Transformer---BERT模型
一、BERT介绍
论文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
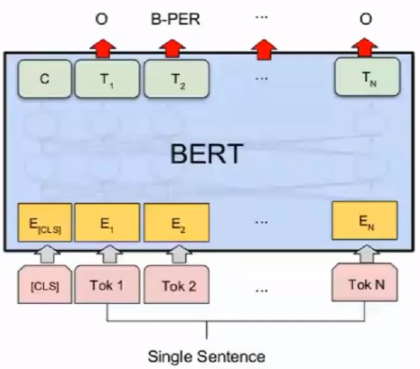
简介:BERT是基于Transformer的深度双向语言表征模型,基本结构如图所示,本质上是利用Transformer结构构造了一个多层双向的Encoder网络。Transformer是Google在2017年提出的基于自注意力机制(Self-attention)的深层模型,在包括机器翻译在内的多项NLP任务上效果显著,超过RNN且训练速度更快。

从上图可见,Bert其实和ELMO及GPT存在千丝万缕的关系,比如如果我们把GPT预训练阶段换成双向语言模型,那么就得到了Bert;而如果我们把ELMO的特征抽取器换成Transformer,那么我们也会得到Bert。与GPT不同之处:在预训练阶段采用了类似ELMO的双向语言模型;另外一点是语言模型的数据规模要比GPT大。
Bert最关键两点:
- 特征抽取器采用Transformer;
- 预训练的时候采用双向语言模型。
二、BERT模型结构
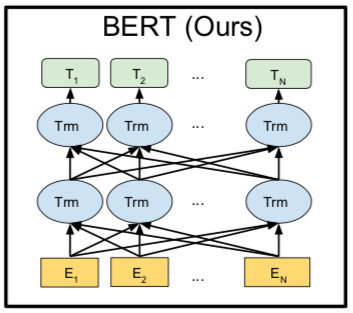
上图中$E_i$是指的单个字或词, $T_i$指的是最终计算得出的隐藏层, Transformer中的注意力矩阵和注意力加权, 经过这样的操作之后, 序列里面的每一个字, 都含有这个字前面的信息和后面的信息, 这就是双向的理解, 在这里, 一句话中每一个字, 经过注意力机制和加权之后, 当前这个字等于用这句话中其他所有字重新表达了一遍, 每个字含有了这句话中所有成分的信息.
根据参数设置的不同,Google 论文中提出了Base和Large两种BERT模型。
三、预训练
BERT预训练过程包含两个不同的预训练任务,分别是Masked Language Model和Next Sentence Prediction任务。
1.Masked Language Model(MLM)
随机把一些单词变为[Mask],然后预测这些被遮盖的词来训练双向语言模型,并且使每个词的表征参考上下文信息。假设输入里面的第二个词汇是被盖住的,把其对应的embedding输入到一个多分类模型中,来预测被盖住的单词。之后做Loss的时候只计算被遮盖部分的Loss。

实际操作方式如下:
【1】随机把一句话中15%的token替换成以下内容:
- 这些token中有80%的几率被替换成[mask];
- 有10%的几率被替换成任意一个其他的token;
- 有10%的几率原封不动

【2】之后让模型预测和还原被遮盖掉或替换掉的部分,模型最终输出的隐藏层的计算结果的难度是:
$X_{hidden}$: [batch size, seq len, embedding dim]
我们初始化一个映射层的权重$W_{vocab}$:
$W_{vocab}$: [embedding dim, vocab size]
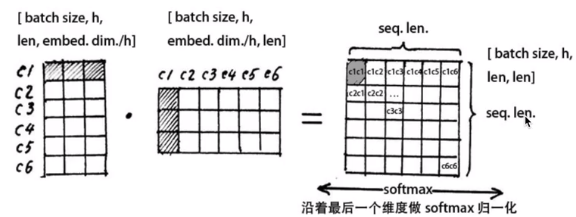
我们用$W_{vocab}$完成隐藏维度到字向量数量的映射, 只要求$X_{hidden}$和$W_{vocab}$的矩阵乘(点积):
$X_{hidden}W_{vocab}$: [batch size, seq len, vocab size]
之后把上面的计算结果在vocab size(最后一个)维度做$softmax$归一化, 是每个字对应的vocab size的和为1, 我们就可以通过vocab size里概率最大的字来得到模型的预测结果, 就可以和我们准备好的$Label$做损失($Loss$)并反传梯度了. 注意做损失的时候, 只计算在第1步里当句中随机遮盖或替换的部分, 其余部分不做损失, 对于其他部分, 模型输出什么东西, 我们不在意.
