jenkins发布程序触发shell调用python脚本刷新akamai cdn api
刷新cdn的流程:
jenkins获取git中的代码,触发脚本推送到生产环境中(即cdn的源站) --> 触发脚本获取git工作目录的更新列表,将更新列表拼凑成带域名信息的url,写入到目录中 --> 触发python脚本读取目录中的url发送给akamai的api进行cdn的刷新
参考文档创建client api,此次我们的账号没有创建client api的权限,需要管理员处理
文档地址:https://developer.akamai.com/api/getting-started#beforeyoubegin
创建和api交互的client api后会得到类似如下信息
client_secret = "pass"
host = "host.purge.akamaiapis.net"
access_token = "token"
client_token = "client_token"
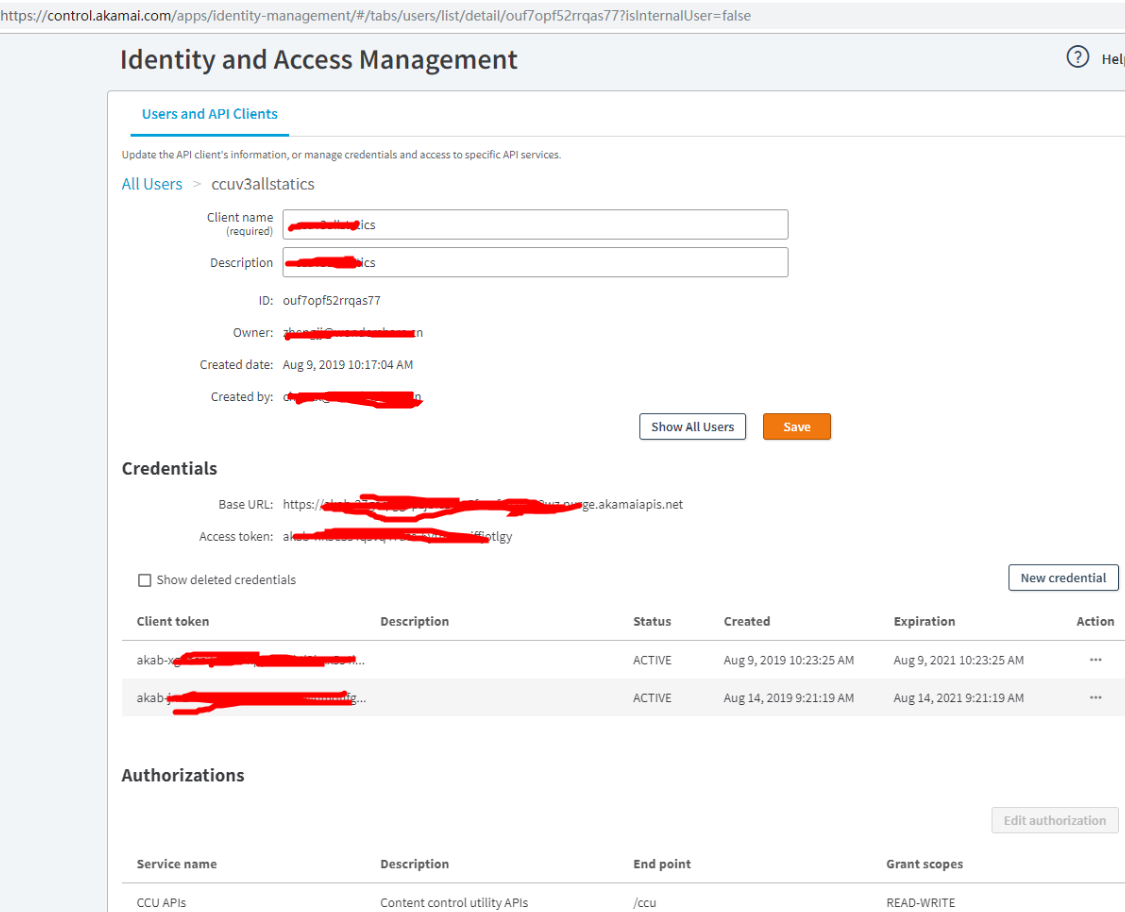
api参考地址:
https://github.com/akamai/api-kickstart
jenkins配合shell脚本触发python自动刷新akamai cdn
项目背景:
设计中心开启了统一资源管理系统neveragain.chinaosft.com,即公司后续新开发的站点引用的image,css,js等公共资源统一从该系统获取
需求:
当代码合并到master的指定目录后需要自动发布代码及图片等资源到生产环境并且能即时刷新CDN
转化为运维需求:
git中提交代码并且合并master --> 使用jenkins发布代码到 neveragain.chinaosft.com 所在服务器 --> 获取更新的代码并且刷新CND
具体实现过程
1.配置jenkins让jenkins能拉取代码到jenkins服务器,因配置较为简单,此处略
2.配置发布的脚本:
脚本的主要逻辑:发布指定代码到生产环境服务器 --> 同时获取代码中dist目录更新的文件,将文件拼凑成CDN的api可以识别的URL --> 使用python脚本读取需要更新的URL列表并且触发AKAMAI CDN API刷新资源
jenkins中的shell脚本
[root@jenkins:/usr/local/worksh/jeninks_task]# cat neveragain_chinasoft_com.sh
#!/bin/bash
#############################################
# 通过jenkins发布任务 neveragain.chinasoft.com 发布 注意/data/www/vhosts/neveragain.chinasoft.com/httpdocs/dist/ 发布到线上对应的是2019目录 cart_iplist="1.1.1.1" function neveragain_chinasoft_eus_rsync()
{
for ip in $cart_iplist
do
echo "-- start pub --- 预发布到外网 ${ip} ----------------------------------------"
