Java的Stream流式操作
前言
最近在实习,在公司看到前辈的一些代码,发现有很多值得我学习的地方,其中有一部分就是对集合使用Stream流式操作,觉得很优美且方便。所以学习一下Stream流,在这里记录一下。
Stream是什么
Stream是Java 8中出现的新特性,极大增强了集合对象的功能,专注于对集合对象进行方便、高效的聚合操作。另外可以配合Lambda表达式,让代码更加容易理解。另外Stream提供串行和并行两种操作方式,并行操作可以很方便的写出高性能的并发程序。
Stream像是一个高级版本的Iterator,使用Iterator只能显式地遍历一个个元素对其执行某些操作;使用Stream,我们只需要指定对集合包含的元素执行什么操作,例如“只获取性别为男的用户”、“获取每个用户姓名的姓氏”等,Stream会帮我们完成隐式的遍历操作,并转换数据。
与Iterator不同的是,Iterator只能串行操作,每次操作完一个元素再去下一个元素。Stream支持串行、并行操作,Stream的并行操作依赖Java 7的Fork/Join框架(JSR166y)来拆分任务和加速处理过程。
Stream就像是一条流水线,单向,不可回头,只能遍历一次,之后就不能再使用了。
使用一个Stream流,一般分为三个步骤:1. 获取数据源-> 2. 中间操作(Intermediate)-> 3. 终端操作(Terminal)。
中间操作:一个流可以有0或多个中间操作,对数据进行转换、过滤等操作,一个接着一个,这些操作是lazy的,中间操作是还没有开始真正的遍历。
终端操作:一个流只能有一个终端操作,使用终端操作之后就会返回结果,不能再使用这个流了。终端操作时,才真正开始遍历。
在Stream中一个流的多次中间操作不是每一次都进行一次遍历的,中间操作是lazy 的,多个中间操作是最终聚合到终端操作的时候进行的,只进行一次遍历循环。可以理解为每个中间操作被当做一个判断条件加入到终端操作循环中,完成每个元素的数据转换。
下面是一些Stream流操作方法的分类:
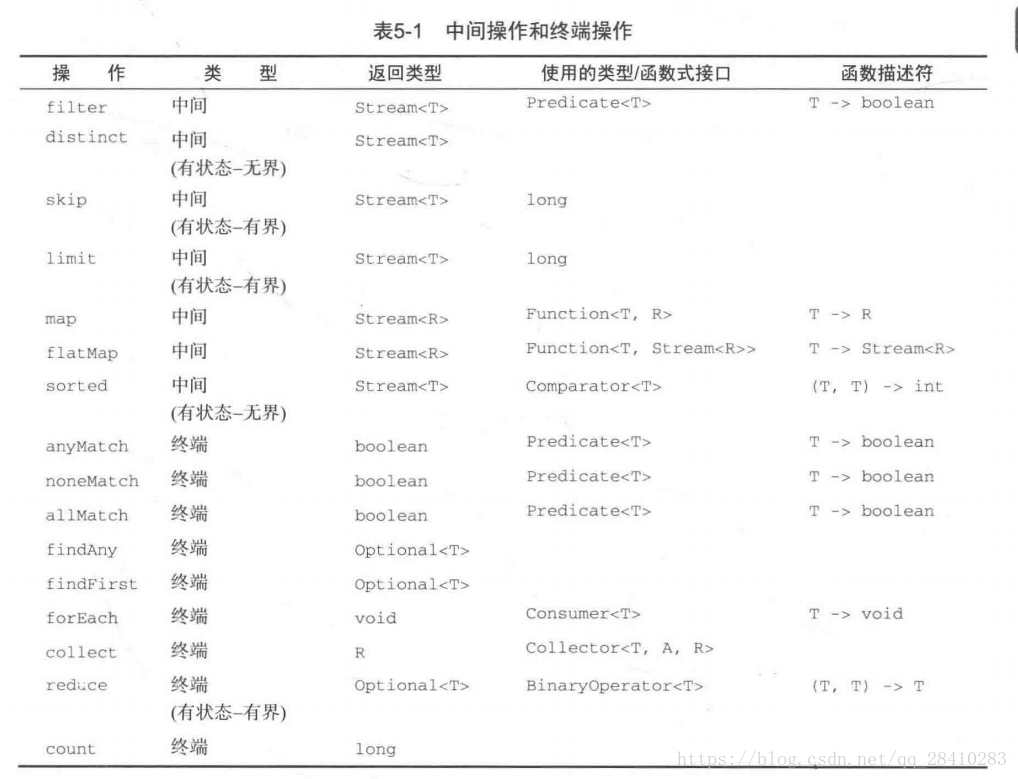
Stream流的创建方式
数组
- Arrays.stream(T array);
- stream.of(array)
Collection
- Collection.stream()
- Collection.parallelStream()
BufferedReader
- java.io.BufferedReader.lines()
静态工厂
- java.util.stream.IntStream.range()
- java.nio.file.Files.walk()
自己构建
- java.util.Spliterator
其他
- Random.ints()
- BitSet.stream()
- Pattern.splitAsStream(java.lang.CharSequence)
- JarFile.stream()
创建示例
//数组
String[] array = new String[]{"1","2","3"};
Arrays.stream(array);
Stream.of(array);
Stream.of(1, 2, 3);
//集合
List<String> list = Arrays.asList(array);
list.stream();
list.parallelStream();
//数值,目前只支持IntStream、LongStream、DoubleStream三种
IntStream.of(new int[]{1,2,3}).forEach(System.out::println);
IntStream.range(1,3).forEach(System.out::println);
IntStream.rangeClosed(1, 3).forEach(System.out::println);
流转换为其它数据结构
Stream stream = Stream.of("1","2","3");
//Array
String[] array2=(String[]) stream.toArray(String[]::new);
//Collection
List<String> list1=(List)stream.collect(Collectors.toList());
List<String> list2=(List)stream.collect(Collectors.toCollection(ArrayList::new));
Set set=(Set)stream.collect(Collectors.toSet());
Stack stack=(Stack)stream.collect(Collectors.toCollection(Stack::new));
//String
String str = stream.collect(Collectors.joining()).toString();
经典用法
1. 将一个List中元素的某一属性取出来作为一个list,并做过滤
