Java8相关底层
Java8是往并行方向走的。由面向对象到函数式编程。
在支持函数式编程的同时还可以支持面向对象的开发。
在JDK1.8里面,接口里面可以有实现方法的!默认方法,default。实现这个接口。
接口里面可以有静态方法
注意Lambda表达式的类型势函数。但是在Java中,Lambda表达式是对象!他们必须依赖于一类特别的对象类型-函数式接口
关于Function<T,R>接口
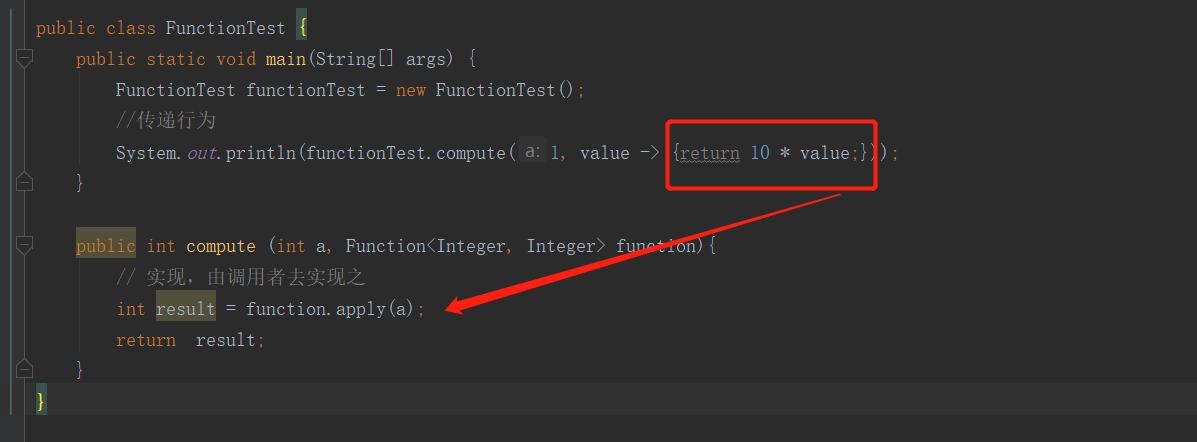
public class FunctionTest {
public static void main(String[] args) {
FunctionTest functionTest = new FunctionTest();
//传递行为
System.out.println(functionTest.compute(1, value -> {return 10 * value;}));
}
public int compute (int a, Function<Integer, Integer> function){
// 实现,由调用者去实现之
int result = function.apply(a);
return result;
}
}
解析:
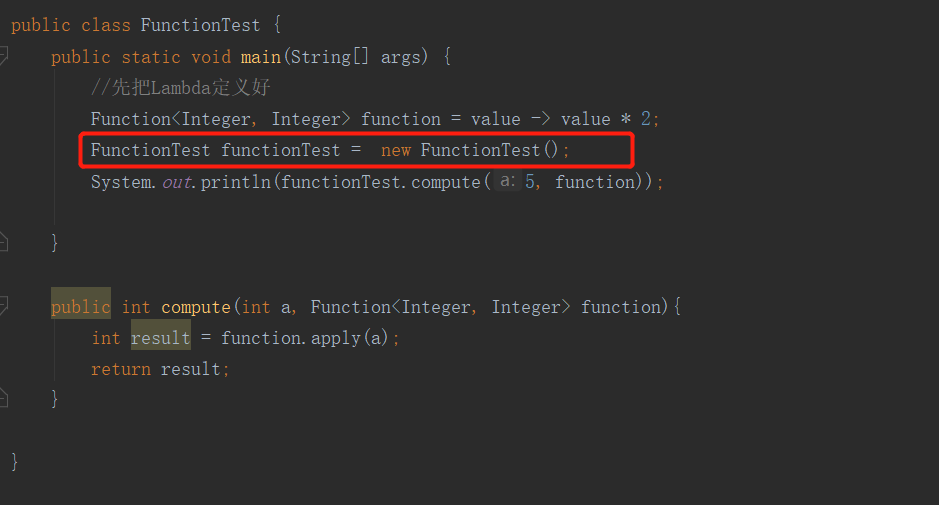
单独吧Lambda抽取出来:
public class FunctionTest {
public static void main(String[] args) {
//先把Lambda定义好
Function<Integer, Integer> function = value -> value * 2;
FunctionTest functionTest = new FunctionTest();
System.out.println(functionTest.compute(5, function));
}
public int compute(int a, Function<Integer, Integer> function){
int result = function.apply(a);
return result;
}
}
多个function之间的串联与先后关系的指定:
public class FunctionTest {
public static void main(String[] args) {
FunctionTest functionTest = new FunctionTest();
System.out.println(functionTest.compute1(2, value -> value * 3, value -> value *value));
System.out.println(functionTest.compute2(2, value -> value * 3, value -> value *value));
}
public int compute1(int a, Function<Integer, Integer> function1, Function<Integer, Integer> function2) {
return function1.compose(function2).apply(a);
}
public int compute2(int a, Function<Integer, Integer> function1, Function<Integer, Integer> function2) {
return function1.andThen(function2).apply(a);
}
}
compose源码:

对比上面的例子,先执行function2 然后将结果赋值给function1去执行
andThen是相反的。
所以,对于 R apply(T t); 要想实现两个输入一个输出,是做不到的。可以通过 BiFunction得到。
public class FunctionTest {
public static void main(String[] args) {
FunctionTest functionTest = new FunctionTest();
System.out.println(functionTest.compute4(2,3, (value1, value2) -> value1 + value2, value -> value * value));
}
public int compute4(int a, int b, BiFunction<Integer, Integer, Integer> biFunction, Function<Integer, Integer> function){
return biFunction.andThen(function).apply(a,b);
}
}
Predicate
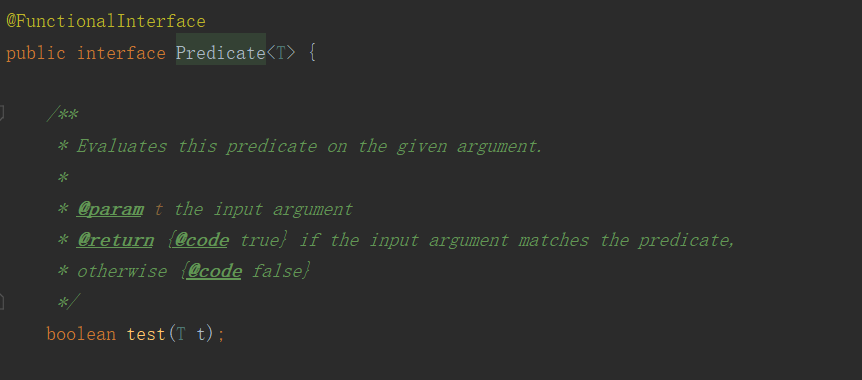
filter的参数类型就是Predicate!
函数式编程提供了更高层次的抽象化:
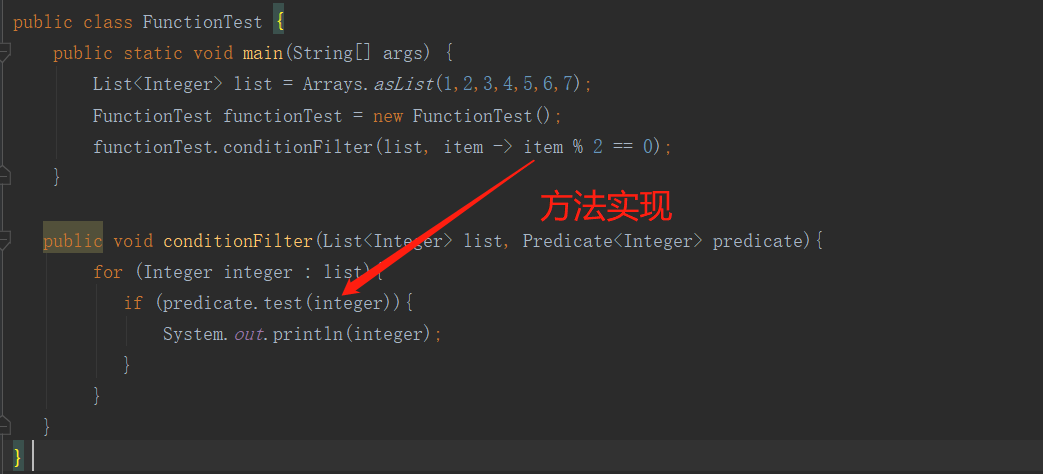
test() 名字都是抽象的,不具体。比较宏观。
public class FunctionTest {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1,2,3,4,5,6,7);
FunctionTest functionTest = new FunctionTest();
functionTest.conditionFilter(list, item -> item % 2 == 0);
}
public void conditionFilter(List<Integer> list, Predicate<Integer> predicate){
for (Integer integer : list){
if (predicate.test(integer)){
System.out.println(integer);
}
}
}
}
对于Predicate的default函数:
public class FunctionTest {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1,2,3,4,5,6,7);
FunctionTest functionTest = new FunctionTest();
functionTest.conditionFilter(list, item -> item % 2 == 0, item -> item < 6);
}
public void conditionFilter(List<Integer> list, Predicate<Integer> predicate1, Predicate<Integer> predicate2){
for (Integer integer : list){
// and 返回的是Predicate! 所以继续 .test
if (predicate1.and(predicate2).test(integer)){
// if (predicate1.or(predicate2).test(integer)){
if (predicate1.negate().test(integer)){ // 取反。满足条件后剩下的
// 如果两个都满足
System.out.println(integer);
}
}
}
}
静态方法: 返回的也是Predicate

作用就是判断两个参数是否相等。
public class FunctionTest {
public static void main(String[] args) {
FunctionTest functionTest = new FunctionTest();
//isEqual传进来的是test 然后和参数 “test”比较
System.out.println(functionTest.isEqual(new Date()).test(new Date()));
}
public Predicate<Date> isEqual(Object object){
return Predicate.isEqual(object);
}
}
Comparator 还是个函数式接口。里面有好几个函数式接口
结合BinaryOperator
Optional 是个容器,可能包含空值,非空值
public class FunctionTest {
public static void main(String[] args) {
// Optional<String> optional = Optional.empty();
Optional<String> optional = Optional.of("valueTest");
optional.ifPresent(item -> System.out.println(item));
System.out.println(optional.orElse("world"));
System.out.println(optional.orElseGet( () -> "hello"));
}
}
public class FunctionTest {
public static void main(String[] args) {
Employee employee1 = new Employee();
employee1.setName("123");
Employee employee2 = new Employee();
employee2.setName("456");
Company company = new Company();
company.setName("c1");
List<Employee> employees = Arrays.asList(employee1, employee2);
company.setEmployees(employees);
List<Employee> result = company.getEmployees();
// if (result != null){
// return result;
// }else {
// return new ArrayList<>();
// }
//一行代码搞定
Optional<Company> optional = Optional.ofNullable(company);
System.out.println(optional.map( item -> item.getEmployees()).orElse(Collections.emptyList()));
}
}
注意 Optional类型,不用做参数类型! 因为没有序列化!
作为返回类型,规避null!
方法引用类似于函数指针。‘’
Remember:
function 接收一个 返回一个
Supplier 只返回不接受
总结方法引用分4类:
1. 类名::静态方法名
2. 引用名(对象名)::实例方法名
3. 类名::实例方法名
4. 构造方法引用:: 类名::new
流有个好处,支持并行化,对一个集合进行迭代,流可以并行,多个线程进行处理。对于多核处理性能大大提升。
public class FunctionTest {
public static void main(String[] args) {
Stream<String> stream = Stream.of("a", "b", "c", "d");
String[] strings = stream.toArray(length -> new String[length]);
Arrays.asList(strings).forEach(System.out::println);
}
}
改造成Lambda表达式构造函数引用: 通过构造函数引用的方式将数组传递进去
public class FunctionTest {
public static void main(String[] args) {
Stream<String> stream = Stream.of("a", "b", "c", "d");
String[] strings = stream.toArray(String[]::new);
Arrays.asList(strings).forEach(System.out::println);
}
}
public class FunctionTest {
public static void main(String[] args) {
Stream<String> stream = Stream.of("a", "b", "c", "d");
List<String> list1 = stream.collect(() -> new ArrayList(),
(theList, item) -> theList.add(item),
(theList1, theList2) -> theList1.addAll(theList2));
//方法二
List<String> list2 = stream.collect(LinkedList::new, LinkedList::add, LinkedList::addAll);
list.stream().forEach(System.out::println);
}
}
public class FunctionTest {
public static void main(String[] args) {
Stream<String> stream = Stream.of("a", "b", "c", "d");
String str = stream.collect(Collectors.joining()).toString();
System.out.println(str);
}
}
flatMap去操作:
public class FunctionTest {
public static void main(String[] args) {
Stream<List<Integer>> listStream = Stream.of(Arrays.asList(1), Arrays.asList(2, 3), Arrays.asList(4, 5, 6));
//每个List转成Stream
listStream.flatMap( theList -> theList.stream())
.map( item -> item * item).forEach(System.out::println);
}
}
正确使用Optional:
public class FunctionTest {
public static void main(String[] args) {
Stream<String> stream = Stream.generate(UUID.randomUUID()::toString);
//返回的是个Optional可以调用get方法。 流里面的第一个元素为啥返回Optional。避免异常。如果流里面没有元素呢?规避之
System.out.println(stream.findFirst().get());
//如果存在元素的话...
stream.findFirst().ifPresent(System.out::println);
//可以创建空的流
Stream<String> stream1 = Stream.empty();
stream1.findFirst().ifPresent(System.out::println);
}
}
public class FunctionTest {
public static void main(String[] args) {
Stream<Integer> stream = Stream.iterate(1, item -> item + 2).limit(6);
IntSummaryStatistics summaryStatistics = stream.filter(item -> item > 2)
.mapToInt(item -> item * 2).skip(2).limit(2).summaryStatistics();
System.out.println( summaryStatistics.getMax());
System.out.println( summaryStatistics.getMin());
}
}
例子:Map: 中间操作,延迟操作。遇到终止操作时候才会执行之
public class FunctionTest {
public static void main(String[] args) {
List<String> list = Arrays.asList("hello", "world", "how are you");
list.stream().map(
item -> {
String result = item.substring(0, 1).toUpperCase() + item.substring(1);
System.out.println("----->");
return result;
}
).forEach( System.out::println);
}
}
Map和flatMap
public static void main(String[] args) {
List<String> list = Arrays.asList("hello welcome", "world hello");
//返回的List string类型的数组 四个数组对象不是不同的!
List<String[]> result = list.stream()
// <R> Stream<R> map(Function<? super T, ? extends R> mapper);
.map(item -> item.split(" ")).distinct().collect(Collectors.toList());
result.forEach(
item -> Arrays.asList(item).forEach(System.out::println)
);
// flatMap System.out.println("----->flatMap"); List<String> resultFlatMap = list.stream().map(item -> item.split(" ")) //<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);
//将数组类型 转成 String类型
.flatMap(Arrays::stream) // 接收的是一个数组类型。返回Stream类型。这样返回四个Stream。 调用FlatMap把四个Stream合并成一个!
.distinct().collect(Collectors.toList());
resultFlatMap.forEach(System.out::println);
}
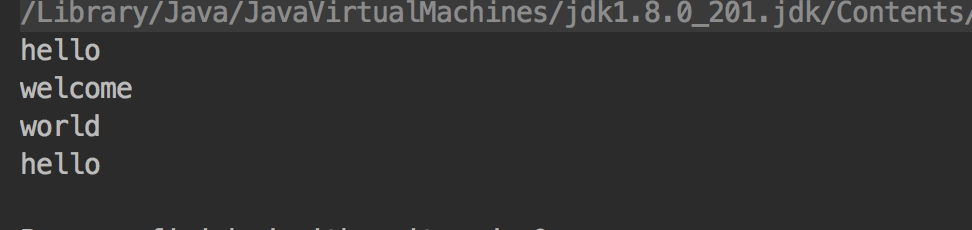

分析 FlatMap将结果打平了,结果放在一个流里面。
上述对于 FlatMap的使用, 首先map映射成字符串数组类型的内容, 然后将字符串数组打平。打平成一个Stream。即: 将 Stream<Strimg[]> ------> Stream<String>
public class FunctionTest {
public static void main(String[] args) {
List<String> list1 = Arrays.asList("你好", "哈哈");
List<String> list2 = Arrays.asList("zhangsan", "lisi", "wangwu");
List<String> result = list1.stream().flatMap(item -> list2.stream().map(item2 -> item + " " + item2)).collect(Collectors.toList());
result.forEach(System.out::println);
}
}

Stream:
和迭代器不同的是,Stream可以并行化操作,迭代器只能命令式、串行化操作
当使用串行方式遍历时,每特item读完后再读下一个
使用并行去遍历时,数据会被分成多段,其中每一个都在不同的线程中处理,然后将结果一起输出。
Stream的并行操作依赖于Java7中引入的Fork/Join框架。任务分解成小任务。
集合关注的是数据与数据存储
流关注的是数计算,流与迭代器类似的一点是: 流复发重复使用或者消费的。
中间操作都会返回一个Stream对象,比如 Stream<Integer> Stream<Strimg> 比如 mapToInt返回 Stream<Integer>
public class FunctionTest {
public static void main(String[] args) {
Employee employee1 = new Employee("a");
Employee employee2 = new Employee("a");
Employee employee3 = new Employee("b");
Employee employee4 = new Employee("c");
List<Employee> list = Arrays.asList(employee1, employee2, employee3, employee4);
Map<String, Long> nameCountMap = list.stream().collect(Collectors.groupingBy(Employee::getName, Collectors.counting()));
System.out.println(nameCountMap);
}
}

list.stream().collect(Collectors.groupingBy(Employee::getName, Collectors.averagingDouble(Employee::getScore));
分组:group by
分区: partition by 区别group by 只能分两组 ,比如 true false。 90以上及格,以下不及格
collect是Stream提供的一个方法。Collector作为Collect方法的参数。Collector接口非常重要,分析之:
Collector是一个接口,文档解释“它是一个可变的汇聚操作,将输入元素累积到一个可变的结果容器中;它会在所有元素处理完毕之后,将累积结果转换为一个最终的表示(这是一个可选操作。支持串行并行两种方式执行。
注意: 并行不一定比串行块,因为并行涉及到线程切换。比如cpu 2核的,生成四个线程。势必四个线程去增强这两个核心,会存在上下文切换。
Collectors本身提供了关于Collectors的常见汇聚实现,Collectors本身是一个工厂。
Collector是由四个元素组成的
combiner函数,有四个线程同时去执行,那么就会生成四个部分结果。然后合并成一个。用在并行流的场景。
为了确保串行与并行操作的结果等价性,Collector函数需要满足两个条件,identity(同一性)与associativity(结合性)。
public interface Collector<T,A,R> T:集合或者流中的每个元素类型, A可变容器类型, R:结果类型
·
public class FunctionTest {
public static void main(String[] args) {
Employee employee1 = new Employee("a", 12);
Employee employee2 = new Employee("a", 23);
Employee employee3 = new Employee("b", 43);
Employee employee4 = new Employee("c", 34);
List<Employee> employees = Arrays.asList(employee1, employee2, employee3, employee4);
String collect1 = employees.stream().map(Employee::getName).collect(Collectors.joining(","));
//连续分组
Map<Integer, Map<String, List<Employee>>> collect = employees.stream()
.collect(Collectors.groupingBy(Employee::getScore, Collectors.groupingBy(Employee::getName)));
//分区
Map<Boolean, List<Employee>> collect2 = employees.stream().collect(Collectors.partitioningBy(e -> e.getScore() > 3));
//连续分区
Map<Boolean, Map<Boolean, List<Employee>>> collect3 = employees.stream().collect(Collectors.partitioningBy(e -> e.getScore() > 80, Collectors.partitioningBy(e -> e.getScore() > 5)));
//综合实战
Map<Boolean, Long> collect4 = employees.stream().collect(Collectors.partitioningBy(employee -> employee.getScore() > 90, Collectors.counting()));
Map<String, Employee> collect5 = employees.stream().collect(Collectors.groupingBy(Employee::getName,
// 收集然后XXX
Collectors.collectingAndThen(Collectors.minBy(Comparator.comparingInt(Employee::getScore)),
Optional::get)));
}
}
排序:
Collector.sort() 本质上是调用 list.sort()
public class FunctionTest {
public static void main(String[] args) {
List<String> list = Arrays.asList("helloWorld", "nihao", "java");
Collections.sort(list, (item1, item2) -> {return (item1.length() - item2.length());});
System.out.println(list);
//当lambda没法推断类型时候,指定下
Collections.sort(list, Comparator.comparingInt((String item) -> item.length()).reversed());
list.sort(Comparator.comparingInt(String::length).reversed());
list.sort(Comparator.comparingInt((String item) -> item.length()).reversed());
//不区分大小写的排序,两个排序规则. 先升序,然后XXX.两个比较规则,第一个相同就调用第二个方法。
Collections.sort(list, Comparator.comparingInt(String::length).thenComparing(String.CASE_INSENSITIVE_ORDER));
Collections.sort(list, Comparator.comparingInt(String::length).thenComparing( (item1, item2) -> item1.toLowerCase().compareTo(item2.toLowerCase())));
Collections.sort(list, Comparator.comparingInt(String::length).thenComparing(Comparator.comparing(String::toLowerCase)));
//长度希望等的,才需要进行第二次比较。小写进行比较,小写逆序。
Collections.sort(list, Comparator.comparingInt(String::length).thenComparing(Comparator.comparing(String::toLowerCase, Comparator.reverseOrder())));
Collections.sort(list, Comparator.comparingInt(String::length).reversed().thenComparing(Comparator.comparing(String::toLowerCase, Comparator.reverseOrder())));
//多级排序
Collections.sort(list, Comparator.comparingInt(String::length).reversed()
// 相同的(比较结果为0的,继续使用下面的方法)
.thenComparing(Comparator.comparing(String::toLowerCase, Comparator.reverseOrder()))
// 是否起作用,取决于前面的比较情况结果
.thenComparing(Comparator.reverseOrder()));
}
}
定义实现自己的收集器:
/**
* 1.实现接口时候,要定义好泛型
* 2.
*/
public class MySetCollector<T> implements Collector<T, Set<T>, Set<T>> { /**
* 提供一个空的容器,供accumulator 后续方法调用
* @return
*/
@Override
public Supplier<Set<T>> supplier() {
System.out.println("-----> supplier");
return HashSet<T>::new;
} /**
* 累加器类型的,接收两个参数不返回值
* @return
*/
@Override
public BiConsumer<Set<T>, T> accumulator() {
System.out.println("-----> accumulator");
//通过方法引用的方式返回了一个 BiConsumer 对象
// return Set<T>::add;
return (set, item) -> set.add(item);
} /**
* 将并行流,多个线程所执行的结果合并起来
* @return
*/
@Override
public BinaryOperator<Set<T>> combiner() {
// 把一个部分结果,添加到另外一个部分结果中
System.out.println("------> combiner");
return (set1, set2) -> {
set1.addAll(set2);
return set1;
};
} /**
* 多线程情况下,最后一步要执行的。返回最终的结果类型。返回结果容器给用户。
* @return
*/
@Override
public Function<Set<T>, Set<T>> finisher() {
// return t -> t;
return Function.identity();
} /**
* 返回一个set集合,表示当前的收集器诸多独特性。
* @return
*/
@Override
public Set<Characteristics> characteristics() {
System.out.println("----->characteristics");
// 直接返回一个不可变的集合,参数为指定的特性
return Collections.unmodifiableSet(EnumSet.of(IDENTITY_FINISH, UNORDERED));
} public static void main(String[] args) {
List<String> list = Arrays.asList("hello", "world", "welcome", "hello");
Set<String> collect = list.stream().collect(new MySetCollector<>());
System.out.println(collect);
}
}
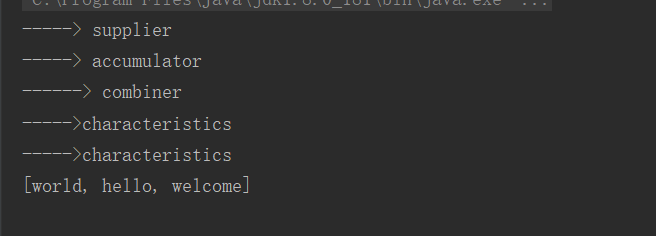
看下面例子:
public class MySetCollector2<T> implements Collector<T,Set<T>, Map<T,T>> {
@Override
public Supplier<Set<T>> supplier() {
System.out.println("supplier invoked");
return HashSet::new;
}
@Override
public BiConsumer<Set<T>, T> accumulator() {
System.out.println("accumulator invoked");
return (set, item) -> {
set.add(item);
};
}
@Override
public BinaryOperator<Set<T>> combiner() {
System.out.println("combiner invoked");
return (set1, set2) -> {
set1.addAll(set2);
return set1;
};
}
@Override
public Function<Set<T>, Map<T, T>> finisher() {
System.out.println("finisher invoked");
return set -> {
Map<T,T> map = new HashMap<>();
set.stream().forEach(
item -> map.put(item, item)
);
return map;
};
}
@Override
public Set<Characteristics> characteristics() {
System.out.println("characteristics invoked!");
return Collections.unmodifiableSet(EnumSet.of(Characteristics.UNORDERED));
}
public static void main(String[] args) {
List<String> list = Arrays.asList("hello", "world", "welcome", "a", "b", "c");
Set<String> set = new HashSet<>();
set.addAll(list);
System.out.println("set"+ set);
Map<String, String> collect = set.stream().collect(new MySetCollector2<>());
System.out.println(collect);
}
}
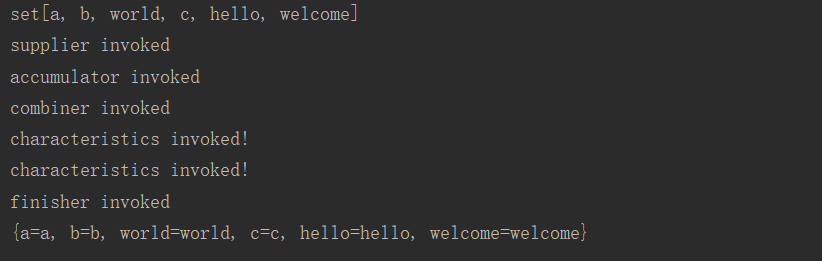
收集器:
对于Collectors惊天工厂类来说,其实现一共分为两种情况:
- 通过ColletcorImpl来实现
- 通过reduceing方法来实现(reducing方法本身又是通过CollectorImpl来实现)
关于toList()
public static <T>
Collector<T, ?, List<T>> toList() {
return new CollectorImpl<>((Supplier<List<T>>) ArrayList::new, List::add,
(left, right) -> { left.addAll(right); return left; },
CH_ID);
}
Java8相关底层的更多相关文章
- java8 学习系列--NIO学习笔记
近期有点时间,决定学习下java8相关的内容: 当然了不止java8中新增的功能点,整个JDK都需要自己研究的,不过这是个漫长的过程吧,以自己的惰性来看: 不过开发中不是有时候讲究模块化开发么,那么我 ...
- Java8 Lambda表达应用 -- 单线程游戏server+异步数据库操作
前段时间我们游戏server升级到开发环境Java8,这些天,我再次server的线程模型再次设计了一下,耗费Lambda表情. LambdaJava代码.特别是丑陋不堪的匿名内部类,这篇文章主要就是 ...
- java8新特性(二)_lambda表达式
最近一直找java8相关新特性的文章,发现都太没有一个连贯性,毕竟大家写博客肯定都有自己的侧重点,这里找到一本书,专门介绍java8新特性的,感觉大家可以看看<写给大忙人看的JavaSE8> ...
- Block详解一(底层分析)
本篇博客不再讲述Block的基本定义使用,最近而是看了很多的block博客讲述的太乱太杂,所以抽出时间整理下block的相关底层知识,在讲述之前,提出几个问题,如果都可以回答出来以及知道原理,大神绕过 ...
- 洞悉MySQL底层架构:游走在缓冲与磁盘之间
提起MySQL,其实网上已经有一大把教程了,为什么我还要写这篇文章呢,大概是因为网上很多网站都是比较零散,而且描述不够直观,不能系统对MySQL相关知识有一个系统的学习,导致不能形成知识体系.为此我撰 ...
- 最新阿里Java技术面试题,看这一文就够了!
金三银四跳槽季即将到来,作为 Java 开发者你开始刷面试题了吗?别急,小编整理了阿里技术面试题,看这一文就够了! 阿里面试题目目录 技术一面(基础面试题目) 技术二面(技术深度.技术原理) 项目实战 ...
- 一篇面经(BAT面试)(转)
0. 写在之前 首先呢我的面试经历和一些面霸和收割机的大神相比绝不算丰富,但我这三个月应该能代表很大一部分人的心路历程:从无忧无虑也无知的状态,然后遭遇挫败,跌入低谷,连续数天的黑暗,慢慢调整,逼着自 ...
- 2019年6月份,阿里最新Java高频面试真题汇总,仅供参考(附福利)
目录 技术一面(23问) 技术二面(3大块) JAVA开发技术面试中可能问到的问题(17问) JAVA方向技术考察点(33快) 项目实战(7大块) 必会知识(48点) 面试小技巧 注意事项 1. 阿里 ...
- 架构师小跟班:送你一份2019年阿里巴巴最新Java面试题,以供参考
大家都说大厂面试造飞机,工作拧螺丝.这话只对了一部分,大厂是平时拧螺丝,一旦需要飞机时也能造的起来. 目录 技术一面(23问) 技术二面(3大块) JAVA开发技术面试中可能问到的问题(17问) JA ...
随机推荐
- 将Quartz.NET集成到 Castle中
原文:https://cloud.tencent.com/developer/article/1030346 Castle是针对.NET平台的一个开源项目,从数据访问框架ORM到IOC容器,再到WEB ...
- docker端口映射或启动容器时报错Error
现象: [root@localhost ~]# docker run -d -p 9000:80 centos:httpd /bin/sh -c /usr/local/bin/start.shd5b2 ...
- Sitemap Error : XML declaration allowed only at the start of the document解决方法
今天ytkah的客户反馈说他的xml网站地图有问题,提示Sitemap Error : XML declaration allowed only at the start of the documen ...
- 网络命令——write、wall、ping、ifconfig、mail
1.write命令: 前提:用户必须在线: (1)向zhb用户发送信息: (2)用户收到信息: CTRL+D结束会话. 2.wall(发送广播信息,即给在线的所有用户发送信息) 管理员发送消息(自己可 ...
- smashing 开源方便的dashboard 试用
smashing 一个方便的dashboard 工具,是在Shopify/dashing 上维护的一个版本因为原有的官方团队不在维护了 smashing 使用简单,提供了脚手架同时也有好多人开发了一些 ...
- promethues exporter+ grafana 监控pg+mysql
这篇文章本来是打算使用pmm 进行数据库监控的,但是居然参考官方文档使用docker 运行起来有点问题,所以直接改用 exporter 进行处理,但是比pmm 弱好多 pmm 的参考架构 说明,以上图 ...
- Reactive Extensions (Rx) 入门(4) —— Rx的事件编程
译文:https://blog.csdn.net/fangxing80/article/details/7685393 原文:http://www.atmarkit.co.jp/fdotnet/int ...
- flag&to do list¬e
没错,今天我要立几个看起来可能会倒的 flag 今天白天 早上除非有特殊情况,不许再看我的博客.不许再看我的qq空间.不许再跟别人聊闲话!!!☑已达成 今天早上一定要坚持做题,把昨天问老师的问题搞懂, ...
- python 判断元素是否在一个列表中
import random val= data=[,,,,] : find=False val=int(input('请输入查找键值(1-9),输入-1离开:')) for i in data: if ...
- js svg转图片格式
1.情景展示 闲来无事的时候,发现chrome扩展程序里面有图像,本想下载下来,却发现文件格式是svg格式,如何将svg文件改成图片格式? chrome-extension://jlgkpaici ...