/usr/local/bin/rsync -vazP --bwlimit= --exclude='.git/' --exclude='.gitignore/' --password-file=/data/www/.rsync/rsyncd.pass /data/www/vhosts/neveragain.chinasoft.com/httpdocs/dist/ apache@$ip::apache/data/www/vhosts/neveragain.chinasoft.com/httpdocs//
if [[ $? == || $? == ]];then
rsync_edit=
else
rsync_edit=
echo "`date` rsync发布失败! -> editUrls.txt"
exit
fi echo -e "-- end pub ${ip} ----------------------------------------------------------\n\n"
done
} # 执行同步
neveragain_chinasoft_eus_rsync # 读取git的更新列表,发送请求调用python脚本刷新akamai CDN
function update_cdn
{
# 工作目录
WORKSPACE="/data/jenkins_home/workspace/DesignCenter.neveragain.chinasoft.com/"
cd $WORKSPACE # 获取git变更列表
changefiles=$(git diff --name-only HEAD~ HEAD)
#echo $changefiles
# 先把文件路径写死,作为测试使用
#changefiles="dist/assets/image/box/drfone-mac.png dist/assets/image/box/drfone-win.png dist/assets/image/box/dvdcreator-mac.png dist/assets/image/box/dvdcreator-win.png" #
now_time="`date +%Y%m%d%H%M%S`"
# 将更新的文件列表写入日志文件中
for newfile in $changefiles;
do
start_str=${newfile::}
#echo $start_str
# 如果变更的文件是 dist 目录下的文件就触发该文件刷新CDN
if [ $start_str == 'dist' ];then
need_file=${newfile:}
#echo $need_file
need_url="https://neveragain.chinasoft.com/2019/$need_file"
#echo $need_url
echo "${need_url}" >> "/usr/local/worksh/jeninks_task/akamai_api/logs/${now_time}.log"
fi
done # 调用Python脚本刷新cdn
/usr/local/worksh/jeninks_task/akamai_api_venv/bin/python /usr/local/worksh/jeninks_task/akamai_api/akamai_api.py $now_time
if [ $? != ];then
echo "刷新CDN失败"
exit
else
echo "刷新CDN成功"
fi }
# 刷新cdn
update_cdn
# python脚本
# 刷新cdn的python脚本结构
[root@jenkins:/usr/local/worksh/jeninks_task/akamai_api]# tree
.
