第十六节:Scrapy爬虫框架之项目创建spider文件数据爬取
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取所设计的, 也可以应用在获取API所返回的数据或者通用的网络爬虫。
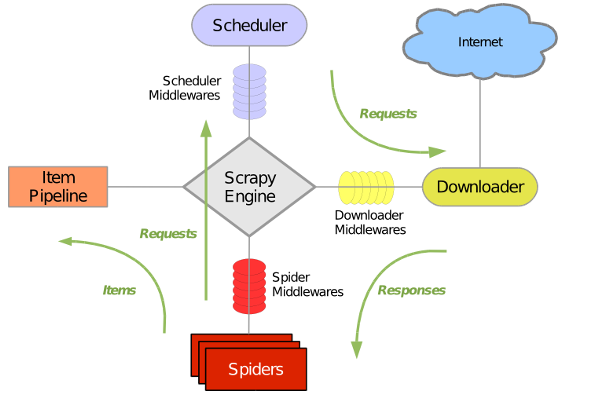
Scrapy原理图如下:
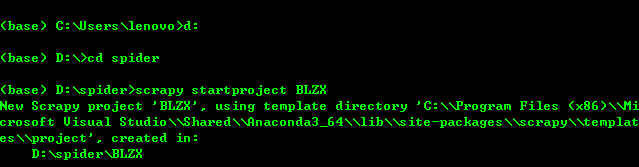
1、创建Scrapy项目:进入你需要创建scrapy项目的文件夹下,输入scrapy startproject BLZX(此处BLZX为爬虫项目名称)
项目创建完成后出现一个scrapy框架自动给你生成的爬虫目录

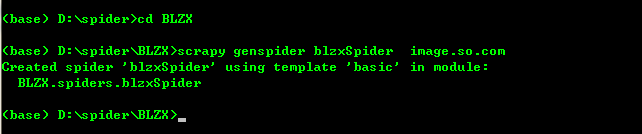
2、进入创建好的项目当中创建spider爬虫文件blzxSpider:
cd BLZX
scrapy genspider blzxSpider image.so.com (其中image.so.com为爬取数据的链接)
到此我们的scrapy爬虫项目已经创建完成,目录如下:

创建好了blzxSpider爬虫文件后scrapy将会在改文件当中自动生成 如下代码,我们就可以在这个文件当中进行编写代码爬取数据了。
# -*- coding: utf-8 -*-
import scrapy class BlzxspiderSpider(scrapy.Spider):
name = 'blzxSpider'
allowed_domains = ['image.so.com']
start_urls = ['http://image.so.com/'] def parse(self, response):
pass
3、爬取360图片玩转的图片,此时我们需要编写blzxSpiser文件进行爬取360图片
代码如下
import scrapy
import json class BoleSpider(scrapy.Spider):
name = 'boleSpider' def start_requests(self):
url = "https://image.so.com/zj?ch=photography&sn={}&listtype=new&temp=1"
page = self.settings.get("MAX_PAGE")
for i in range(int(page)+1):
yield scrapy.Request(url=url.format(i*30)) def parse(self,response):
photo_list = json.loads(response.text)
for image in photo_list.get("list"):
id = image["id"]
url = image["qhimg_url"]
title = image["group_title"]
thumb = image["qhimg_thumb_url"]
print(id,url,title,thumb)
抓取的结果为
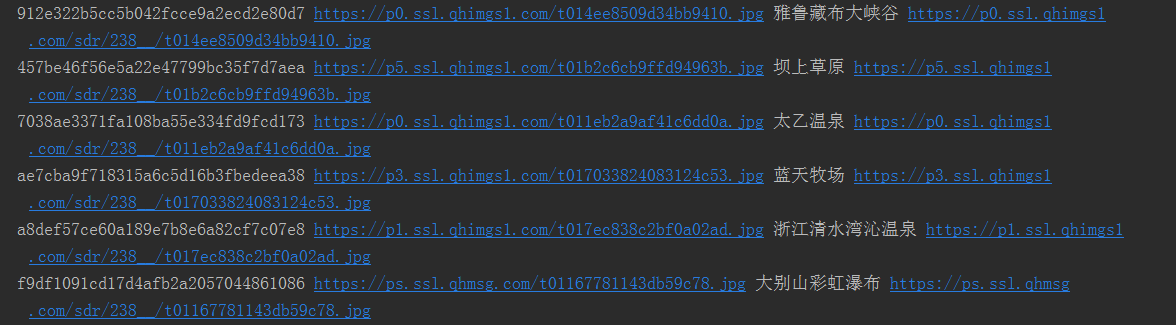
最后,我们已经将360图片的信息已经抓取下来了并打印在的控制台当中。但是我们需要把数据给下载下来,并且进行存储,所以在下一节当中会对item.py文件进行讲解。
第十六节:Scrapy爬虫框架之项目创建spider文件数据爬取的更多相关文章
- 第三百一十六节,Django框架,中间件
第三百一十六节,Django框架,中间件 django 中的中间件(middleware),在django中,中间件其实就是一个类,在请求到来和结束后,django会根据自己的规则在合适的时机执行中间 ...