List<Long> names= users.stream().filter(Objects::nonNull).map(User::getId).collect(Collectors.toList());
//或者
List<Long> names1=
users.stream().filter(Objects::nonNull).map(u->u.getId()).collect(Collectors.toList());
//遍历list
names.forEach(System.out::println);
2. 将List转换成Map
//key:id value:name
Map<Long, String> map = users.stream().collect(Collectors.toMap(p -> p.getId(), p -> p.getName()));
//或者,第三个参数表示如果key重复保留k1,舍弃k2。
Map<Long, String> map2 = users.stream().collect(Collectors.toMap(User::getId,User::getName,(k1,k2)->k1));
//key:id value:user
Map<Long, User> map3 = users.stream().collect(Collectors.toMap(p -> p.getId(), p->p));
//遍历map,包括k,v。map.values.forEach()不能遍历Key
map3.forEach((k,v)-> System.out.println("k:v="+k+":"+v));
3. 使用sorted对List排序
//降序,默认是升序
List<User> list=
users.stream().sorted(Comparator.comparing(User::getId).reversed()).collect(Collectors.toList());
//遍历list
list.forEach(System.out::println);
Comparator.comparing(User::getId)表示以id作为排序的数据。
4. 对List分组存入一个Map
//按照性别分组
Map<String,List<User>> map=users.stream().collect(Collectors.groupingBy(User::getSex));
map.forEach((k,v)-> System.out.println("k:v="+k+":"+v));
5. 使用map转换大写
List<String> list1 = new ArrayList<>();
list1.add("a");
list1.add("b");
list1.add("c");
List<String> list2 = list1.stream().map(String::toUpperCase).collect(Collectors.toList());
6. flatMap和map
//map
List<String> str = Arrays.asList("a,b,c", "d,e", "f");
List<String[]> list1 = str.stream().map(s -> s.split(",")).collect(Collectors.toList());
list1.forEach(p-> System.out.print(Arrays.toString(p)+","));//[a, b, c],[d, e],[f]
//flatMap
List<String> list2 = str.stream().map(s -> s.split(",")).flatMap(Arrays::stream).sorted(Comparator.comparing(p->p.toString()).reversed()).collect(Collectors.toList());
System.out.println(list2);//[f, e, d, c, b, a]
flatMap与map的区别在于 flatMap是将一个流中的每个元素都转成一个个流,flatMap之后得到的是每个流中元素的总的集合,即对每个流进行了二次遍历取出其中的元素,融合到总的集合中。
7. reduce
//求和 sum=11,第一个参数1为初始值(种子),第二个参数为运算规则(BinaryOperator)。1+1+2+3+4=11
Integer sum = Stream.of(1, 2, 3, 4).reduce(1, Integer::sum);
//concat="ABCD";
String concat = Stream.of("A", "B", "C").reduce("", String::concat);
//求和,reduce方法无初始值,返回类型为Optional,需要调用get()方法取值。
Integer sum2 = Stream.of(1, 2, 3, 4).reduce(Integer::sum).get();
