MapReduce Join的使用
一、Map端Join
可连接两个都非常大的数据集之间可使用map端连接,数据在到达map端之前就执行连接操作。
需满足:
两个要连接的数据集都先划分成相同数量的分区,相同的key要保证在同一分区中(每个分区中两个数据集数据量不一定要要相同), 并且要 按连接key排序;
利用CompositeInputFormat类,可实现map端连接:
代码参考:GitHub上Join示例
其它参考:hadoop实现join (CompositeInputFormat)
二、Reduce端连接
Reduce端连接更简单易用,以天气连接为例:
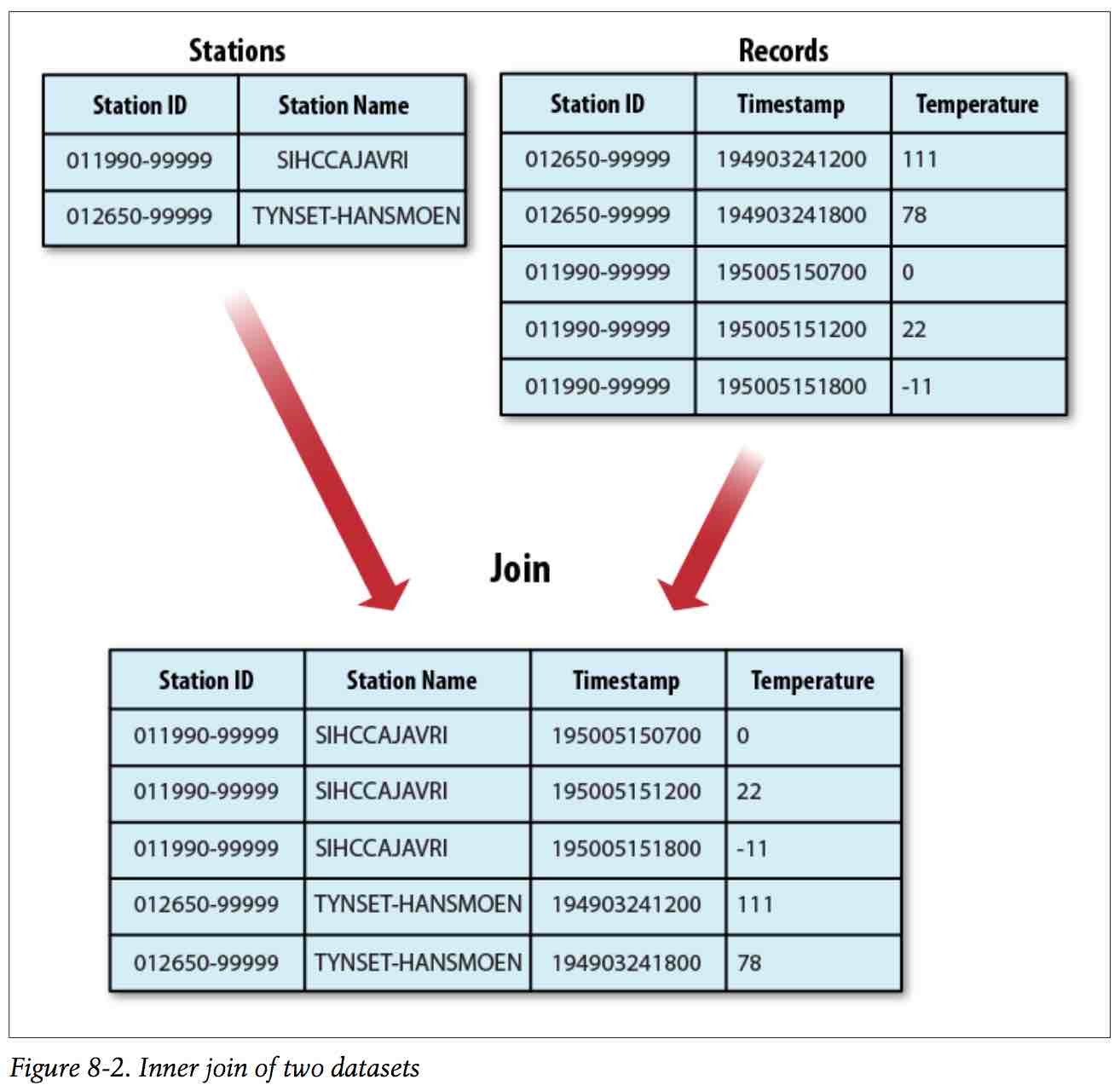
使用步骤:
1、使用MutipleInputs类设定不同输入数据集的InputFormat,以及Mapper;
2、辅助排序:通过自定义一个WritableComparable类型的 T,添加一个辅助排序字段,重写compareTo()方法,
作为传入Reducer的key,可完成可控的二次排序;
3、自定义Partitioner类,保证以自定义WritableComparable类型的T以首字段进行分区;自定一个分组Comparator类;
job.setPartitionerClass(KeyPartitioner.class);
job.setGroupingComparatorClass(TextPair.FirstComparator.class);
自定义Partitioner类、Comparator:
public static class KeyPartitioner extends Partitioner<TextPair, Text> {
@Override
public int getPartition(TextPair key, Text value, int numPartitions) {
return (key.getFirst().hashCode() & Integer.MAX_VALUE) % numPartitions;
}
}
public static class FirstComparator extends WritableComparator {
private static final Text.Comparator TEXT_COMPARATOR = new Text.Comparator();
public FirstComparator() {
super(TextPair.class);
}
@Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
try {
int firstL1 = WritableUtils.decodeVIntSize(b1[s1]) + readVInt(b1, s1);
int firstL2 = WritableUtils.decodeVIntSize(b2[s2]) + readVInt(b2, s2);
return TEXT_COMPARATOR.compare(b1, s1, firstL1, b2, s2, firstL2);
} catch (IOException e) {
throw new IllegalArgumentException(e);
}
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
if (a instanceof TextPair && b instanceof TextPair) {
return ((TextPair) a).first.compareTo(((TextPair) b).first);
}
return super.compare(a, b);
}
}
3、在Reducer中把选到达的key提取出来,即可自定义完成Join操作;
三、使用分布式缓存来实现:
其它参考:MapReduce 中的两表 join 几种方案简介
MapReduce Join的使用的更多相关文章
- mapreduce join
MapReduce Join 对两份数据data1和data2进行关键词连接是一个很通用的问题,如果数据量比较小,可以在内存中完成连接. 如果数据量比较大,在内存进行连接操会发生OOM.mapredu ...