- scrapy爬虫成长日记之创建工程-抽取数据-保存为json格式的数据
在安装完scrapy以后,相信大家都会跃跃欲试想定制一个自己的爬虫吧?我也不例外,下面详细记录一下定制一个scrapy工程都需要哪些步骤.如果你还没有安装好scrapy,又或者为scrapy的安装感到 ...
- 第二百六十六节,Tornado框架-XSS处理,页码计算,页码显示
Tornado框架-XSS处理,页码计算,页码显示 Tornado框架-XSS攻击过滤 注意:Tornado框架的模板语言,读取数据已经自动处理了XSS攻击,过滤转换了危险字符 如果要使危险字符可以远 ...
- 创建一个scrapy爬虫框架的项目
第一步:打开pycharm,选择"terminal",如图所示: 第二步:在命令中端输入创建scrapy项目的命令:scrapy startproject demo (demo指的 ...
- Scrapy爬虫框架(2)--内置py文件
Scrapy概念图 这里有很多py文件,分别与Scrapy的各个模块对应 superspider是一个爬虫项目 spider1.py则是一个创建好的爬虫文件,爬取资源返回url和数据 items.py ...
- 【php爬虫】百万级别知乎用户数据爬取与分析
代码托管地址:https://github.com/hoohack/zhihuSpider 这次抓取了110万的用户数据,数据分析结果如下: 开发前的准备 安装Linux系统(Ubuntu14.04) ...
- Python爬虫入门教程 3-100 美空网数据爬取
美空网数据----简介 从今天开始,我们尝试用2篇博客的内容量,搞定一个网站叫做"美空网"网址为:http://www.moko.cc/, 这个网站我分析了一下,我们要爬取的图片在 ...
- 第十七节:Scrapy爬虫框架之item.py文件以及spider中使用item
Scrapy原理图: item位于原理图的最左边 item.py文件是报存爬取数据的容器,他使用的方法和字典很相似,但是相比字典item多了额外的保护机制,可以避免拼写错误或者定义错误. 1.创建it ...
- 第二百五十六节,Web框架
Web框架 Web框架本质 众所周知,对于所有的Web应用,本质上其实就是一个socket服务端,用户的浏览器其实就是一个socket客户端. 举例: #!/usr/bin/env python #c ...
随机推荐
- 洛谷P4331 [BOI2004]Sequence 数字序列(左偏树)
传送门 感觉……不是很看得懂题解在说什么? 我们先把原数列$a_i-=i$,那么本来要求递增序列,现在只需要求一个非严格递增的就行了(可以看做最后每个$b_i+=i$,那么非严格递增会变为递增) 如果 ...
- set和get方法
package day02; public class Person { /**为了封装,一般的属性都设置成为private(私有的),所以你无法用 .属性 的方式来得到属性值, * 因此此时用两个p ...
- NDK(10)Android.mk各属性简介,Android.mk 常用模板--未完
参考 : http://blog.csdn.net/hudashi/article/details/7059006 1. Android.mk简介 Android.mk文件是GNU Makefile的 ...
- CoreText的使用方法
- (void)draw { CGContextRef context = UIGraphicsGetCurrentContext(); NSMutableAttributedString *attr ...
- jmeter(二)元件的作用域与执行顺序
1.元件的作用域 JMeter中共有8类可被执行的元件(测试计划与线程组不属于元件),这些元件中,取样器是典型的不与其它元件发生交互作用的元件,逻辑控制器只对其子节点的取样器有效,而其它元件(conf ...
- C. Two strings 二分 + 预处理
http://codeforces.com/contest/762/problem/C 第一个串str[],第二个sub[] 预处理出prefix[i]表示sub的前i位和str[]的最长lcs去到s ...
- NSoup获取网页源代码
NSoup是JSoup的Net移植版本.使用方法基本一致. 如果项目涉及HTML的处理,强烈推荐NSoup,毕竟字符串截断太苦逼了. 下载地址:http://nsoup.codeplex.com/ # ...
- 置换测试: Mock, Stub 和其他
简介 在理想情况下,你所做的所有测试都是能应对你实际代码的高级测试.例如,UI 测试将模拟实际的用户输入(Klaas 在他的文章中有讨论)等等.实但际上,这并非永远都是个好主意.为每个测试用例都访问一 ...
- AJPFX简述java语言现状和发展
作为一种最流行的网络编程语言之一,java语言在当今信息化社会中发挥了 重要的作用.Java语言具有面向对象.跨平台.安全性.多线程等特点,这使得java成为许多应用系统的理想开发语言.java应用在 ...
- 短视频SDK用于旅游行业
超级简单易用的短视频SDK来自RDSDK.COM.锐动天地为开发者提供短视频编辑.视频直播.特效.录屏.编解码.视频转换,等多种解决方案,涵盖PC.iOS.Android多平台.以市场为导向,不断打磨 ...