这样做会产生两个缺点:
- 会造成预训练和微调时的不一致,因为在微调时[MASK]总是不可见的;
- 由于每个Batch中只有15%的词会被预测,因此模型的收敛速度比起单向的语言模型会慢,训练花费的时间会更长。
解决方法:
- 对于第一个缺点的解决办法是,把80%需要被替换成[MASK]的词进行替换,10%的随机替换为其他词,10%保留原词。由于Transformer Encoder并不知道哪个词需要被预测,哪个词是被随机替换的,这样就强迫每个词的表达需要参照上下文信息。
- 对于第二个缺点目前没有有效的解决办法,但是从提升收益的角度来看,付出的代价是值得的。
2.Next Sentence Prediction(NSP)
首先我们拿到属于上下文的一对句子, 也就是两个句子, 之后我们要在这两段连续的句子里面加一些特殊$token$: $[cls]$上一句话,$[sep]$下一句话.$[sep]$
也就是在句子开头加一个$[cls]$, 在两句话之中和句末加$[sep]$, 具体地就像下图一样:
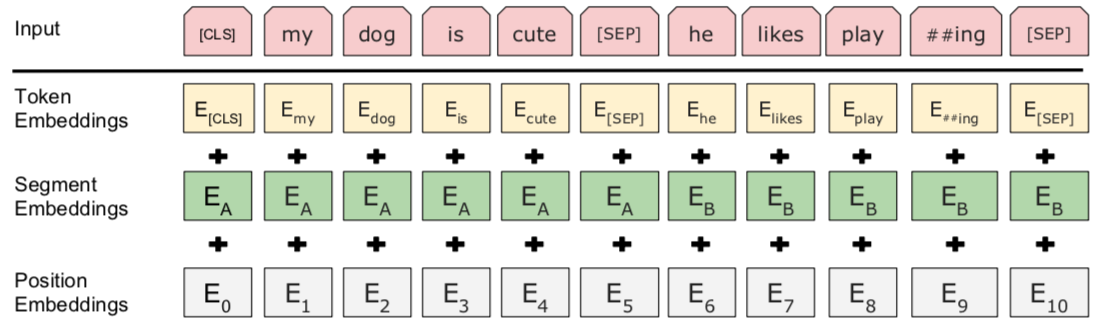
我们看到上图中两句话是[cls] my dog is cute [sep] he likes playing [sep], [cls]我的狗很可爱[sep]他喜欢玩耍[sep], 除此之外, 我们还要准备同样格式的两句话, 但他们不属于上下文关系的情况; [cls]我的狗很可爱[sep]企鹅不擅长飞行[sep], 可见这属于上下句不属于上下文关系的情况;在实际的训练中, 我们让上面两种情况出现的比例为1:1, 也就是一半的时间输出的文本属于上下文关系, 一半时间不是.
我们进行完上述步骤之后, 还要随机初始化一个可训练的 segment embeddings , 见上图中, 作用就是用 embeddings 的信息让模型分开上下句, 我们一把给上句全 0 的 tokentoken , 下句啊全 1 的 token , 让模型得以判断上下句的起止位置, 例如:
- [cls] 我的狗很可爱 [sep] 企鹅不擅长飞行 [sep]
- 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1
上面 0 和 1 就是 segment embeddings .
