大数据平台消息流系统Kafka
Kafka前世今生
随着大数据时代的到来,数据中蕴含的价值日益得到展现,仿佛一座待人挖掘的金矿,引来无数的掘金者。但随着数据量越来越大,如何实时准确地收集并分析如此大的数据成为摆在所有从业人员面前的难题。
为了解决大数据流式处理中面临的巨大数据吞吐量的难题,LinkedIn公司开发了Kafka作为其活动流和运营数据处理的消息管道。作为全球最大的职业社交网站,LinkedIn会员人数在世界范围内已超过3亿,Kafka作为一款消息服务,为其系统数据的稳定运行做出了巨大的贡献,因此Kafka的性能和可靠性也得以验证。
LinkedIn与2011将其开源并捐献给Apache基金会,并与2012年正式成为Apache的顶级项目,目前官方最新版本为2.0。
初识Kafka
首先,Kafka作为一个分布式的流平台,具有三个关键能力:
1. 发布和订阅消息(流),在这方面,它类似于一个消息队列或企业消息系统。
2. 以容错的方式存储消息(流)。
3. 在消息流发生时处理它们。
kafka在很多大数据量的应用场景下能更好的替换传统的消息系统,消息系统被用于各种场景(解耦数据生产者,缓存未处理的消息等),与大多数消息系统比较,kafka有更好的吞吐量,内置分区,副本和故障转移,这有利于处理大规模的消息。
Kafka对比主流MQ
这里主要与ActiveMQ和RabbitMQ做对比。
TPS比较:
Kafka最高,RabbitMq 次之, ActiveMq最差。吞吐量对比:
kafka具有高的吞吐量,内部采用消息的批量处理,zero-copy机制,数据的存储和获取是本地磁盘顺序批量操作,具有O(1)的复杂度,消息处理的效率很高。
rabbitMQ在吞吐量方面稍逊于kafka,他们的出发点不一样,rabbitMQ支持对消息的可靠的传递,支持事务,不支持批量的操作;基于存储的可靠性的要求存储可以采用内存或者硬盘。在架构模型方面:
RabbitMQ遵循AMQP协议,RabbitMQ的broker由Exchange,Binding,queue组成,其中exchange和binding组成了消息的路由键;客户端Producer通过连接channel和server进行通信,Consumer从queue获取消息进行消费(长连接,queue有消息会推送到consumer端,consumer循环从输入流读取数据)。rabbitMQ以broker为中心;有消息的确认机制。
kafka遵从一般的MQ结构,producer,broker,consumer,以consumer为中心,消息的消费信息保存的客户端consumer上,consumer根据消费的点,从broker上批量pull数据;无消息确认机制。在可用性方面:
rabbitMQ支持miror的queue,主queue失效,miror queue接管。
kafka的broker支持主备模式。
activeMq也支持主备模式。在集群负载均衡方面:
kafka采用zookeeper对集群中的broker、consumer进行管理,可以注册topic到zookeeper上;通过zookeeper的协调机制,producer保存对应topic的broker信息,可以随机或者轮询发送到broker上;并且producer可以基于语义指定分片,消息发送到broker的某分片上。
rabbitMQ的负载均衡需要单独的loadbalancer进行支持。
下图展示Kafka与主流MQ的同步发送(注:Kafka还支持异步发送模式,性能比同步发送高的多)性能对比:

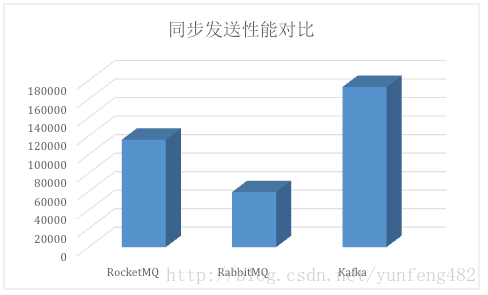
结语
可以看出Kafka在处理大数据的消息流方面,在高性能、高吞吐量和高系统可靠性上较传统MQ具有很大的优势,从设计上处处能看出kafka在这方面的野心,这也是如今在大数据消息流处理中,Kafka如此火热的主要原因。
但是,不得不说,Kafka也有很多不尽人意的地方。比如:
1. Kafka并不保证每条消息的精确处理(不丢失且不重复消费)。Kafka消息丢失主要在两个地方存在可能性:a) Producer端重试次数用完后放弃该批次消息,b) Broker端Partition的leader副本崩溃,其他副本与leader的数据不是完全一致的。Kafka消息产生重复消息也主要在两个地方会出现:a) Producer端发送完批次消息,消息写入成功,但响应超时,造成该批次消息被重发;b) Consumer端对消息偏移量的维护与实际消息消费进度不一致。
2. 0.11(这其实是一个较新的版本,只是Kafka最近的版本号跨度很大)之前的版本不支持事务消息。
3. 只能保证消息的分区有序性(如果在Producer端buffer中的批次是异步发送,在遇到超时和重试的时候,也会乱序),如果需要保证特定类型消息的有序性,需要开发自定义的分区器,将特定类型消息分布到同一个分区(Partition)。
4. 在 2.0 以前,Kafka 自身的访问控制机制还是粗粒度的。比如对“创建Topic”这一权限的控制,只有“全集群”这一种范围。也就是说,对于任何一个用户来说,我们只能给或者不给这种权限。而且Kafka对消息访问的权限控制也不够好,在数据安全性方面有待提升。
大数据平台消息流系统Kafka的更多相关文章
- GoldenGate实时投递数据到大数据平台(5) - Kafka
Oracle GoldenGate是Oracle公司的实时数据复制软件,支持关系型数据库和多种大数据平台.从GoldenGate 12.2开始,GoldenGate支持直接投递数据到Kafka等平台, ...
- 电竞大数据平台 FunData 的系统架构演进
电竞大数据时代,数据对比赛的观赏性和专业性都起到了至关重要的作用.同样的,这也对电竞数据的丰富性与实时性提出了越来越高的要求. 电竞数据的丰富性从受众角度来看,可分为赛事.战队和玩家数据:从游戏角 ...
- Kafka 集群在马蜂窝大数据平台的优化与应用扩展
马蜂窝技术原创文章,更多干货请订阅公众号:mfwtech Kafka 是当下热门的消息队列中间件,它可以实时地处理海量数据,具备高吞吐.低延时等特性及可靠的消息异步传递机制,可以很好地解决不同系统间数 ...
- 时间序列大数据平台建设(Time Series Data,简称TSD)
来源:https://blog.csdn.net/bluishglc/article/details/79277455 引言在大数据的生态系统里,时间序列数据(Time Series Data,简称T ...
- TOP100summit:【分享实录】链家网大数据平台体系构建历程
本篇文章内容来自2016年TOP100summit 链家网大数据部资深研发架构师李小龙的案例分享. 编辑:Cynthia 李小龙:链家网大数据部资深研发架构师,负责大数据工具平台化相关的工作.专注于数 ...
- 大数据平台的技术演化之路 诸葛io平台设计实例
如今,数据分析能力正逐渐成为企业发展的标配,企业通过数据分析的过程将数据中的信息提取出来,进行处理.识别.加工.呈现,最后成为指导企业业务发展的知识和智慧.而处理.识别.加工.呈现的过程从本质上来讲, ...
- 携程实时大数据平台演进:1/3 Storm应用已迁到JStorm
携程大数据平台负责人张翼分享携程的实时大数据平台的迭代,按照时间线介绍采用的技术以及踩过的坑.携程最初基于稳定和成熟度选择了Storm+Kafka,解决了数据共享.资源控制.监控告警.依赖管理等问题之 ...
- 如何基于Go搭建一个大数据平台
如何基于Go搭建一个大数据平台 - Go中国 - CSDN博客 https://blog.csdn.net/ra681t58cjxsgckj31/article/details/78333775 01 ...
- 知名大厂如何搭建大数据平台&架构
今天我们来看一下淘宝.美团和滴滴的大数据平台,一方面进一步学习大厂大数据平台的架构,另一方面也学习大厂的工程师如何画架构图.通过大厂的这些架构图,你就会发现,不但这些知名大厂的大数据平台设计方案大同小 ...
随机推荐
- linux 文件 chgrp、chown、chmod
linux 默认情况下有会提供6个terminal 来让用户登录,使用[Ctrl]+[Alt] +[F1]~[F6] 组合 linux 文件 任何一个文件都具有"user,Group及Oth ...
- Manven下载
1.下载地址:http://maven.apache.org/download.cgi 2.点击下载链接 3.解压zip到安装路径 我的:C:\Progr ...
- 异或+构造 HDOJ 5416 CRB and Tree
题目传送门 题意:给一棵树,问f (u, v) 意思是u到v的所有路径的边权值的异或和,问f (u, v) == s 的u,v有几对 异或+构造:首先计算f (1, u) 的值,那么f (u, v) ...
- uwp选取文件夹并读取其中的图片
uwp对文件的操作和wpf,winform等等有很大的不同,主要原因是uwp对权限的要求比较严格,不能想从前那样随心所欲的读取文件. 1.首先找到Package.appxmanifest这个文件,在功 ...
- 对dynamic和lambda的学习
var, object, dynamic的区别以及使用 dynamic(2) – ExpandoObject的使用 .NET中的Lambda表达式与匿名方法
- 221 Maximal Square 最大正方形
在一个由0和1组成的二维矩阵内,寻找只包含1的最大正方形,并返回其面积.例如,给出如下矩阵:1 0 1 0 01 0 1 1 11 1 1 1 11 0 0 1 0返回 4. 详见:https://l ...
- 1475 建设国家 DP
http://www.51nod.com/onlineJudge/questionCode.html#!problemId=1475 这题转化过来就是,给定n个点,每个点都有一个过期时间,一个价值.现 ...
- Hackonacci Matrix Rotations 观察题 ,更新了我的模板
https://www.hackerrank.com/contests/w27/challenges/hackonacci-matrix-rotations 一开始是没想到观察题的.只想到直接矩阵快速 ...
- ASP.NET Excel下载方法一览
方法一 通过GridView(简评:方法比较简单,但是只适合生成格式简单的Excel,且无法保留VBA代码),页面无刷新 aspx.cs部分 using System; using System.Co ...
- Asp.Net MVC之 自动装配、动态路径(链接)等
一.Model层 using System; using System.Collections.Generic; using System.Linq; using System.Web; namesp ...