//取最大值,max=2.0。
Double max = Stream.of(1.0, 2.0, -1.0, 1.5).reduce(Double.MIN_VALUE, Double::max);
optional也是Java 8中的新特性,可以存储null或者实例,有机会再深入讲吧。
8. limit和skip
List<Long> ids=users.stream().map(User::getId).limit(5).skip(2).collect(Collectors.toList());
ids.forEach(System.out::println);//0-9 输出了 2 3 4
limit(5)限制只要前五条,skip(2)跳过前两条。特别注意如果limit和skip配合sorted使用,需先进行limit和skip。
9. anyMatch
Map<Long, String> map = new HashMap<>();
map.put(1L, "1号");
map.put(2L, "2号");
map.put(3L, "3号");
List<User> list = Lists.newArrayList();
list.add(new User(1L,10,"1号","",""));
list.add(new User(2L,10,"2号","",""));
list.add(new User(3L,10,"3号","",""));
boolean f = false;
//所有都匹配的时候才会返回true
for(Map.Entry<Long,String> entry:map.entrySet()){
f = list.stream().anyMatch(p ->
Objects.equals(entry.getKey(), p.getId())
);
}
以下,补充于20191211
突然想起来面试的时候有几个关于取两个List的交集、并集问题也可以用Stream来解决。特此记录一下。
List<String> list1 = Lists.newArrayList();
list1.add("1");
list1.add("2");
list1.add("3");
list1.add("4");
List<String> list2 = Lists.newArrayList();
list2.add("3");
list2.add("4");
list2.add("5");
list2.add("6");
//交集,或使用list1.retainAll(list2);
List<String> intersection=list1.stream().filter(i->list2.contains(i)).collect(Collectors.toList());
System.out.println("交集:");
intersection.forEach(System.out::println);
//差集,或使用list1.removeAll(list2);
List<String> reduce=list1.stream().filter(i->!list2.contains(i)).collect(Collectors.toList());
System.out.println("差集:");
reduce.forEach(System.out::println);
//并集
List<String> listAll = list1;
listAll.addAll(list2);
System.out.println("并集:");
listAll.forEach(System.out::println);
//去重并集,或使用list1.removeAll(list2);list1.addAll(list2);
List<String> listAllDistinct = listAll.stream().distinct().collect(Collectors.toList());
System.out.println("去重并集:");
listAllDistinct.forEach(System.out::println);
使用Stream和使用ArrayList的removeAll、retainAll方法比较,Stream不会改变原来的List。
生命不息,学习不止。还需继续努力。20191210
Java的Stream流式操作的更多相关文章
- Java8——Stream流式操作的一点小总结
我发现,自从我学了Stream流式操作之后,工作中使用到的频率还是挺高的,因为stream配合着lambda表达式或者双冒号(::)使用真的是优雅到了极致!今天就简单分(搬)享(运)一下我对strea ...
- Java8中的Stream流式操作 - 入门篇
作者:汤圆 个人博客:javalover.cc 前言 之前总是朋友朋友的叫,感觉有套近乎的嫌疑,所以后面还是给大家改个称呼吧 因为大家是来看东西的,所以暂且叫做官人吧(灵感来自于民间流传的四大名著之一 ...