注意力机制就是, 让每句话中的每一个字对应的那一条向量里, 都融入这句话所有字的信息, 那么我们在最终隐藏层的计算结果里, 只要取出$[cls]token$所对应的一条向量, 里面就含有整个句子的信息, 因为我们期望这个句子里面所有信息都会往$[cls]token$所对应的一条向量里汇总:
模型最终输出的隐藏层的计算结果的维度是:
$X_{hidden}$: [batch_size, seq_len, embedding_dim]$
我们要取出$[cls]token$所对应的一条向量, $[cls]$对应着seq len维度的第$0$条:
$cls\_vector = X_{hidden}[:, 0, :]$,
$cls\_vector \in \mathbb{R}^{batch\_size, embedding\_dim} $
之后我们再初始化一个权重, 完成从embedding dim维度到1的映射, 也就是逻辑回归, 之后用$sigmoid$函数激活, 就得到了而分类问题的推断.
我们用$\hat{y}$来表示模型的输出的推断, 他的值介于$(0, 1)$之间:
$\hat{y} = sigmoid(Linear(cls vector)) \quad \hat{y} \in (0, 1)$
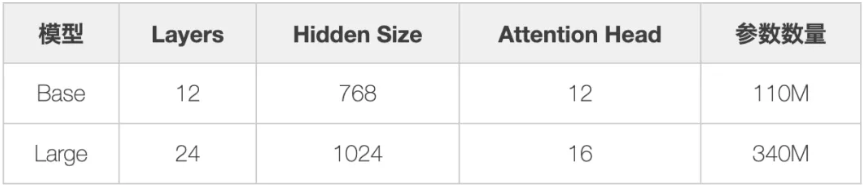
3.BERT训练参数和技巧
BERT论文中, 推荐的模型参数为: 基准模型transformer_block=12, embedding_dimension=768, num_heads=12, Total Param eters=110M), 可见其中共有1.1亿参数, 除此之外, 还有比基准模型还大的高性能模型, 参数量为3亿, 要想训练并使用这么大参数的模型, 需要充裕的计算资源。
训练技巧:
- 因为我们是按单个字为单位训练BERT, 所以在Masked LM里面, 把句子中的英文单词分出来, 将英文单词所在的区域一起遮盖掉, 让模型预测这个部分;
