.14-71313-gcc.4.4.7-linux/source/tools/Triton/src/examples/python/taint/sym.py
[+] Loading 0x400040 - 0x400270
[+] Loading 0x400270 - 0x40028c
[+] Loading 0x400000 - 0x4007f4
[+] Loading 0x600e10 - 0x601048
[+] Loading 0x600e28 - 0x600ff8
[+] Loading 0x40028c - 0x4002ac
[+] Loading 0x4006a4 - 0x4006e0
[+] Loading 0x000000 - 0x000000
[+] Loading 0x600e10 - 0x601000
[+] Loading 0x000000 - 0x000000
answer: elite
参考
https://triton.quarkslab.com/documentation/doxygen/#install_sec
https://github.com/JonathanSalwan/Triton/tree/master/src/examples/python
Triton 学习的更多相关文章
- NVIDIA GPUs上深度学习推荐模型的优化
NVIDIA GPUs上深度学习推荐模型的优化 Optimizing the Deep Learning Recommendation Model on NVIDIA GPUs 推荐系统帮助人在成倍增 ...
- Nvidia Triton使用教程:从青铜到王者
1 相关预备知识 模型:包含了大量参数的一个网络(参数+结构),体积10MB-10GB不等 模型格式:相同的模型可以有不同的存储格式(可类比音视频文件),目前主流有torch.tf.onnx和trt, ...
- 从直播编程到直播教育:LiveEdu.tv开启多元化的在线学习直播时代
2015年9月,一个叫Livecoding.tv的网站在互联网上引起了编程界的注意.缘于Pingwest品玩的一位编辑在上网时无意中发现了这个网站,并写了一篇文章<一个比直播睡觉更奇怪的网站:直 ...
- Angular2学习笔记(1)
Angular2学习笔记(1) 1. 写在前面 之前基于Electron写过一个Markdown编辑器.就其功能而言,主要功能已经实现,一些小的不影响使用的功能由于时间关系还没有完成:但就代码而言,之 ...
- ABP入门系列(1)——学习Abp框架之实操演练
作为.Net工地搬砖长工一名,一直致力于挖坑(Bug)填坑(Debug),但技术却不见长进.也曾热情于新技术的学习,憧憬过成为技术大拿.从前端到后端,从bootstrap到javascript,从py ...
- 消息队列——RabbitMQ学习笔记
消息队列--RabbitMQ学习笔记 1. 写在前面 昨天简单学习了一个消息队列项目--RabbitMQ,今天趁热打铁,将学到的东西记录下来. 学习的资料主要是官网给出的6个基本的消息发送/接收模型, ...
- js学习笔记:webpack基础入门(一)
之前听说过webpack,今天想正式的接触一下,先跟着webpack的官方用户指南走: 在这里有: 如何安装webpack 如何使用webpack 如何使用loader 如何使用webpack的开发者 ...
- Unity3d学习 制作地形
这周学习了如何在unity中制作地形,就是在一个Terrain的对象上盖几座小山,在山底种几棵树,那就讲一下如何完成上述内容. 1.在新键得项目的游戏的Hierarchy目录中新键一个Terrain对 ...
- 《Django By Example》第四章 中文 翻译 (个人学习,渣翻)
书籍出处:https://www.packtpub.com/web-development/django-example 原作者:Antonio Melé (译者注:祝大家新年快乐,这次带来<D ...
随机推荐
- imposm模块安装
imposm安装 pip install imposm 报错,参考:https://imposm.org/docs/imposm/2.5.0/install.html 并安装依赖: sudo ap-g ...
- Python之路【第三十一篇】:django ajax
Ajax 文件夹为Ajaxdemo 向服务器发送请求的途径: 1.浏览器地址栏,默认get请求: 2.form表单: get请求 post请求 3.a标签,超链接(get请求) 4.Ajax请求 特点 ...
- 解决html 图片缓存问题
<!--问题:上传一张图片,通过js更新src属性刷新图片使其即时显示时, 当img的src当前的url与上次地址无变化时(只更改图片,名称不变,不同图片名称相同)图片不变化(仍显示原来的图片) ...
- 如何在CentOS / RHEL 7上启用IPv6
默认情况下,在RHEL / CenOS 7系统上启用IPv6.因此,如果故意在系统上禁用IPv6,则可以通过以下任一方法重新启用它. 1.在内核模块中启用IPv6(需要重启)2.使用sysctl设置启 ...
- 2019 光环新网科技java面试笔试题 (含面试题解析)
本人5年开发经验.18年年底开始跑路找工作,在互联网寒冬下成功拿到阿里巴巴.今日头条.光环新网科技等公司offer,岗位是Java后端开发,因为发展原因最终选择去了光环新网科技,入职一年时间了,也 ...
- Java知识回顾 (14)网络编程
本资料来自于runoob,略有修改. 网络编程是指编写运行在多个设备(计算机)的程序,这些设备都通过网络连接起来. java.net 包中 J2SE 的 API 包含有类和接口,它们提供低层次的通信细 ...
- js继承(十)
一.原型链继承[子构造函数的原型对象是父构造函数的实例][对原型属性和方法的继承]1.每个构造函数[prototype]都有一个原型对象,原型对象中都包含一个指向构造函数的指针[constructor ...
- canvas实现酷炫气泡效果
canvas实现动画主要是靠设置定时器(setinterval())和定时清除画布里的元素实现,canvas动画上手很简单,今天可以自己动手来实现一个酷炫气泡效果. 气泡炸裂效果(类似水面波纹) 代码 ...
- 爬取网易云音乐歌手和id
pip install lxml csv requests from lxml import etree from time import sleep import csv import reques ...
- day 07 作业
猜年龄游戏 ''' 给定年龄,用户可以猜三次年龄 年龄猜对,让用户选择两次奖励 用户选择两次奖励后可以退出 ''' age_count = 0 age = 20 prize_dict = { '0': ...