├── akamai_api.py
├── lib
│ ├── http_calls.py
│ ├── __init__.py
├── logs
│ ├── 20190814164047.log
│ └── 20190814172256.log
├── log.txt
├── README.md
└── requirement.txt
# cat /usr/local/worksh/jeninks_task/akamai_api/logs/20190814172256.log
https://neveragain.chinasoft.com/2019/assets/icon/brand/finder.svg
https://neveragain.chinasoft.com/2019/assets/icon/logo/edraw-horizontal-white.png
# 主程序
[root@jenkins:/usr/local/worksh/jeninks_task]# cat /usr/local/worksh/jeninks_task/akamai_api/akamai_api.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @File : akamai_api.py
# @Desc : 读取指定文件中url的路径内容,刷新Akamai CDN的边缘节点数据 import requests, json,time,os,sys
from lib.http_calls import EdgeGridHttpCaller
from akamai.edgegrid import EdgeGridAuth
import logging class Akamai_API():
def __init__(self,api_host,api_access_token,api_client_token,api_client_secret,verbose=False,debug=False,action="delete",network="production"):
self.host = api_host
self.access_token = api_access_token
self.client_token = api_client_token
self.client_secret = api_client_secret self.verbose = verbose
self.debug = debug #API的清除动作:delete invalidate
self.action =action
self.network =network self.session = requests.Session() def __auth(self):
self.session.auth = EdgeGridAuth(
client_token=self.client_token,
client_secret=self.client_secret,
access_token=self.access_token
)
return self.session def postPurgeRequest(self,refush_url_list):
self.__auth()
baseurl = '%s://%s/' % ('https', self.host)
httpCaller = EdgeGridHttpCaller(self.session, self.debug, self.verbose, baseurl)
purge_obj = {
# "objects": [
# "https://bc.akamaiapibootcamp.com/index.html"
# ]
"objects": refush_url_list,
}
# print("Adding %s request to queue - %s" % (self.action, json.dumps(purge_obj)))
purge_post_result = httpCaller.postResult('/ccu/v3/%s/url/%s' % (self.action, self.network), json.dumps(purge_obj))
return purge_post_result def ReadFile(filename):
"""
读取文件内容中的url路径
每行一条url路径
"""
l = []
error_l = []
with open(filename) as f:
for url in f.readlines():
url_str = str(url).strip("\n")
if str(url).startswith("https://neveragain.chinasoft.com"):
l.append(url_str)
else:
error_l.append(url_str)
if error_l:
raise Exception("The format of the file path is incorrect. %s"%('\n'.join(error_l)))
return l if __name__ == "__main__":
#API信息
API_HOST = "host.purge.akamaiapis.net"
API_ACCESS_TOKEN = "token"
API_CLIENT_TOKEN = "client_token"
API_CLIENT_SECRET = "api_client_secret=" api = Akamai_API(api_host=API_HOST,api_access_token=API_ACCESS_TOKEN,api_client_token=API_CLIENT_TOKEN,api_client_secret=API_CLIENT_SECRET) #接收url文件名称
if len(sys.argv) != 2:
raise Exception("Not enough parameters for %s"%sys.argv[0])
prefix_url_filename = sys.argv[1] # 定义日志级别
baseDir = os.path.dirname(os.path.abspath(__file__))
logfile = os.path.join(baseDir,"log.txt")
logging.basicConfig(level=logging.INFO,
filename=logfile,
filemode='a',
format='%(asctime)s - %(filename)s - %(levelname)s: %(message)s')
logger = logging.getLogger(__name__) #读取url的文件内容
filename = os.path.join(baseDir,os.path.join("logs","%s.log"%prefix_url_filename))
if not os.path.isfile(filename):
raise Exception("Not exists file %s" %filename)
url_list = ReadFile(filename) #每次POST提交url的条数
MAX_REQUEST_SIZE = 800
while url_list:
batch = []
batch_size = 0 while url_list and batch_size < MAX_REQUEST_SIZE:
next_url = url_list.pop()
batch.append(next_url)
batch_size += 1
if batch:
response = api.postPurgeRequest(batch)
if response["httpStatus"] != 201:
# 将本次请求url返回到总url列表中,以便稍后在试
url_list.extend(batch)
#速率限制
if response["httpStatus"] == 507:
details = response.json().get('detail', '<response did not contain "detail">')
print('Will retry request in 1s seconds due to API rate-limit: %s,Try again now.'%details)
logger.info('Will retry request in 1s seconds due to API rate-limit: %s,Try again now.'%details)
time.sleep(1)
# 针对速率限制以外的错误 抛出
if response["httpStatus"] != 507:
details = response.json().get('detail', '<response did not contain "detail">')
print("{status:Failed,detail:%s}"%details)
logger.info("{status:Failed,detail:%s}"%details)
response.raise_for_status()
else:
logger.info("{status:Success,supportId:%s,purgeId:%s,queue:%s}"%(response["supportId"],response["purgeId"],json.dumps(batch))) # 依赖包: [root@jenkins:/usr/local/worksh/jeninks_task/akamai_api]# cat requirement.txt
asn1crypto==0.24.0
certifi==2019.6.16
cffi==1.12.3
chardet==3.0.4
configparser==3.7.4
cryptography==2.7
edgegrid-python==1.1.1
idna==2.8
ndg-httpsclient==0.5.1
pyasn1==0.4.6
pycparser==2.19
pyOpenSSL==19.0.0
requests==2.22.0
six==1.12.0
urllib3==1.25.3 [root@jenkins:/usr/local/worksh/jeninks_task/akamai_api]# cat lib/http_calls.py
#!/usr/bin/env python # Python edgegrid module
""" Copyright 2015 Akamai Technologies, Inc. All Rights Reserved. Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
"""
import sys if sys.version_info[0] >= 3:
# python3
from urllib import parse
else:
# python2.7
import urlparse as parse import logging, json logger = logging.getLogger(__name__) class EdgeGridHttpCaller():
def __init__(self, session, debug, verbose, baseurl):
self.debug = debug
self.verbose = verbose
self.session = session
self.baseurl = baseurl
return None def urlJoin(self, url, path):
return parse.urljoin(url, path) def getResult(self, endpoint, parameters=None):
path = endpoint
endpoint_result = self.session.get(parse.urljoin(self.baseurl, path), params=parameters)
if self.verbose: print(">>>\n" + json.dumps(endpoint_result.json(), indent=2) + "\n<<<\n")
status = endpoint_result.status_code
if self.verbose: print("LOG: GET %s %s %s" % (endpoint, status, endpoint_result.headers["content-type"]))
self.httpErrors(endpoint_result.status_code, path, endpoint_result.json())
return endpoint_result.json() def httpErrors(self, status_code, endpoint, result):
if not isinstance(result, list):
details = result.get('detail') or result.get('details') or ""
else:
details = ""
if status_code == 403:
error_msg = "ERROR: Call to %s failed with a 403 result\n" % endpoint
error_msg += "ERROR: This indicates a problem with authorization.\n"
error_msg += "ERROR: Please ensure that the credentials you created for this script\n"
error_msg += "ERROR: have the necessary permissions in the Luna portal.\n"
error_msg += "ERROR: Problem details: %s\n" % details
exit(error_msg) if status_code in [400, 401]:
error_msg = "ERROR: Call to %s failed with a %s result\n" % (endpoint, status_code)
error_msg += "ERROR: This indicates a problem with authentication or headers.\n"
error_msg += "ERROR: Please ensure that the .edgerc file is formatted correctly.\n"
error_msg += "ERROR: If you still have issues, please use gen_edgerc.py to generate the credentials\n"
error_msg += "ERROR: Problem details: %s\n" % result
exit(error_msg) if status_code in [404]:
error_msg = "ERROR: Call to %s failed with a %s result\n" % (endpoint, status_code)
error_msg += "ERROR: This means that the page does not exist as requested.\n"
error_msg += "ERROR: Please ensure that the URL you're calling is correctly formatted\n"
error_msg += "ERROR: or look at other examples to make sure yours matches.\n"
error_msg += "ERROR: Problem details: %s\n" % details
exit(error_msg) error_string = None
if "errorString" in result:
if result["errorString"]:
error_string = result["errorString"]
else:
for key in result:
if type(key) is not str or isinstance(result, dict) or not isinstance(result[key], dict):
continue
if "errorString" in result[key] and type(result[key]["errorString"]) is str:
error_string = result[key]["errorString"]
if error_string:
error_msg = "ERROR: Call caused a server fault.\n"
error_msg += "ERROR: Please check the problem details for more information:\n"
error_msg += "ERROR: Problem details: %s\n" % error_string
exit(error_msg) def postResult(self, endpoint, body, parameters=None):
headers = {'content-type': 'application/json'}
path = endpoint
endpoint_result = self.session.post(parse.urljoin(self.baseurl, path), data=body, headers=headers,
params=parameters)
status = endpoint_result.status_code
if self.verbose: print("LOG: POST %s %s %s" % (path, status, endpoint_result.headers["content-type"]))
if status == 204:
return {}
self.httpErrors(endpoint_result.status_code, path, endpoint_result.json()) if self.verbose: print(">>>\n" + json.dumps(endpoint_result.json(), indent=2) + "\n<<<\n")
return endpoint_result.json() def postFiles(self, endpoint, file):
path = endpoint
endpoint_result = self.session.post(parse.urljoin(self.baseurl, path), files=file)
status = endpoint_result.status_code
if self.verbose: print("LOG: POST FILES %s %s %s" % (path, status, endpoint_result.headers["content-type"]))
if status == 204:
return {}
self.httpErrors(endpoint_result.status_code, path, endpoint_result.json()) if self.verbose: print(">>>\n" + json.dumps(endpoint_result.json(), indent=2) + "\n<<<\n")
return endpoint_result.json() def putResult(self, endpoint, body, parameters=None):
headers = {'content-type': 'application/json'}
path = endpoint endpoint_result = self.session.put(parse.urljoin(self.baseurl, path), data=body, headers=headers,
params=parameters)
status = endpoint_result.status_code
if self.verbose: print("LOG: PUT %s %s %s" % (endpoint, status, endpoint_result.headers["content-type"]))
if status == 204:
return {}
if self.verbose: print(">>>\n" + json.dumps(endpoint_result.json(), indent=2) + "\n<<<\n")
return endpoint_result.json() def deleteResult(self, endpoint):
endpoint_result = self.session.delete(parse.urljoin(self.baseurl, endpoint))
status = endpoint_result.status_code
if self.verbose: print("LOG: DELETE %s %s %s" % (endpoint, status, endpoint_result.headers["content-type"]))
if status == 204:
return {}
if self.verbose: print(">>>\n" + json.dumps(endpoint_result.json(), indent=2) + "\n<<<\n")
return endpoint_result.json()
# 报错
warning: inexact rename detection was skipped due to too many files.
warning: you may want to set your diff.renameLimit variable to at least 3074 and retry the command.
Traceback (most recent call last):
File "/usr/local/worksh/jeninks_task/akamai_api/akamai_api.py", line 109, in <module>
response = api.postPurgeRequest(batch)
File "/usr/local/worksh/jeninks_task/akamai_api/akamai_api.py", line 48, in postPurgeRequest
purge_post_result = httpCaller.postResult('/ccu/v3/%s/url/%s' % (self.action, self.network), json.dumps(purge_obj))
File "/usr/local/worksh/jeninks_task/akamai_api/lib/http_calls.py", line 112, in postResult
self.httpErrors(endpoint_result.status_code, path, endpoint_result.json())
File "/usr/local/worksh/jeninks_task/akamai_api_venv/lib/python3.6/site-packages/requests/models.py", line 897, in json
return complexjson.loads(self.text, **kwargs)
File "/usr/local/python3/lib/python3.6/json/__init__.py", line 354, in loads
return _default_decoder.decode(s)
File "/usr/local/python3/lib/python3.6/json/decoder.py", line 339, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
File "/usr/local/python3/lib/python3.6/json/decoder.py", line 357, in raw_decode
raise JSONDecodeError("Expecting value", s, err.value) from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
刷新CDN失败
修改 MAX_REQUEST_SIZE = 200,每次批量提交800条,被cdn拒绝,修改为200后问题解决
jenkins发布程序触发shell调用python脚本刷新akamai cdn api的更多相关文章
- shell调用python脚本,并且向python脚本传递参数
1.shell调用python脚本,并且向python脚本传递参数: shell中: python test.py $para1 $para2 python中: import sys def main ...