- 很多句子里含有数字, 显然在Masked LM中, 让模型准确地预测数据是不现实的, 所以我们把原文中的数字(包括整数和小数)都替换成一个特殊token, #NUM#, 这样模型只要预测出这个地方应该是某些数字就可以来。
四、BERT完成下游任务
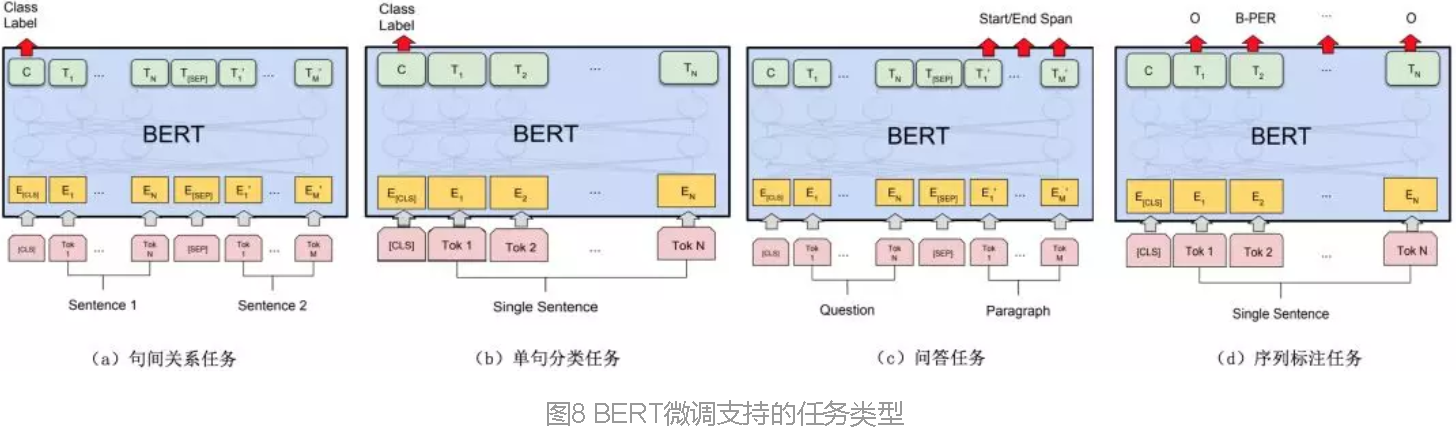
NLP四个任务:序列标注、分类任务、句子关系推断、生成式任务
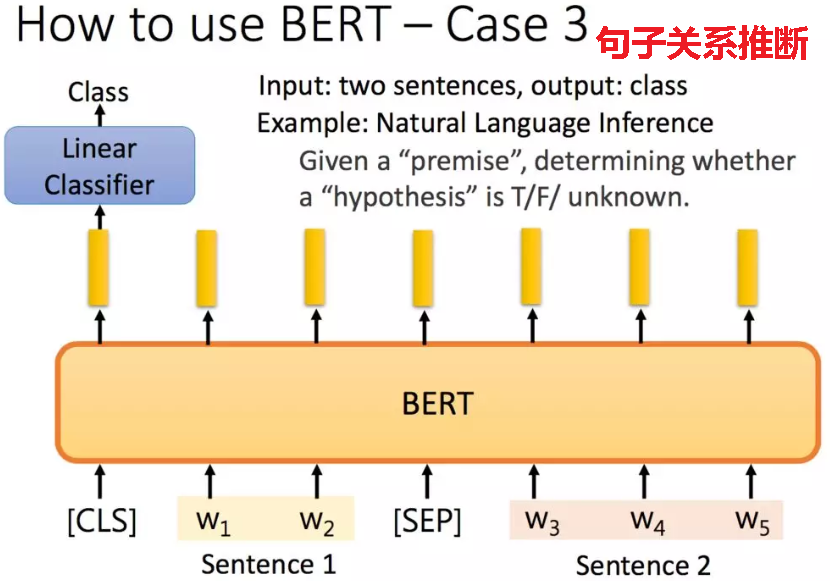
1.句子关系推断
对于句子关系类任务,和GPT类似,加上一个起始和终结符号,句子之间加个分隔符即可。对于输出来说,把第一个起始符号对应的Transformer最后一层位置上面串接一个softmax分类层即可。
举例:给定一个前提/假设,得到推论是否正确:
为了训练一个理解句子间关系的模型,引入一个下一句预测任务。这一任务的训练语料可以从语料库中抽取句子对包括两个句子A和B来进行生成,其中50%的概率B是A的下一个句子,50%的概率B是语料中的一个随机句子。NSP任务预测B是否是A的下一句。NSP的目的是获取句子间的信息,这点是语言模型无法直接捕捉的。
Google的论文结果表明,这个简单的任务对问答和自然语言推理任务十分有益,但是后续一些新的研究[15]发现,去掉NSP任务之后模型效果没有下降甚至还有提升。我们在预训练过程中也发现NSP任务的准确率经过1-2个Epoch训练后就能达到98%-99%,去掉NSP任务之后对模型效果并不会有太大的影响。
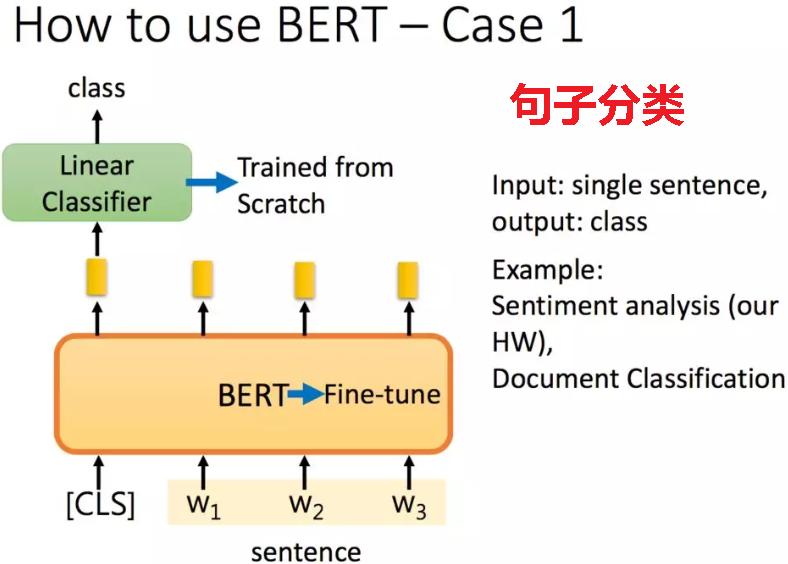
2.分类任务
如果是分类任务,在句子前面加一个标志,将其经过Bert得到的embedding输出到二分类模型中,得到分类结果。二分类模型从头开始学,而Bert在预训练的基础上进行微调(fine-tuning)。
文中还有很多其他的应用,如单词分类:
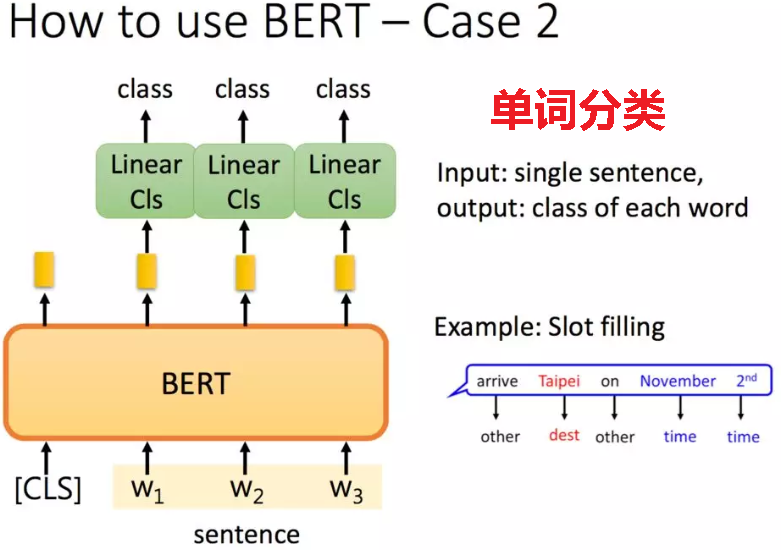
3.序列标注
输入部分和单句分类是一样的,只需要输出部分Transformer最后一层每个单词对应位置都进行分类即可。
4.生成式任务
对于机器翻译或者文本摘要,聊天机器人这种生成式任务,同样可以稍作改造即可引入Bert的预训练成果。只需要附着在S2S结构上,encoder部分是个深度Transformer结构,decoder部分也是个深度Transformer结构。根据任务选择不同的预训练数据初始化encoder和decoder即可。这是相当直观的一种改造方法。当然,也可以更简单一点,比如直接在单个Transformer结构上加装隐层产生输出也是可以的。
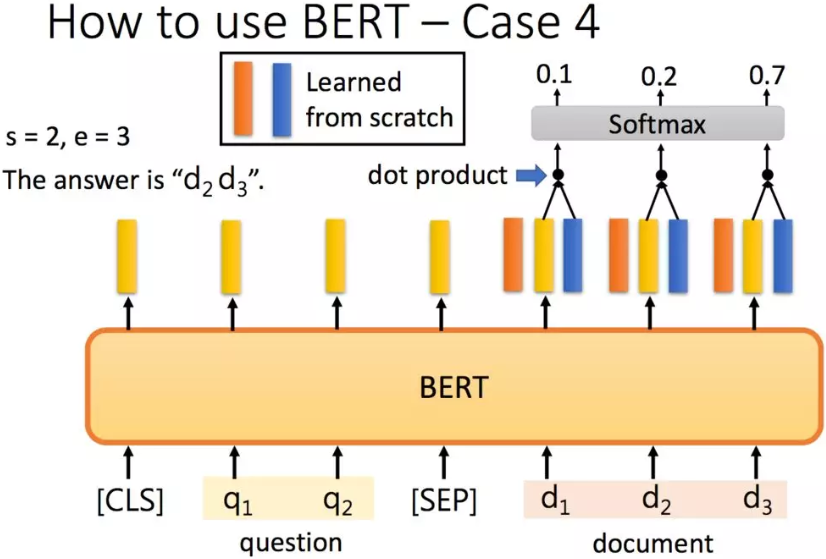
举例:抽取式QA,抽取式的意思是输入一个原文和问题,输出两个整数start和end,代表答案在原文中的起始位置和结束位置,两个位置中间的结果就是答案。
解决QA问题:把问题 - 分隔符 - 原文输入到BERT中,每一个单词输出一个黄颜色的embedding,这里还需要学习两个(一个橙色一个蓝色)的向量,这两个向量分别与原文中每个单词对应的embedding进行点乘,经过softmax之后得到输出最高的位置。正常情况下start <= end,但如果start > end的话,说明是矛盾的case,此题无解。


五、BERT总结
1.优点
- 考虑双向信息(LM只考虑单向)
- 长距离依赖(long-term dependence)
2.缺点
- 测试数据没有[mask],discrepancy,削弱了一定的泛化能力。
- 缺乏生成能力(LM具有生成能力)
- 针对每一个mask预测时,没有考虑mask间的相关性(例:w1 w2 [mask] w4 w5 [mask] w7,第一个mask为w3,第二个mask为w6,理想情况是需要考虑w3和w6间相关性的,bert里面没有考虑这点,二者是独立的)
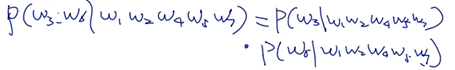 类似于朴素贝叶斯,没有考虑特征间的相关性。
类似于朴素贝叶斯,没有考虑特征间的相关性。
六、应用
1.获得句向量
使用BERT模型生成句子序列向量 - 不著人间风雨门 - 博客园
参考文献:
【1】美团BERT的探索和实践
【3】aespresso/a_journey_into_math_of_ml: 汉语自然语言处理视频教程-开源学习资料
【6】Dissecting BERT Part 1: The Encoder - Dissecting BERT - Medium
【7】使用BERT模型生成句子序列向量 - 不著人间风雨门 - 博客园
【8】NLP:自回归(Autoregressive LM)与自编码语言模型(Autoencoder LM)_人工智能_小马哥的博客-CSDN博客
【9】台大《应用深度学习》国语课程(2020) by 陈蕴侬
Transformer---BERT模型的更多相关文章
- attention、self-attention、transformer和bert模型基本原理简述笔记
attention 以google神经机器翻译(NMT)为例 无attention: encoder-decoder在无attention机制时,由encoder将输入序列转化为最后一层输出state ...
- 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史(转载)
转载 https://zhuanlan.zhihu.com/p/49271699 首发于深度学习前沿笔记 写文章 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 张 ...
- BERT模型介绍
前不久,谷歌AI团队新发布的BERT模型,在NLP业内引起巨大反响,认为是NLP领域里程碑式的进步.BERT模型在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩:全部两个衡量指标上全面超越 ...
- 想研究BERT模型?先看看这篇文章吧!
最近,笔者想研究BERT模型,然而发现想弄懂BERT模型,还得先了解Transformer. 本文尽量贴合Transformer的原论文,但考虑到要易于理解,所以并非逐句翻译,而是根据笔者的个人理解进 ...