- Java 之 Stream 流
Stream流 在Java 8中,得益于Lambda所带来的函数式编程,引入了一个全新的Stream概念,用于解决已有集合类库既有的弊端 一.传统遍历 1.传统集合的多步遍历代码 几乎所有的集合(如 ...
- java1.8新特性之stream流式算法
在Java1.8之前还没有stream流式算法的时候,我们要是在一个放有多个User对象的list集合中,将每个User对象的主键ID取出,组合成一个新的集合,首先想到的肯定是遍历,如下: List& ...
- Stream流式编程
Stream流式编程 Stream流 说到Stream便容易想到I/O Stream,而实际上,谁规定“流”就一定是“IO流”呢?在Java 8中,得益于Lambda所带来的函数式编程,引入了一个 ...
- 《JAVA8开发指南》使用流式操作
为什么需要流式操作 集合API是Java API中最重要的部分.基本上每一个java程序都离不开集合.尽管很重要,但是现有的集合处理在很多方面都无法满足需要. 一个原因是,许多其他的语言或者类库以声明 ...
- 第46天学习打卡(四大函数式接口 Stream流式计算 ForkJoin 异步回调 JMM Volatile)
小结与扩展 池的最大的大小如何去设置! 了解:IO密集型,CPU密集型:(调优) //1.CPU密集型 几核就是几个线程 可以保持效率最高 //2.IO密集型判断你的程序中十分耗IO的线程,只要大于 ...
- Stream流式计算
Stream流式计算 集合/数据库用来进行数据的存储 而计算则交给流 /** * 现有5个用户,用一行代码 ,一分钟按以下条件筛选出指定用户 *1.ID必须是偶数 *2.年龄必须大于22 *3.用户名 ...
- Java学习:Stream流式思想
Stream流 Java 8 API添加了一种新的机制——Stream(流).Stream和IO流不是一回事. 流式思想:像生产流水线一样,一个操作接一个操作. 使用Stream流的步骤:数据源→转换 ...
随机推荐
- UGUI:窗口限制以及窗口缩放
版权申明: 本文原创首发于以下网站: 博客园『优梦创客』的空间:https://www.cnblogs.com/raymondking123 优梦创客的官方博客:https://91make.top ...
- nginx访问jupyter
现在jupyter已通过k8s安装完成,并通过nodeport暴露出来. 如果不能直接访问这个nodeport(像我在的公司)或是希望能组织好jupyter实例, 那应该如何调通呢? 这里包括两个技术 ...
- drf框架 - 视图家族 | GenericAPIView | mixins | generics | viewsets
视图家族 view:视图 generics:工具视图 mixins:视图工具集 viewsets:视图集 学习曲线: APIView => GenericAPIView => mixins ...
- svg形状相关的学习(二)
_ 阅读目录 一:线段 二:笔画特性 1. stroke-width 2. stroke-opacity 3. stroke-dasharray 属性 三:常见的形状 1. 矩形 2. 圆角矩形 3. ...
- jdbc笔记2
private static String driver; private static String url; private static String username; private sta ...
- Chartjs 简单使用 ------ 制作sin cos 折线图
Chart.js 一款简单干净的图表工具,基于html5 的Javascript. 可以用来制做条形,扇形,折线,混合等等的强大工具 图表要放在html 的 cancas 标签中 <canv ...
- antdpro 打包部署后访问路由刷新后404
antdpro build 后访问路由刷新后 404? 解决方法有三种: 1. 改用 hashHistory,在 .umirc.js或者是config.js 里配 history: 'hash' 2. ...
- JavaSE 笔试题: 自增变量
JavaSE 笔试题 自增变量 public class Test { public static void main(String[] args) { int i = 1; i = i++; int ...
- something want to write
1.时间戳不能相信是因为机器时间有误差.相当于机器不断电的跑着时钟. 2.写log的时候记得log别人的ip,不然没办法很好的debug.
- Docker在Windows上的初体验
作为Docker的初学者,我有几个疑问,找到了答案,并实践了一下,希望对和我一样的初学者有帮助: 1.Docker是什么? 大家对虚拟机应该比较熟悉,虚拟机和docker都是为了实现隔离. 虚拟机隔离 ...