scrapy框架爬取开源中国项目大厅所有的发布项目。
本文爬取的字段,项目名称,发布时间,项目周期,应用领域,最低报价,最高报价,技术类型
1,items中定义爬取字段。
import scrapy class KaiyuanzhongguoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
publishTime = scrapy.Field()
cycle = scrapy.Field()
application = scrapy.Field()
budgetMinByYuan = scrapy.Field()
budgetMaxByYuan = scrapy.Field()
ski = scrapy.Field()
2, 爬虫主程序
# -*- coding: utf-8 -*-
import scrapy
import json
from kaiyuanzhongguo.items import KaiyuanzhongguoItem
class KyzgSpider(scrapy.Spider):
name = 'kyzg'
# allowed_domains = ['www.xxx.com']
base_url = 'https://zb.oschina.net/project/contractor-browse-project-and-reward?pageSize=10¤tPage='
start_urls = ['https://zb.oschina.net/project/contractor-browse-project-and-reward?pageSize=10¤tPage=1']
def parse(self, response):
result = json.loads(response.text)
totalpage = result['data']['totalPage']
for res in result['data']['data']:
item = KaiyuanzhongguoItem()
item['name'] = res['name']
item['publishTime'] = res['publishTime']
item['cycle'] = res['cycle']
item['application'] = res['application']
item['budgetMinByYuan'] = res['budgetMinByYuan']
item['budgetMaxByYuan'] = res['budgetMaxByYuan']
skillList = res['skillList']
skill = []
item['ski'] = ''
if skillList:
for sk in skillList:
skill.append(sk['value'])
item['ski'] = ','.join(skill)
yield item
for i in range(2,totalpage+1):
url_info = self.base_url+str(i)
yield scrapy.Request(url=url_info,callback=self.parse)
3,数据库设计
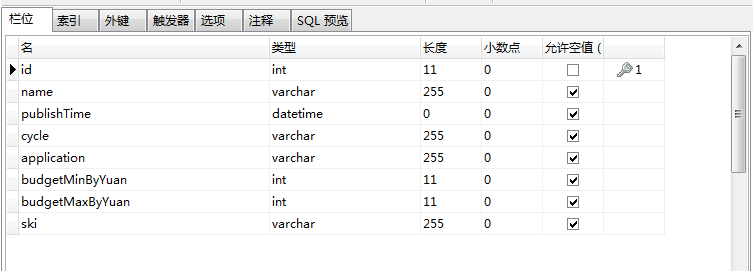
4,pipelines.py文件中写入mysql数据库
# 写入mysql数据库
import pymysql
class KaiyuanzhongguoPipeline(object):
conn = None
mycursor = None def open_spider(self, spider):
self.conn = pymysql.connect(host='172.16.25.4', user='root', password='root', db='scrapy')
self.mycursor = self.conn.cursor() def process_item(self, item, spider):
print(':正在写数据库...')
sql = 'insert into kyzg VALUES (null,"%s","%s","%s","%s","%s","%s","%s")' % (
item['name'], item['publishTime'], item['cycle'], item['application'], item['budgetMinByYuan'], item['budgetMaxByYuan'], item['ski'])
bool = self.mycursor.execute(sql)
self.conn.commit()
return item def close_spider(self, spider):
print('写入数据库完成...')
self.mycursor.close()
self.conn.close()
5,settings.py文件中设置请求头和打开下载管道
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36'
ITEM_PIPELINES = {
'kaiyuanzhongguo.pipelines.KaiyuanzhongguoPipeline': 300,
}
6,运行爬虫
scrapy crawl kyzg --nolog
7,查看数据库是否写入成功

done。
scrapy框架爬取开源中国项目大厅所有的发布项目。的更多相关文章
- 使用scrapy框架爬取自己的博文(2)
之前写了一篇用scrapy框架爬取自己博文的博客,后来发现对于中文的处理一直有问题- - 显示的时候 [u'python\u4e0b\u722c\u67d0\u4e2a\u7f51\u9875\u76 ...
- scrapy框架爬取笔趣阁
笔趣阁是很好爬的网站了,这里简单爬取了全部小说链接和每本的全部章节链接,还想爬取章节内容在biquge.py里在加一个爬取循环,在pipelines.py添加保存函数即可 1 创建一个scrapy项目 ...
- scrapy框架爬取笔趣阁完整版
继续上一篇,这一次的爬取了小说内容 pipelines.py import csv class ScrapytestPipeline(object): # 爬虫文件中提取数据的方法每yield一次it ...
- Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)
1. Scrapy框架 Scrapy是python下实现爬虫功能的框架,能够将数据解析.数据处理.数据存储合为一体功能的爬虫框架. 2. Scrapy安装 1. 安装依赖包 yum install g ...
- 爬虫入门(四)——Scrapy框架入门:使用Scrapy框架爬取全书网小说数据
为了入门scrapy框架,昨天写了一个爬取静态小说网站的小程序 下面我们尝试爬取全书网中网游动漫类小说的书籍信息. 一.准备阶段 明确一下爬虫页面分析的思路: 对于书籍列表页:我们需要知道打开单本书籍 ...
- 基于python的scrapy框架爬取豆瓣电影及其可视化
1.Scrapy框架介绍 主要介绍,spiders,engine,scheduler,downloader,Item pipeline scrapy常见命令如下: 对应在scrapy文件中有,自己增加 ...
- scrapy框架爬取糗妹妹网站妹子图分类的所有图片
爬取所有图片,一个页面的图片建一个文件夹.难点,图片中有不少.gif图片,需要重写下载规则, 创建scrapy项目 scrapy startproject qiumeimei 创建爬虫应用 cd qi ...
- scrapy框架爬取妹子图片
首先,建立一个项目#可在github账户下载完整代码:https://github.com/connordb/scrapy-jiandan2 scrapy startproject jiandan2 ...
- 使用scrapy框架爬取自己的博文(3)
既然如此,何不再抓一抓网页的文字内容呢? 谷歌浏览器有个审查元素的功能,就是按树的结构查看html的组织形式,如图: 这样已经比较明显了,博客的正文内容主要在div 的class = cnblogs_ ...
随机推荐
- 历时一年《Python自动化测试实战》终于出版!!!
一.为什么会写这本书 1.系统梳理.可以加深自己对测试知识体系的系统梳理 2.名气.增加个人的名气,比如:面试时,可以很自豪的说,我是xxxx书的作者 3.利他.帮助有需要的学习者更系统.完备的学习和 ...
- git clone 某个链接时候报错Initialized empty Git repository in 不能克隆
查看下是不是git是不是1.7.1版本. git --version 使用 yum -y update 更新一下. 再使用git clone 虽然还是会提示这个报错,但是可以克隆了.亲测有效. git ...
- 【miscellaneous】编码格式简介(ANSI、GBK、GB2312、UTF-8、GB18030和 UNICODE)
转发:http://blog.jobbole.com/30526/ 来源:潜行者m 的博客 编码一直是让新手头疼的问题,特别是 GBK.GB2312.UTF-8 这三个比较常见的网页编码的区别,更是让 ...
- 嵌入式02 STM32 实验07 串口通信
STM32串口通信(F1系列包含3个USART和2个UART) 一.单片机与PC机串行通信研究目的和意义: 单片机自诞生以来以其性能稳定,价格低廉.功能强大.在智能仪器.工业装备以及日用电子消费产品中 ...
- 读文件时出现这个错误 'utf-8' codec can't decode byte 0xba in position 21: invalid start byte
''' file2 文件内容: 很任性wheniwasyoung ''' 源代码: f = open("file2",'r',encoding="utf-8") ...
- Python实现斐波那契递归和尾递归计算
##斐波那契递归测试 def fibonacciRecursive(deepth): if deepth == 1: return 1 elif deepth == 2: return 1 else: ...
- 【题解】Luogu P5342 [TJOI2019]甲苯先生的线段树
原题传送门 挺有趣的一道题 \(c=1\),暴力求出点权和n即可 \(c=2\),先像\(c=1\)一样暴力求出点权和n,考虑有多少路径点权和也为n 考虑设x为路径的转折点,\(L\)为\(x\)向左 ...
- Spring Security的RBAC数据模型嵌入
1.简介 基于角色的权限访问控制(Role-Based Access Control)作为传统访问控制(自主访问,强制访问)的有前景的代替受到广泛的关注.在RBAC中,权限与角色相关联,用户通过成 ...
- Actions require unique method/path combination for Swagger
原文:Actions require unique method/path combination for Swagger services.AddSwaggerGen (c => { c.Re ...
- SQL Server——死锁查看
一.通过语句查看 --查询哪些死锁SELECT request_session_id spid, OBJECT_NAME( resource_associated_entity_id ) tableN ...