Multi-Agent Reinforcement Learning Based Frame Sampling for Effective Untrimmed Video Recognition
Multi-Agent Reinforcement Learning Based Frame Sampling for Effective Untrimmed Video Recognition
ICCV 2019 (oral)
2019-08-01 15:08:19
Paper:https://arxiv.org/abs/1907.13369
1. Backgroud and Motivation:
本文提出一种基于多智能体强化学习的未裁剪视频识别模型,来自适应的从未裁剪视频中,截取出样本视频帧进行行为识别。具体的示意图如下所示:
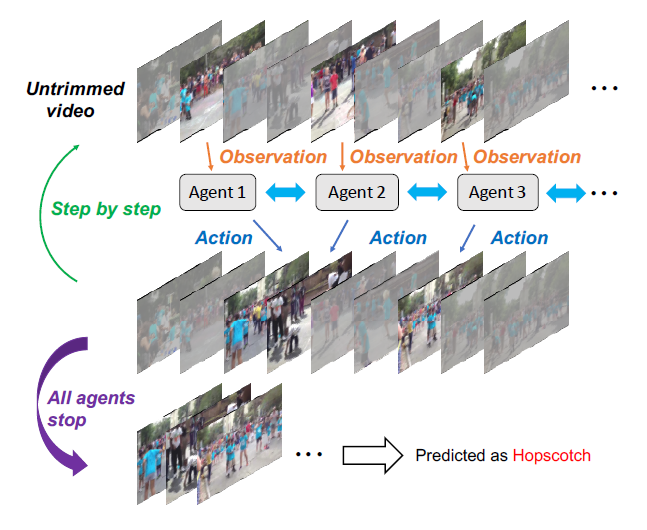
2. Architecture
2.1 Context-aware Observation Network:
这个 context-aware observation network 是一个基础的观测网络,随后是 context network。这个基础的观测网络是用于编码 选中的视频帧的视频信息,输出为 feature vector,作为 context network 的输入。与 single-agent 系统不同的是,multi-agent 的系统,每一个智能体的选择不仅依赖于 local environment state,而且受到 context information 的影响。所以,我们设计了一个 context-aware module,来维持一个 joint internal state of agents,用一个 RNN 网络将 history context information 进行总结。为了能够使之更加有效的工作,每一个智能体 only accesses context information from its 2M neighboring agents but not from all agents. 正式的来说,所有的时间步骤 t,智能体 a 观测到一个组合的状态 $s_t^a$ 及其 之前的 hidden state $h_{t-1}^a$ 作为 context module 的输入,然后产生其当前的 hidden states:

2.2 Policy Network:
作者采用 fc + softmax function 作为 policy network。在每一个时间步骤 t,每一个智能体 a,根据策略网络产生的概率分布, 选择一个动作 $u_t^a$ 来执行。动作集合是一个离散的空间 {moving ahead, moving back and staying}。并且设置一定的步幅。当所有的智能体都选择 staying 的时候,意味着该停止了。
2.3 Classification Network:
就是将选中的视频帧进行 action 的分类。
3. Objectives
本文将同时进行 奖励最大化的优化 以及 分类网络的优化。
3.1 MARL Objective:
Reward function: 奖励函数反应了 agents 选择动作的好坏。当所有的智能体都选择动作时,每一个时刻 t,每一个智能体基于分类的概率 $p_t^a$ 得到了其各自的奖励 $r_t^a$ 。给予 agent 奖励可以促使其知道更加具有信息量的 frame,从而一步一步的改善正确预测的概率。所以,作者设计了一个简单的奖励函数,鼓励模型增加其 confidence。特定的,对于第 t 个时间步骤来说,agent a 接收的奖励按照如下的方式进行计算:
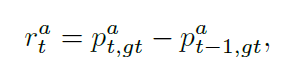
其中,$p_{t,c}^a$ 代表了智能体 a 在时刻 t 模型将其预测为 class c 的概率,gt 是视频的 ground truth label。所有的智能体共享同一个 reward function。考虑到序列决策的场景,考虑累积折扣回报是更加合适的,即:将来的奖励对当前的步骤贡献更小一些。特别的,在时刻 t,对于智能体 a 来说,折扣的回报可以计算如下:
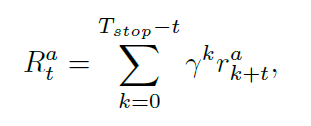
Policy Gradient: 服从 REINFORCE 算法,作者将目标函数设置为:
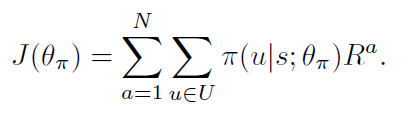
在本文的情况下,学习网络参数使其可以最大化上述公式,其梯度为:
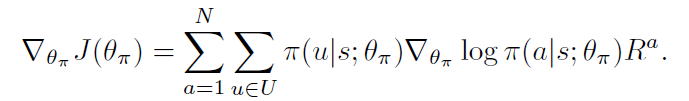
这变成了一个 non-trivial optimization problem, 由于 action sequence space 的维度过高。REINFORCE 通过蒙特卡洛采样的方式,进行梯度的估计:
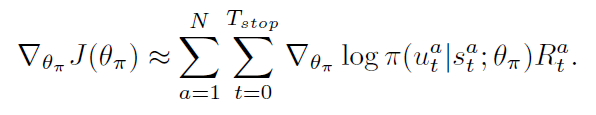
然后,我们可以利用随机梯度下降的方式,来最小化下面的损失:
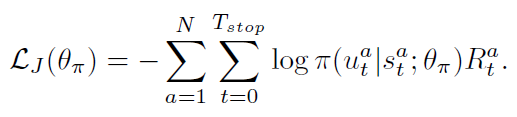
Maximum entropy:
为了避免让策略迅速变的 deterministic,研究者考虑将 entropy regularization 技术引入到 DRL 算法中,以鼓励探索。更大的熵,agent 就会更加偏向于探索其他动作。所以,我们利用 policy 的 entropy 来进行正则:
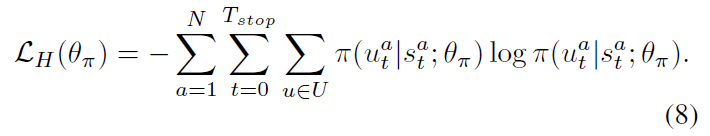
所以,MARL 总得损失是上述两个损失函数的加和:
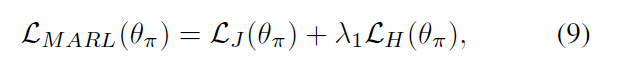
3.2 Classification Objective :
作者用 Cross-entropy loss 来最小化 gt 和 prediction p 之间的 KL-散度:
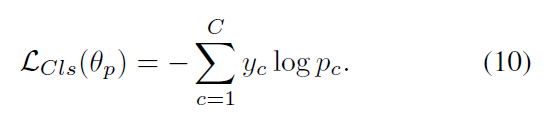
最终,我们优化组合损失,即:
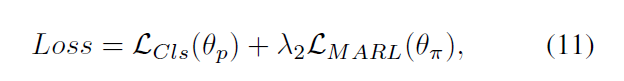
4. Experiments:


==
Multi-Agent Reinforcement Learning Based Frame Sampling for Effective Untrimmed Video Recognition的更多相关文章
- [转]Deep Reinforcement Learning Based Trading Application at JP Morgan Chase
Deep Reinforcement Learning Based Trading Application at JP Morgan Chase https://medium.com/@ranko.m ...
- [转]Introduction to Learning to Trade with Reinforcement Learning
Introduction to Learning to Trade with Reinforcement Learning http://www.wildml.com/2018/02/introduc ...
- Introduction to Learning to Trade with Reinforcement Learning
http://www.wildml.com/2015/12/implementing-a-cnn-for-text-classification-in-tensorflow/ The academic ...
- 【资料总结】| Deep Reinforcement Learning 深度强化学习
在机器学习中,我们经常会分类为有监督学习和无监督学习,但是尝尝会忽略一个重要的分支,强化学习.有监督学习和无监督学习非常好去区分,学习的目标,有无标签等都是区分标准.如果说监督学习的目标是预测,那么强 ...
- (转) Deep Reinforcement Learning: Pong from Pixels
Andrej Karpathy blog About Hacker's guide to Neural Networks Deep Reinforcement Learning: Pong from ...
- (转) Playing FPS games with deep reinforcement learning
Playing FPS games with deep reinforcement learning 博文转自:https://blog.acolyer.org/2016/11/23/playing- ...
- (转) Deep Learning Research Review Week 2: Reinforcement Learning
Deep Learning Research Review Week 2: Reinforcement Learning 转载自: https://adeshpande3.github.io/ad ...
- 论文笔记:Learning how to Active Learn: A Deep Reinforcement Learning Approach
Learning how to Active Learn: A Deep Reinforcement Learning Approach 2018-03-11 12:56:04 1. Introduc ...
- (zhuan) Evolution Strategies as a Scalable Alternative to Reinforcement Learning
Evolution Strategies as a Scalable Alternative to Reinforcement Learning this blog from: https://blo ...
随机推荐
- Android数据库GreenDao配置版本问题
感谢该贴解决我多天的困惑:https://blog.csdn.net/u013472738/article/details/72895747 主要是降低了GreenDao版本 网上很多教程说的版本都是 ...
- 【故障处理】 DBCA建库报错CRS-2566
[故障处理] DBCA建库报错CRS-2566 PRCR-1071 PRCR-1006 一.1 BLOG文档结构图 一.2 前言部分 一.2.1 导读和注意事项 各位技术爱好者, ...
- xshell 连接出现 The remote SSH server rejected X11 forwarding request
如果本文对你有用,请爱心点个赞,提高排名,帮助更多的人.谢谢大家!❤ yum install xorg-x11-xauth 同时sshd的config文件开启X11Forwarding yes vim ...
- ThreadLocal源码原理以及防止内存泄露
ThreadLocal的原理图: 在线程任务Runnable中,使用一个及其以上ThreadLocal对象保存多个线程的一个及其以上私有值,即一个ThreadLocal对象可以保存多个线程一个私有值. ...
- mac随笔
1.查看端口,lsof -i tcp:post lsof -i tcp:8086 2.kill进程 找到进程的PID,使用kill命令:kill PID(进程的PID,如2044),杀死对应的进程 k ...
- Spring源码窥探之:声明式事务
1. 导入驱动,连接池,jdbc和AOP的依赖 <!-- c3p0数据库连接池 --> <dependency> <groupId>c3p0</groupId ...
- hiveSQL常用日期函数
注意 MM,DD,MO,TU 等要大写 Hive 可以在 where 条件中使用 case when 已知日期 要求日期 语句 结果 本周任意一天 本周一 select date_sub(next_d ...
- SQL SERVER错误:已超过了锁请求超时时段。
问题:远程连接数据库,无法打开视图,报错:SQL SERVER错误:已超过了锁请求超时时段. (Microsoft SQL Server,错误: 1222) 执行语句获取进程id select * f ...
- 查vue版本号
在项目中,找到package.json文件夹 找"dependencies"然后就可以看到你装的vue的版本了.
- wget递归下载网站资源
wget -r -p -np -k http://archive.openwrt.org/barrier_breaker/14.07/ramips/mt7620a/packages/ 在下载https ...