- SQL join中级篇--hive中 mapreduce join方法分析
1. 概述. 本文主要介绍了mapreduce框架上如何实现两表JOIN. 2. 常见的join方法介绍 假设要进行join的数据分别来自File1和File2. 2.1 reduce side jo ...
- MapReduce Join关联
Reduce join 原理 Map端的主要工作:为来自不同表(文件)的key/value对打标签以区别不同来源的记录.然后用连接字段作为key,其余部分和新加的标志作为value,最后进行输出. R ...
- mapreduce join操作
上次和朋友讨论到mapreduce,join应该发生在map端,理由太想当然到sql里面的执行过程了 wheremap端 join在map之前(笛卡尔积),但实际上网上看了,mapreduce的笛卡尔 ...
- Hadoop.2.x_高级应用_二次排序及MapReduce端join
一.对于二次排序案例部分理解 1. 分析需求(首先对第一个字段排序,然后在对第二个字段排序) 杂乱的原始数据 排序完成的数据 a,1 a,1 b,1 a,2 a,2 [排序] a,100 b,6 == ...
- MapReduce实现的Join
MapReduce Join 对两份数据data1和data2进行关键词连接是一个很通用的问题,如果数据量比较小,可以在内存中完成连接. 如果数据量比较大,在内存进行连接操会发生OOM.mapredu ...
- MapReduce中的Join算法
在关系型数据库中Join是非常常见的操作,各种优化手段已经到了极致.在海量数据的环境下,不可避免的也会碰到这种类型的需求,例如在数据分析时需要从不同的数据源中获取数据.不同于传统的单机模式,在分布式存 ...
- 大数据mapreduce俩表join之python实现
二次排序 在Hadoop中,默认情况下是按照key进行排序,如果要按照value进行排序怎么办?即:对于同一个key,reduce函数接收到的value list是按照value排序的.这种应用需求在 ...
- Hadoop学习之路(二十一)MapReduce实现Reduce Join(多个文件联合查询)
MapReduce Join 对两份数据data1和data2进行关键词连接是一个很通用的问题,如果数据量比较小,可以在内存中完成连接. 如果数据量比较大,在内存进行连接操会发生OOM.mapredu ...
随机推荐
- 算法复习——LCA模板(POJ1330)
题目: Description A rooted tree is a well-known data structure in computer science and engineering. An ...
- [HDU-5536] Chip Factory (01字典树)
Problem Description John is a manager of a CPU chip factory, the factory produces lots of chips ever ...
- Tomcat 调优技巧
Tomcat 调优技巧:1.Tomcat自身调优: ①采用动静分离节约Tomcat的性能: ②调整Tomcat的线程池: ③调整Tomcat的连接器: ④修改Tomcat的运行模式: ⑤禁用AJP连接 ...
- uva 550 有趣的乘法(dfs)
题目大意:给三个数A(进制).B(如*****7的最后一个数字7).C(*****7*4的后面的因数4)求符合条件下的第一个因数的位数最少 例子: 179487 * 4 = 717948 (10进制) ...
- hdu 1104 数论+bfs
Remainder Time Limit: 6000/3000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total ...
- Linux中有硬件时钟与系统时钟
在Linux中有硬件时钟与系统时钟等两种时钟.硬件时钟是指主机板上的时钟设备,也就是通常可在BIOS画面设定的时钟.系统时钟则是指kernel中的时钟.当Linux启动时,系统时钟会去读取硬件时钟的设 ...
- 不拖控件的asp.net编程方法——第1回
以前写的asp.net程序基本上都用了webfrom的控件编写的,当然有个好处就是易入门.快速效率高,但感觉自己这了几个小系统,还是没学到什么东西,感觉心里没底,因为都是封装好的东西,拿来就用的,功能 ...
- Gradle讲解
简介: Gradle是一个基于Apache Ant和Apache Maven概念的项目自动化构建工具.它使用一种基于Groovy的特定领域语言(DSL)来声明项目设置,抛弃了基于XML的各种繁琐配置. ...
- 文件重定向,getline()获取一样,屏幕输出流,格式控制符dec,oct,hex,精度控制setprecision(int num),设置填充,cout.width和file(字符),进制输入
1.在window下的命令重定向输出到文件里 2.将内容输入到某个文件里的方式:命令<1.txt (使用1.txt中的命令) 3.读取文件里的名,然后将命令读取最后输出到文件里.命令< ...
- nexus批量更新jar包
nexus批量更新jar包 学习了:https://blog.csdn.net/newtelcom/article/details/54379607 手动进行jar包的拷贝,在维护界面内进行批量更新: