python网络爬虫。第一次测试-有道翻译
2018-03-0720:53:56
成功的效果如下

代码备份
# -*- coding: UTF-8 -*-
from urllib import request
from urllib import parse
import json if __name__ == "__main__":
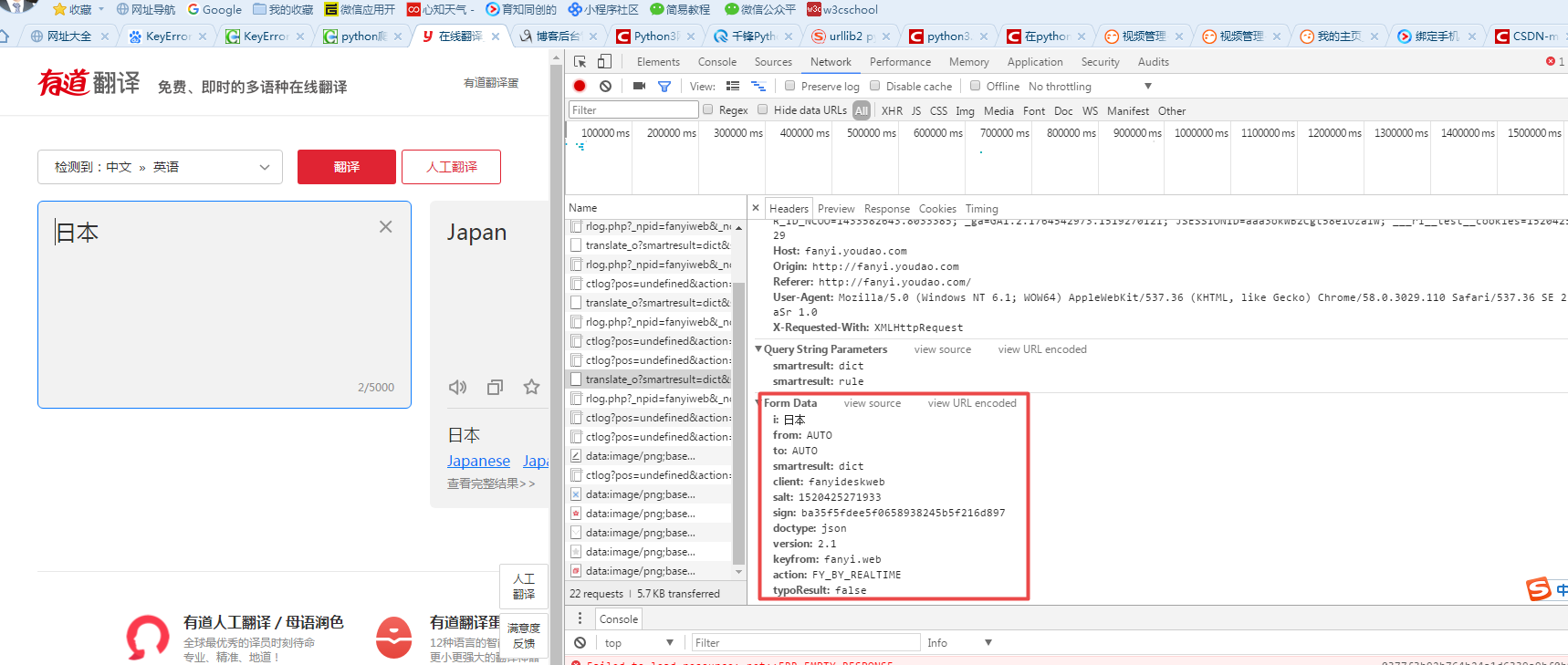
#对应上图的Request URL
Request_URL = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc'
#创建Form_Data字典,存储上图的Form Data
Form_Data = {}
Form_Data['i'] = 'hello'
Form_Data['from'] = 'AUTO'
Form_Data['to'] = 'AUTO'
Form_Data['smartresult'] = 'dict'
Form_Data['client'] = 'fanyideskweb'
Form_Data['salt'] = ''
Form_Data['sign'] = 'ba35f5fdee5f0658938245b5f216d897'
Form_Data['doctype'] = "json"
Form_Data['version'] = '2.1'
Form_Data['keyfrom'] = 'fanyi.web'
Form_Data['action'] = 'FY_BY_REALTIME'
Form_Data['typoResult'] = 'false'
#使用urlencode方法转换标准格式
data = parse.urlencode(Form_Data).encode('utf-8')
#传递Request对象和转换完格式的数据
response = request.urlopen(Request_URL,data)
print(response.getcode())
#读取信息并解码
html = response.read().decode('utf-8')
#使用JSON
translate_results = json.loads(html)
#找到翻译结果
translate_results = translate_results["translateResult"][0][0]['tgt']
#打印翻译信息
print(html)
print("翻译的结果是:%s" % translate_results)
效果还是可以的,毕竟这是自己的第一次调试。
代码更新
加入json数据解析的方法
# -*- coding: UTF-8 -*-
from urllib import request
from urllib import parse
import json if __name__ == "__main__":
#对应上图的Request URL
Request_URL = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc'
#创建Form_Data字典,存储上图的Form Data
Form_Data = {}
Form_Data['i'] = '我曾经有一个梦想'
Form_Data['from'] = 'AUTO'
Form_Data['to'] = 'AUTO'
Form_Data['smartresult'] = 'dict'
Form_Data['client'] = 'fanyideskweb'
Form_Data['salt'] = ''
Form_Data['sign'] = 'ba35f5fdee5f0658938245b5f216d897'
Form_Data['doctype'] = "json"
Form_Data['version'] = '2.1'
Form_Data['keyfrom'] = 'fanyi.web'
Form_Data['action'] = 'FY_BY_REALTIME'
Form_Data['typoResult'] = 'false'
#使用urlencode方法转换标准格式
data = parse.urlencode(Form_Data).encode('utf-8')
#传递Request对象和转换完格式的数据
response = request.urlopen(Request_URL,data)
#读取信息并解码
html = response.read().decode('utf-8')
#使用JSON
translate_results = json.loads(html)
print("输出json数据为: %s" % translate_results)
# 找到可用的key
print("可用的key为:%s" %translate_results.keys())
#找到翻译结果
test = translate_results["type"]
your_input = translate_results["translateResult"][0][0]['src']
translate_results = translate_results["translateResult"][0][0]['tgt'] #打印翻译信息 print("测试输出 %s" %test)
print("待翻译的内容为:%s" % your_input)
print("翻译的结果是:%s" % translate_results)
输出结果为
C:\Users\Administrator\PycharmProjects\python_test1\venv\Scripts\python.exe C:/Users/Administrator/PycharmProjects/python_test1/123.py
输出json数据为: {'type': 'ZH_CN2EN', 'errorCode': 0, 'elapsedTime': 1, 'translateResult': [[{'src': '我曾经有一个梦想', 'tgt': 'I had a dream'}]]}
可用的key为:dict_keys(['type', 'errorCode', 'elapsedTime', 'translateResult'])
测试输出 ZH_CN2EN
待翻译的内容为:我曾经有一个梦想
翻译的结果是:I had a dream Process finished with exit code 0
python网络爬虫。第一次测试-有道翻译的更多相关文章
- Python网络爬虫与信息提取
1.Requests库入门 Requests安装 用管理员身份打开命令提示符: pip install requests 测试:打开IDLE: >>> import requests ...
- 关于Python网络爬虫实战笔记①
python网络爬虫项目实战笔记①如何下载韩寒的博客文章 python网络爬虫项目实战笔记①如何下载韩寒的博客文章 1. 打开韩寒博客列表页面 http://blog.sina.com.cn/s/ar ...
- Python网络爬虫
http://blog.csdn.net/pi9nc/article/details/9734437 一.网络爬虫的定义 网络爬虫,即Web Spider,是一个很形象的名字. 把互联网比喻成一个蜘蛛 ...
- Python 正则表达式 (python网络爬虫)
昨天 2018 年 01 月 31 日,农历腊月十五日.20:00 左右,152 年一遇的月全食.血月.蓝月将今晚呈现空中,虽然没有看到蓝月亮,血月.月全食也是勉强可以了,还是可以想像一下一瓶蓝月亮洗 ...
- Python网络爬虫学习总结
1.检查robots.txt 让爬虫了解爬取该网站时存在哪些限制. 最小化爬虫被封禁的可能,而且还能发现和网站结构相关的线索. 2.检查网站地图(robots.txt文件中发现的Sitemap文件) ...
- Python 网络爬虫 001 (科普) 网络爬虫简介
Python 网络爬虫 001 (科普) 网络爬虫简介 1. 网络爬虫是干什么的 我举几个生活中的例子: 例子一: 我平时会将 学到的知识 和 积累的经验 写成博客发送到CSDN博客网站上,那么对于我 ...
- 学习推荐《精通Python网络爬虫:核心技术、框架与项目实战》中文PDF+源代码
随着大数据时代的到来,我们经常需要在海量数据的互联网环境中搜集一些特定的数据并对其进行分析,我们可以使用网络爬虫对这些特定的数据进行爬取,并对一些无关的数据进行过滤,将目标数据筛选出来.对特定的数据进 ...
- Python网络爬虫实战(一)快速入门
本系列从零开始阐述如何编写Python网络爬虫,以及网络爬虫中容易遇到的问题,比如具有反爬,加密的网站,还有爬虫拿不到数据,以及登录验证等问题,会伴随大量网站的爬虫实战来进行. 我们编写网络爬虫最主要 ...
- python网络爬虫之解析网页的正则表达式(爬取4k动漫图片)[三]
前言 hello,大家好 本章可是一个重中之重,因为我们今天是要爬取一个图片而不是一个网页或是一个json 所以我们也就不用用到selenium模块了,当然有兴趣的同学也一样可以使用selenium去 ...
随机推荐
- eclipse断点有个斜杠 skip all breakpoints
切换到debug,单击下 skip all breakpoints 即可
- jmeter的master-slave模式
要求: 1.相同的jmeter版本 2.最好相同的java版本 jmeter可以通过master-slave的方式实现更大的并发,但是作为master的机器将会消耗更多的资源,因为所有的slave的压 ...
- Codeforces Round #247 (Div. 2) B
B. Shower Line time limit per test 1 second memory limit per test 256 megabytes input standard input ...
- python操作mysql方法和常见问题
http://www.cnblogs.com/ma6174/archive/2013/02/21/2920126.html 安装mysql模块 sudo easy_install mysql-pyth ...
- socker地址API
大端字节序是指一个整数的高位字节存储在内存的低地址处,低位字节存储在内存的高地址处.小端字节序是指整数的高位字节存储在内存的高地址处,低位字节则存储在内存的低地址处. 现代pc大多采用小端字节序,故小 ...
- poj 2318 TOYS & poj 2398 Toy Storage (叉积)
链接:poj 2318 题意:有一个矩形盒子,盒子里有一些木块线段.而且这些线段坐标是依照顺序给出的. 有n条线段,把盒子分层了n+1个区域,然后有m个玩具.这m个玩具的坐标是已知的,问最后每一个区域 ...
- Android实战简易教程-第四十五枪(SlideSwitch-好看又有用的开关button)
开关button也是在项目中经经常使用到的控件,github上有开源的项目,我们研究下它的用法: 1.SlideButton.java: /* * Copyright (C) 2015 Quinn C ...
- Android7.0源码编译运行指南【转】
见连接: http://blog.csdn.net/HardReceiver/article/details/52650303
- dpdpdpdp~~~!!!
dpdpdpdpdpdp D你妹个P! 妈的劳资就不信征服不了你!!哼!!
- linux CentOS中创建用户 无密码登录
首先点击左上角的 “应用程序” -> “系统工具” -> “终端”,首先在终端中输入 su ,按回车,输入 root 密码以 root 用户登录,接着执行命令创建新用户 hadoop: 接 ...