HDFS中的fsck命令(检查数据块是否健康)
在HDFS中,提供了fsck命令,用于检查HDFS上文件和目录的健康状态、获取文件的block信息和位置信息等。
我们在master机器上执行hdfs fsck就可以看到这个命令的用法。
[hadoop-twq@master ~]$ hdfs fsck
Usage: hdfs fsck <path> [-list-corruptfileblocks | [-move | -delete | -openforwrite] [-files [-blocks [-locations | -racks]]]] [-includeSnapshots] [-storagepolicies] [-blockId <blk_Id>]
<path> start checking from this path
-move move corrupted files to /lost+found
-delete delete corrupted files
-files print out files being checked
-openforwrite print out files opened for write
-includeSnapshots include snapshot data if the given path indicates a snapshottable directory or there are snapshottable directories under it
-list-corruptfileblocks print out list of missing blocks and files they belong to
-blocks print out block report
-locations print out locations for every block
-racks print out network topology for data-node locations
-storagepolicies print out storage policy summary for the blocks
-blockId print out which file this blockId belongs to, locations (nodes, racks) of this block, and other diagnostics info (under replicated, corrupted or not, etc)
查看文件目录的健康信息
执行如下的命令:
hdfs fsck /user/hadoop-twq/cmd可以查看/user/hadoop-twq/cmd目录的健康信息:
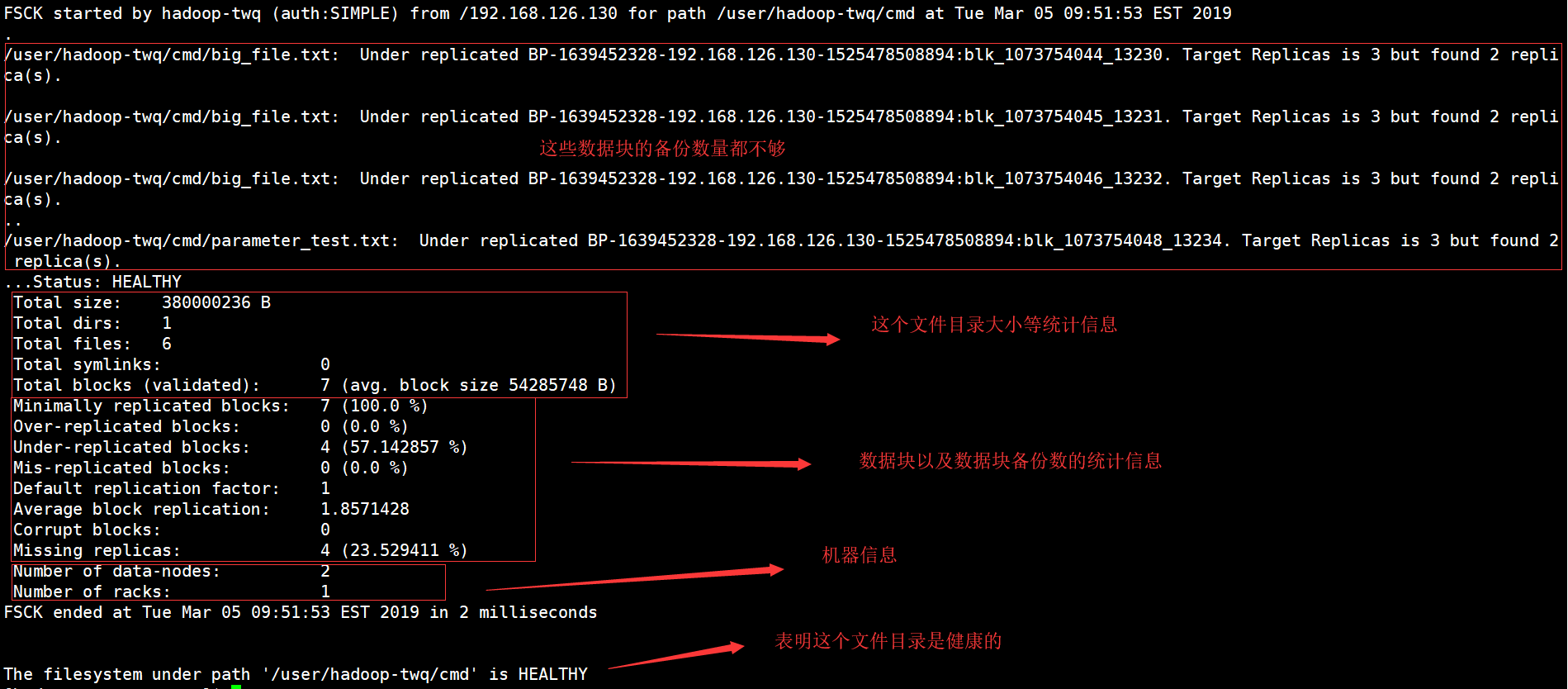
其中有一个比较重要的信息,就是Corrupt blocks,表示损坏的数据块的数量
查看文件中损坏的块 (-list-corruptfileblocks)
[hadoop-twq@master ~]$ hdfs fsck /user/hadoop-twq/cmd -list-corruptfileblocks
Connecting to namenode via http://master:50070/fsck?ugi=hadoop-twq&listcorruptfileblocks=1&path=%2Fuser%2Fhadoop-twq%2Fcmd
The filesystem under path '/user/hadoop-twq/cmd' has 0 CORRUPT files
上面的命令可以找到某个目录下面的损坏的数据块,但是上面表示没有看到坏的数据块
损坏文件的处理
将损坏的文件移动至/lost+found目录 (-move)
hdfs fsck /user/hadoop-twq/cmd -move
删除有损坏数据块的文件 (-delete)
hdfs fsck /user/hadoop-twq/cmd -delete
检查并列出所有文件状态(-files)
执行如下的命令:
hdfs fsck /user/hadoop-twq/cmd -files
显示结果如下:
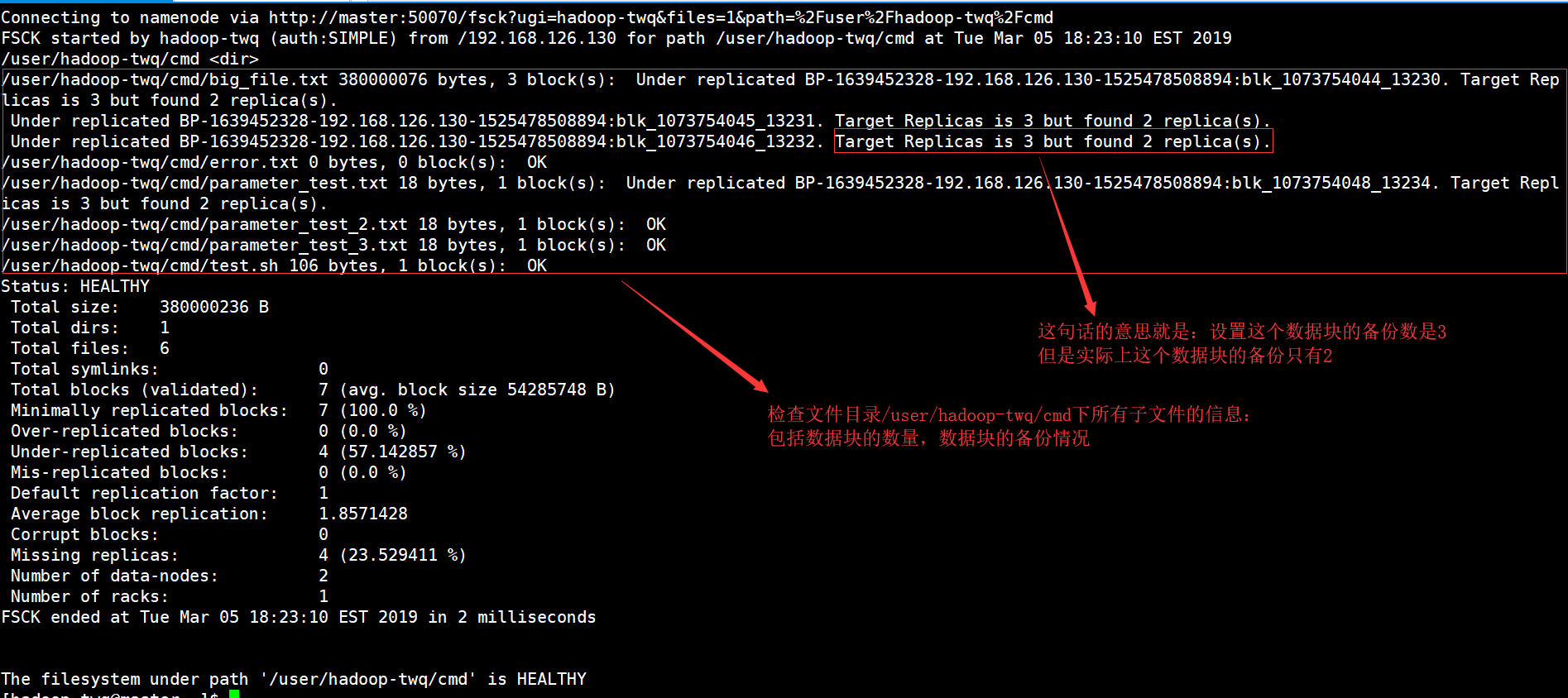
上面的命令可以检查指定路径下的所有文件的信息,包括:数据块的数量以及数据块的备份情况
检查并打印正在被打开执行写操作的文件(-openforwrite)
执行下面的命令可以检查指定路径下面的哪些文件正在执行写操作:
hdfs fsck /user/hadoop-twq/cmd -openforwrite
打印文件的Block报告(-blocks)
执行下面的命令,可以查看一个指定文件的所有的Block详细信息,需要和-files一起使用:
hdfs fsck /user/hadoop-twq/cmd/big_file.txt -files -blocks
结果如下:

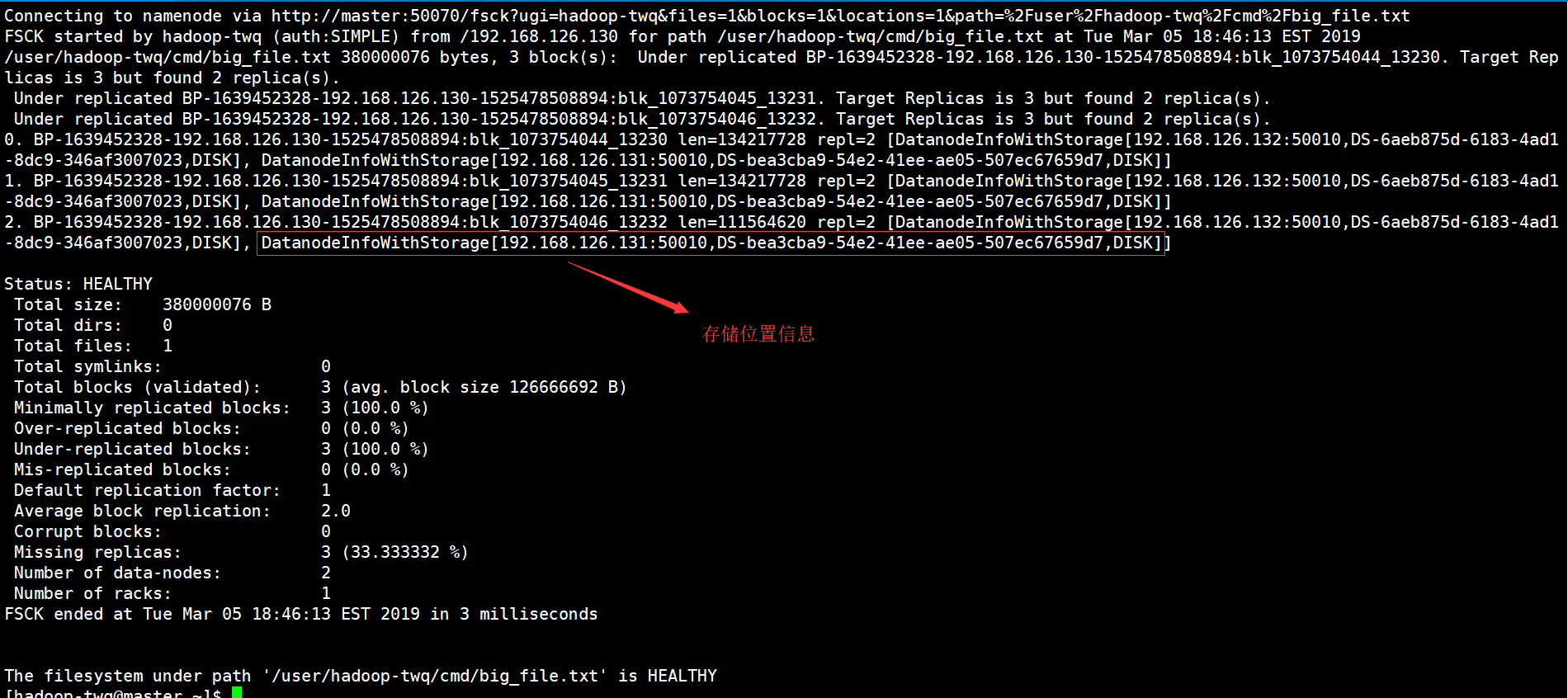
如果,我们在上面的命令再加上-locations的话,就是表示还需要打印每一个数据块的位置信息,如下命令:
hdfs fsck /user/hadoop-twq/cmd/big_file.txt -files -blocks -locations
结果如下:
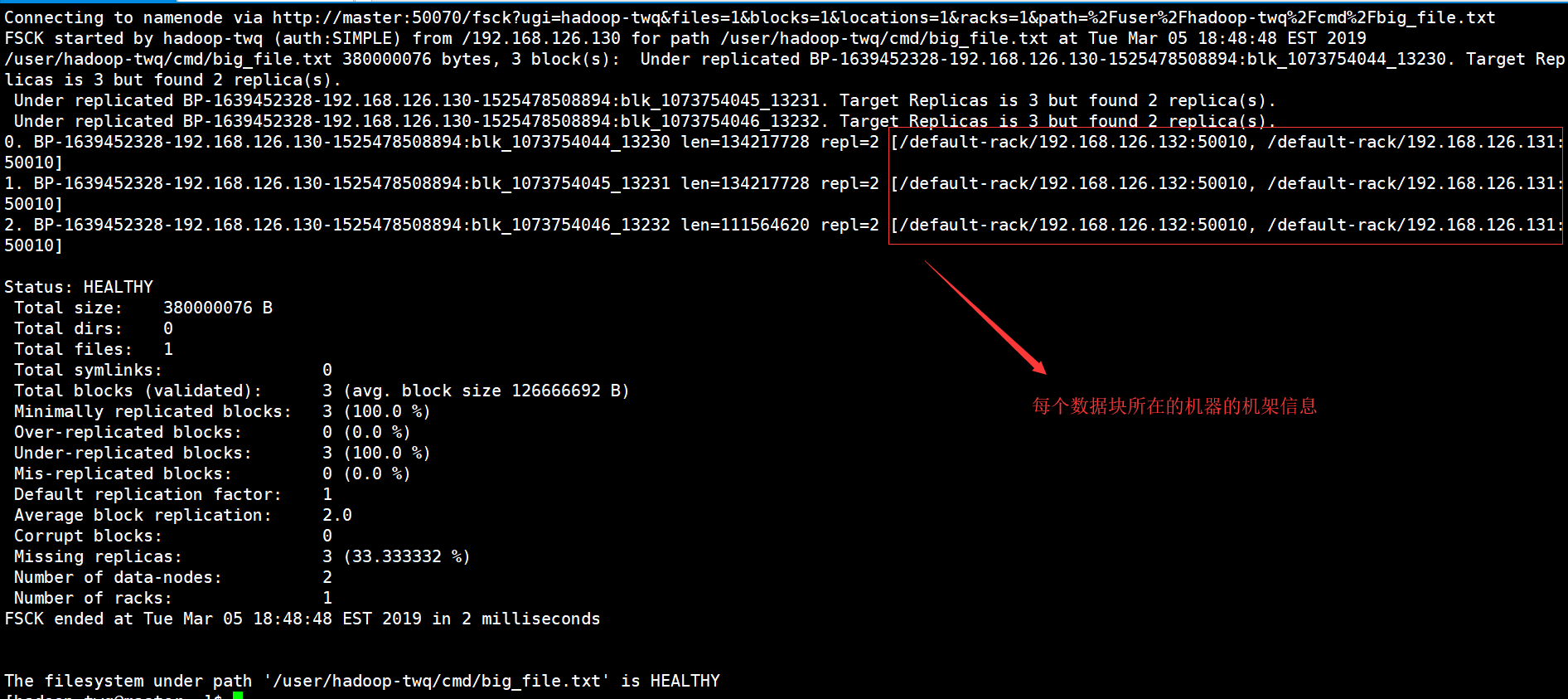
如果,我们在上面的命令再加上-racks的话,就是表示还需要打印每一个数据块的位置所在的机架信息,如下命令:
hdfs fsck /user/hadoop-twq/cmd/big_file.txt -files -blocks -locations -racks
结果如下:
hdfs fsck的使用场景
场景一
当我们执行如下的命令:
hdfs fsck /user/hadoop-twq/cmd
可以查看/user/hadoop-twq/cmd目录的健康信息:
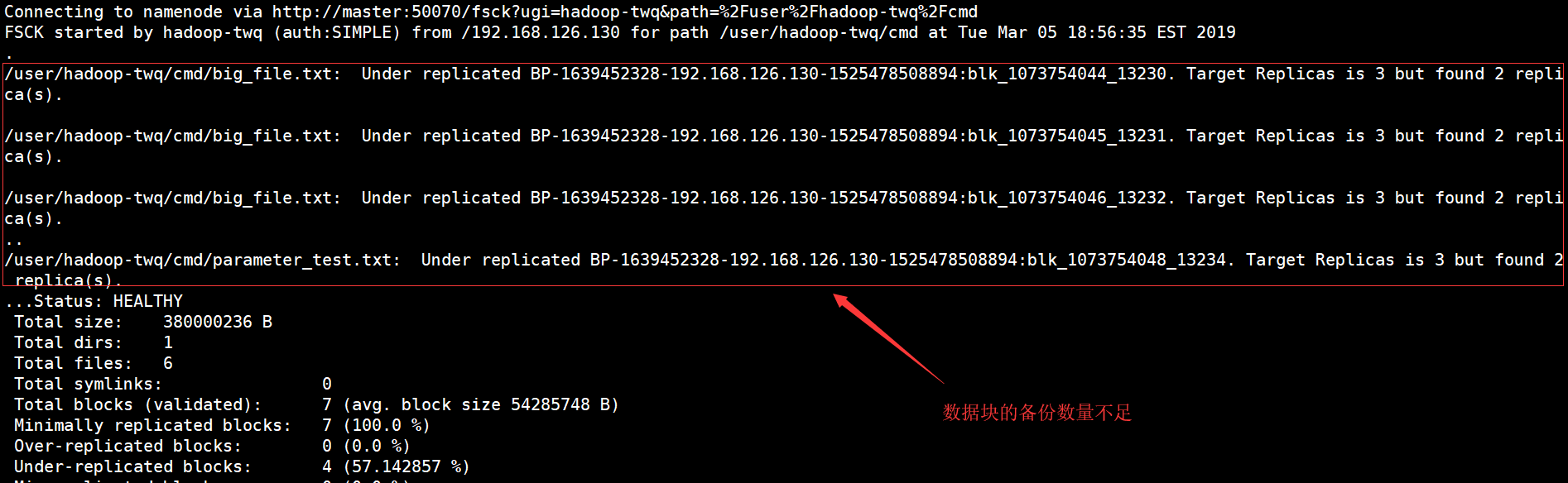
我们可以看出,有两个文件的数据块的备份数量不足,这个我们可以通过如下的命令,重新设置两个文件数据块的备份数:
## 将文件big_file.txt对应的数据块备份数设置为1
hadoop fs -setrep -w 1 /user/hadoop-twq/cmd/big_file.txt
## 将文件parameter_test.txt对应的数据块备份数设置为1
hadoop fs -setrep -w 1 /user/hadoop-twq/cmd/parameter_test.txt
上面命令中 -w 参数表示等待备份数到达指定的备份数,加上这个参数后再执行的话,则需要比较长的时间
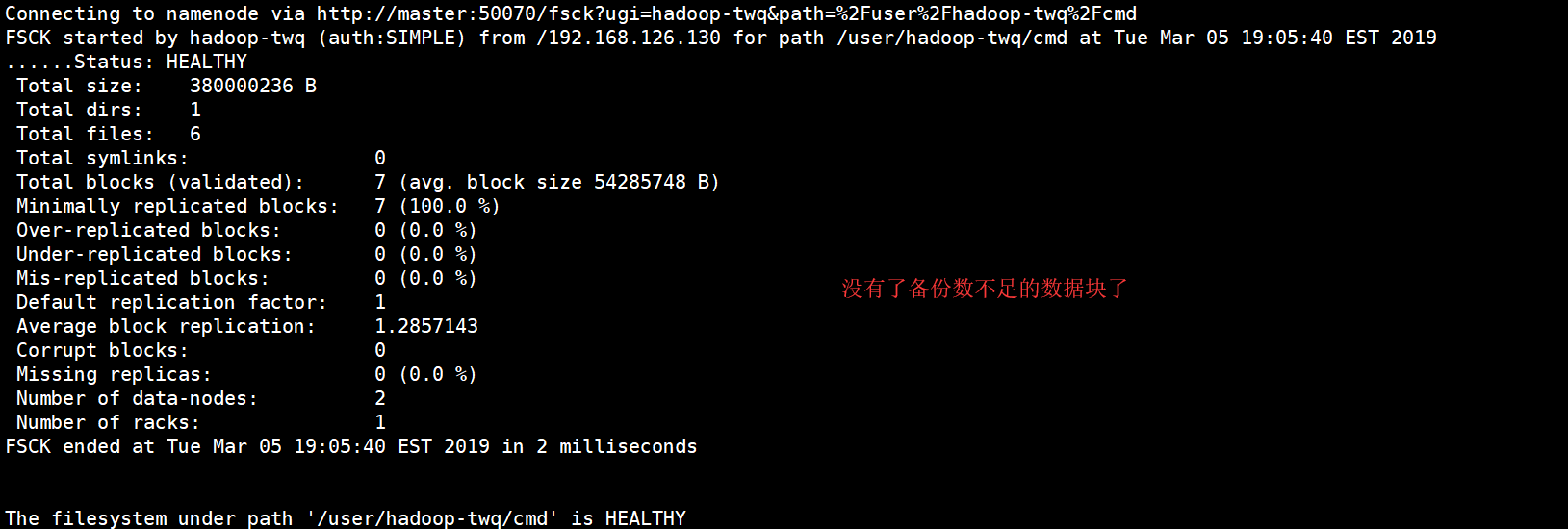
执行完上面的命令后,我们再来执行下面的命令:
hdfs fsck /user/hadoop-twq/cmd
结果如下:
场景二
当我们访问HDFS的WEB UI的时候,出现了如下的警告信息:
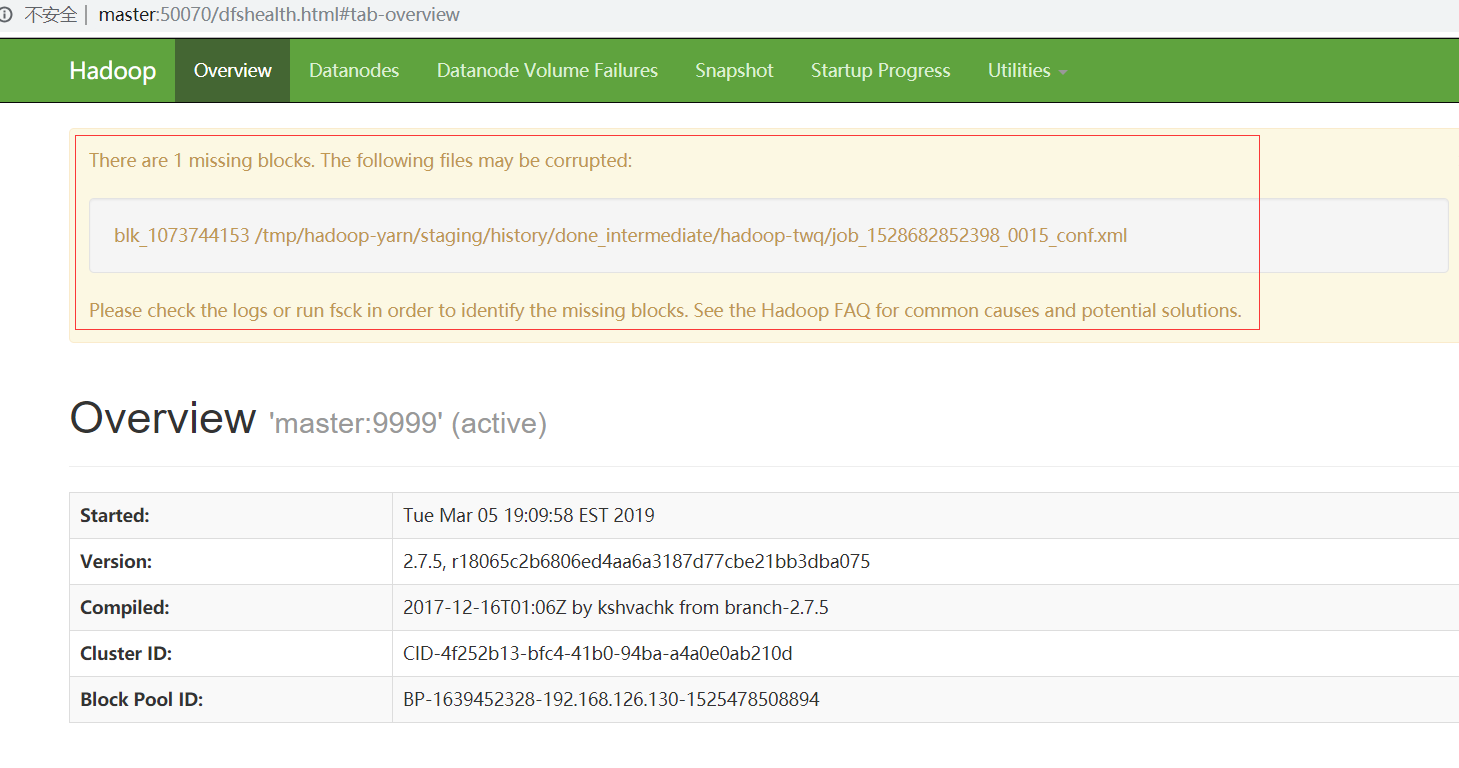
表明有一个数据块丢失了,这个时候我们执行下面的命令来确定是哪一个文件的数据块丢失了:
[hadoop-twq@master ~]$ hdfs fsck / -list-corruptfileblocks
Connecting to namenode via http://master:50070/fsck?ugi=hadoop-twq&listcorruptfileblocks=1&path=%2F
The list of corrupt files under path '/' are:
blk_1073744153 /tmp/hadoop-yarn/staging/history/done_intermediate/hadoop-twq/job_1528682852398_0015_conf.xml
The filesystem under path '/' has 1 CORRUPT files
发现是数据块blk_1073744153丢失了,这个数据块是淑文文件/tmp/hadoop-yarn/staging/history/done_intermediate/hadoop-twq/job_1528682852398_0015_conf.xml的。
如果出现这种场景是因为在DataNode中没有这个数据块,但是在NameNode的元数据中有这个数据块的信息,我们可以执行下面的命令,把这些没用的数据块信息删除掉,如下:
[hadoop-twq@master ~]$ hdfs fsck /tmp/hadoop-yarn/staging/history/done_intermediate/hadoop-twq/ -delete
Connecting to namenode via http://master:50070/fsck?ugi=hadoop-twq&delete=1&path=%2Ftmp%2Fhadoop-yarn%2Fstaging%2Fhistory%2Fdone_intermediate%2Fhadoop-twq
FSCK started by hadoop-twq (auth:SIMPLE) from /192.168.126.130 for path /tmp/hadoop-yarn/staging/history/done_intermediate/hadoop-twq at Tue Mar 05 19:18:00 EST 2019
....................................................................................................