- 通过Java调用Python脚本
在进行开发的过程中,偶尔会遇到需要使用Java调用Python脚本的时候,毕竟Python在诸如爬虫,以及科学计算等方面具有天然的优势.最近在工作中遇到需要在Java程序中调用已经写好的Python程 ...
- linux+php+apache web调用python脚本权限问题解决方案
lamp : linux + apache + mysql + php 在上篇随笔中linux+php+apache调用python脚本时出现的问题的根本原因是:apache运行时使用的apache用 ...
- PHP 调用Python脚本
上次做用户反馈自动翻译,写了个python脚本,将日文的用户反馈翻译成中文,效果虽然可以,但其它不懂python的童鞋就没法使用了,所以搭了个web服务,让其他人可以通过网页访问查询.使用的是apac ...
- C++中调用Python脚本
C++中调用Python脚本的意义就不讲了,至少你可以把它当成文本形式的动态链接库, 需要的时候还可以改一改,只要不改变接口, C++的程序一旦编译好了,再改就没那么方便了 先看Python的代码 代 ...
- java调用python脚本并向python脚本传递参数
1.安装Eclipse 先安装jdk,再安装Eclipse,成功后开始建立py_java项目,在这个项目的存储目录SRC下建立test包,在test包中New-Class,新建MyDemo类,建好完成 ...
- Window环境下,PHP调用Python脚本
参考 php调用python脚本*** php 调用 python脚本的方法 解决办法:php提供了许多调用其他脚本或程序的方法,比如exec/system/popen/proc_open/passt ...
- C#调用Python脚本的简单示例
C#调用Python脚本的简单示例 分类:Python (2311) (0) 举报 收藏 IronPython是一种在 .NET及 Mono上的 Python实现,由微软的 Jim Huguni ...
- Java调用Python脚本并获取返回值
在Java程序中有时需要调用Python的程序,这时可以使用一般的PyFunction来调用python的函数并获得返回值,但是采用这种方法有可能出现一些莫名其妙的错误,比如ImportError.在 ...
随机推荐
- 数据库基准测试标准 TPC-C or TPC-H or TPC-DS
针对数据库不同的使用场景TPC组织发布了多项测试标准.其中被业界广泛接受和使用的有TPC-C .TPC-H和TPC-DS. TPC-C: Approved in July of 1992, TPC B ...
- 2019.11.15 JQ图片轮播
<div class="three"> <div class="bjtp"> <img class="bjpic b1& ...
- QMutexLocker基于QMutex的便利类
首先需要注意的是:QMutexLocker这个类是基于QMutex的便利类,这个类不能够定义 私有成员变量 和 全局变量,只能够定义局部变量来使用. 使用方法:(1)先定义一个QMutex类的 ...
- 98: 模拟赛-神光 dp
$code$ #include <cstdio> #include <cstring> #include <algorithm> using namespace s ...
- cf 1051F 树+图
$des$给定一张 $n$ 个点 $m$ 条边的带权无向联通图,$q$ 次询问,每次询问 $u_i$ 到 $v_i$ 的最短路长度.$n,q <= 10^5, m - n <= 20$ $ ...
- 洛谷 P1456Monkey King
题目描述 要把打架的两堆猴子合并为一堆,查询的又是最大值,所以很容易想到可并堆. 题目要求打完架后战斗力最大的猴子的战斗力要减半,但不能直接在堆中进行这个操作,因为战斗力减半后这只猴子不一定是战斗力最 ...
- 交互设计算法基础(2) - Selection Sort
int[] selection_sort(int[] arr) { int i, j, min, temp, len=arr.length; for (i=0; i<len-1; i++) { ...
- 如何快速把ps序列图层建立帧动画?
工具ps 1.将序列帧图片载入ps 新建->脚本->将文件载入堆栈 2.制作序列帧动画 窗口->时间轴->时间轴面板右上角菜单->从图层建立帧 3.去除多余的透明画布 全 ...
- realloc()函数
原型:extern void *realloc(void *mem_address, unsigned int newsize); 参数: mem_address: 要改变内存大小的指针名 newsi ...
- OpenCV Facial Landmark Detection 人脸关键点检测
Opencv-Facial-Landmark-Detection 利用OpenCV中的LBF算法进行人脸关键点检测(Facial Landmark Detection) Note: OpenCV3.4 ...