- zz从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 Bert最近很火,应该是最近最火爆的AI进展,网上的评价很高,那么Bert值得这么高的评价吗?我个人判断是值得.那为什么 ...
- 图示详解BERT模型的输入与输出
一.BERT整体结构 BERT主要用了Transformer的Encoder,而没有用其Decoder,我想是因为BERT是一个预训练模型,只要学到其中语义关系即可,不需要去解码完成具体的任务.整体架 ...
- BERT模型
BERT模型是什么 BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为de ...
- 使用BERT模型生成token级向量
本文默认读者有一定的Transformer基础,如果没有,请先稍作学习Transormer以及BERT. 相信网上有很多方法可以生成BERT向量,最有代表性的一个就是bert as service,用 ...
- NLP学习(3)---Bert模型
一.BERT模型: 前提:Seq2Seq模型 前提:transformer模型 bert实战教程1 使用BERT生成句向量,BERT做文本分类.文本相似度计算 bert中文分类实践 用bert做中文命 ...
- Pytorch | BERT模型实现,提供转换脚本【横扫NLP】
<谷歌终于开源BERT代码:3 亿参数量,机器之心全面解读>,上周推送的这篇文章,全面解读基于TensorFlow实现的BERT代码.现在,PyTorch用户的福利来了:一个名为Huggi ...
随机推荐
- RAID及磁盘配额
RAID的对比: 版本 特点 磁盘个数 可用空间 故障磁盘数 应用环境 RAID0 读写速度快,数据容易丢失 两个 全部 一块 测试,临时性 RAID1 读写速度慢,数据可靠 至少两个,可以2的倍数 ...
- 洛谷p3384【模板】树链剖分题解
洛谷p3384 [模板]树链剖分错误记录 首先感谢\(lfd\)在课上调了出来\(Orz\) \(1\).以后少写全局变量 \(2\).线段树递归的时候最好把左右区间一起传 \(3\).写\(dfs\ ...
- 日常笔记4关于cin、cin.get()、cin.getline()、getline()使用区别
1.关于PAT中段错误 使用字符数组出现错误: char str[256]; 报错段错误,然后改用C++中的string 改成: string str; 同char数组一样,也可以使用下标来取单个字符 ...
- Windows搭建FTP/Http文件共享(利用IIS)
控制面板——程序——添加功能 勾选Ftp服务器.万维网服务.IIS管理控制台 然后,计算机——右键管理——服务和应用程序,添加网站和添加Ftp IP设置为 未分配 或 本机获取到的静态IP即可. 然后 ...
- 你真的了解strtotime('X month')吗
经常会有人被strtotime结合-1 month, +1 month, next month的时候搞得很困惑, 然后就会觉得这个函数有点不那么靠谱, 动不动就出问题. 用的时候就会很慌… 今天是20 ...
- .net core —— 控制台如何获取配置文件的内容?
本文链接:https://blog.csdn.net/yenange/article/details/82457761参考: https://github.com/liuzhenyulive/Json ...
- kibana无法显示elasticsearch中的index
我是用的logstash将kafka中的数据同步到elasticsearch.logstash和kafka在同一台服务器,elasticsearch在另外的服务器上. 经过排查,是因为我的logsta ...
- Shell脚本——添加和删除用户
写一个脚本admin_user.sh,其用法格式为: admin_user.sh --add USERLIST --del USERLIST -v|--verbose -h|--help 其中, -h ...
- torch_09_GAN
1.生成对抗网络 让两个网络相互竞争,通过生成网络来生成假的数据,对抗网络通过判别器判别真伪,最后希望生成网络生成的数据能够以假乱真骗过判别器 2.生成模型 就是‘生成’样本和‘真实’的样本尽可能的相 ...
- ng 使用阿里巴巴矢量图
1.进入阿里巴巴矢量图标库中,选择需要下载的图标,添加进项目中 2.进去项目选择Font class 模式,然后下载到本地 3.解压下载的压缩包,把.css/.svg/.ttf/.woff/.woff ...