..
/tmp/hadoop-yarn/staging/history/done_intermediate/hadoop-twq/job_1528682852398_0015_conf.xml: CORRUPT blockpool BP-1639452328-192.168.126.130-1525478508894 block blk_1073744153 /tmp/hadoop-yarn/staging/history/done_intermediate/hadoop-twq/job_1528682852398_0015_conf.xml: MISSING 1 blocks of total size 220262 B...................................................................................................
....................................................................................................
........................Status: CORRUPT
Total size: 28418833 B
Total dirs: 1
Total files: 324
Total symlinks: 0
Total blocks (validated): 324 (avg. block size 87712 B)
********************************
UNDER MIN REPL'D BLOCKS: 1 (0.30864197 %)
dfs.namenode.replication.min: 1
CORRUPT FILES: 1
MISSING BLOCKS: 1
MISSING SIZE: 220262 B
CORRUPT BLOCKS: 1
********************************
Minimally replicated blocks: 323 (99.69136 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 0 (0.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 1
Average block replication: 0.99691355
Corrupt blocks: 1
Missing replicas: 0 (0.0 %)
Number of data-nodes: 2
Number of racks: 1
FSCK ended at Tue Mar 05 19:18:01 EST 2019 in 215 milliseconds
然后执行:
[hadoop-twq@master ~]$ hdfs fsck / -list-corruptfileblocks
Connecting to namenode via http://master:50070/fsck?ugi=hadoop-twq&listcorruptfileblocks=1&path=%2F
The filesystem under path '/' has 0 CORRUPT files
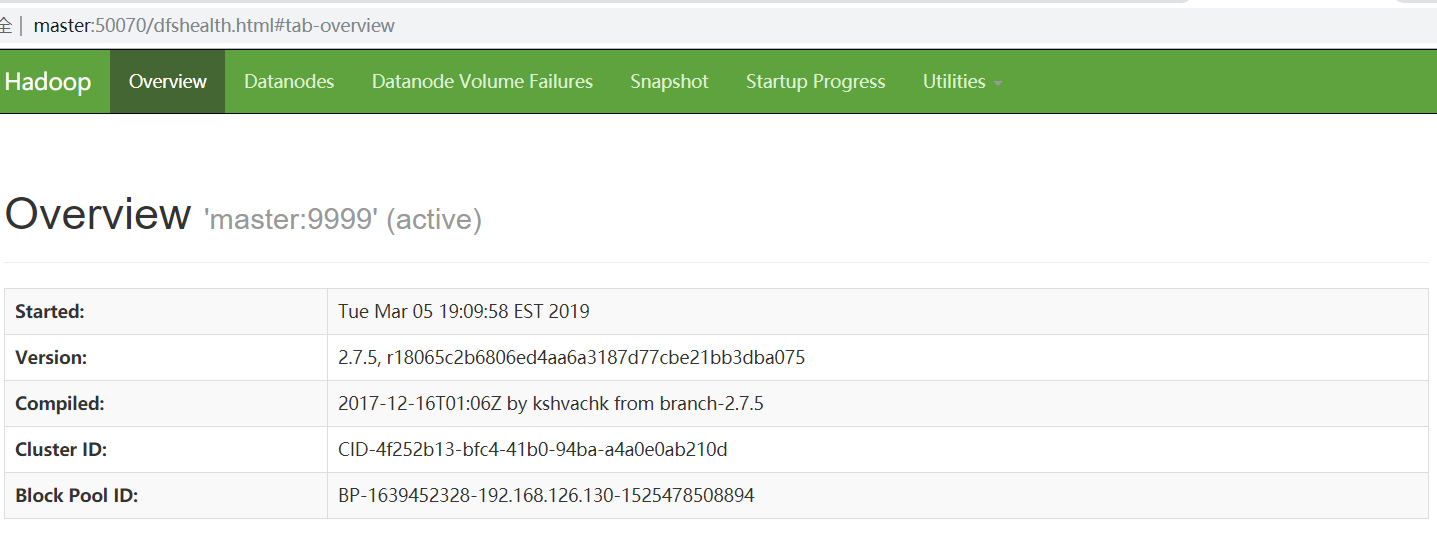
丢失的数据块没有的,被删除了。我们也可以刷新WEB UI,也没有了警告信息:
HDFS中的fsck命令(检查数据块是否健康)的更多相关文章
- 利用describe( )中的count来检查数据是否缺省
#-*- coding: utf-8 -*- #在python的pandas库中,只需要读入数据,然后使用describe()函数就可以查看数据的基本情况 import pandas as pd in ...
- HDFS源码分析之数据块Block、副本Replica
我们知道,HDFS中的文件是由数据块Block组成的,并且为了提高容错性,每个数据块Block都会在不同数据节点DataNode上有若干副本Replica.那么,什么是Block?什么又是Replic ...
- HDFS中的数据块(Block)
我们在分布式存储原理总结中了解了分布式存储的三大特点: 数据分块,分布式的存储在多台机器上 数据块冗余存储在多台机器以提高数据块的高可用性 遵从主/从(master/slave)结构的分布式存储集群 ...
- HDFS源码分析心跳汇报之数据块增量汇报
在<HDFS源码分析心跳汇报之BPServiceActor工作线程运行流程>一文中,我们详细了解了数据节点DataNode周期性发送心跳给名字节点NameNode的BPServiceAct ...
- HDFS源码分析数据块汇报之损坏数据块检测checkReplicaCorrupt()
无论是第一次,还是之后的每次数据块汇报,名字名字节点都会对汇报上来的数据块进行检测,看看其是否为损坏的数据块.那么,损坏数据块是如何被检测的呢?本文,我们将研究下损坏数据块检测的checkReplic ...
- HDFS源码分析数据块之CorruptReplicasMap
CorruptReplicasMap用于存储文件系统中所有损坏数据块的信息.仅当它的所有副本损坏时一个数据块才被认定为损坏.当汇报数据块的副本时,我们隐藏所有损坏副本.一旦一个数据块被发现完好副本达到 ...
- Oracle 数据块损坏与恢复具体解释
1.什么是块损坏: 所谓损坏的数据块,是指块没有採用可识别的 Oracle 格式,或者其内容在内部不一致. 通常情况下,损坏是由硬件故障或操作系统问题引起的.Oracle 数据库将损坏的块标识为&qu ...
- [转]Oracle数据块体系的详细介绍
数据块概述Oracle对数据库数据文件(datafile)中的存储空间进行管理的单位是数据块(data block).数据块是数据库中最小的(逻辑)数据单位.与数据块对应的,所有数据在操作系统级的最小 ...
- Oracle数据块深入分析总结
http: 最近在研究块的内部结构,把文档简单整理了一下,和大家分享一下.该篇文章借助dump和BBED对数据 库内部结构进行了分析,最后附加了一个用BBED解决ORA-1200错误的小例子.在总结的 ...
随机推荐
- GCC 基础知识
目录 GCC 基础知识 一.GCC编译选项解析 二.多模块.多个文件一起编译 三.静态库与动态库 四.查看帮助文档 GCC 基础知识 一.GCC编译选项解析 1. 常用编译选项 命令格式:gcc [选 ...
- maven dependency中provided和compile的区别
重点:这个项目打成war包时,scope=provided的jar包,不会出现在WEB-INFO/lib目录下,而scope=compile的jar包,会放到WEB-INFO/lib目录 scope= ...
- ApachShiro 一个系统 两套验证方法-(后台管理员登录、前台App用户登录)同一接口实现、源码分析
需求: 在公司新的系统里面博主我使用的是ApachShiro 作为安全框架.作为后端的鉴权以及登录.分配权限等操作 管理员的信息都是存储在管理员表 前台App 用户也需要校验用户名和密码进行登录.但是 ...
- Git命令和使用
Git & GitHub Git是一个工具,用于命令行操作 GitHub是一个协同工作平台 包括: Remote original Repository - 远程主仓库(上线唯一仓库) Rem ...
- ConsoleLoggerExtensions.AddConsole(ILoggerFactory)已过时代码修复
0x00.问题 netcoreapp2.2环境下, Startup.cs 代码配置如下 public void Configure(IApplicationBuilder app, IHostingE ...
- C# 使用代理实现方法过滤
一.为什么要进行方法过滤 一些情况下我们需要再方法调用前记录方法的调用时间和使用的参数,再调用后需要记录方法的结束时间和返回结果,当方法出现异常的时候,需要记录异常的堆栈和原因,这些都是与业务无关的代 ...
- ssh免秘钥
用过好几次免秘钥,但是每次都会忘了应该把copy谁的公钥到另外用户的.ssh文件夹 这里专门记录一次 注意点: A要使用ssh免密登录到B用户下(可以使远程服务器),就把A的用户下的.ssh文件的id ...
- 超详细Vue实现导航栏绑定内容锚点+滚动动画+vue-router(hash模式可用)
超详细Vue实现导航栏绑定内容锚点+滚动动画+vue-router(hash模式可用) 转载自:https://www.jianshu.com/p/2ad8c8b5bf75 亲测有效~ <tem ...
- tomcat7:deploy (default-cli) on project myproject: Cannot invoke Tomcat manager: Software caused connection abort: socket write error
我使用的默认settings.xml,默认的里面只有tomcat6的服务器,没有tomcat7的服务器,接着往下看,下面来验证我的言论 进行tomcat7:run的命令时
- UCOSIII事件标志组
两种同步机制 "或"同步 "与"同步 使能 #define OS_CFG_FLAG_EN 1u /* Enable (1) or Disable (0) cod ...